Na ruim duizend scrapes met Simplescraper ging ik niet meer successen tellen, maar mislukkingen bijhouden. Die omslag — van “werkte het?” naar “waarom ging het deze keer stuk?” — heeft me meer geleerd dan welke documentatiepagina dan ook ooit kon.
Simplescraper is een degelijke Chrome-extensie om data van websites te halen zonder code te schrijven. Met in de Chrome Web Store en een echt toegankelijke point-and-click interface heeft het zijn plek in de no-code scraping toolkit verdiend. Maar dit staat er niet op de landingspagina: als je op schaal consistente, betrouwbare resultaten wilt, moet je goed snappen waar visuele scrapers kwetsbaar worden. Een dat werknemers meer dan negen uur per week kwijt zijn aan repetitieve data-invoer — precies het soort probleem dat mensen richting tools als Simplescraper duwt. Maar als je de eigenaardigheden van de tool niet kent, ben je die negen uur kwijt aan debuggen in plaats van aan iets nuttigs. In dit artikel deel ik de vijf best practices die ik uit echte operationele ervaring heb gedistilleerd: selectieproblemen oplossen, de juiste scrapingmodus kiezen, het maximale uit de gratis versie halen, blokkades vermijden en weten wanneer je moet overstappen.

Wat is Simplescraper (en waarom best practices belangrijk zijn)
Simplescraper is een Chrome-extensie waarmee je visueel elementen op een webpagina kunt selecteren — producttitels, prijzen, afbeeldingen, contactgegevens — en ze zonder een regel code kunt omzetten in gestructureerde data. Je wijst, je klikt, en daarna bouwt het een “recipe” die je later opnieuw kunt gebruiken op vergelijkbare pagina’s.
Het kernmodel werkt zo:
- Visuele elementselectie: Klik op wat je wilt. Simplescraper herkent automatisch terugkerende patronen (zoals productlijsten, zoekresultaten of vacatures).
- Recipes: Sla je extractie-instelling op om later opnieuw te gebruiken of op batches URL’s uit te voeren.
- Twee scrapingmodi: Browser (lokaal, draait in je Chrome) en Cloud (draait op de servers van Simplescraper, zonder toezicht).
- Integraties: Export naar Google Sheets, Airtable, webhooks, Zapier, Make, CSV en JSON.
- AI-extractie: Een nieuwere die CSS-selectors genereert op basis van een schema-prompt.
De doelgroep is breed — marketeers, salesteams, e-commerce operators, onderzoekers — iedereen die gestructureerde data van websites wil halen zonder een ontwikkelaar in te huren. En voor overzichtelijke pagina’s levert Simplescraper snel resultaat.
Waarom zijn best practices dan belangrijk? Omdat op het moment dat je verder gaat dan een simpele productlijst of een nette bedrijvengids, de frictie begint. Dynamische content, anti-botmaatregelen, lui geladen afbeeldingen, diep geneste HTML-structuren — dat zijn de echte omstandigheden waarin een frustrerende ervaring zich onderscheidt van een productieve. Als je vooraf de juiste aanpak kiest, bespaar je uren aan trial-and-error.
Best practice 1: Wat te doen wanneer Simplescraper elementen niet kan selecteren
Dit is veruit de meest voorkomende frustratie die ik heb gezien. Je klikt op een element, Simplescraper markeert het, je bent tevreden — en dan blijkt in de output de helft van je data te ontbreken. Foto’s zijn leeg. Bio’s ontbreken. Locaties zijn verdwenen.
De oprichter zelf dat “the element/css selector still ain't 100%.” Die eerlijkheid is verfrissend, maar het lost je kapotte scrape om 23.00 uur op woensdag niet op.
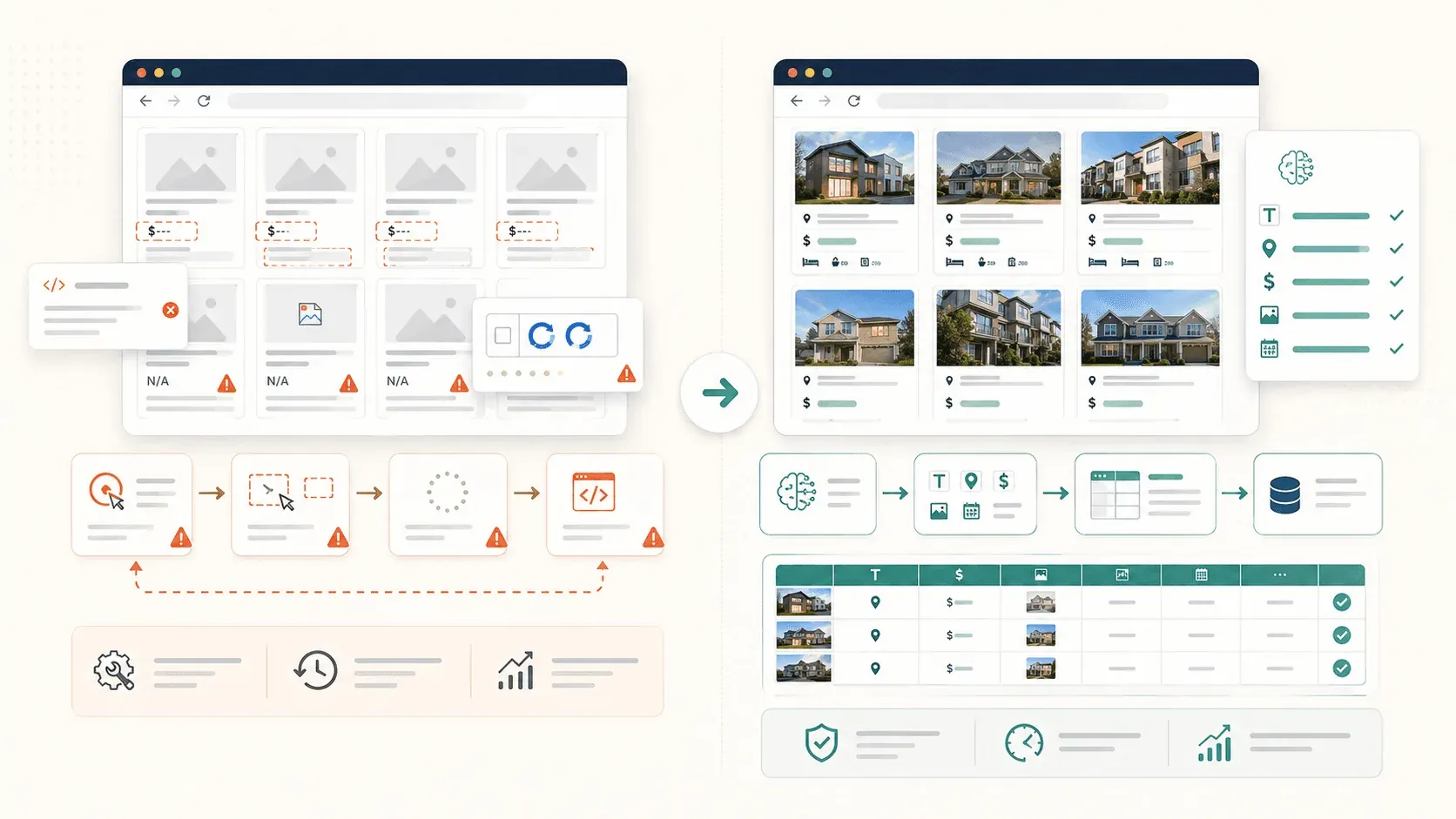
Veelvoorkomende selectiefouten (en waarom ze gebeuren)
Vier patronen laten Simplescraper het vaakst struikelen:
- Lui geladen afbeeldingen: Het afbeeldingselement bestaat letterlijk totdat je ernaartoe scrolt. Als je scrape vóór het scrollen uitvoert, krijg je lege afbeeldingsvelden.
- Geneste of gegroepeerde containers: De automatische detectie van Simplescraper , wat soms betekent dat slechts één deel van een pagina wordt gepakt in plaats van de volledige herhalende set. Gebruikers melden tabellen die “niet alle rijen in één keer willen selecteren.”
- Dynamische JavaScript-content: Elementen die pas na het initiële laden van de pagina worden gerenderd via React, Vue of AJAX-aanroepen zijn simpelweg nog niet aanwezig wanneer de scraper te vroeg handelt.
- Oneindige scroll-paginatie: De data die je wilt, is nog niet in de HTML geladen omdat je moet scrollen of op “meer laden” moet klikken.
Praktische stappen om problemen op te lossen
Voordat je naar handmatige selectors grijpt, probeer dit:
- Scrol eerst de hele pagina door. Daardoor komen lui geladen afbeeldingen en content in de DOM.
- Gebruik “Include Similar” wanneer het aantal items opvallend laag lijkt. De eigen documentatie van Simplescraper raadt dit aan voor gegroepeerde content.
- Wacht tot de pagina volledig is gerenderd op sites met veel JavaScript. Geef het een paar extra seconden voordat je de scrape start.
- Begin met een kleine steekproef. Controleer het aantal rijen op 2–3 pagina’s voordat je een batch van 500 pagina’s laat draaien.
Overschakelen naar handmatige CSS-selectors
Als visuele selectie blijft falen, is het tijd om handmatig te werken. Dat is de power move die gelegenheidsgebruikers onderscheidt van effectieve gebruikers.
Zo werkt het:
- Klik met de rechtermuisknop op het gewenste element in Chrome → Inspecteren.
- Zoek in DevTools de classnaam of data-attribuut van het element op (bijv.
.product-card .priceof[data-test="location"]). - Ga in Simplescraper naar het tabblad en plak je selector.
- Test de selector door een kleine scrape uit te voeren.
Tips voor robuuste selectors:
- Geef de voorkeur aan classnamen (
.listing-title) boven positionele selectors (div:nth-child(3)) - Gebruik wanneer die beschikbaar zijn — die blijven meestal stabieler bij site-updates
- Vermijd diep geneste paden die breken zodra de HTML-structuur van de site verandert
Het AI-alternatief: laat Thunderbit velden automatisch herkennen
Ik ben er eerlijk over: mijn team heeft juist gebouwd omdat we deze exacte frustratie beu waren. Thunderbit’s “AI Suggest Fields” leest de paginastructuur en beveelt automatisch kolommen en extractielogica aan. Geen CSS-kennis nodig. De AI past zich aan de lay-out van elke site aan, inclusief geneste content en lui geladen afbeeldingen.
Als je per scrape meer dan een paar minuten kwijt bent aan het debuggen van selectors, is het de moeite waard om een heel andere aanpak te proberen.
Best practice 2: kiezen tussen Cloud scraping en Browser scraping
De meeste Simplescraper-gebruikers kiezen standaard een modus — meestal wat ze als eerste hebben geprobeerd — zonder na te denken over welke modus eigenlijk bij hun use case past. Dat zorgt voor vermijdbare fouten.
Wanneer Browser scraping gebruiken
- Pagina’s waarvoor inloggen nodig is: LinkedIn, CRM-dashboards, interne tools — alles achter authenticatie vereist je actieve browsersessie.
- Snelle eenmalige extractions: Je zit toch al op de pagina en wilt de data nu hebben.
- Je gratis credits sparen: Browser scraping verbruikt geen cloud credits.
De afweging: je computer moet aan blijven en grote jobs zijn trager dan in de cloud.
Wanneer Cloud scraping gebruiken
- Openbare pagina’s (e-commerce listings, bedrijvengidsen, vastgoedsites) waarvoor geen login nodig is.
- Geplande monitoring: Draait onbewaakt op een terugkerende basis.
- Batchjobs: in één cloudbatch.
- Integratie-output: Automatische push naar Google Sheets, Airtable of webhooks.
De afweging: cloud scraping — 2 per JavaScript-ingeschakelde pagina, 1 per niet-JS-pagina — en vreet je gratis maandtegoed van 100 credits snel op.
Besliskader
| Scenario | Aanbevolen modus | Waarom | Risico als het fout is |
|---|---|---|---|
| Pagina’s waarvoor inloggen nodig is (LinkedIn, dashboards) | Browser | Heeft je geauthenticeerde sessie nodig | Cloudmodus loopt vast op loginmuren |
| Openbare e-commerce productlijsten | Cloud | Sneller, draait zonder toezicht | Browsermodus houdt je machine bezet |
| Geplande terugkerende monitoring | Cloud | Draait zonder dat jij aanwezig bent | Browser vereist dat jij er bent |
| Sites met sterke anti-botbeveiliging (Amazon, Yelp) | Browser (fallback) of Cloud met proxy | IP-rotatie of hergebruik van sessies nodig | Cloud zonder proxy wordt snel geblokkeerd |
| Snelle eenmalige extractie | Browser | Direct, zonder creditkosten | Cloud instellen voor één pagina is overdreven |

Hoe Thunderbit dit vereenvoudigt
In is de keuze een simpele schakelaar binnen dezelfde interface. De cloudmodus verwerkt tot 50 pagina’s tegelijk — zonder aparte betaalde laag voor cloudtoegang. De browsermodus handelt sites waarvoor inloggen nodig is af zonder extra configuratie. De mentale last van “welke modus heb ik nodig?” wordt een stuk kleiner wanneer beide modi in dezelfde workflow leven.
Best practice 3: haal het maximale uit Simplescraper’s gratis versie
Prijsverwarring komt vaak voor. Ik heb forumposts gezien waarin mensen ervan uitgaan dat “gratis Chrome-extensie” betekent “alles gratis”. Dat is niet zo. En aan de andere kant zag ik mensen aannemen dat Simplescraper duur is omdat de betaalde abonnementen niet opvallend worden getoond. Geen van beide aannames helpt.
Wat het gratis plan van Simplescraper echt bevat
Volgens :
- Browser scraping: Onbeperkt (draait lokaal in je Chrome)
- Cloud credits: 100 per maand
- Opgeslagen recipes: 3
- Exportformaten: CSV en JSON
- Wat NIET inbegrepen is: Prioritaire support, geavanceerde proxy-opties, hogere cloudtegoedlimieten
Een realistisch gratis-versie-scenario
Stel dat je 50 productpagina’s van een openbare e-commerce site wilt scrapen.
- Browsermodus (gratis): Je kunt dit volledig gratis doen. Open elke pagina (of gebruik een lijst), voer de recipe uit en exporteer naar CSV. Benodigde tijd: hangt af van je geduld en internetsnelheid, maar reken op 15–30 minuten actief werk voor 50 pagina’s met handmatige navigatie.
- Cloudmodus (gratis versie): Met JavaScript-rendering ingeschakeld kost elke pagina 2 credits. 50 pagina’s = 100 credits. Dat is je volledige maandelijkse cloudtegoed in één job. Geen planning, geen retries als iets mislukt.
De gratis versie is echt bruikbaar voor kleine, incidentele scrapes. Maar zodra je cloudautomatisering of schaal nodig hebt, is hij snel op.
Vergelijking gratis versie: Simplescraper vs. Thunderbit
| Functie | Simplescraper Gratis | Thunderbit Gratis |
|---|---|---|
| Pagina’s/credits | Onbeperkte browser + 100 cloud credits | 6 pagina’s met volledige AI-functies |
| AI-aangedreven extractie | Beperkt (Smart Extract gebruikt credits) | Volledige AI Suggest Fields inbegrepen |
| Exportdoelen | CSV, JSON | Excel, Google Sheets, Airtable, Notion — allemaal gratis |
| Opgeslagen configuraties | 3 recipes | Sjablonen beschikbaar |
| Subpagin scraping | Handmatige recipe-instelling | Inbegrepen in het paginatotaal |
De modellen zijn echt verschillend. Simplescraper geeft je onbeperkte lokale scraping met beperkte cloudcapaciteit. geeft je minder pagina’s, maar stopt per pagina volledige AI-mogelijkheden in het proces, plus gratis export naar de tools die de meeste teams echt gebruiken. De gratis versie van Simplescraper werkt prima als je basis lokale scraping nodig hebt en handwerk niet erg vindt. Maar als je AI-aangedreven extractie met flexibele exports wilt, levert Thunderbit’s gratis versie meer per pagina op.
Best practice 4: hoe je voorkomt dat je wordt geblokkeerd tijdens het scrapen
Niemand denkt aan anti-botmaatregelen totdat ze naar een CAPTCHA-muur of een lege dataset staren. Tegen die tijd ben je al tijd en mogelijk credits kwijt.
Proactieve verdediging is altijd goedkoper dan reactief debuggen.
Stel rate limits in en doseer je verzoeken
De belangrijkste reden om geblokkeerd te worden: een site bestoken met razendsnelle verzoeken. Voor een webserver ziet 50 requests in 10 seconden vanaf één IP eruit als een aanval, niet als een nieuwsgierige onderzoeker.
Algemene vuistregels:
- Voeg 2–5 seconden toe tussen paginarequests voor de meeste commerciële sites.
- Voor gevoelige targets (marktplaatsen, reviewsites) doe je het rustiger aan — 5–10 seconden.
- Gebruik je Simplescraper API, dan kan de parameter helpen om te zorgen dat pagina’s volledig laden vóór de extractie, wat je tempo ook natuurlijk vertraagt.
Wanneer proxyrotatie inschakelen
Proxyrotatie wijzigt je IP-adres tussen requests, zodat je eruitziet als meerdere verschillende gebruikers. Dat heb je nodig voor:
- Amazon, Yelp, TripAdvisor, LinkedIn (agressieve anti-botsystemen)
- Elke site die rate-limits per IP hanteert
- Grote batchjobs (honderden pagina’s van één domein)
Het platform van Simplescraper , waaronder standaard-, premium- en residential-opties. De exacte beschikbaarheid per abonnement is echter niet altijd glashelder in de publieke documentatie — verifieer dit voordat je ervan uitgaat dat de gratis versie zware targets aankan. Residential proxies kosten meestal meer, maar worden minder snel gemarkeerd.
Omgaan met JavaScript-zware sites
Moderne sites gebouwd met React, Vue of Angular renderen content pas na het initiële laden van de pagina. Als je scraper handelt vóór JavaScript klaar is met uitvoeren, krijg je lege velden.
Strategieën:
- Gebruik cloud scrapingmodus voor betere rendering (Simplescraper’s cloud kan JavaScript uitvoeren).
- Scrol handmatig door de pagina vóór een browser scrape om lui geladen content te activeren.
- Gebruik
waitForSelectorin API-gebaseerde workflows om te pauzeren totdat de doel-elementen verschijnen. - Accepteer dat sommige sterk dynamische single-page apps simpelweg buiten het bereik van een visuele scraper kunnen vallen.
Het hands-off alternatief
handelt anti-botbeveiliging, CAPTCHA’s en JavaScript-rendering automatisch af — zonder proxyconfiguratie, zonder het tunen van vertragingen, zonder handmatig scrollen. Voor gebruikers die geen amateur-DevOps-engineer willen worden alleen maar om een productcatalogus te scrapen, maakt dat uit. De problemen verdwijnen niet — ze worden gewoon iemand anders’ probleem.
Best practice 5: weet wanneer Simplescraper zijn plafond heeft bereikt
Ik wou dat iemand dit stuk twee jaar geleden voor me had geschreven.
Er komt een punt waarop de tool geen tijdbesparing meer is, maar een tijdverslinder. Die grens vroeg herkennen bespaart je de sunk-cost-valkuil van “ik heb al 15 recipes gebouwd, nu kan ik niet meer overstappen.”
De praktische limieten van Simplescraper
- Dynamische single-page applicaties die content via AJAX laden zonder traditionele paginanavigatie
- Oneindige scroll die constant scrollen vereist om alle items te laden (niet de standaard klik-gebaseerde paginering)
- Subpaginaverrijking: een overzichtspagina scrapen en vervolgens elke detailpagina bezoeken voor extra data. Simplescraper kan dit doen met , maar de complexiteit van de setup groeit snel.
- Lay-outwijzigingen die bestaande recipes breken. Wanneer een site zijn HTML-structuur bijwerkt, werken je zorgvuldig afgestelde CSS-selectors niet meer.
Signalen dat je de tool bent ontgroeid
Je hebt waarschijnlijk je limiet bereikt wanneer:
- Je bij elke scrape handmatig CSS-selectors moet aanpassen omdat automatische detectie blijft falen
- Recipes na site-updates breken en opnieuw opgebouwd moeten worden
- Je tientallen of honderden pagina’s tegelijk wilt scrapen maar steeds tegen credit- of snelheidslimieten aanloopt
- Data van subpagina’s complexe meerstaps recipe-ketens vereist
- Je meer tijd kwijt bent aan het onderhouden van scrapes dan aan het daadwerkelijk gebruiken van de uitgehaalde data
Dat laatste is het duidelijkste signaal. Wanneer onderhoud het werk wordt, is het no-code voordeel verdwenen.
Overstappen naar een AI-aangedreven workflow
Hier vertel ik over wat mijn team heeft gebouwd met , omdat het specifiek is ontworpen voor de failure modes die hierboven zijn beschreven:
- AI leest elke pagina elke keer opnieuw — geen kwetsbare recipes of CSS-selectors om te onderhouden. Als een site zijn lay-out verandert, past de AI zich bij de volgende run aan.
- Subpagin scraping verrijkt je datatabel met één klik. Scrape een listing en bezoek daarna automatisch elke detailpagina voor extra velden.
- Gepland scrapen met natuurlijke taal (“elke maandag om 9:00”) in plaats van timing-presets configureren.
- Cloud scraping op 50 pagina’s tegelijk voor snelheid op openbare sites.
- Native gratis exports naar Google Sheets, Airtable, Notion en Excel zonder webhookconfiguratie.
Simplescraper vs. Thunderbit: vergelijking naast elkaar
Hier staat alles op één plek:

| Mogelijkheid | Simplescraper | Thunderbit |
|---|---|---|
| Veldinstelling | Handmatige CSS-selectors / visuele selectie | AI Suggest Fields (gewoon Engels) |
| Subpaginaverrijking | Mogelijk via batch-workflows (complexe setup) | Automatische verrijking met 1 klik |
| Automatisch aanpassen aan lay-outwijzigingen | Breekt (handmatige fix nodig) | AI leest de paginastructuur elke keer opnieuw |
| Cloud-paginaconcurrentie | Batch tot 5.000 URL’s (afhankelijk van abonnement) | 50 pagina’s tegelijk |
| Export naar Notion/Airtable | Via webhook (betaalde abonnementen) | Native, gratis |
| Planning | Voorinstellingen + aangepaste timingbediening | Beschrijving in natuurlijke taal |
| Anti-bot / CAPTCHA-afhandeling | Proxymodi beschikbaar (afhankelijk van abonnement) | Automatisch, zonder configuratie |
| Gratis versie | 100 cloud credits + onbeperkte browser + 3 recipes | 6 pagina’s met volledige AI-functies + gratis exports |
Kortom: Simplescraper blinkt uit in eenvoudige, visuele extractie met weinig setup, waarbij af en toe handmatige afstelling acceptabel is. Thunderbit neemt het over waar dat model stukloopt — door paginainterpretatie, lay-outaanpassing en workflowcomplexiteit op zich te nemen, zodat jij dat niet hoeft te doen.
Geen van beide tools is universeel beter. Ze zitten op verschillende punten van de complexiteitscurve — en dat is prima.
Snel overzicht: checklist met Simplescraper-best practices
Sla dit op voor je volgende scraping-sessie:
- Test altijd eerst op een kleine steekproef. Controleer het aantal rijen en de volledigheid van de velden op 2–3 pagina’s voordat je opschaalt.
- Scrol de pagina vóór het scrapen om lui geladen content te activeren.
- Gebruik “Include Similar” wanneer de list-detectie te smal lijkt.
- Kies je scrapingmodus bewust. Browser voor sites waarvoor inloggen nodig is; cloud voor openbare pagina’s en geplande jobs.
- Stel vertragingen tussen requests in — minimaal 2–5 seconden voor commerciële sites, langer voor targets met sterke anti-botbeveiliging.
- Ken je gratis-versie-math. 100 cloud credits = 50 JavaScript-ingeschakelde pagina’s. Plan daarop.
- Sla recipes alleen op voor stabiele pagina’s. Als een site vaak wordt bijgewerkt, breken recipes.
- Leer de basis van CSS-selectors als fallback. Classnamen en data-attributen zijn beter dan positionele selectors.
- Monitor blokkades proactief. Als je lege resultaten of CAPTCHA’s krijgt, vertraag of schakel van modus.
- Herken het plafond. Als onderhoudstijd langer wordt dan datagebruikstijd, evalueer alternatieven.
Conclusie: maak elke scrape de moeite waard
De belangrijkste les uit meer dan duizend scrapes gaat niet over één specifieke tool. Het is dat de aanpak belangrijker is dan de software. Begrijpen waarom een scrape mislukt — lui laden, verkeerde modus, agressieve anti-bot, kwetsbare selectors — is waardevoller dan welke featurelijst dan ook.
Simplescraper werkt echt goed voor eenvoudige extractie-opdrachten. Als je pagina’s netjes zijn, je behoeften bescheiden zijn en je af en toe handmatige afstelling niet erg vindt, levert het prima resultaat.
Maar als je merkt dat je meer met de tool vecht dan dat je hem gebruikt — selectors debuggen, kapotte recipes opnieuw bouwen, proxies configureren, pagina’s handmatig scrollen — dan is dat een signaal, geen persoonlijke mislukking. Het betekent dat je bent ontgroeid aan wat visueel scrapen alleen aankan.
Als dat herkenbaar klinkt, probeer dan — zes pagina’s met volledige AI-functies, gratis exports naar Sheets, Airtable en Notion. Vergelijk het met je huidige workflow en kijk wat blijft hangen. Soms is de beste best practice weten wanneer je helemaal naar een andere tool moet grijpen.
FAQ’s
Is Simplescraper gratis te gebruiken?
Ja, Simplescraper heeft een gratis plan met onbeperkt lokaal browser scrapen, , 3 opgeslagen recipes en CSV/JSON-export. JavaScript-ingeschakelde cloudpagina’s kosten 2 credits per stuk, dus die 100 credits dekken ongeveer 50 pagina’s in cloudmodus. Betaalde plannen beginnen bij $39 per maand (Plus) voor 6.000 credits en $70 per maand (Pro) voor 15.000 credits.
Kan Simplescraper websites met veel JavaScript aan?
Soms. De cloudmodus van Simplescraper kan JavaScript renderen en de tool claimt ondersteuning voor single-page apps. Toch kunnen complexe SPA’s met zware dynamische rendering, oneindige scroll of agressieve anti-botsystemen nog steeds onvolledige resultaten opleveren. Cloudmodus met passende wachttijden verbetert de betrouwbaarheid, maar sterk dynamische sites blijven een uitdaging voor elke visuele scraper.
Wat is het verschil tussen cloud- en browser scraping in Simplescraper?
Browser scraping draait lokaal in je Chrome-browser — het gebruikt je actieve sessie (handig voor sites waarvoor inloggen nodig is), kost geen credits, maar vereist dat je computer aan blijft. draait op de servers van Simplescraper — het is sneller, draait zonder toezicht, ondersteunt planning en integraties, maar kost credits per pagina en kan geen pagina’s bereiken achter je persoonlijke login.
Wanneer moet ik overstappen van Simplescraper naar een alternatief zoals Thunderbit?
Het duidelijkste signaal is wanneer onderhoudstijd groter wordt dan datagebruikstijd. Als je regelmatig kapotte selectors repareert na site-updates, handmatig proxies instelt, recipes opnieuw bouwt of meer tijd kwijt bent aan troubleshooting dan aan het analyseren van je geëxtraheerde data, ben je de grens voorbij van wat handmatige visuele scraping efficiënt kan bieden. Tools zoals die AI gebruiken om de paginastructuur bij elke run te interpreteren, nemen het grootste deel van die onderhoudslast weg.
Hoe voorkom ik dat ik word geblokkeerd tijdens het scrapen met Simplescraper?
Drie belangrijke praktijken: ten eerste, doseer je verzoeken met 2–5 seconden vertraging tussen pagina’s (langer voor sites met sterke anti-botbeveiliging zoals Amazon of Yelp). Ten tweede, gebruik browsermodus als fallback voor sites die cloud-IP’s agressief blokkeren — je browsersessie lijkt meer op normaal verkeer. Ten derde, schakel proxyrotatie in voor grote batchjobs op gevoelige targets, maar controleer wel eerst welke proxy-opties in je abonnement zitten voordat je erop vertrouwt.
Meer leren