Substack-scraper

Vertrouwd door professionals bij toonaangevende bedrijven














Ontgrendel Substack-gegevens met Thunderbit
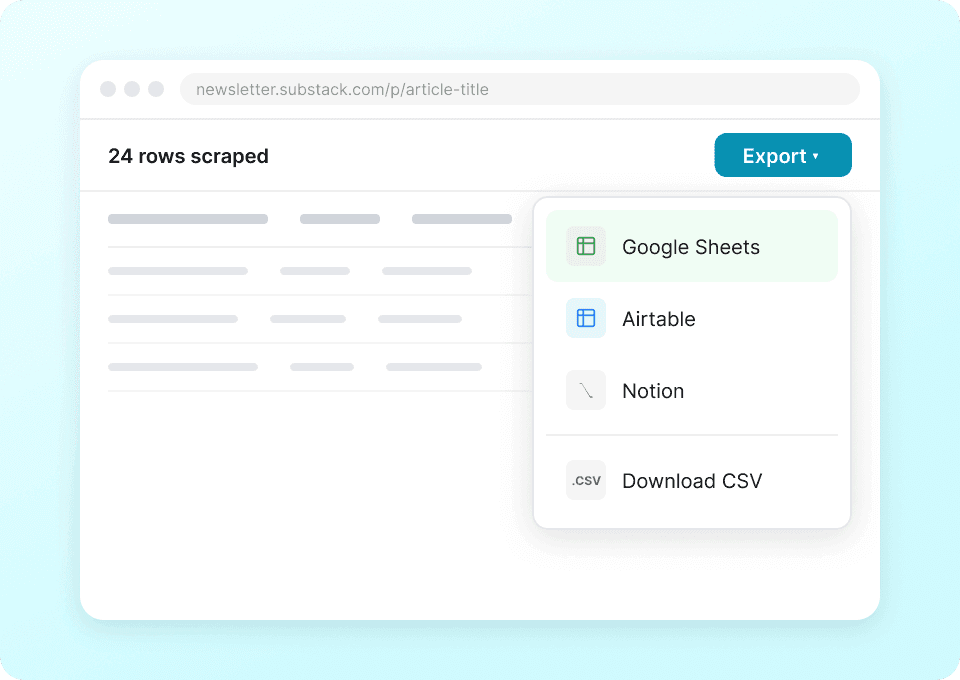
Stuur Substack-gegevens rechtstreeks naar je apps
Stop met het handmatig kopiëren en plakken van Substack-publicatiegegevens zoals auteursnaam, artikeltitel en aantal abonnees. Met Thunderbit stuur je met één klik je geëxtraheerde gegevens direct naar Google Sheets, Notion of Airtable. Analyseer publicatietrends en contentprestaties zonder het vervelende handwerk.
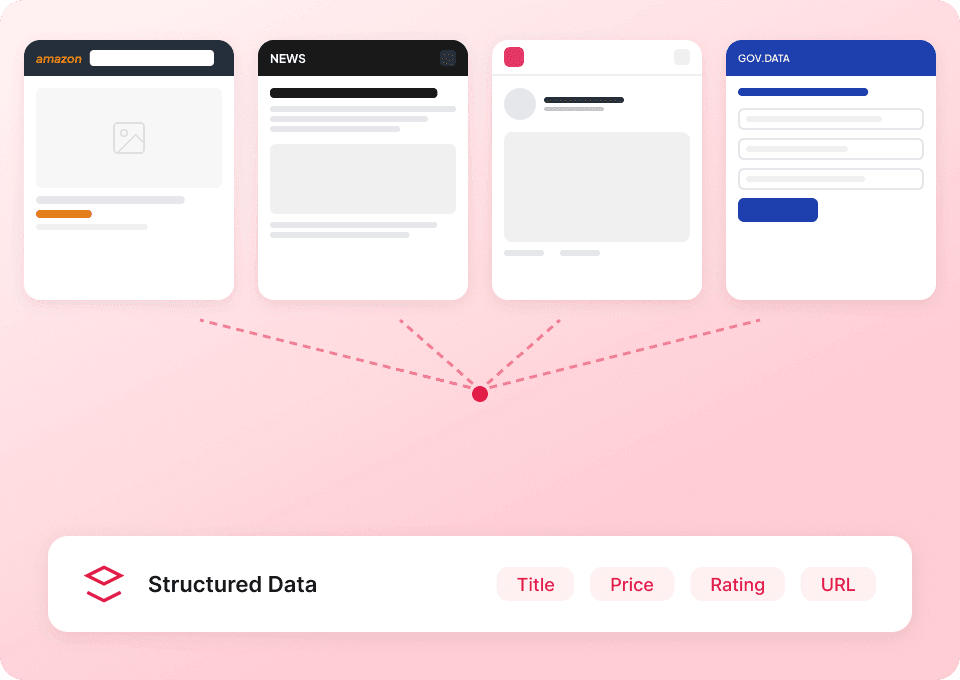
Één scraper voor Substack en daarbuiten
Blijf niet hangen in het gebruik van een andere scraper voor elke website. Thunderbit werkt meteen met Substack en bevat meer dan 50 kant-en-klare sjablonen voor andere populaire platforms. Extraheer publicatiebeschrijvingen, artikelcontent en meer, en gebruik vervolgens dezelfde tool om overal anders gegevens te verzamelen.
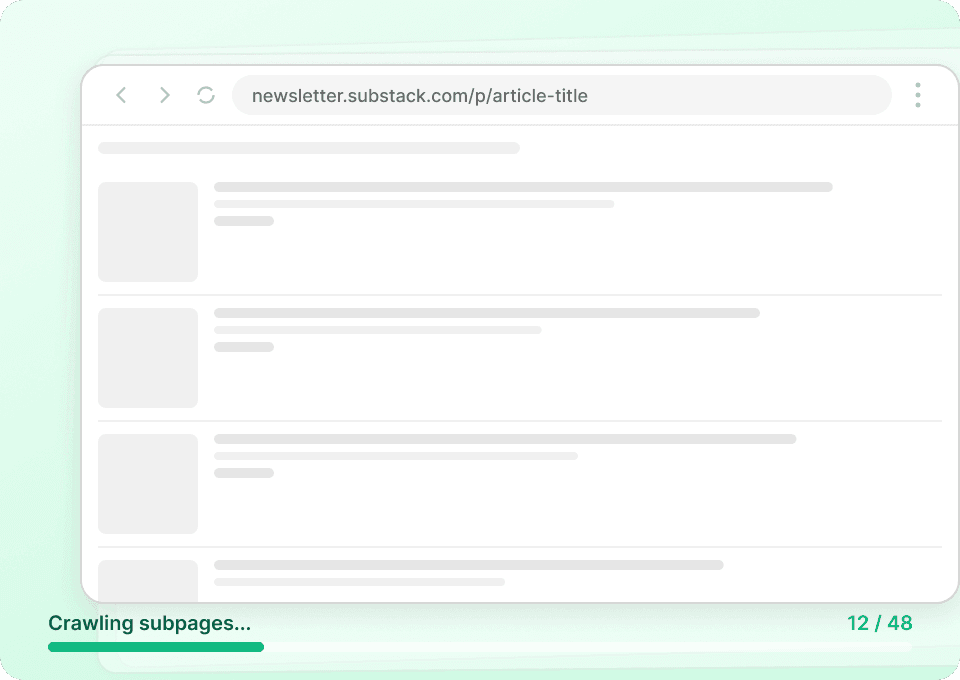
Krijg het volledige Substack-verhaal
Publicatieoverzichtspagina's van Substack tonen alleen samenvattingen. Thunderbit bezoekt automatisch elke artikel-subpagina om de volledige inhoud te extraheren, zodat je een complete dataset krijgt. Haal in één keer de volledige artikeltekst, auteursnaam, publicatienaam en artikelcontent op.
Moeite om Substack effectief te scrapen?
Zie waarom Thunderbit traditionele scrapers voor Substack-gegevens verslaat.
Traditionele scrapers
De oude manier van werkenThunderbit
De slimmere aanpakNeem niet alleen ons woord ervoor
Bekijk wat onze gebruikers over Thunderbit zeggen.








Veelgestelde vragen
Gerelateerd toepassingen
Ontdek meer toepassingen van Thunderbit’s webscraper.

HKTVmall Webscraper
Verzamel productnamen, prijzen en zelfs klantbeoordelingen uit HKTVmall-verklaringen met slechts een paar klikken — zonder ingewikkelde installatie.
Meer weten ->Tradera Webscraper
Met de Thunderbit Tradera Webscraper kun je eenvoudig gegevens verzamelen van Tradera-advertenties en productpagina’s. Dankzij AI-gestuurde veldsuggesties haal je moeiteloos productnamen, prijzen, categorieën, afbeeldingen en beschrijvingen op voor analyse of voorraadbeheer. Ideaal voor e-commerce verkopers, verzamelaars en onderzoekers die gestructureerde Tradera-data willen verzamelen.
Meer weten ->
Amarillas.com Webscraper
Met de Thunderbit Amarillas.com-webscraper kun je gestructureerde data van Amarillas.com verzamelen, zoals motels en restaurantvermeldingen. Dankzij AI-gestuurde veldsuggesties verzamel je razendsnel bedrijfsnamen, locaties, telefoonnummers, beoordelingen en reviews voor onderzoek, marketing of leadgeneratie.
Meer weten ->
Rakuten Travel Webscraper
Met de Thunderbit Rakuten Travel Webscraper kun je moeiteloos gegevens verzamelen van hotelvermeldingen en detailpagina’s op Rakuten Travel. Dankzij AI-gestuurde veldsuggesties verzamel je snel hotelnamen, prijzen, beoordelingen, kamertypes en voorzieningen – ideaal voor onderzoek of reisplanning. Perfect voor reisagenten, onderzoekers en bedrijven die gestructureerde reisdata nodig hebben.
Meer weten ->
iBegin Webscraper
Met de Thunderbit iBegin-scraper kun je eenvoudig bedrijfsresultaten en gedetailleerde bedrijfsinformatie van de iBegin-website verzamelen. Dankzij AI-gestuurde veldsuggesties verzamel je razendsnel bedrijfsnamen, contactgegevens, adressen, beoordelingen en meer – ideaal voor leadgeneratie, onderzoek of marketinganalyses.
Meer weten ->DialIndia Webscraper
Met de Thunderbit DialIndia-webscraper kun je eenvoudig gegevens halen uit de bedrijfsprofielen en reisgidsen van DialIndia, dankzij AI-gestuurde veldsuggesties. Verzamel bedrijfsnamen, contactinformatie, locaties en beschrijvingen voor onderzoek, marketing of leadgeneratie in slechts een paar klikken.
Meer weten ->Klaar om je data-extractie een boost te geven?
Sluit je aan bij 100.000+ professionals die Thunderbit al gebruiken om hun webscraping-workflows te automatiseren.
De gratis proefperiode biedt onbeperkte credits voor 8 webpagina’s.