Het internet staat bomvol data, maar die is zelden direct bruikbaar. Heb je ooit geprobeerd om handmatig prijzen van een concurrent over te typen, een lijst met leads uit een online bedrijvengids te halen, of de laatste nieuwtjes van je concurrenten bij te houden? Dan weet je hoe tijdrovend, saai en foutgevoelig dat is. Hier komen webscrapers om de hoek kijken – en daarom zijn ze tegenwoordig onmisbaar voor sales-, marketing- en operationele teams.
Sterker nog, bijna gebruikt inmiddels webscraping- of data-extractietools in hun dagelijkse processen. Of het nu gaat om concurrentieanalyse, leadgeneratie of marktonderzoek: webscrapers zijn van een nichetool uitgegroeid tot een onmisbaar zakelijk hulpmiddel. Maar wat is een scraper nu eigenlijk? Hoe werkt zo’n tool? En hoe kun je er zelf mee aan de slag – ook als je geen techneut bent? We leggen het je stap voor stap uit.
Wat is een scraper? In gewone taal
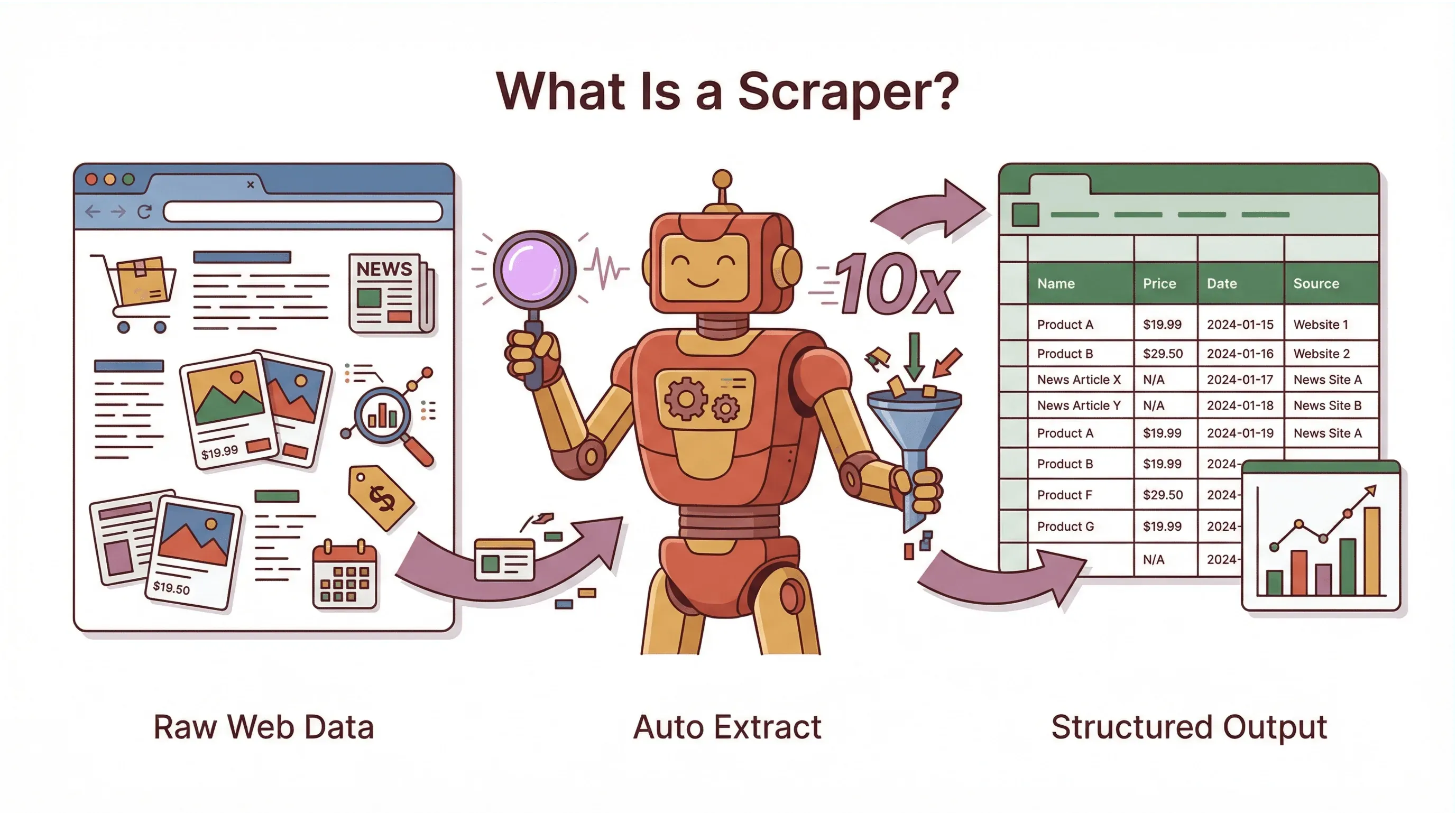 Een webscraper is een softwaretool (of soms een script) die automatisch informatie van websites haalt. Zie het als een razendsnelle, onvermoeibare digitale assistent: in plaats van zelf data van een webpagina naar een spreadsheet te kopiëren, doet de webscraper dit voor jou – supersnel en met minder fouten. Het is alsof je een stagiair hebt die nooit slaapt, nooit moppert en geen loonsverhoging vraagt.
Een webscraper is een softwaretool (of soms een script) die automatisch informatie van websites haalt. Zie het als een razendsnelle, onvermoeibare digitale assistent: in plaats van zelf data van een webpagina naar een spreadsheet te kopiëren, doet de webscraper dit voor jou – supersnel en met minder fouten. Het is alsof je een stagiair hebt die nooit slaapt, nooit moppert en geen loonsverhoging vraagt.
Om het verschil duidelijk te maken, zo passen webscrapers in het grotere plaatje van automatisering:
- Bot: Elke geautomatiseerde software die taken op internet uitvoert. Webscrapers zijn een type bot.
- Crawler: Een bot die systematisch het web afstruint, links volgt en pagina’s indexeert (zoals een zoekmachine).
- Webscraper: Een bot die zich richt op het verzamelen van specifieke data van webpagina’s – en rommelige, ongestructureerde content omzet in overzichtelijke tabellen.
Zie het web als een gigantische bibliotheek: een crawler is de bibliothecaris die alle boeken vindt, terwijl een webscraper de assistent is die de feiten die jij nodig hebt netjes voor je opschrijft.
Webscrapers zijn allang niet meer alleen voor techneuten of hackers. Ze worden breed ingezet voor legitieme zakelijke doelen: prijsvergelijkingen, verzamelen van openbare data voor onderzoek, concurrentieanalyse en meer. Het belangrijkste is dat een webscraper webdata die bedoeld is voor mensen omzet in gestructureerde informatie waar computers (en teams) direct mee aan de slag kunnen.
Hoe werkt een scraper? Van webpagina naar gestructureerde data
Laten we het proces ontrafelen. In de basis volgt een webscraper een workflow die sterk lijkt op wat een mens zou doen – alleen dan veel sneller:
- Input/Startpunt: Je geeft de webscraper een doel – meestal één of meerdere URL’s van de pagina’s waar je data van wilt halen.
- Pagina ophalen: De webscraper laadt de inhoud van de webpagina, net als je browser. Bij complexe sites kan hij zelfs de pagina “renderen” om dynamische content of oneindig scrollen aan te kunnen.
- Parsen en data herkennen: De webscraper leest de HTML-code van de pagina en zoekt naar de specifieke gegevens die je wilt – zoals productnamen, prijzen of contactinformatie. Bij traditionele webscrapers geef je precies aan waar gezocht moet worden (met “selectors” of patronen). Moderne AI-webscrapers kunnen dit vaak zelf uitzoeken.
- Extractie: Zodra de data gevonden is, haalt de webscraper deze eruit – tekst, getallen, links of afbeeldingen. Vaak wordt de data direct opgeschoond of omgezet (bijvoorbeeld “€19,99” naar een getal).
- Herhalen: Wil je data van meerdere pagina’s? De webscraper kan automatisch links volgen, door paginering bladeren of een hele lijst met URL’s verwerken.
- Output: Tot slot exporteert de webscraper de resultaten in een gestructureerd formaat – zoals CSV, Excel, Google Sheets of een database. Je hebt nu een nette tabel met bruikbare data.
Kortom: pagina bezoeken → info vinden → data halen → herhalen → exporteren. Wat een mens dagen zou kosten, doet een goede webscraper in minuten of uren.
Belangrijkste onderdelen van een webscraper
De kern bestaat uit:
- Navigator/Crawler: Vindt en laadt de pagina’s die je wilt scrapen. Regelt paginering, volgt links of werkt een URL-lijst af.
- Parser/Extractor: Leest de HTML en herkent de data die je wilt verzamelen – via regels, patronen of AI.
- Data Cleaner: Maakt de data schoon en gestructureerd (verwijdert HTML-tags, standaardiseert formaten, enz.).
- Exporter: Slaat de resultaten op in een bestand, spreadsheet of database – klaar voor analyse of gebruik.
Sommige webscrapers zijn simpele scripts, andere zijn complete platforms. Maar de basis blijft: vinden, extraheren, structureren, exporteren.
Soorten scraper-tools: Code-based vs. AI-gedreven
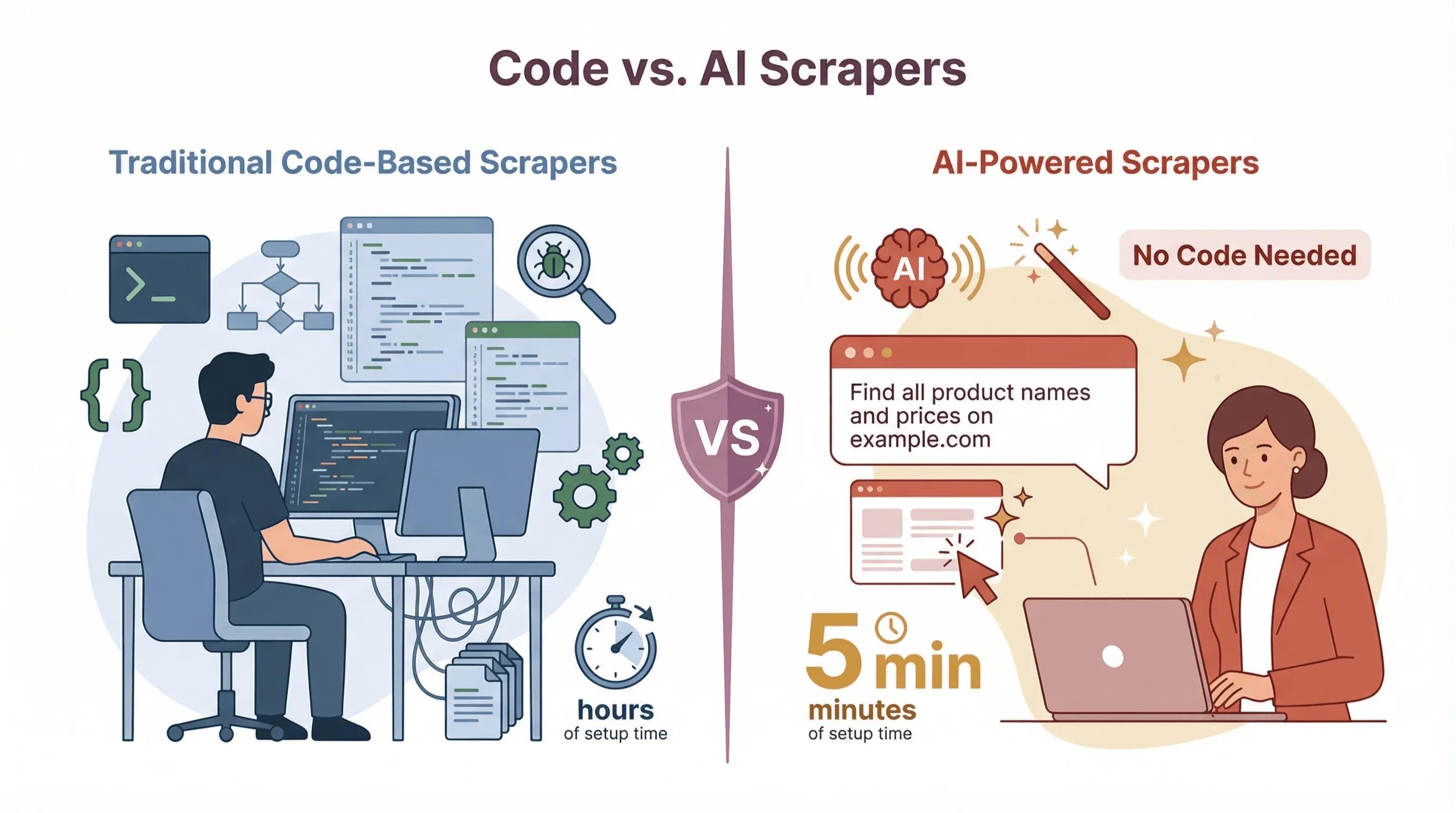 Niet elke webscraper is hetzelfde. Door de jaren heen zijn er grofweg twee hoofdtypen ontstaan:
Niet elke webscraper is hetzelfde. Door de jaren heen zijn er grofweg twee hoofdtypen ontstaan:
Traditionele code-based webscrapers
Dit zijn de klassiekers onder de webscrapers. Ze vereisen programmeerkennis – meestal in Python, JavaScript of een andere scripttaal. Jij (of je ontwikkelaar) schrijft code die precies aangeeft welke pagina’s bezocht moeten worden, welke HTML-elementen je wilt, hoe je paginering afhandelt, enzovoort.
Voordelen:
- Maximale flexibiliteit – geschikt voor vrijwel elke website of datastructuur.
- Ideaal voor maatwerk, complexe of grootschalige projecten.
Nadelen:
- Hoge technische drempel – je moet kunnen programmeren.
- Kwetsbaar – breekt snel als de website verandert.
- Veel onderhoud – scripts moeten vaak worden aangepast.
No-code en AI-gedreven webscrapers
Welkom in de toekomst. Deze tools zijn gemaakt voor zakelijke gebruikers, niet voor developers. Sommige werken met een visuele interface (point-and-click), de nieuwste generatie – zoals – gebruikt AI om zelf te bepalen wat er uit de pagina gehaald moet worden, vaak op basis van een simpele prompt in gewone taal.
Voordelen:
- Geen programmeerkennis nodig – iedereen kan ermee werken.
- Supersnel opzetten – binnen enkele minuten aan de slag.
- Slim – AI past zich aan bij veranderingen en dynamische content.
- Weinig onderhoud – minder tijd kwijt aan repareren.
Nadelen:
- Minder geschikt voor extreem specialistische taken.
- Soms beperkt door de mogelijkheden van de tool (al wordt dat snel minder).
Vergelijkingstabel: Code-based vs. AI-gedreven webscrapers
| Aspect | Code-based scrapers | AI-gedreven/no-code scrapers |
|---|---|---|
| Gebruiksgemak | Vereist programmeren | Geen code nodig |
| Snelheid opzetten | Uren tot dagen | Minuten |
| Aanpasbaarheid | Kwetsbaar – breekt bij sitewijzigingen | Adaptief – AI past zich aan |
| Onderhoud | Hoog – vaak bijwerken nodig | Laag – AI werkt zichzelf bij |
| Omgaan met dynamische content | Extra tools nodig (zoals Selenium) | AI verwerkt JS, infinite scroll ingebouwd |
| Data-nauwkeurigheid | Afhankelijk van handmatige setup | Hoog – contextbewuste extractie |
| Schaalbaarheid | Maatwerkscripts nodig voor schaal | Cloud-schaalbaarheid standaard |
| Export/Integratie | Handmatig coderen voor output | Eén klik export naar Sheets, Excel, enz. |
| Kosten | Gratis tools, maar hoge arbeidskosten | SaaS-prijzen, vaak met gratis versie |
Voor de meeste zakelijke gebruikers zijn AI-gedreven webscrapers een enorme stap vooruit – sneller, eenvoudiger en betrouwbaarder, vooral voor dagelijkse datataken.
Wanneer kies je welk type webscraper?
- Kies voor code-based als je unieke, complexe wensen hebt en een developer beschikbaar is.
- Ga voor AI/no-code als je snel wilt starten, geen programmeerkennis hebt of veel verschillende sites wilt scrapen met minimale setup.
Voor de meeste sales-, marketing- en operationele teams zijn AI-tools zoals Thunderbit de beste keuze.
Thunderbit: De nieuwe standaard voor zakelijke webscraping
Laten we kijken hoe het verschil maakt (oké, misschien niet “het spel verandert” – maar het leven wel een stuk makkelijker maakt). Thunderbit is een AI-webscraper Chrome-extensie, speciaal ontwikkeld voor zakelijke gebruikers die snel resultaat willen zonder gedoe.
Wat maakt Thunderbit uniek?
- AI Suggest Fields: Met één klik scant Thunderbit’s AI de pagina en stelt automatisch de beste kolommen voor om te extraheren (zoals “Naam”, “Prijs”, “E-mail”, enz.). Geen gedoe met HTML of selectors.
- 2-klik scraping: Na de AI-suggestie klik je op “Scrapen” en Thunderbit haalt de data op en toont het direct in een overzichtelijke tabel – klaar om te exporteren.
- Subpagina’s & paginering: Meer details nodig? Thunderbit bezoekt automatisch subpagina’s (zoals productdetails of LinkedIn-profielen) en verrijkt je tabel. Ook paginering en infinite scroll worden ondersteund.
- Cloud- of browsermodus: Scrapen in je browser (ideaal voor ingelogde sites) of via Thunderbit’s cloudservers (supersnel voor openbare sites).
- Directe datatemplates: Voor populaire sites (Amazon, Zillow, Instagram, enz.) zijn er kant-en-klare templates – direct laden en scrapen.
- Gratis, onbeperkt exporteren: Exporteer je data naar Excel, Google Sheets, Airtable, Notion of download als CSV/JSON – geen betaalmuur, zelfs niet in de gratis versie.
- AI-autovullen: Automatiseer het invullen van formulieren en repetitieve webtaken – ook gratis.
- Geplande scraping: Stel webscrapers in om automatisch te draaien (bijvoorbeeld elke ochtend), de AI regelt de timing.
- Speciale extractors: Eén-klik tools voor e-mails, telefoonnummers en afbeeldingen – ideaal voor snelle klussen.
- Meertalige ondersteuning: Thunderbit werkt in 34 talen, dus je kunt wereldwijd data scrapen.
Thunderbit wordt vertrouwd door , van zelfstandigen tot grote teams. Het is de tool die ik zelf graag had gehad toen ik nog handmatig data moest verzamelen.
Thunderbit’s belangrijkste functies uitgelegd
Wat levert het je op?
- AI Suggest Fields: Bespaart uren instellen – klik en klaar.
- Subpagina scraping: Haalt diepere data op (zoals volledige productspecificaties of contactinfo) zonder extra werk.
- Cloud vs. browser scraping: Flexibel voor elke site – openbaar of achter login.
- Directe templates: Eén klik scrapen voor bekende sites – geen setup nodig.
- Gratis data-export: Je data snel waar je het wilt hebben – zonder verborgen kosten.
Meer weten? Bekijk de of ons .
Praktische toepassingen: zo gebruiken bedrijven webscrapers
Webscrapers zijn niet alleen voor data-nerds – ze leveren echte resultaten in allerlei sectoren. Zo worden ze ingezet:
| Branche/Functie | Scraper-toepassing | Zakelijk voordeel |
|---|---|---|
| Sales & Lead Gen | Leads verzamelen uit directories, CRM-data verrijken | Grotere, actuele leadlijsten, sneller contact |
| Marketing | Blogs van concurrenten, reviews, social sentiment scrapen | Datagedreven campagnes, concurrentie-inzicht |
| E-commerce | Prijzen van concurrenten monitoren, productcatalogi bijwerken | Dynamische prijzen, beter assortiment |
| Vastgoed | Woningen verzamelen, markttrends analyseren | Snellere analyse, betere deals |
| Finance/Investering | Nieuws, rapportages, alternatieve data scrapen | Informatievoordeel, bredere analyse |
| Onderzoek/Journalistiek | Openbare registers verzamelen, trends analyseren | Grotere datasets, diepere inzichten |
Sales, marketing en e-commerce: praktijkvoorbeelden
Sales:
Een salesteam heeft een lijst nodig van winkels in hun regio. In plaats van urenlang Googlen gebruiken ze Thunderbit om een bedrijvengids te scrapen – namen, adressen, telefoonnummers, alles in een spreadsheet binnen enkele minuten. Met subpagina scraping halen ze zelfs de e-mailadressen van de eigenaren binnen.
Marketing:
Een marketingmanager wil bijhouden waar concurrenten over bloggen en wat klanten vinden. Thunderbit scrapt blogkoppen en data van concurrenten, en verzamelt reviews of tweets waarin hun merk genoemd wordt. Het team ontdekt dat 30% van de reviews van concurrenten over slechte support gaat – dus starten ze een campagne waarin hun eigen service centraal staat.
E-commerce:
Een e-commerce manager zet Thunderbit in om prijzen van 100 top-producten bij concurrenten te monitoren, elke 6 uur. Zo zien ze direct wanneer ze te duur zijn en kunnen ze snel bijsturen. Ook scrapen ze leverancierssites om hun eigen catalogus actueel te houden.
De rode draad? Tijdwinst, betere data en slimmere beslissingen.
Strategische waarde en compliance: verantwoord scrapen
Met grote scrapingkracht komt ook verantwoordelijkheid (en soms juridische aandachtspunten). Waar moet je als bedrijf op letten?
- Dataprivacy: Verzamel je persoonsgegevens (zoals e-mails of social media-profielen), houd dan rekening met privacywetgeving zoals AVG en CCPA. Beperk je tot openbare, niet-gevoelige info tenzij je een duidelijke juridische basis hebt.
- Websitevoorwaarden: Veel sites hebben regels tegen scrapen. Rechters kiezen soms de kant van webscrapers (vooral bij openbare data), maar check altijd de voorwaarden en wees voorzichtig.
- robots.txt: Dit bestand geeft aan welke delen van een site bots mogen bezoeken. Het is geen wet, maar het is netjes om het te respecteren.
- Rate limiting: Overbelast websites niet – scrape met mate, op een menselijk tempo.
- Auteursrecht: Data scrapen is één ding; het herpubliceren ervan iets anders. Beperk je tot feiten (zoals prijzen of specificaties), niet tot complete artikelen of beschermde content.
Best practices:
- Gebruik officiële API’s als die er zijn.
- Check robots.txt en de voorwaarden van de site.
- Beperk je tot openbare, niet-gevoelige data.
- Sla gescrapete data veilig op.
- Vraag juridisch advies bij grote of gevoelige projecten.
Meer weten? Lees .
Webscraper-tools: zo kies je de juiste oplossing voor jouw bedrijf
Let bij het kiezen van een webscraper op:
- Gebruiksgemak: Kan je team ermee werken zonder te programmeren?
- Schaalbaarheid: Kan het de hoeveelheid data aan die je nodig hebt?
- Aanpasbaarheid: Werkt het nog als websites veranderen?
- Integratie: Kun je de data makkelijk exporteren naar waar je het nodig hebt?
- Compliance: Helpt de tool je om aan de regels te voldoen?
- Support: Is er hulp als je vastloopt?
- Kosten: Past het binnen je budget?
Een handig beslismatrixje:
| Behoefte/Situatie | Beste tooltype |
|---|---|
| Geen programmeerkennis, snel starten | AI-gedreven/no-code (Thunderbit) |
| Maatwerk, complex of groot project | Code-based (Python, Scrapy) |
| Regelmatig veranderende sites | AI-gedreven/no-code |
| Grootschalige, geautomatiseerde workflows | Cloud-based, schaalbare tools |
| Strenge compliance-eisen | Tools met compliance-functies |
Test je favoriete tool eerst in een pilot – kijk hoe het omgaat met jouw echte datavraag voordat je het breed uitrolt.
Conclusie: de toekomst van webscrapers in zakelijke data-automatisering
Webscrapers zijn een onmisbaar onderdeel geworden van moderne bedrijfsautomatisering. Ze ontsluiten verborgen webdata en maken er bruikbare inzichten van voor sales, marketing, e-commerce en meer. Dankzij AI-tools zoals kan iedereen – niet alleen developers – deze kracht benutten, vaak met slechts een paar klikken.
Nu het web steeds complexer wordt en datagedreven werken de norm is, zullen webscrapers alleen maar slimmer, sneller en beter geïntegreerd raken in dagelijkse processen. De toekomst? Zie webscrapers niet alleen als dataverzamelaars, maar als AI-assistenten die data samenvatten, categoriseren en direct inzichten leveren.
Nog nooit een moderne webscraper geprobeerd? Dit is het moment. Begin klein, werk volgens de regels en ontdek hoeveel meer je kunt bereiken als webdata direct beschikbaar is. Meer weten? Bekijk de voor meer tips, praktijkvoorbeelden en handleidingen.
Veelgestelde vragen
1. Wat is het verschil tussen een webscraper en een crawler?
Een crawler doorzoekt het web systematisch om pagina’s te vinden en te indexeren (zoals een zoekmachine). Een webscraper richt zich op het verzamelen van specifieke data van die pagina’s. Veel webscrapers hebben ook crawl-functionaliteit, maar niet elke crawler is een webscraper.
2. Is webscraping legaal?
Webscraping is toegestaan als je het verantwoord doet – beperk je tot openbare data, respecteer privacywetgeving en check de voorwaarden van websites. Vermijd het scrapen van gevoelige persoonsgegevens of auteursrechtelijk beschermde content zonder toestemming.
3. Moet ik kunnen programmeren om een webscraper te gebruiken?
Niet meer! Moderne AI-tools zoals laten je data scrapen zonder code – met een paar klikken of een simpele prompt in gewone taal.
4. Welke soorten data kan ik met een webscraper verzamelen?
Je kunt tekst, getallen, prijzen, e-mails, afbeeldingen, links en meer extraheren – eigenlijk alles wat je op een webpagina ziet. Sommige webscrapers kunnen zelfs PDF’s, afbeeldingen of subpagina’s verwerken voor nog rijkere data.
5. Hoe kies ik de juiste webscraper voor mijn bedrijf?
Kijk naar de vaardigheden van je team, de complexiteit van de sites, de hoeveelheid data, compliance-eisen en integratiemogelijkheden. Voor de meeste bedrijven bieden AI-tools zoals Thunderbit de beste mix van gebruiksgemak, snelheid en betrouwbaarheid.
Benieuwd wat een moderne webscraper voor jou kan doen? en zet webdata om in zakelijk resultaat – zonder code.
Meer weten