Pixiv Webscraper
Vertrouwd door professionals bij toonaangevende bedrijven














Pixiv-data scrapen, simpel gemaakt
Extraheer Pixiv-data zoals titels, auteurs en sectiedetails zonder handmatig kopiëren en plakken.
Scrape Pixiv-data in bulk op schaal
Pixiv-data handmatig pagina voor pagina verzamelen gaat al snel traag, zeker als je tientallen of honderden titels, samenvattingen, auteurs, publicatiedatums, nieuwsbronnen en secties nodig hebt. Met Thunderbit kun je in één keer een lijst met URL’s scrapen, zodat je van een paar pagina’s naar een grote set Pixiv-records kunt gaan zonder tijd te verspillen aan repetitief werk.

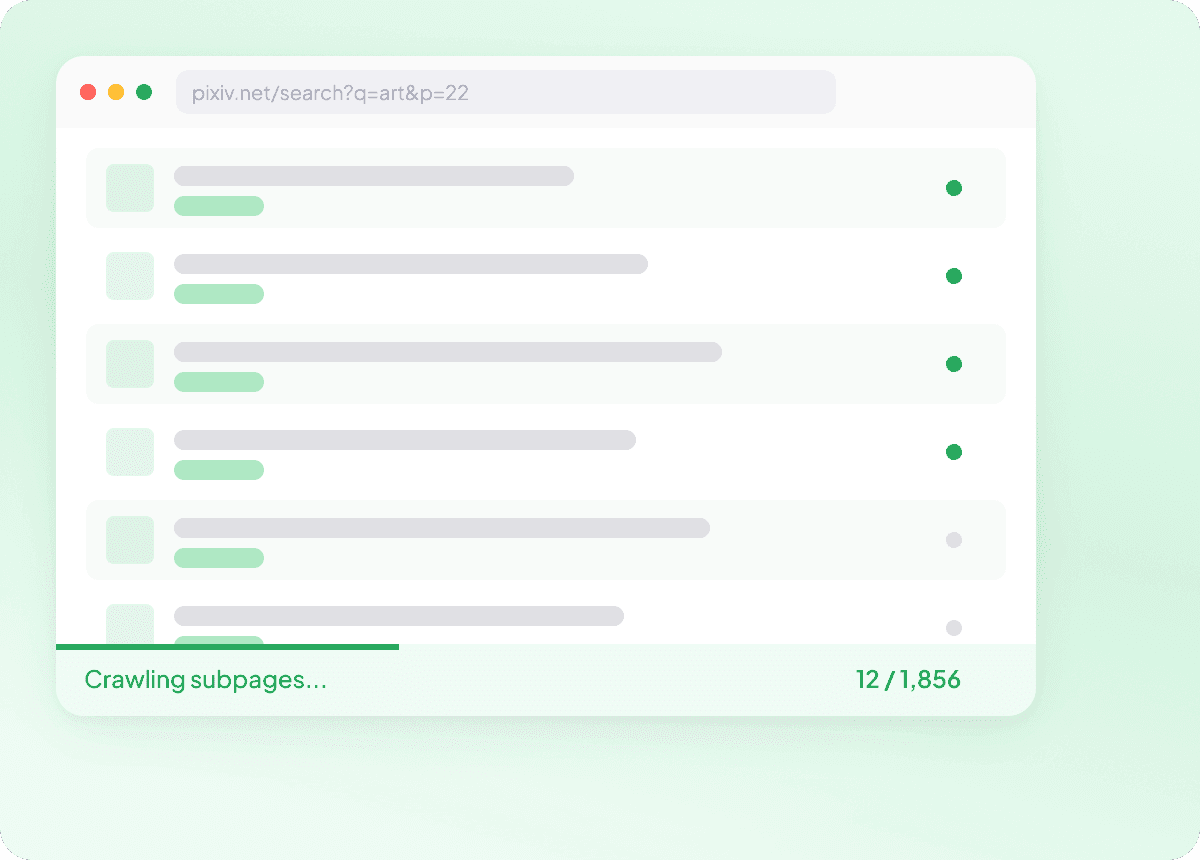
Leg volledige details van Pixiv-subpagina’s vast
Overzichtspagina’s op Pixiv tonen vaak alleen de basis, terwijl de echte details op elke artikel- of post-subpagina staan. Thunderbit bezoekt elke gelinkte subpagina en haalt het volledige beeld op, waardoor je rijkere data krijgt zoals samenvatting, auteur, publicatiedatum, nieuwsbron en sectie in een nette structuur.
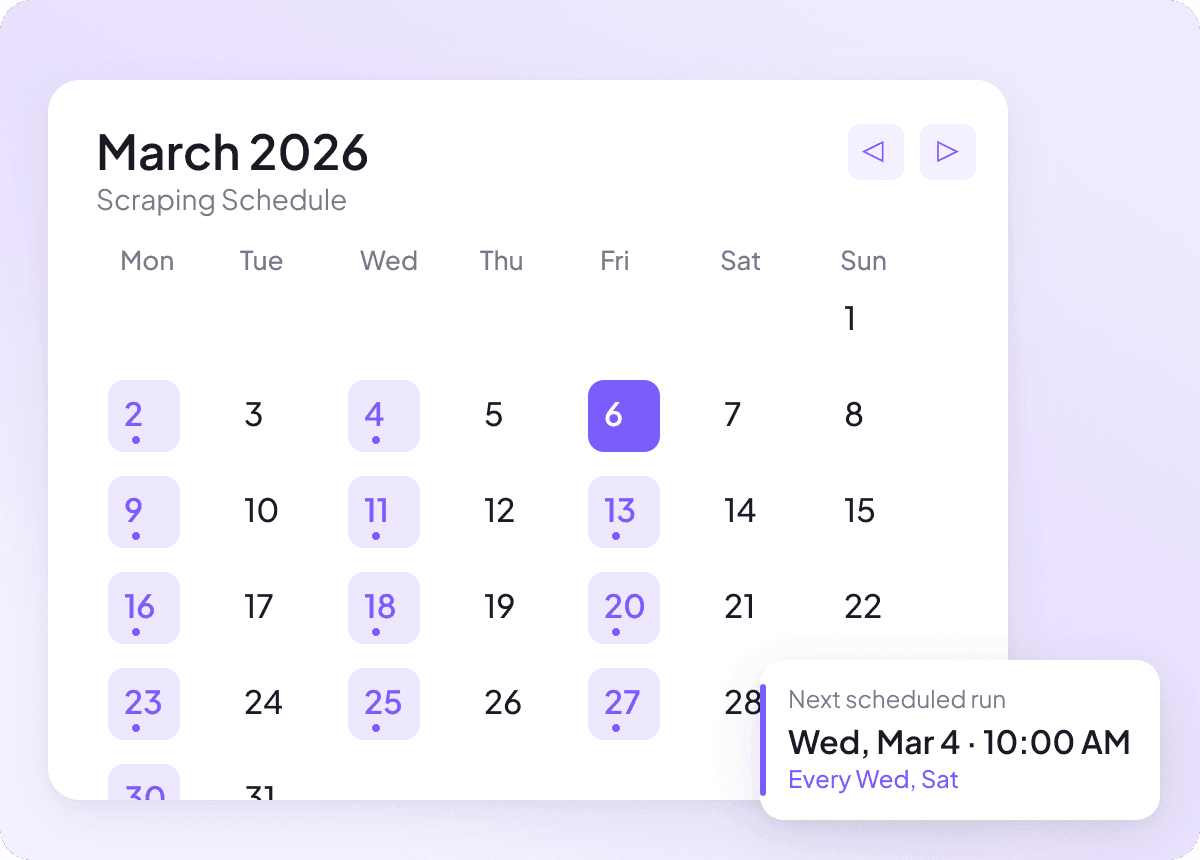
Houd Pixiv-data automatisch actueel
Pixiv-content kan dagelijks veranderen, en handmatig bijhouden betekent steeds opnieuw dezelfde pagina’s controleren. Met geplande scraping draait Thunderbit op de automatische piloot en levert het regelmatig verse Pixiv-data aan je spreadsheet, zodat je tracking van titel, auteur en sectie actueel blijft zonder dat je ernaar hoeft om te kijken.
Waarom is Thunderbit anders dan traditionele pixiv scrapers?
Een simpelere manier om Pixiv te scrapen zonder fragiele selectors of opschoning.
Traditionele scrapers
De oude manier van werkenThunderbit AI
De slimmere aanpakNeem niet alleen ons woord ervoor
Zie wat onze gebruikers over Thunderbit zeggen.





Veelgestelde vragen
Gerelateerd use cases
Ontdek meer use cases van Thunderbit's webscraper.
On the Beach Webscraper
Met de Thunderbit On the Beach Webscraper haal je moeiteloos vakantie- en hoteloverzichten, prijzen, beoordelingen en meer van On the Beach binnen, allemaal in slechts twee klikken. Dankzij AI-gestuurde veldsuggesties verzamel en orden je snel reisinformatie voor analyse, vergelijking of reisplanning. Perfect voor reisprofessionals, analisten en vakantieplanners.
Meer leren ->
ReverseAustralia Webscraper
Met de Thunderbit ReverseAustralia-webscraper kun je eenvoudig gegevens verzamelen van klacht- en reactiepagina's op ReverseAustralia. Dankzij AI-gestuurde veldsuggesties verzamel je razendsnel telefoonnummers, klachtomschrijvingen, reacties, gebruikersnamen en meer voor analyse of onderzoek. Perfect voor marketeers, onderzoekers en bedrijven die gestructureerde feedbackdata zoeken.
Meer leren ->
White Pages Webscraper
Met de Thunderbit White Pages-scraper kun je moeiteloos gegevens uit White Pages-telefoon- en bedrijfsvermeldingen halen dankzij AI-gestuurde veldsuggesties. Verzamel snel namen, telefoonnummers, adressen en website-URL’s voor leadgeneratie, marketing of onderzoek – allemaal in een paar klikken.
Meer leren ->
Rakuten Travel Webscraper
Met de Thunderbit Rakuten Travel Webscraper kun je moeiteloos gegevens verzamelen van hotelvermeldingen en detailpagina’s op Rakuten Travel. Dankzij AI-gestuurde veldsuggesties verzamel je snel hotelnamen, prijzen, beoordelingen, kamertypes en voorzieningen – ideaal voor onderzoek of reisplanning. Perfect voor reisagenten, onderzoekers en bedrijven die gestructureerde reisdata nodig hebben.
Meer leren ->
TripAdvisor Bedrijfsvermeldingen Webscraper
Met de Thunderbit TripAdvisor Bedrijfsvermeldingen Webscraper kun je eenvoudig gegevens verzamelen uit TripAdvisor bedrijfsvermeldingen, de resource hub en het eigenarenforum. Dankzij AI-gestuurde veldsuggesties verzamel je razendsnel resource-namen, URL's, beschrijvingen, forumonderwerpen, auteurs en forumberichten voor onderzoek, marketing of analyse.
Meer leren ->
People-Search Webscraper
Met de Thunderbit People-Search Webscraper kun je gestructureerde data verzamelen van People-Search profielen en reverse phone lookup pagina’s. Dankzij AI-gestuurde veldsuggesties verzamel je razendsnel namen, locaties, telefoonnummers, e-mails en meer – ideaal voor onderzoek, marketing of leadgeneratie. Perfect voor marketeers, onderzoekers en bedrijven die op zoek zijn naar openbare gegevens en contactinformatie.
Meer leren ->Klaar om je data-extractie een boost te geven?
Sluit je aan bij meer dan 100.000 professionals die Thunderbit al gebruiken om hun webscraping-workflows te automatiseren.
De gratis proefperiode biedt onbeperkte credits voor 8 webpagina's.