Heb je ooit geprobeerd om precies die ene dataset van een website te halen—denk aan een lijst met concurrentieprijzen, een productcatalogus of verse sales leads? Dan weet je vast hoe het voelt: met een standaard webscraper kom je tot zo’n 80%, maar die laatste 20%? Daar zit vaak de echte uitdaging (en soms de frustratie). In een wereld waar data de dienst uitmaakt, kun je als bedrijf niet meer genoegen nemen met ‘bijna goed’. Maatwerkextractie en data-extractiediensten zijn inmiddels onmisbaar, zeker nu de wereldwijde webscraping-markt naar verwachting groeit van $754 miljoen in 2024 tot . Als jouw datastrategie geen maatwerk scraping bevat, loop je het risico dat je onzichtbaar wordt in je markt.
Ik heb jarenlang teams geholpen—van jonge start-ups tot gevestigde bedrijven—om verder te komen dan eindeloos kopiëren en plakken of werken met starre, standaardtools. Het verschil? De kracht van maatwerk data-extractie. In deze gids leg ik uit wat maatwerkextractie precies is, waarom het zo belangrijk is, hoe (de AI-webscraper die mijn team en ik hebben gebouwd) het supermakkelijk maakt, en hoe je de juiste data-extractiedienst voor jouw bedrijf kiest. Ook deel ik wat praktijkervaringen—want iedere dataliefhebber heeft zo zijn verhalen.
Wat is maatwerkextractie? De kracht van op maat gemaakte data-extractiediensten
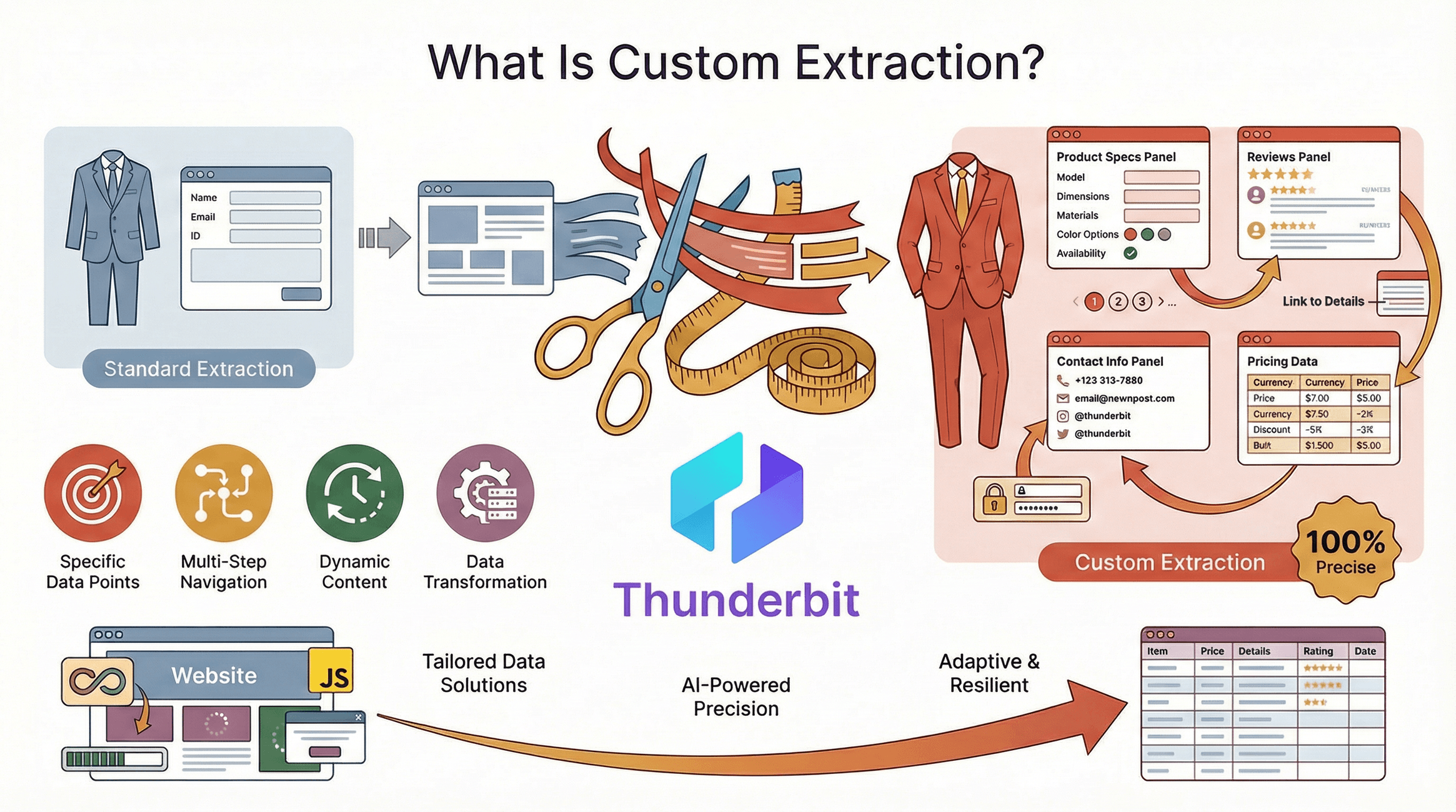 Laten we bij het begin beginnen: maatwerkextractie draait om het verzamelen van precies die data die jij nodig hebt, in het juiste formaat, van de websites die voor jouw bedrijf belangrijk zijn. In tegenstelling tot standaard scrapingtools die alleen pakken wat makkelijk te vinden is, is maatwerkextractie precies, flexibel en robuust—zelfs als websites ingewikkeld zijn, dynamisch werken of vaak van structuur veranderen.
Laten we bij het begin beginnen: maatwerkextractie draait om het verzamelen van precies die data die jij nodig hebt, in het juiste formaat, van de websites die voor jouw bedrijf belangrijk zijn. In tegenstelling tot standaard scrapingtools die alleen pakken wat makkelijk te vinden is, is maatwerkextractie precies, flexibel en robuust—zelfs als websites ingewikkeld zijn, dynamisch werken of vaak van structuur veranderen.
Zie het als een maatpak in plaats van confectiekleding. Met maatwerkextractie zit je niet vast aan standaardvelden of sjablonen. Je kunt:
- Specifieke datapunten kiezen (zoals productspecificaties, reviews of contactgegevens)
- Door meerdere stappen navigeren (paginering, subpagina’s, inloggen)
- Omgaan met dynamische content (oneindig scrollen, data geladen via JavaScript)
- Data direct tijdens het extraheren formatteren, opschonen of transformeren
Waarom is dit belangrijk? Omdat zakelijke behoeften zelden simpel zijn. Misschien wil je productlijsten scrapen en per item doorklikken voor details en reviews. Of je wilt prijzen van concurrenten monitoren, maar alleen voor bepaalde producten. Standaardtools lopen dan vast, missen data of vereisen dat je zelf HTML-expert wordt. Maatwerkextractiediensten zijn juist gemaakt voor dit soort situaties—vaak met hulp van AI en natuurlijke taalverwerking.
Wil je dieper in het verschil duiken tussen maatwerk en standaard scraping? Lees dan .
Waarom maatwerk data-extractiediensten essentieel zijn voor groei
Laten we het praktisch maken. Waarom zou je investeren in maatwerk data-extractie? Omdat het niet alleen een technische upgrade is, maar een echte groeiversneller. Zo leveren maatwerkextractiediensten direct resultaat op:
| Zakelijke behoefte | Maatwerk data scraping oplossing | Typisch resultaat/ROI |
|---|---|---|
| Leadgeneratie | Up-to-date contactgegevens scrapen uit directories, LinkedIn of reviewwebsites | Tot 80% minder handmatig zoekwerk; grotere en relevantere leadlijsten |
| Prijsmonitoring concurrenten | Prijzen en voorraad volgen op concurrerende sites, ook bij dynamische lay-outs | 4%+ omzetgroei door dynamische prijzen; tot 15% margeverbetering |
| Marktinformatie & onderzoek | Nieuws, reviews of rapportages op grote schaal verzamelen | 50%+ meer datagebruik; sneller en beter onderbouwde beslissingen |
| Productcatalogus bijwerken | Productinformatie uit meerdere bronnen halen, inclusief subpagina’s en varianten | Altijd actuele catalogi; minder fouten en handmatig werk |
| Operationele automatisering | Terugkerende scrapes plannen voor rapportages, compliance of voorraadbeheer | 85% snellere time-to-market voor data; 73% lagere verzamelkosten |
(, )
Kortom: maatwerkextractie is geen luxe, maar een must om concurrerend te blijven. Bedrijven die dit beheersen, zijn hun concurrenten steeds een stap voor, reageren sneller op marktveranderingen en ontdekken inzichten die groei stimuleren.
Thunderbit’s aanpak: Maatwerk data-extractie voor iedereen
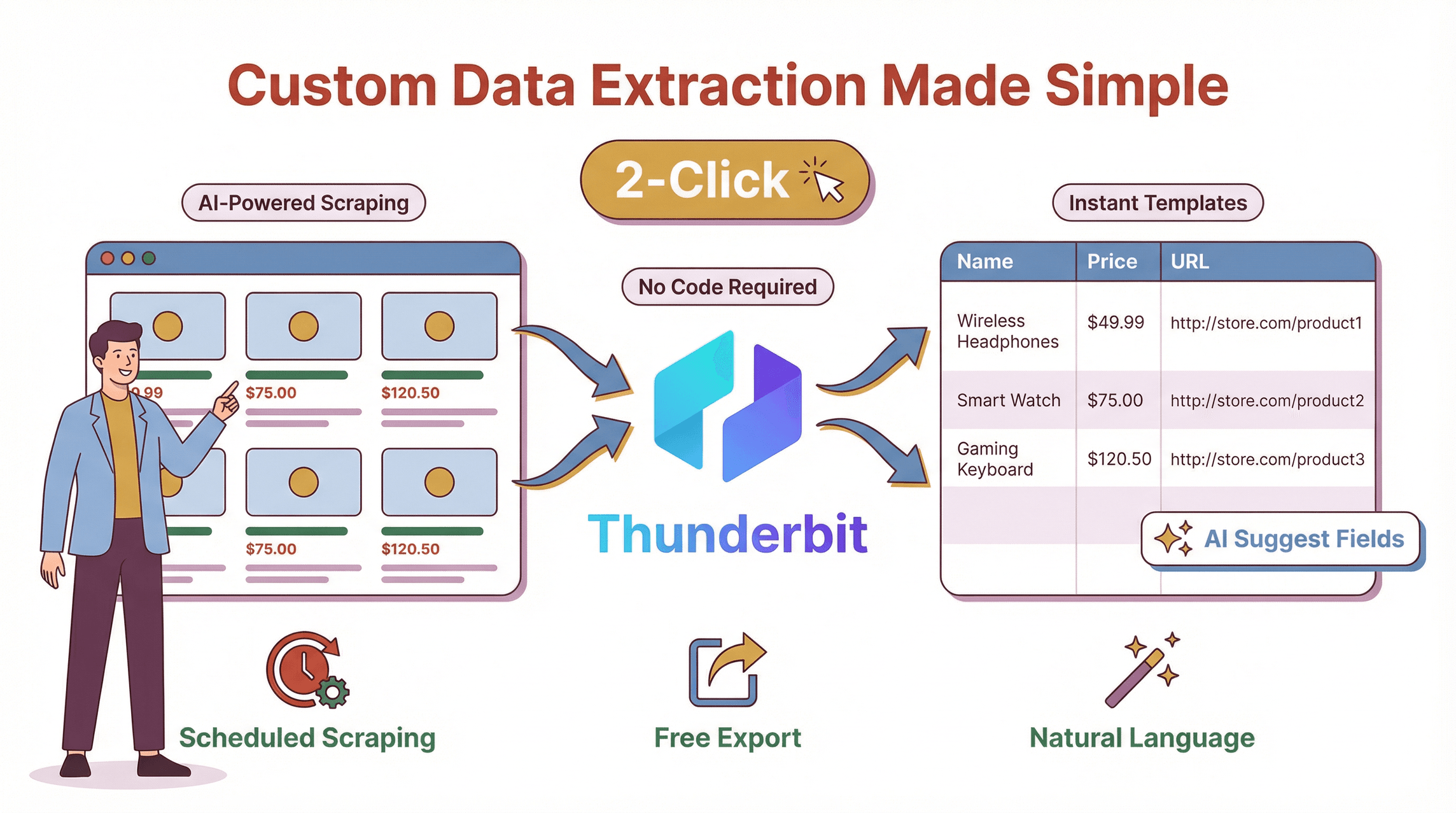
Eerlijk is eerlijk: ik heb Thunderbit gebouwd omdat ik het zat was om teams te zien worstelen met logge, code-intensieve webscrapers die bij elke kleine websitewijziging vastliepen. Thunderbit is een die maatwerk data-extractie voor iedereen toegankelijk maakt—dus niet alleen voor developers.
Wat maakt Thunderbit uniek?
- AI-gestuurde veldsuggesties: Klik op “AI Suggest Fields” en Thunderbit scant de pagina, waarna het de beste kolommen voorstelt—zoals “Productnaam”, “Prijs”, “Afbeeldings-URL” of “E-mail”. Geen gedoe meer met selectors.
- Natuurlijke taal prompts: Wil je een datum extraheren, een beschrijving vertalen of items categoriseren? Geef het gewoon in het Nederlands op. De AI regelt de rest.
- Scrapen in 2 klikken: Ga naar de gewenste site, open Thunderbit en klik op “Scrape”. Geen code, geen sjablonen (tenzij je dat wilt), geen hoofdpijn.
- Geschikt voor complexe pagina’s: Thunderbit kan omgaan met paginering, oneindig scrollen, subpagina’s en zelfs dynamische content via JavaScript. Het past zich aan als websites veranderen.
- Subpagina scraping: Meer details nodig per item? Thunderbit bezoekt automatisch elke subpagina (zoals productdetails) en vult je tabel aan.
- Geplande scraping: Stel terugkerende scrapes in met natuurlijke taal (“elke maandag om 9 uur”) en Thunderbit doet de rest.
- Directe sjablonen: Voor populaire sites als Amazon, Zillow of LinkedIn zijn er 1-klik sjablonen—geen installatie nodig.
- Gratis data-export: Exporteer je data naar Excel, Google Sheets, Airtable, Notion, CSV of JSON—zonder betaalmuur of limieten.
De missie van Thunderbit is simpel: laat zakelijke gebruikers beschrijven wat ze willen, en laat AI het technische werk doen. Het is alsof je een AI-onderzoeksassistent hebt die nooit moe wordt (en nooit klaagt over koffie).
Stapsgewijs: Zo gebruik je Thunderbit voor maatwerk data scraping
Laten we een praktijkvoorbeeld doorlopen met Thunderbit. Ik gebruik een productcatalogus als voorbeeld, maar de stappen zijn vergelijkbaar voor leads, reviews of andere data.
Stap 1: Installeer Thunderbit
Ga naar de en voeg deze toe aan je browser. Maak gratis een account aan—geen creditcard nodig voor de gratis versie.
Stap 2: Open de gewenste website
Navigeer naar de pagina die je wilt scrapen (bijvoorbeeld een categoriepagina met producten).
Stap 3: Start Thunderbit en gebruik AI Suggest Fields
Klik op het Thunderbit-icoon. Druk op “AI Suggest Fields”—de AI scant de pagina en stelt kolommen voor zoals “Productnaam”, “Prijs”, “Afbeeldings-URL”, enzovoort. Je kunt velden hernoemen, toevoegen of verwijderen.
Stap 4: Pas velden aan met AI-prompts
Wil je iets specifieks extraheren? Voeg per veld een instructie toe—zoals “haal de datum op in formaat JJJJ-MM-DD” of “vertaal beschrijving naar Spaans”. Thunderbit’s AI past je regel direct toe tijdens het scrapen.
Stap 5: Zet paginering of subpagina scraping aan (indien nodig)
Staat je data op meerdere pagina’s? Zet Paginering aan. Wil je details van subpagina’s (zoals productdetails), gebruik dan Subpagina Scraping—Thunderbit bezoekt elke link en vult je tabel aan.
Stap 6: Klik op “Scrape” en zie de data binnenstromen
Thunderbit haalt je data op, regelt navigatie en formatting automatisch. Je ziet een voorbeeldtabel terwijl het werkt.
Stap 7: Exporteer je data
Tevreden met het resultaat? Exporteer direct naar . Je kunt ook downloaden als CSV of JSON.
Dat is alles. Geen code, geen sjablonen (tenzij je wilt), en geen “waarom werkt dit niet?”-momenten. Meer weten? Bekijk de .
Thunderbit versus andere data-extractiediensten
Even technisch: hoe verhoudt Thunderbit zich tot andere extractiediensten zoals Azure AI Document Intelligence of traditionele webscrapers?
| Functie / Criteria | Thunderbit | Azure AI Document Intelligence | Traditionele scrapers (zoals Octoparse, Scrapy) |
|---|---|---|---|
| Gebruiksgemak | No-code, AI-gestuurd, 2 klikken | Gericht op developers, API-gebaseerd | Lastige leercurve, vaak coderen vereist |
| Maatwerkextractie | Natuurlijke taalprompts, veld-AI | Custom ML-modellen voor documenten | Handmatige configuratie, selectors, scripts |
| Webpagina’s verwerken | Ja (HTML, dynamisch, subpagina’s) | Nee (gericht op documenten/PDFs) | Ja, maar moeite met dynamische sites |
| Documenten/PDFs verwerken | Ja (via browser/PDF-modus) | Ja (OCR, ML) | Soms, maar beperkt |
| Aanpasbaarheid | AI past zich aan bij lay-outwijzigingen | ML past zich aan nieuwe documenten aan | Breekt bij sitewijzigingen, vereist updates |
| Planning | Ingebouwd, natuurlijke taal | Via API, integratie nodig | Soms, maar complex |
| Exportopties | Sheets, Excel, Airtable, Notion, CSV, JSON | API/JSON, developer-integratie nodig | CSV, Excel, DB, varieert |
| Support | Moderne SaaS, snel reagerend | Enterprise, formele support | Community of leverancier, varieert |
| Prijs | Gratis versie, betalen per gebruik | Verbruik-gebaseerd, enterprise focus | Gratis (open source) of maandabonnementen |
Thunderbit is ideaal voor zakelijke gebruikers die krachtige webdata willen zonder technische drempels. Azure is top voor grootschalige documentverwerking, maar niet voor websites. Traditionele webscrapers zijn krachtig voor techneuten, maar vragen veel onderhoud en kennis.
Meer weten? Lees .
Hoe kies je de juiste maatwerk data-extractiedienst?
Het draait niet alleen om functies, maar vooral om wat bij jouw situatie past. Gebruik deze checklist bij je keuze:
- Datakwaliteit & betrouwbaarheid: Levert het accurate, schone en volledige data? Kun je testen op jouw sites?
- Flexibiliteit & maatwerk: Kan het jouw specifieke websites, dynamische content, logins of subpagina’s aan? Kun je velden of transformaties zelf instellen?
- Compliance & ethiek: Houdt het zich aan wet- en regelgeving? Worden privacyregels en sitevoorwaarden gerespecteerd?
- Schaalbaarheid & prestaties: Kan het jouw datavolume en frequentie aan? Is er cloud scraping of parallelle verwerking?
- Integratie & workflow: Kun je data exporteren naar jouw tools (Sheets, Excel, CRM, etc.)? Ondersteunt het planning of automatisering?
- Support & documentatie: Is er snelle support en duidelijke documentatie? Zijn er tutorials of een kennisbank?
- Beveiliging: Wordt je data veilig verwerkt? Zijn inloggegevens versleuteld? Zijn er certificeringen?
- Kosten: Is de prijs transparant en passend bij jouw gebruik? Geen verborgen kosten of betaalmuren?
Test elke kandidaat in de praktijk. Scrape een echte site, exporteer de data en kijk hoe het in je workflow past. Meer tips? Lees .
Maatwerk data scraping integreren in je bedrijfsprocessen
Data extraheren is pas het begin—de echte waarde zit in het integreren in je dagelijkse processen. Zo maak je maatwerkextractie onderdeel van je bedrijf:
- Automatiseer terugkerende taken: Gebruik geplande scraping om je data actueel te houden—dagelijkse prijschecks, wekelijkse leadupdates, enzovoort.
- Voer data direct in je tools: Exporteer naar . Gebruik Zapier, Make of n8n voor verdere automatisering (bijvoorbeeld leads direct naar je CRM).
- Stel meldingen in: Koppel aan Slack of e-mail om direct updates te krijgen—zoals prijsdalingen bij concurrenten of nieuwe productlanceringen.
- Werk samen in de cloud: Deel databases (Airtable, Notion) zodat teams altijd bij de gescrapete data kunnen.
- Automatiseer van begin tot eind: Combineer scraping met BI-tools (Tableau, Power BI) voor live dashboards, of trigger acties (zoals repricing) op basis van gescrapete data.
Inspiratie nodig? Bekijk .
Best practices voor maximale waarde uit maatwerkextractie
Wil je het maximale halen uit maatwerk data-extractie? Dit heb ik geleerd (soms op de harde manier):
- Stel duidelijke doelen: Weet precies welke data je nodig hebt en waarom. Scrape niet zomaar, maar met een doel.
- Begin klein, test vaak: Start met kleine pilots, controleer de data en schaal op als je tevreden bent.
- Monitor datakwaliteit: Controleer regelmatig steekproeven. Stel validatieregels of meldingen in voor afwijkingen.
- Optimaliseer frequentie: Scrape zo vaak als nodig, maar niet vaker. Te veel scraping kan blokkades opleveren (en je IT-team irriteren).
- Blijf ethisch & compliant: Respecteer sitevoorwaarden, privacywetgeving en ethische richtlijnen. Scrape geen gevoelige of verboden data.
- Gebruik veldprompts: Gebruik AI-prompts om data direct te schonen, formatteren of verrijken tijdens het scrapen.
- Beveilig je data: Ga zorgvuldig om met inloggegevens en gescrapete data—gebruik encryptie en toegangsbeheer.
- Documenteer je proces: Houd bij wat je scrapt, waarvandaan en hoe vaak. Dat voorkomt problemen achteraf.
- Blijf verbeteren: Zie maatwerkextractie als een continu proces. Pas je aanpak aan als je behoeften veranderen.
Meer best practices? Lees .
Conclusie & belangrijkste inzichten: Til je datastrategie naar een hoger niveau met maatwerkextractie
Maatwerk data-extractie en scrapingdiensten zijn niet alleen voor datafanaten—het zijn onmisbare tools voor elk bedrijf dat snel wil schakelen, concurrerend wil blijven en slimmer wil beslissen. De tijd van handmatig kopiëren en plakken of kwetsbare scripts is voorbij. Met AI-tools zoals kan iedereen maatwerkextractie toepassen—zonder te hoeven programmeren.
Onthoud vooral:
- Maatwerkextractie = relevante data. Haal de juiste data, niet alleen meer data.
- Zakelijke waarde is bewezen. Van sales tot operations en marktonderzoek: maatwerk scraping levert echt rendement op.
- Gebruiksgemak is er nu. Tools als Thunderbit maken data-extractie toegankelijk voor iedereen.
- Integratie is alles. Maak gescrapete data onderdeel van je dagelijkse workflow, niet een losstaand project.
- Kies bewust. Stem de tool af op je behoeften—test, vergelijk en verbeter.
- Best practices winnen. Duidelijke doelen, kwaliteitscontroles en ethiek houden je datastrategie sterk.
Klaar om je datavaardigheden te upgraden? en probeer een maatwerk scrape op een echte businesscase. Of duik dieper in de materie via de voor uitgebreide uitleg, tutorials en het laatste nieuws over AI-gedreven data-extractie.
Het web is een goudmijn aan inzichten—maatwerkextractie is jouw gereedschap. Veel succes met scrapen!
Veelgestelde vragen
1. Wat is maatwerk data-extractie en hoe verschilt het van standaard scraping?
Maatwerk data-extractie betekent dat je scraping volledig afstemt op de data die jij nodig hebt, in het gewenste formaat, van elke website—ook als die complex of dynamisch is. In tegenstelling tot standaardtools die alleen pakken wat makkelijk is, past maatwerkextractie zich aan jouw wensen en veranderende websites aan.
2. Wie profiteert het meest van maatwerk data-extractiediensten?
Sales (voor leads), marketing (voor concurrentieanalyse), operations (voor automatisering), productmanagers (voor catalogusupdates) en marktonderzoekers (voor inzichten) halen allemaal grote voordelen uit maatwerkextractie—vooral als standaardtools tekortschieten.
3. Hoe maakt Thunderbit maatwerkextractie eenvoudiger?
Thunderbit gebruikt AI om velden voor te stellen, complexe navigatie (paginering, subpagina’s) te regelen en laat je in gewone taal beschrijven wat je wilt. Geen code, geen sjablonen (tenzij je wilt), en directe export naar je favoriete tools.
4. Waar moet ik op letten bij het kiezen van een data-extractiedienst?
Let op datakwaliteit, flexibiliteit, compliance, schaalbaarheid, integratie, support, beveiliging en kosten. Test elke dienst op jouw praktijkcases voordat je kiest.
5. Hoe integreer ik maatwerk data scraping in mijn bedrijfsprocessen?
Automatiseer terugkerende taken, exporteer data naar Sheets/Excel/Notion, stel meldingen in en gebruik workflowtools zoals Zapier of n8n. Het doel: maak webdata een vast onderdeel van je dagelijkse processen, niet een eenmalig project.
Benieuwd wat maatwerkextractie voor jouw bedrijf kan betekenen? en maak van webchaos heldere bedrijfsinzichten.
Meer weten