Flickr-webscraper
Vertrouwd door professionals bij toonaangevende bedrijven














Haal Flickr-data op in twee klikken
Thunderbit maakt data-extractie van Flickr eenvoudig, zonder code.
Twee klikken naar Flickr-data
Handmatig fototitels, auteursgebruikersnamen of uploaddatums kopiëren van Flickr kost veel tijd. Met Thunderbit sla je dat heen-en-weer gekopieer gewoon over. Wijs simpelweg naar de data die je wilt — zoals de fotobeschrijving of licentietype — en onze AI doet de rest. Met twee klikken haal je data op zonder ook maar één regel code te schrijven.
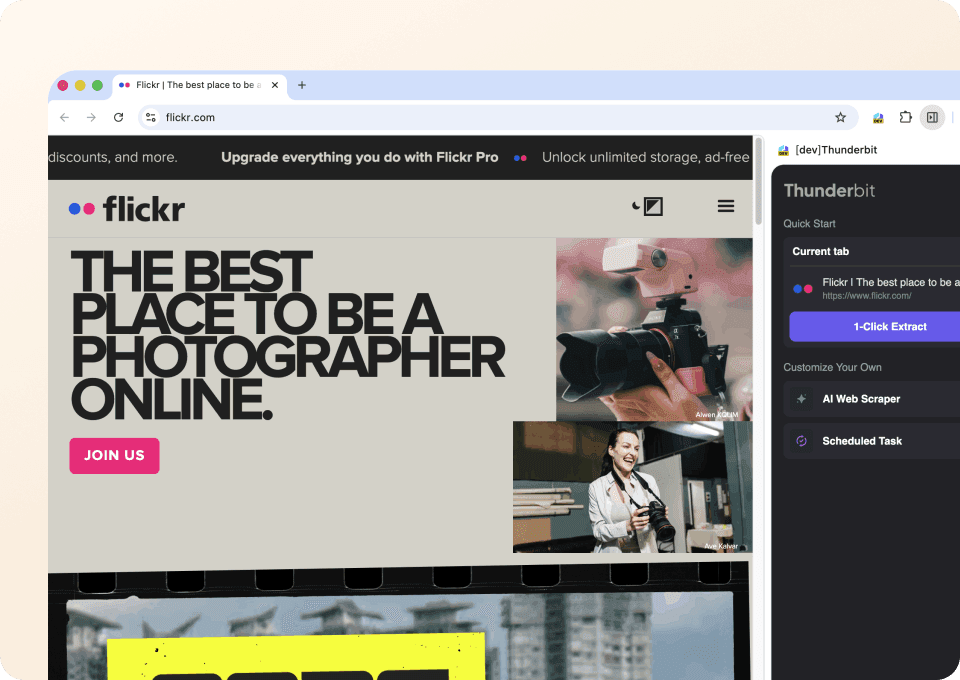
Krijg volledige fotodetails van Flickr
Flickr-zoek- of galerijpagina's tonen alleen basisinformatie. Voor het volledige plaatje heb je de details van elke afzonderlijke fotopagina nodig. Thunderbit kan automatisch elke gelinkte subpagina bezoeken, de beschrijving, tags en andere details ophalen en die als nieuwe kolommen toevoegen aan je data-export. Geen eindeloos klikken en handmatig kopiëren meer van pagina tot pagina.
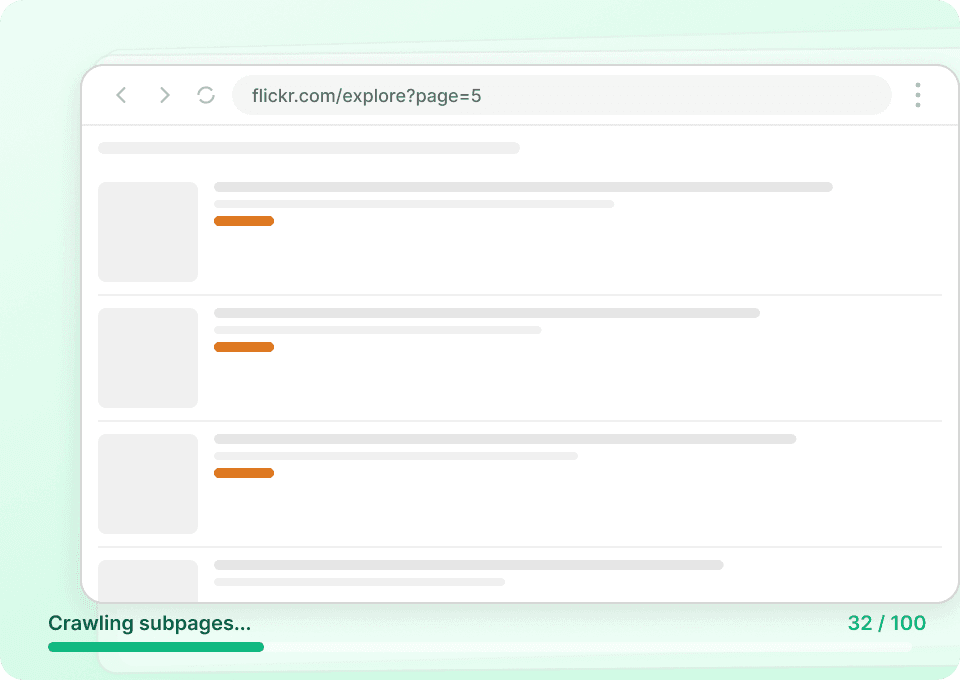
Bulk data-extractie van Flickr
Flickr één foto tegelijk scrapen is traag en onpraktisch. In plaats van handmatig door individuele pagina's te gaan en daaruit data te halen, kun je met Thunderbit meerdere Flickr-URL's invoeren. Daarna bezoekt het elke pagina, haalt het de fototitel, auteursgebruikersnaam en andere datapunten op, en bundelt het alles voor je.

Waarom is Thunderbit anders dan traditionele Flickr scrapers?
Haal data uit Flickr zonder de rompslomp van traditionele scraping.
Traditionele scrapers
De oude manier van werkenThunderbit AI
De slimmere aanpakNeem niet alleen ons woord ervoor
Zie wat onze gebruikers over Thunderbit zeggen.





Veelgestelde vragen
Gerelateerd use cases
Ontdek meer use cases van Thunderbit's webscraper.

HKTVmall Webscraper
Verzamel productnamen, prijzen en zelfs klantbeoordelingen uit HKTVmall-verklaringen met slechts een paar klikken — zonder ingewikkelde installatie.
Meer leren ->Substack-scraper
Haal abonneeaantallen, artikeltitels en publicatiebeschrijvingen van Substack in een nette spreadsheet — zonder code; de AI doet de structurering.
Meer leren ->
ReverseAustralia Webscraper
Met de Thunderbit ReverseAustralia-webscraper kun je eenvoudig gegevens verzamelen van klacht- en reactiepagina's op ReverseAustralia. Dankzij AI-gestuurde veldsuggesties verzamel je razendsnel telefoonnummers, klachtomschrijvingen, reacties, gebruikersnamen en meer voor analyse of onderzoek. Perfect voor marketeers, onderzoekers en bedrijven die gestructureerde feedbackdata zoeken.
Meer leren ->
People-Search Webscraper
Met de Thunderbit People-Search Webscraper kun je gestructureerde data verzamelen van People-Search profielen en reverse phone lookup pagina’s. Dankzij AI-gestuurde veldsuggesties verzamel je razendsnel namen, locaties, telefoonnummers, e-mails en meer – ideaal voor onderzoek, marketing of leadgeneratie. Perfect voor marketeers, onderzoekers en bedrijven die op zoek zijn naar openbare gegevens en contactinformatie.
Meer leren ->Tradera Webscraper
Met de Thunderbit Tradera Webscraper kun je eenvoudig gegevens verzamelen van Tradera-advertenties en productpagina’s. Dankzij AI-gestuurde veldsuggesties haal je moeiteloos productnamen, prijzen, categorieën, afbeeldingen en beschrijvingen op voor analyse of voorraadbeheer. Ideaal voor e-commerce verkopers, verzamelaars en onderzoekers die gestructureerde Tradera-data willen verzamelen.
Meer leren ->
TripAdvisor Bedrijfsvermeldingen Webscraper
Met de Thunderbit TripAdvisor Bedrijfsvermeldingen Webscraper kun je eenvoudig gegevens verzamelen uit TripAdvisor bedrijfsvermeldingen, de resource hub en het eigenarenforum. Dankzij AI-gestuurde veldsuggesties verzamel je razendsnel resource-namen, URL's, beschrijvingen, forumonderwerpen, auteurs en forumberichten voor onderzoek, marketing of analyse.
Meer leren ->Klaar om je data-extractie een boost te geven?
Sluit je aan bij meer dan 100.000 professionals die Thunderbit al gebruiken om hun webscraping-workflows te automatiseren.
De gratis proefperiode biedt onbeperkte credits voor 8 webpagina's.