

Jeśli w 2026 roku potrzebujesz danych z sieci, trudne pytanie brzmi już nie „czy da się to zeskrobać?”, ale „która warstwa narzędzi da mi użyteczne dane przy najmniejszym marnowaniu czasu na konfigurację, utrzymanie i koszty infrastruktury?”. Dlatego ta strona jest uporządkowana przede wszystkim pod kątem dopasowania: AI web scrapery dla szybkości, narzędzia no-code dla powtarzalnych zadań w przeglądarce, API dla skali i walki z botami oraz biblioteki Python dla zespołów, które chcą mieć pełną kontrolę.
Krótka odpowiedź
- Wybierz AI web scraper, jeśli chcesz najszybszej drogi od strony do arkusza przy minimalnej konfiguracji.
- Wybierz no-code scraper, jeśli potrzebujesz bardziej jawnej paginacji, harmonogramów, obsługi logowania lub powtarzalnej kontroli zadań.
- Wybierz scraping API, jeśli renderowanie, ochrona antybotowa, współbieżność i skuteczność odblokowywania są ważniejsze niż prostota interfejsu.
- Wybierz bibliotekę Python, jeśli Twój zespół chce pełnej kontroli nad żądaniami, parsowaniem, automatyzacją przeglądarki, ponawianiem prób i wdrożeniem.
W przypadku większości zespołów biznesowych błędem jest zbyt wczesne schodzenie „w dół stosu”. Zacznij od najlżejszego narzędzia, które realnie wykona zadanie, a dopiero potem przechodź od AI do no-code, od no-code do API i od API do kodu — tylko wtedy, gdy przepływ pracy naprawdę tego wymaga.
Pobierz pełny pakiet wizualny tutaj: pakiet wizualny narzędzi do scrapowania stron internetowych.
Szybka tabela porównawcza: narzędzia do scrapowania stron internetowych w skrócie
Poniższe sygnały cenowe sprawdzono 12 maja 2026 r. na oficjalnych stronach produktów, cenników lub dokumentacji. Tam, gdzie dostawcy stosują rozliczenie niestandardowe lub oparte na użyciu, opisuję model cenowy zamiast podawać fikcyjną miesięczną kwotę „jabłka do jabłek”.
| Narzędzie | Kategoria | Najlepsze zastosowanie | Dlaczego trafiło na tę listę 2026 | Sygnał cenowy (sprawdzone w maju 2026) |
|---|---|---|---|---|
| Thunderbit | AI web scraper | Sprzedaż, operacje, e-commerce, nieruchomości | Najszybsza nietechniczna droga od strony WWW do uporządkowanej tabeli | Plan darmowy, płatne poziomy, ceny dla firm |
| Kadoa | Platforma ekstrakcji AI | Zespoły danych i większe cykliczne programy | Świetnie sprawdza się przy samonaprawiających się przepływach ekstrakcji w stylu agentowym | Darmowa ewaluacja, plany rozliczane za użycie i dla firm |
| Octoparse | No-code scraper | Analitycy i cykliczne zadania operacyjne | Dojrzałe scrapowanie w chmurze i wizualny kreator zadań | Plan darmowy, Standard od 69 USD/mies., wyższe pakiety |
| ParseHub | Low-code scraper | Techniczni nietechnicy i badacze | Elastyczna logika nawigacji przy trudniejszych serwisach | Plan darmowy, płatne plany od 189 USD/mies. |
| Web Scraper | Przeglądarkowy no-code scraper | Początkujący i lekkie powtarzalne zadania | Prosty model mapy witryny z opcjonalną warstwą chmurową | Darmowe rozszerzenie, Cloud od 50 USD/mies. |
| Browse AI | No-code robot scraper | Monitoring i zespoły pracujące przede wszystkim na arkuszach | Świetne do powtarzalnego monitoringu i alertów o zmianach | Plan darmowy, płatne plany, pakiet zarządzany |
| Bardeen | Automatyzacja przeglądarki z AI | Automatyzacja GTM i revops | Najlepszy, gdy scrapowanie jest tylko jednym krokiem większego workflow | Plan darmowy, Basic od 10 USD/mies., Premium i Enterprise |
| ScrapeStorm | Wizualny scraper wspierany przez AI | Użytkownicy chcący szybkiej konfiguracji wizualnej | Przydatny most między ręcznymi selektorami a wsparciem AI | Darmowy okres próbny, płatne plany, ceny dla firm |
| ScraperAPI | Scraping API | Programiści skalujący liczbę żądań | Proste API plus proxy, CAPTCHA i odciążenie renderowania | 7-dniowy okres próbny, płatne od 49 USD/mies. |
| Bright Data Web Scraper | Platforma enterprise do scrapowania | Programy z dużą liczbą zakupów i naciskiem na zgodność | Najszerszy stos pozyskiwania danych w tym zestawieniu | Cennik produktowy i oparty na użyciu |
| Zyte | API + warstwa antybotowa | Zespoły programistyczne i data teamy | Silne działania w przeglądarce, renderowanie JS i rotacja IP | 5 USD darmowego kredytu testowego, plany oparte na użyciu |
| ZenRows | Scraping API | Startupy i zespoły deweloperskie | Czyste API antybotowe z niższym progiem wejścia | Darmowy okres próbny, Developer od 69 USD/mies. |
| ScrapingBee | Scraping API | Zespoły scrapujące serwisy ciężkie od JS | Przydatne, gdy renderowanie jest głównym problemem | Darmowy okres próbny, płatne od 49 USD/mies. |
| Selenium | Open-source automatyzacja przeglądarki | Flow podobne do QA i scrapowanie wymagające interakcji | Nadal ważne tam, gdzie liczy się dokładne odwzorowanie zachowania użytkownika | Darmowe i open source |
| Beautiful Soup | Biblioteka parsowania w Pythonie | Lekkie scrapowanie w Pythonie | Najprostszy parser w tym zestawie do chaotycznego HTML | Darmowe i open source |
| Playwright | Nowoczesna automatyzacja przeglądarki | Nowoczesne aplikacje webowe i zespoły deweloperskie | Najlepszy nowoczesny wybór do skryptowego scrapowania w przeglądarce | Darmowe i open source |
| urllib3 | Biblioteka HTTP w Pythonie | Programiści chcący niskopoziomowej kontroli nad żądaniami | Przydatna podstawa, gdy chcesz bezpośrednio kontrolować zachowanie transportu | Darmowe i open source |
Jak wybrać właściwe narzędzie do scrapowania stron internetowych
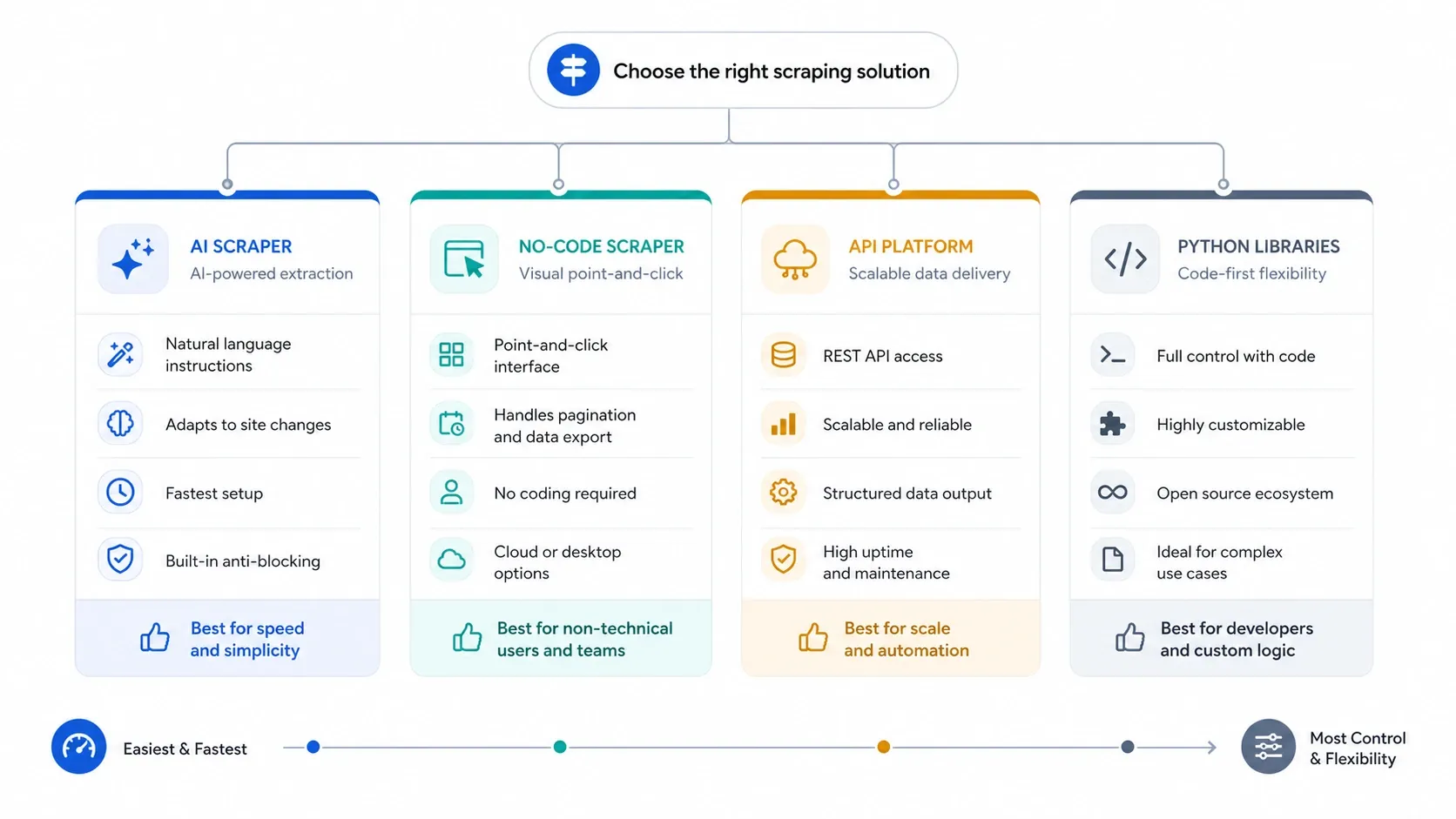
Zanim porównasz marki, użyj czterech filtrów:
- Czas do pierwszego użytecznego wyniku
Jeśli narzędzie nie potrafi szybko wyciągnąć prawdziwej tabeli, już przegrywa w większości zastosowań biznesowych. - Koszt utrzymania
Tani scraper, który psuje się przy każdej zmianie układu strony, nie jest wcale tani. - Limit skali
Rozszerzenie do przeglądarki może być idealne przy 50 stronach tygodniowo i fatalne przy 5 milionach żądań miesięcznie. - Dopasowanie do workflow
Najlepszy scraper dla zespołu revops rzadko jest najlepszy dla inżyniera platformy.
Ramy decyzyjne są zwykle prostsze, niż wydają się zespołom:
- Jeśli chcesz pobierać leady, ogłoszenia albo strony produktów bez dotykania selektorów, zacznij od AI.
- Jeśli potrzebujesz powtarzalnych zadań, uruchomień w chmurze i bardziej jawnej kontroli, przejdź do wizualnych builderów no-code.
- Jeśli prawdziwym problemem jest antybot, renderowanie JavaScript i współbieżność, skocz do API.
- Jeśli chcesz samodzielnie kontrolować każdą warstwę, użyj bibliotek Python i zaakceptuj ciężar utrzymania.
Najlepsze AI web scrapery do szybkich procesów biznesowych
To pierwsza kategoria, którą testowałbym, jeśli chcesz dostać dane gotowe do arkusza przy jak najmniejszej konfiguracji.
1. Thunderbit
Thunderbit nadal jest tutaj najłatwiejszym punktem startowym dla osób nietechnicznych. Kluczową przewagą nie jest tylko „AI” w oderwaniu od reszty, ale to, że produkt skraca pętlę konfiguracji. Otwierasz stronę, prosisz AI o zaproponowanie pól, wzbogacasz dane przez podstrony, gdy trzeba, i wysyłasz wynik prosto do narzędzi, z których Twój zespół już korzysta.
- Najlepsze dla: prospectingu sprzedażowego, monitoringu e-commerce, zbierania danych o nieruchomościach i zespołów operacyjnych pracujących w przeglądarce.
- Dlaczego się wyróżnia: najszybsza droga od chaotycznej strony do uporządkowanej tabeli.
- Uwaga: jeśli potrzebujesz logiki na poziomie crawlera albo bardzo niestandardowych przepływów inżynierskich, ostatecznie przejdziesz do API lub kodu.
- Sygnał cenowy: plan darmowy, samoobsługowe płatne poziomy i ceny dla firm.
Ten materiał nadal jest najszybszym sposobem, by ocenić, czy scrapowanie w modelu AI-first wystarczy do Twojego workflow:
Wypróbuj Thunderbit AI Web Scraper za darmo
2. Kadoa
Kadoa to bardziej infrastrukturalna opcja AI w tej grupie. Ma sens wtedy, gdy chcesz samonaprawiającej się ekstrakcji i zadań cyklicznych w większej skali operacyjnej, niż zwykle są w stanie obsłużyć rozszerzenia do przeglądarki.
- Najlepsze dla: zespołów danych, wewnętrznych programów analitycznych i większych, cyklicznych obciążeń ekstrakcyjnych.
- Dlaczego się wyróżnia: orkiestracja w stylu agentowym i mocniejsza historia o ograniczaniu kosztów utrzymania.
- Uwaga: jest cięższe, niż potrzebuje większość użytkowników biznesowych do szybkiego, jednorazowego scrapowania.
- Sygnał cenowy: darmowa ewaluacja, plany oparte na użyciu i dla firm.
Najlepsze no-code narzędzia do scrapowania stron do powtarzalnych zadań
Gdy zadanie scrapowania staje się cykliczne, bardziej liczą się wizualne kreatory workflow i uruchamianie w chmurze niż sama szybkość „jednego kliknięcia”.
3. Octoparse
Octoparse pozostaje jednym z najbardziej wiarygodnych narzędzi no-code, gdy zadanie jest większe niż rozszerzenie do przeglądarki, ale jeszcze nie jest projektem inżynierskim pisanym od zera. Jego wartość wynika z połączenia uruchomień w chmurze, szablonów i dojrzałego wizualnego kreatora zadań.
- Najlepsze dla: analityków, zespołów cenowych i cyklicznych zadań zbierania danych o realnym znaczeniu operacyjnym.
- Dlaczego się wyróżnia: więcej możliwości niż wtyczki do przeglądarki, bez zmuszania do pisania kodu.
- Uwaga: za tę elastyczność płaci się stromszą krzywą uczenia niż w narzędziach AI-first.
- Sygnał cenowy: plan darmowy, Standard od 69 USD/mies., wyższe płatne poziomy.
Jeśli chcesz ocenić bardziej tradycyjne środowisko no-code przed zakupem narzędzi AI-first, ten oficjalny przegląd Octoparse nadal jest pomocny:
4. ParseHub
ParseHub nadal jest istotny, bo sporo zespołów chce bardziej szczegółowej logiki krok po kroku niż to, co daje lekki AI scraper. To nie jest najładniejszy produkt w tej kategorii, ale pozostaje elastyczny.
- Najlepsze dla: badaczy, dziennikarzy i technicznych nietechników, którzy mogą zaakceptować większą konfigurację.
- Dlaczego się wyróżnia: mocniejsza logika warunkowa i kontrola nawigacji niż w wielu narzędziach dla początkujących.
- Uwaga: wolniej się go uczy i wygląda mniej nowocześnie niż nowsi konkurenci.
- Sygnał cenowy: plan darmowy, płatne plany od 189 USD/mies.
5. Web Scraper
Web Scraper to jedna z bardziej przejrzystych opcji typu „naucz się podstaw bez kupowania platformy”. Jeśli lubisz model mapy witryny, nadal jest to sensowny punkt wejścia.
- Najlepsze dla: początkujących, projektów hobbystycznych i mniejszych zadań wykonywanych z poziomu przeglądarki.
- Dlaczego się wyróżnia: prosty start i łatwe przejście od lokalnego rozszerzenia do planów chmurowych.
- Uwaga: staje się ograniczający, gdy potrzebujesz bardziej adaptacyjnej logiki lub lepszej obsługi odblokowywania.
- Sygnał cenowy: darmowe rozszerzenie, Cloud od 50 USD/mies.
6. Browse AI
Browse AI pozostaje mocnym wyborem, gdy równie ważne są scrapowanie i monitoring. Jego model robota jest intuicyjny dla użytkowników biznesowych, którzy myślą w stylu: „obserwuj tę stronę i powiedz mi, co się zmieniło”.
- Najlepsze dla: monitoringu konkurencji, śledzenia cen i zespołów pracujących przede wszystkim na arkuszach.
- Dlaczego się wyróżnia: dopracowany onboarding, monitoring cykliczny i wyniki przyjazne automatyzacji.
- Uwaga: złożone zadania o dużej skali mogą szybciej stać się drogie niż w stackach opartych na API.
- Sygnał cenowy: plan darmowy, płatne plany, pakiet zarządzany.
Dla zespołów oceniających monitoring stron zamiast jednorazowej ekstrakcji, ten krótki oficjalny przegląd nadal jest dobrym sygnałem:
7. Bardeen
Bardeen mniej skupia się na samej głębokości scrapowania, a bardziej na tym, co dzieje się po nim. Najmocniejszy jest wtedy, gdy ekstrakcja stron WWW jest tylko jednym krokiem w większym workflow automatyzacji przeglądarki.
- Najlepsze dla: operacji GTM, routingu leadów, przekazywania do CRM i automatyzacji natywnej dla przeglądarki.
- Dlaczego się wyróżnia: mocna historia automatyzacji workflow wokół samego scrapowania.
- Uwaga: nie jest to najczystszy wybór, gdy jedyną rzeczą mającą znaczenie jest dokładność ekstrakcji.
- Sygnał cenowy: plan darmowy, Basic od 10 USD/mies., poziomy Premium i Enterprise.
8. ScrapeStorm
ScrapeStorm nadal wypełnia użyteczną niszę pośrodku dla użytkowników, którzy chcą wsparcia AI, ale jednocześnie oczekują bardziej tradycyjnego wizualnego środowiska scrapowania.
- Najlepsze dla: scrapowania katalogów, zbierania stron e-commerce i wizualnie konfigurowanych zadań cyklicznych.
- Dlaczego się wyróżnia: łatwiejszy start niż w przypadku wielu starszych narzędzi wizualnych.
- Uwaga: jest mniej dopracowany niż liderzy kategorii i może wydawać się węższy na trudniejszych stronach.
- Sygnał cenowy: darmowy okres próbny, płatne plany, ceny dla firm.

Najlepsze scraping API, gdy liczy się skala i obsługa antybota
To kategoria, do której warto przejść, gdy prawdziwym ograniczeniem nie jest już „jak wybrać dane?”, tylko „jak utrzymać niezawodność pod obciążeniem?”.
9. ScraperAPI
ScraperAPI nadal jest jednym z najbardziej przystępnych produktów API-first dla programistów, którzy chcą przestać myśleć o proxy i wskaźnikach skuteczności żądań.
- Najlepsze dla: programistów, którzy chcą szybko przejść od prototypu do produkcji.
- Dlaczego się wyróżnia: proste API plus proxy, CAPTCHA i obsługa renderowania.
- Uwaga: nadal odpowiadasz za parsowanie, ponawianie prób i jakość danych po stronie downstream.
- Sygnał cenowy: 7-dniowy okres próbny, płatne od 49 USD/mies.
10. Bright Data Web Scraper
Bright Data to ciężka artyleria, gdy bardziej niż prostota liczą się możliwości odblokowywania, zasoby proxy, zgodność i opcje zarządzane.
- Najlepsze dla: zbierania danych na poziomie enterprise i programów wrażliwych pod kątem zgodności.
- Dlaczego się wyróżnia: najszerszy stack w tym porównaniu — od proxy po zarządzane produkty do pozyskiwania danych.
- Uwaga: łatwo kupić za dużo, jeśli zespół nadal ma dość prosty workflow.
- Sygnał cenowy: cennik produktowy i oparty na użyciu.
11. Zyte
Zyte pozostaje poważną opcją dla zespołów developerskich, które chcą działań w przeglądarce, renderowania JS, rotujących IP i postawy antybotowej w jednym spójnym modelu platformy.
- Najlepsze dla: programów scrapowania prowadzonych przez inżynierów i powtarzalnych systemów ekstrakcji.
- Dlaczego się wyróżnia: mocny stack antydetekcyjny i workflow API-first.
- Uwaga: lepsze dla zespołów z odpowiedzialnością inżynierską niż dla użytkowników biznesowych.
- Sygnał cenowy: 5 USD kredytu na darmowy okres próbny, plany oparte na użyciu.
12. ZenRows
ZenRows ma jedno z najczystszych doświadczeń deweloperskich w kategorii API, jeśli chcesz obsługi antybota bez enterprise’owego procesu zakupowego.
- Najlepsze dla: startupów, programistów i szczupłych zespołów narzędzi wewnętrznych.
- Dlaczego się wyróżnia: relatywnie niski próg wejścia i mocne pozycjonowanie antybotowe.
- Uwaga: nadal jest to produkt API, więc odpowiedzialność za logikę aplikacji i testy jakości nadal zostaje po Twojej stronie.
- Sygnał cenowy: darmowy okres próbny, Developer od 69 USD/mies.
13. ScrapingBee
ScrapingBee ma sens wtedy, gdy Twoją realną potrzebą jest renderowana strona i mniej pracy infrastrukturalnej, szczególnie przy serwisach mocno opartych na JS.
- Najlepsze dla: programistów scrapujących dynamiczne strony, którzy chcą odciążyć renderowanie.
- Dlaczego się wyróżnia: proste API wokół headless browsing i proxy.
- Uwaga: usuwa pracę infrastrukturalną, ale nie potrzebę dobrej logiki scrapowania.
- Sygnał cenowy: darmowy okres próbny, płatne od 49 USD/mies.
Najlepsze biblioteki Python do web scrapingu dla niestandardowych stacków
Ta grupa nadal jest właściwą odpowiedzią, gdy kontrola liczy się bardziej niż wygoda, a Twój zespół jest gotów samodzielnie utrzymywać rozwiązanie.
14. Selenium
Selenium nie jest najnowszym narzędziem do przeglądarki, ale wciąż pozostaje istotne tam, gdzie dokładność interakcji użytkownika ma większe znaczenie niż czysty throughput scrapowania.
- Najlepsze dla: flow z dużą liczbą interakcji, nakładki z QA i stron, gdzie zachowanie przeglądarki jest głównym wyzwaniem.
- Dlaczego się wyróżnia: dojrzały ekosystem i szerokie wsparcie przeglądarek.
- Uwaga: w wielu zadaniach scrapowania jest cięższe i wolniejsze niż nowsze stosy automatyzacji.
- Sygnał cenowy: darmowe i open source.
15. Beautiful Soup

Beautiful Soup pozostaje najprostszym parserem w stosie scrapowania w Pythonie. To nie jest kompletna platforma do scrapowania, ale nadal jest najłatwiejszym sposobem, by zamienić chaotyczny HTML w użyteczną strukturę.
- Najlepsze dla: lekkich zadań w Pythonie, statycznych stron HTML i szybkich prototypów.
- Dlaczego się wyróżnia: niski próg poznawczy i wyrozumiałe parsowanie.
- Uwaga: połącz go z
requests, warstwą przeglądarki albo crawlerem; sam z siebie tylko parsuje. - Sygnał cenowy: darmowe i open source.
16. Playwright
Playwright to mój domyślny nowoczesny wybór dla zespołów developerskich, które potrzebują solidnej automatyzacji przeglądarki na dzisiejszym webie.
- Najlepsze dla: serwisów mocno opartych na JavaScript, nowoczesnej automatyzacji przeglądarki i zespołów, które czują się komfortowo, pisząc kod.
- Dlaczego się wyróżnia: mocne mechanizmy oczekiwania, wsparcie wielu przeglądarek i czyste API.
- Uwaga: nadal odpowiadasz za współbieżność, selektory, infrastrukturę przeglądarki i walidację danych.
- Sygnał cenowy: darmowe i open source.
17. urllib3
urllib3 jest na tej liście, bo niektóre zespoły chcą bezpośredniej kontroli nad zachowaniem transportu zamiast wyższego poziomu abstrakcji. To nie jest scraper dla początkujących, ale jest użyteczną biblioteką bazową, gdy budujesz własny stack.
- Najlepsze dla: programistów, którzy chcą ścisłej kontroli nad ponawianiem prób, proxy, sesjami i zachowaniem HTTP.
- Dlaczego się wyróżnia: lekka, niezawodna i szeroko używana jako infrastruktura.
- Uwaga: większość stacku budujesz samodzielnie.
- Sygnał cenowy: darmowe i open source.
Darmowe narzędzia do scrapowania stron, które warto przetestować najpierw
Jeśli chcesz przetestować przed zakupem, najlepsze darmowe punkty startowe z tej listy to Thunderbit, Octoparse, ParseHub, Web Scraper, Browse AI, Bardeen, Selenium, Beautiful Soup, Playwright i urllib3. Darmowe doświadczenie wystarcza, by zrozumieć, jakiego typu scrapera naprawdę potrzebujesz, a to zwykle jest ważniejsze niż obsesyjne trzymanie się idealnej checklisty funkcji już pierwszego dnia.
Moja krótka lista według typu zespołu

- Zespoły sprzedaży, operacji i e-commerce: zacznij od Thunderbit, a potem porównaj Browse AI, jeśli monitoring jest ważniejszy niż wzbogacanie danych z podstron.
- Analitycy i osoby wykonujące cykliczne zadania ręczne: najpierw Octoparse, a potem ParseHub, jeśli potrzebujesz bardziej niestandardowej logiki zadań.
- Zespoły automatyzujące GTM: Bardeen, jeśli scrapowanie ma trafiać bezpośrednio do CRM, Sheets lub workflow przeglądarkowych.
- Zespoły deweloperskie budujące narzędzia wewnętrzne: ScraperAPI, ZenRows, Zyte lub Playwright — zależnie od tego, ile części stacku chcesz posiadać samodzielnie.
- Enterprise’owe programy danych: Bright Data i Zyte to tu poważniejsze rozmowy infrastrukturalne, a Kadoa jest alternatywą prowadzoną przez AI, gdy głównym celem jest ograniczenie kosztów utrzymania.
Kiedy schodzić niżej w stacku
Użyj tej ścieżki rozwoju:
- Zostań przy AI web scraperach, dopóki nie trafisz na ograniczenia powtarzalności lub przypadków brzegowych.
- Przejdź do no-code builderów, gdy harmonogramy, paginacja i wykonywanie w chmurze są ważniejsze niż prostota jednego kliknięcia.
- Przejdź do API, gdy skuteczność odblokowywania, renderowanie i współbieżność stają się wąskim gardłem.
- Przejdź do bibliotek Python, gdy abstrakcja dostawcy kosztuje więcej niż samodzielne posiadanie całego systemu.
Większość zespołów robi to w złej kolejności. Najpierw wszystko nadbudowują, a dopiero później orientują się, że lżejsze narzędzie mogło rozwiązać prawdziwy workflow.
Ostateczny wniosek
Najlepsze narzędzie do scrapowania stron internetowych w 2026 roku nie ma najdłuższej listy funkcji. To takie, które dostarcza dokładne dane do następnego workflow przy najmniejszym obciążeniu utrzymaniowym dla Twojego zespołu. Dlatego narzędzia AI-first nadal wygrywają u operatorów, rozwiązania no-code pozostają cenne przy powtarzalnych zadaniach w przeglądarce, API dominują tam, gdzie liczy się skala i blokady, a biblioteki Python nadal kontrolują najbardziej wymagającą część stosu.
Jeśli Twoim celem jest zdobycie użytecznych danych jeszcze w tym tygodniu, zacznij prosto. Jeśli jednak Twoje obciążenie już mówi Ci, że prawdziwym problemem jest skuteczność odblokowywania, renderowanie w przeglądarce i kontrola inżynierska, schodź w dół stacku świadomie, a nie z przyzwyczajenia.
Zacznij od najlżejszego scrapera, który naprawdę potrafi wykonać zadanie Get Started Free
FAQ
1. Jakie jest najlepsze narzędzie do scrapowania stron dla użytkowników nietechnicznych w 2026 roku?
Dla większości zespołów nietechnicznych narzędzia AI-first, takie jak Thunderbit i Browse AI, nadal są najszybszą drogą, bo skracają czas konfiguracji, pracę nad selektorami i koszty utrzymania.
2. Co powinienem wybrać dla stron mocno opartych na JavaScript lub chronionych antybotowo?
W takich przypadkach częściej sens mają ScraperAPI, Bright Data, Zyte, ZenRows, ScrapingBee, Playwright lub Selenium niż rozszerzenia do przeglądarki.
3. Czy narzędzia no-code do scrapowania nadal mają sens, skoro AI scrapery są lepsze?
Tak. Octoparse, ParseHub, Web Scraper i Browse AI nadal są ważne, gdy potrzebujesz bardziej jawnej kontroli nad zadaniami, uruchomień cyklicznych lub debugowania widocznego w przeglądarce.
4. Które narzędzia mają największy sens dla zespołów deweloperskich?
ScraperAPI, Zyte, ZenRows, ScrapingBee, Playwright, Selenium, Beautiful Soup i urllib3 to najbardziej naturalne wybory, gdy workflow należy do inżynierii.
Powiązane lektury




