Po wykonaniu znacznie ponad tysiąca ekstrakcji z użyciem Simplescraper przestałem liczyć sukcesy, a zacząłem katalogować porażki. Ta zmiana — z „czy zadziałało?” na „dlaczego tym razem się zepsuło?” — nauczyła mnie więcej niż jakakolwiek strona dokumentacji.
Simplescraper to solidne rozszerzenie Chrome do pobierania danych ze stron internetowych bez pisania kodu. Dzięki w Chrome Web Store i naprawdę przystępnemu interfejsowi typu wskaż i kliknij, zasłużył na swoje miejsce w zestawie narzędzi do scrapowania bez kodu. Ale jest coś, czego nikt nie mówi na stronie głównej: spójne, niezawodne wyniki na dużą skalę wymagają zrozumienia, gdzie wizualne scrapery stają się kruche. , że pracownicy spędzają ponad dziewięć godzin tygodniowo na powtarzalnym wprowadzaniu danych — a to dokładnie taki ból, który popycha ludzi do narzędzi takich jak Simplescraper. Ale jeśli nie znasz jego dziwactw, te dziewięć godzin spędzisz na debugowaniu zamiast na czymś pożytecznym. W tym artykule omawiam pięć najlepszych praktyk wyciągniętych z rzeczywistego doświadczenia operacyjnego: rozwiązywanie problemów z zaznaczaniem elementów, wybór właściwego trybu scrapowania, maksymalne wykorzystanie darmowego planu, unikanie blokad i rozpoznanie momentu, kiedy czas iść dalej.

Czym jest Simplescraper i dlaczego najlepsze praktyki mają znaczenie
Simplescraper to rozszerzenie Chrome, które pozwala wizualnie zaznaczać elementy na stronie internetowej — tytuły produktów, ceny, obrazy, dane kontaktowe — i wyodrębniać je do uporządkowanych danych bez napisania ani jednej linii kodu. Wskażesz, klikniesz, a narzędzie zbuduje „receptę”, którą można ponownie wykorzystać na podobnych stronach.
Model działania wygląda tak:
- Wizualne zaznaczanie elementów: Klikasz to, co chcesz pobrać. Simplescraper automatycznie wykrywa powtarzające się wzorce (listy produktów, wyniki wyszukiwania, oferty pracy).
- Recepty: Zapisujesz konfigurację ekstrakcji, aby użyć jej później albo uruchamiać na paczkach adresów URL.
- Dwa tryby scrapowania: Browser (lokalny, działa w Twoim Chrome) i Cloud (uruchamiany na serwerach Simplescraper, bez nadzoru).
- Integracje: Eksport do Google Sheets, Airtable, webhooków, Zapier, Make, CSV i JSON.
- Ekstrakcja AI: Nowsza funkcja , która generuje selektory CSS na podstawie schematu i podpowiedzi.
Grupa docelowa jest szeroka — marketerzy, zespoły sprzedaży, operatorzy e-commerce, badacze — każdy, kto chce pobierać uporządkowane dane ze stron bez zatrudniania programisty. A w przypadku prostych stron Simplescraper działa szybko.
Dlaczego więc najlepsze praktyki są ważne? Bo w chwili, gdy wyjdziesz poza prostą listę produktów albo czysty katalog, pojawia się tarcie. Dynamiczna treść, zabezpieczenia anty-bot, obrazy ładowane leniwie, zagnieżdżone struktury HTML — to właśnie te warunki w realnym świecie odróżniają frustrujące doświadczenie od produktywnego. Znajomość właściwego podejścia z góry oszczędza godziny prób i błędów.
Najlepsza praktyka 1: Co zrobić, gdy Simplescraper nie zaznacza elementów
To zdecydowanie najczęstsza frustracja, jaką widziałem. Klikasz element, Simplescraper go podświetla, czujesz, że wszystko jest w porządku — a potem w wynikach brakuje połowy danych. Zdjęcia są puste. Biogramy zniknęły. Lokalizacje wyparowały.
Sam założyciel już na początku , że „element/css selector still ain't 100%.” Ta szczerość jest odświeżająca, ale nie naprawia zepsutego scrapingu o 23:00 w środę.
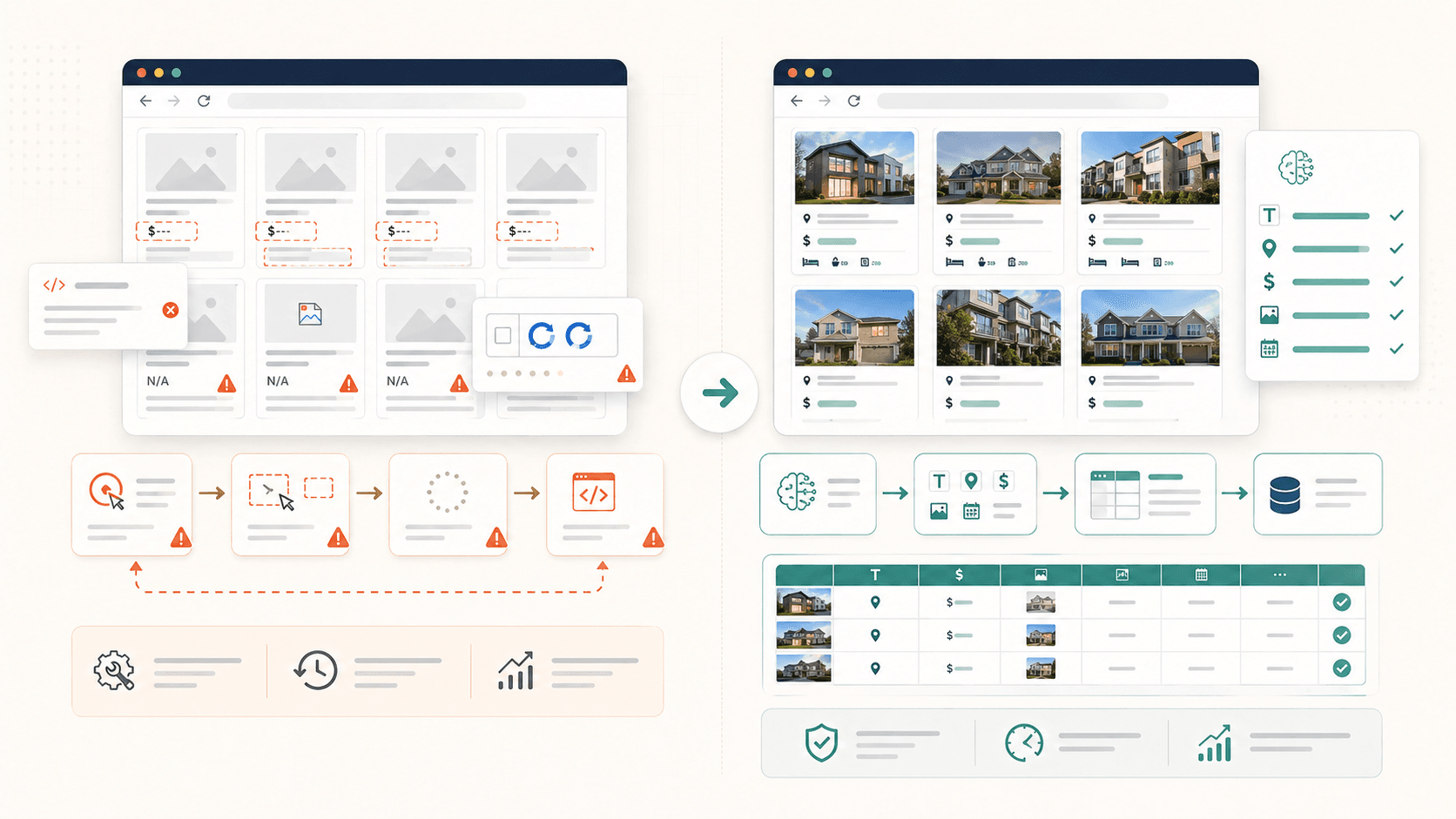
Najczęstsze błędy zaznaczania elementów i skąd się biorą
Cztery wzorce najczęściej sprawiają problemy Simplescraper:
- Obrazy ładowane leniwie: Element obrazu dosłownie , dopóki nie przewiniesz do niego ekranu. Jeśli zaczniesz scrapowanie przed przewinięciem, dostaniesz puste pola obrazów.
- Zagnieżdżone lub pogrupowane kontenery: Automatyczne wykrywanie w Simplescraper , co czasem oznacza, że pobiera tylko jedną sekcję strony zamiast całego powtarzalnego zestawu. Użytkownicy zgłaszają tabele, które „nie chcą zaznaczyć wszystkich wierszy za jednym razem”.
- Dynamiczna zawartość JavaScript: Elementy renderowane po początkowym załadowaniu strony przez React, Vue lub wywołania AJAX po prostu jeszcze nie istnieją, gdy scraper zadziała za wcześnie.
- Nieskończone przewijanie zamiast paginacji: Dane, których chcesz, nie zostały jeszcze załadowane do HTML, bo wymagają przewijania albo kliknięcia „załaduj więcej”.
Praktyczne kroki rozwiązywania problemów
Zanim sięgniesz po ręczne selektory, spróbuj tego:
- Najpierw przewiń całą stronę. To wymusza załadowanie obrazów i treści lazy-loaded do DOM.
- Użyj opcji „Include Similar”, gdy liczba elementów wygląda podejrzanie nisko. Własna dokumentacja Simplescraper rekomenduje to dla treści grupowanych.
- Poczekaj na pełny render strony w serwisach ciężkich od JavaScriptu. Daj im kilka dodatkowych sekund przed uruchomieniem scrapingu.
- Zacznij od małej próbki. Sprawdź liczbę wierszy na 2–3 stronach, zanim uruchomisz paczkę 500 stron.
Przejście na ręczne selektory CSS
Gdy wizualne zaznaczanie nadal zawodzi, czas przejść na tryb ręczny. To właśnie ten ruch, który odróżnia zwykłych użytkowników od skutecznych.
Oto proces:
- Kliknij prawym przyciskiem myszy element, którego chcesz użyć w Chrome → Inspect.
- W DevTools zidentyfikuj nazwę klasy elementu lub atrybut danych (np.
.product-card .pricealbo[data-test="location"]). - W Simplescraper przejdź do zakładki i wklej swój selektor.
- Przetestuj selektor, uruchamiając małe scrapowanie.
Wskazówki dotyczące solidnych selektorów:
- Preferuj nazwy klas (
.listing-title) zamiast selektorów pozycyjnych (div:nth-child(3)) - Używaj , gdy są dostępne — zwykle są stabilniejsze przy zmianach serwisu
- Unikaj głęboko zagnieżdżonych ścieżek, które psują się, gdy zmienia się struktura HTML strony
Alternatywa AI: pozwól Thunderbit automatycznie wykrywać pola
Powiem wprost — mój zespół zbudował właśnie dlatego, że mieliśmy dość tego samego problemu. Funkcja Thunderbit „AI Suggest Fields” odczytuje strukturę strony i automatycznie rekomenduje kolumny oraz logikę ekstrakcji. Nie potrzebujesz znajomości CSS. AI dopasowuje się do układu każdej strony, także do zagnieżdżonej treści i obrazów ładowanych leniwie.
Jeśli spędzasz więcej niż kilka minut na jednym scrapie na debugowaniu selektorów, warto całkiem spróbować innego podejścia.
Najlepsza praktyka 2: Wybór między scrapowaniem w chmurze a w przeglądarce
Większość użytkowników Simplescraper wybiera tryb domyślnie — zwykle ten, który wypróbowali jako pierwszy — bez zastanowienia, czy dany tryb pasuje do ich rzeczywistego przypadku użycia. To prowadzi do możliwych do uniknięcia błędów.
Kiedy używać scrapowania w przeglądarce (lokalnie)
- Strony wymagające logowania: LinkedIn, panele CRM, wewnętrzne narzędzia — wszystko za uwierzytelnieniem wymaga aktywnej sesji przeglądarki.
- Szybkie jednorazowe ekstrakcje: Już jesteś na stronie, po prostu chcesz teraz pobrać dane.
- Oszczędzanie darmowych kredytów: Scrapowanie w przeglądarce nie zużywa kredytów chmurowych.
Minus: komputer musi być włączony, a duże zadania działają wolniej niż w chmurze.
Kiedy używać scrapowania w chmurze
- Strony publiczne (listingi e-commerce, katalogi, serwisy nieruchomości), gdzie logowanie nie jest potrzebne.
- Zaplanowane monitorowanie: Działa bez nadzoru, cyklicznie.
- Zadania wsadowe: w jednej paczce w chmurze.
- Dostarczanie do integracji: Automatyczne wysyłanie do Google Sheets, Airtable lub webhooków.
Minus: scrapowanie w chmurze — 2 za stronę z JavaScriptem, 1 za stronę bez JS — i szybko zużywa 100-kredytowy limit darmowego planu.
Ramy decyzyjne
| Scenariusz | Zalecany tryb | Dlaczego | Ryzyko, jeśli wybierzesz źle |
|---|---|---|---|
| Strony wymagające logowania (LinkedIn, panele) | Browser | Wymaga uwierzytelnionej sesji | Tryb Cloud natrafi na ścianę logowania |
| Publiczne listingi produktów e-commerce | Cloud | Szybszy, działa bez nadzoru | Tryb Browser blokuje Twój komputer |
| Zaplanowane, cykliczne monitorowanie | Cloud | Działa bez Twojego udziału | Browser wymaga Twojej obecności |
| Serwisy z silnym anty-botem (Amazon, Yelp) | Browser (awaryjnie) lub Cloud z proxy | Potrzebna rotacja IP albo ponowne użycie sesji | Cloud bez proxy szybko zostanie zablokowany |
| Szybka jednorazowa ekstrakcja | Browser | Natychmiastowo, bez kosztu kredytów | Konfigurowanie chmury dla jednej strony to przesada |

Jak Thunderbit upraszcza ten wybór
W wybór to po prostu przełącznik w tym samym interfejsie. Tryb Cloud przetwarza do 50 stron jednocześnie — bez osobnego płatnego planu za dostęp do chmury. Tryb Browser obsługuje strony wymagające logowania bez dodatkowej konfiguracji. Mentalny ciężar pytania „którego trybu potrzebuję?” wyraźnie maleje, gdy oba tryby żyją w tym samym procesie.
Najlepsza praktyka 3: Jak najlepiej wykorzystać darmowy plan Simplescraper
Zamieszanie wokół cen jest realne. Widziałem posty na forach, w których ludzie zakładali, że „darmowe rozszerzenie Chrome” oznacza „wszystko za darmo”. To nie tak działa. Z drugiej strony widziałem też osoby przekonane, że Simplescraper jest drogi, bo płatne plany nie są wyraźnie pokazane. Żadne z tych założeń nie pomaga.
Co faktycznie zawiera darmowy plan Simplescraper
Zgodnie z :
- Scrapowanie w przeglądarce: bez limitu (działa lokalnie w Chrome)
- Kredyty chmurowe: 100 miesięcznie
- Zapisane recepty: 3
- Formaty eksportu: CSV i JSON
- Czego NIE zawiera: priorytetowego wsparcia, zaawansowanych opcji proxy, większych limitów kredytów chmurowych
Realistyczny scenariusz darmowego planu
Załóżmy, że chcesz pobrać 50 stron produktowych z publicznego sklepu internetowego.
- Tryb Browser (darmowy): Możesz zrobić to całkowicie za darmo. Otwórz każdą stronę (albo użyj listy), uruchom receptę, wyeksportuj do CSV. Czas potrzebny zależy od cierpliwości i prędkości internetu, ale przy ręcznej nawigacji dla 50 stron licz około 15–30 minut aktywnej pracy.
- Tryb Cloud (darmowy plan): Jeśli renderowanie JavaScriptu jest włączone, każda strona kosztuje 2 kredyty. 50 stron = 100 kredytów. To cały miesięczny limit chmurowy w jednym zadaniu. Bez harmonogramu, bez ponownych prób, jeśli coś się nie powiedzie.
Darmowy plan jest naprawdę użyteczny przy małych, okazjonalnych ekstrakcjach. Ale szybko się kończy, gdy potrzebujesz automatyzacji w chmurze albo większej skali.
Porównanie darmowych planów: Simplescraper vs. Thunderbit
| Funkcja | Simplescraper Free | Thunderbit Free |
|---|---|---|
| Strony / kredyty | Bez limitu w przeglądarce + 100 kredytów chmurowych | 6 stron z pełnymi funkcjami AI |
| Ekstrakcja oparta na AI | Ograniczona (Smart Extract zużywa kredyty) | Pełne AI Suggest Fields w zestawie |
| Miejsca eksportu | CSV, JSON | Excel, Google Sheets, Airtable, Notion — wszystko za darmo |
| Zapisane konfiguracje | 3 recepty | Dostępne szablony |
| Scrapowanie podstron | Ręczna konfiguracja recepty | Wliczone w liczbę stron |
Modele są naprawdę różne. Simplescraper daje nieograniczone lokalne scrapowanie przy ograniczonej chmurze. daje mniej stron, ale każda z nich ma pełną moc AI, a do tego darmowy eksport do narzędzi, z których zespoły faktycznie korzystają. Darmowy plan Simplescraper działa, jeśli potrzebujesz podstawowego lokalnego scrapowania i nie przeszkadza Ci ręczna praca. Ale jeśli chcesz ekstrakcji wspieranej przez AI z elastycznym eksportem, darmowy plan Thunderbit daje więcej na jedną stronę.
Najlepsza praktyka 4: Jak unikać blokad podczas scrapowania
Nikt nie myśli o zabezpieczeniach anty-bot, dopóki nie patrzy na ścianę CAPTCHA albo pusty zbiór danych. Wtedy czas i być może kredyty są już spalone.
Profilaktyka jest zawsze tańsza niż późniejsze rozwiązywanie problemów.
Ustal limity i tempo żądań
Najczęstszy powód blokady: zasypywanie strony zbyt szybkim tempem żądań. Dla serwera WWW 50 żądań w 10 sekund z jednego IP wygląda jak atak, a nie jak ciekawy badacz.
Ogólne zasady:
- Dodawaj 2–5 sekund między żądaniami stron w większości serwisów komercyjnych.
- W przypadku wrażliwych celów (marketplace'y, serwisy z recenzjami) zwolnij jeszcze bardziej — 5–10 sekund.
- Jeśli używasz API Simplescraper, parametr może pomóc upewnić się, że strona w pełni się załadowała przed ekstrakcją, co naturalnie spowalnia też tempo.
Kiedy włączyć rotację proxy
Rotacja proxy zmienia adres IP między żądaniami, dzięki czemu wyglądasz jak wielu różnych użytkowników. Będzie Ci potrzebna w przypadku:
- Amazon, Yelp, TripAdvisor, LinkedIn (agresywne systemy anty-bot)
- każdego serwisu ograniczającego liczbę żądań na IP
- dużych zadań wsadowych (setki stron z jednej domeny)
Platforma Simplescraper , w tym standardowe, premium i residential. Jednak dokładna dostępność zależnie od planu nie zawsze jest jasno opisana w publicznej dokumentacji — sprawdź to, zanim założysz, że darmowy plan obsługuje trudne cele. Proxy residential zwykle kosztują więcej, ale rzadziej są oznaczane jako podejrzane.
Obsługa stron ciężkich od JavaScriptu
Nowoczesne serwisy zbudowane w React, Vue lub Angularze renderują treść po początkowym załadowaniu strony. Jeśli scraper zadziała, zanim JavaScript skończy się wykonywać, dostaniesz puste pola.
Strategie:
- Używaj trybu scrapowania w chmurze dla lepszego renderowania (chmura Simplescraper potrafi wykonywać JavaScript).
- Ręcznie przewiń stronę przed uruchomieniem scrapingu w przeglądarce, aby wywołać treści ładowane leniwie.
- Używaj
waitForSelectorw przepływach opartych na API, aby zatrzymać się, dopóki nie pojawią się docelowe elementy. - Zaakceptuj, że niektóre silnie dynamiczne aplikacje typu single-page mogą po prostu wykraczać poza to, co wizualny scraper jest w stanie niezawodnie obsłużyć.
Alternatywa bezobsługowa
automatycznie radzi sobie z ochroną anty-bot, CAPTCHA i renderowaniem JavaScriptu — bez konfiguracji proxy, bez strojenia opóźnień, bez ręcznego przewijania. Dla użytkowników, którzy nie chcą zamieniać się w amatorskich inżynierów DevOps tylko po to, by pobrać katalog produktów, ma to znaczenie. Problemy nie znikają — po prostu stają się problemem kogoś innego.
Najlepsza praktyka 5: Rozpoznaj, kiedy Simplescraper osiągnął swoje granice
Szkoda, że ktoś nie napisał mi tej sekcji dwa lata temu.
Jest moment, w którym narzędzie przestaje oszczędzać czas, a zaczyna go pożerać. Wczesne rozpoznanie tego progu chroni przed pułapką utopionych kosztów: „Zbudowałem już 15 recept, teraz nie mogę się przesiąść”.
Praktyczne ograniczenia Simplescraper
- Dynamiczne aplikacje typu single-page, które ładują treść przez AJAX bez tradycyjnej nawigacji między stronami
- Nieskończone przewijanie, które wymaga ciągłego scrollowania, aby wczytać wszystkie elementy (a nie standardowej paginacji opartej na klikaniu)
- Wzbogacanie podstron: scrapowanie strony listy, a następnie odwiedzanie każdej strony szczegółów w celu pobrania dodatkowych danych. Simplescraper potrafi to zrobić dzięki , ale złożoność konfiguracji szybko rośnie.
- Zmiany układu strony, które psują istniejące recepty. Gdy serwis aktualizuje strukturę HTML, starannie dopracowane selektory CSS przestają działać.
Sygnały, że narzędzie już Ci nie wystarcza
Prawdopodobnie osiągnąłeś limit, gdy:
- Ręcznie poprawiasz selektory CSS przy każdym scrapowaniu, bo automatyczne wykrywanie ciągle zawodzi
- Recepty psują się po aktualizacjach serwisu i trzeba je przebudowywać
- Musisz scrapować dziesiątki lub setki stron jednocześnie, ale stale wpadasz na limity kredytów lub prędkości
- Dane z podstron wymagają złożonych, wieloetapowych łańcuchów recept
- Spędzasz więcej czasu na utrzymywaniu scrapów niż na faktycznym korzystaniu z wyekstrahowanych danych
To ostatnie jest najjaśniejszym sygnałem. Gdy utrzymanie staje się pracą, znika korzyść wygody no-code.
Przejście na workflow wspierany przez AI
Tu chcę opowiedzieć o tym, co mój zespół zbudował w , bo zostało zaprojektowane właśnie z myślą o trybach awarii opisanych powyżej:

- AI odczytuje każdą stronę na nowo za każdym razem — bez kruchych recept i selektorów CSS do utrzymywania. Jeśli serwis zmieni układ, AI dopasuje się przy następnym uruchomieniu.
- Scrapowanie podstron wzbogaca Twoją tabelę danych jednym kliknięciem. Najpierw pobierz listę, potem automatycznie odwiedź każdą stronę szczegółów po dodatkowe pola.
- Zaplanowane scrapowanie przy użyciu języka naturalnego („w każdy poniedziałek o 9:00”) zamiast konfigurowania gotowych presetów czasu.
- Cloud scraping do 50 stron jednocześnie dla większej prędkości na publicznych stronach.
- Natywny darmowy eksport do Google Sheets, Airtable, Notion i Excela bez konfiguracji webhooków.
Simplescraper vs. Thunderbit: porównanie obok siebie
Oto wszystko w jednym miejscu:

| Możliwość | Simplescraper | Thunderbit |
|---|---|---|
| Konfiguracja pól | Ręczne selektory CSS / wybór wizualny | AI Suggest Fields (zwykły angielski) |
| Wzbogacanie podstron | Możliwe przez workflow wsadowe (złożona konfiguracja) | Automatyczne wzbogacanie jednym kliknięciem |
| Automatyczne dopasowanie do zmian układu | Psuje się (wymaga ręcznej naprawy) | AI odczytuje strukturę strony za każdym razem |
| Równoległość stron w chmurze | Do 5000 adresów URL w paczce (zależnie od planu) | 50 stron jednocześnie |
| Eksport do Notion/Airtable | Przez webhook (płatne plany) | Natywnie, za darmo |
| Harmonogram | Presety + własne ustawienia czasu | Opis w języku naturalnym |
| Obsługa anty-bot / CAPTCHA | Dostępne tryby proxy (zależnie od planu) | Automatyczna, bez konfiguracji |
| Darmowy plan | 100 kredytów chmurowych + nielimitowany Browser + 3 recepty | 6 stron z pełnymi funkcjami AI + darmowy eksport |
Krótko mówiąc: Simplescraper błyszczy przy prostych, wizualnych, mało skomplikowanych ekstrakcjach, gdzie od czasu do czasu ręczne poprawki są akceptowalne. Thunderbit przejmuje tam, gdzie ten model zaczyna się rozpadać — obsługując interpretację strony, adaptację układu i złożoność workflow, żebyś Ty nie musiał.
Żadne narzędzie nie jest uniwersalnie lepsze. Siedzą na różnych punktach krzywej złożoności — i to jest w porządku.
Szybka ściągawka: lista najlepszych praktyk dla Simplescraper
Zapisz to na następną sesję scrapowania:
- Zawsze najpierw testuj na małej próbce. Sprawdź liczbę wierszy i kompletność pól na 2–3 stronach przed skalowaniem.
- Przewiń stronę przed scrapowaniem, aby uruchomić treści ładowane leniwie.
- Używaj „Include Similar”, gdy wykrywanie listy wydaje się zbyt wąskie.
- Świadomie wybieraj tryb scrapowania. Browser dla stron wymagających logowania; Cloud dla stron publicznych i zadań harmonogramowanych.
- Ustaw opóźnienia między żądaniami — minimum 2–5 sekund dla serwisów komercyjnych, więcej dla celów z silnym anty-botem.
- Znasz już matematykę darmowego planu. 100 kredytów chmurowych = 50 stron z JavaScriptem. Planuj odpowiednio.
- Zapisuj recepty tylko dla stabilnych stron. Jeśli serwis często się aktualizuje, recepty będą się psuć.
- Naucz się podstaw selektorów CSS jako planu awaryjnego. Nazwy klas i atrybuty danych są lepsze niż selektory pozycyjne.
- Monitoruj blokady proaktywnie. Jeśli dostajesz puste wyniki albo CAPTCHA, zwolnij albo zmień tryb.
- Rozpoznaj moment graniczny. Gdy czas utrzymania przewyższa czas korzystania z danych, oceń alternatywy.
Podsumowanie: niech każda ekstrakcja ma znaczenie
Najważniejsza lekcja z ponad tysiąca ekstrakcji nie dotyczy żadnego konkretnego narzędzia. Chodzi o to, że podejście ma większe znaczenie niż oprogramowanie. Zrozumienie, dlaczego ekstrakcja się nie udaje — lazy loading, zły tryb, agresywny anty-bot, kruche selektory — jest cenniejsze niż jakakolwiek lista funkcji.
Simplescraper naprawdę dobrze działa przy prostych zadaniach ekstrakcji. Jeśli Twoje strony są czyste, potrzeby umiarkowane i nie przeszkadzają Ci okazjonalne ręczne poprawki — dostarcza wynik.
Ale jeśli częściej walczysz z narzędziem, niż z niego korzystasz — debugujesz selektory, przebudowujesz zepsute recepty, konfigurujesz proxy, ręcznie przewijasz strony — to nie jest porażka osobista, tylko sygnał. Oznacza, że wyrósł już ponad to, co samo wizualne scrapowanie potrafi niezawodnie obsłużyć.
Jeśli brzmi to znajomo, wypróbuj — sześć stron z pełnymi funkcjami AI, darmowy eksport do Sheets, Airtable i Notion. Porównaj go ze swoim obecnym workflow i zobacz, co zadziała najlepiej. Czasem najlepszą praktyką jest wiedzieć, kiedy sięgnąć po zupełnie inne narzędzie.
FAQ
Czy Simplescraper jest darmowy?
Tak, Simplescraper ma darmowy plan obejmujący nielimitowane lokalne scrapowanie w przeglądarce, , 3 zapisane recepty oraz eksport CSV/JSON. Strony chmurowe z JavaScriptem kosztują 2 kredyty każda, więc te 100 kredytów wystarcza na około 50 stron w trybie chmurowym. Płatne plany zaczynają się od 39 USD/mies. (Plus) za 6000 kredytów i 70 USD/mies. (Pro) za 15 000 kredytów.
Czy Simplescraper radzi sobie ze stronami ciężkimi od JavaScriptu?
Czasami tak. Tryb Cloud w Simplescraper potrafi renderować JavaScript, a narzędzie deklaruje obsługę aplikacji typu single-page. Jednak złożone SPA z mocnym dynamicznym renderowaniem, nieskończonym przewijaniem lub agresywnymi systemami anty-bot nadal mogą dawać niepełne wyniki. Użycie trybu Cloud z odpowiednimi czasami oczekiwania poprawia niezawodność, ale silnie dynamiczne strony pozostają wyzwaniem dla każdego wizualnego scrapera.
Jaka jest różnica między scrapowaniem chmurowym a przeglądarkowym w Simplescraper?
Scraping w przeglądarce działa lokalnie w Twoim Chrome — korzysta z aktywnej sesji (świetne dla stron wymagających logowania), nie zużywa kredytów, ale wymaga, by komputer był włączony. działa na serwerach Simplescraper — jest szybszy, działa bez nadzoru, wspiera harmonogramy i integracje, ale kosztuje kredyty za stronę i nie ma dostępu do stron za Twoim osobistym logowaniem.
Kiedy powinienem przejść z Simplescraper na alternatywę, taką jak Thunderbit?
Najbardziej oczywistym sygnałem jest to, że czas utrzymania przekracza czas korzystania z danych. Jeśli regularnie naprawiasz uszkodzone selektory po aktualizacjach strony, ręcznie konfigurujesz proxy, przebudowujesz recepty albo spędzasz więcej czasu na rozwiązywaniu problemów niż na analizie pobranych danych, to znaczy, że wyrósłeś już poza to, co ręczne wizualne scrapowanie może efektywnie dostarczyć. Narzędzia takie jak , które używają AI do interpretacji struktury strony przy każdym uruchomieniu, eliminują większość tego obciążenia.
Jak uniknąć blokad podczas scrapowania w Simplescraper?
Trzy kluczowe praktyki: Po pierwsze, rozłóż żądania w czasie, stosując opóźnienie 2–5 sekund między stronami (dłużej w serwisach z silnym anty-botem, takich jak Amazon czy Yelp). Po drugie, używaj trybu Browser jako planu awaryjnego dla stron, które agresywnie blokują chmurowe IP — sesja przeglądarki wygląda bardziej jak normalny ruch. Po trzecie, włącz rotację proxy przy dużych zadaniach wsadowych na wrażliwych celach, choć zanim zaczniesz na tym polegać, sprawdź, które opcje proxy obejmuje Twój plan.
Dowiedz się więcej