

De online wereld verandert in een moordend tempo, en websites bewegen net zo snel mee. In al die jaren dat ik met SaaS en automatisering werk, heb ik één ding goed geleerd: soms is het slimmer om te bouwen op wat er al is, in plaats van alles zelf uit te vinden. Of je nu een concurrent wilt analyseren, een nieuw productconcept test of gewoon een back-up van je eigen site wilt maken, de mogelijkheid om elke website te klonen—dus de inhoud, structuur of zelfs de functionaliteit overnemen—kan je team echt een flinke voorsprong geven. Dankzij slimme AI-tools zoals Thunderbit is deze aanpak niet meer alleen voor techneuten, maar voor iedereen die een browser kan bedienen.
Maar laten we eerlijk zijn: een website klonen is niet gewoon “Opslaan als” aanklikken. Moderne sites zijn dynamisch, interactief en soms net zo lastig te pakken als een paling in een emmer snot. In deze gids leg ik uit wat “elke website klonen” nu écht betekent, waarom het waardevol is voor bedrijven, welke hobbels je tegenkomt, en—het belangrijkste—hoe je het veilig, slim en legaal doet met tools als Thunderbit.
Elke Website Klonen: Wat Betekent Dat Nu Precies?
Laten we bij het begin beginnen. Als mensen het hebben over “een website klonen”, bedoelen ze vaak verschillende dingen:
- Het design klonen: Een site maken die er precies zo uitziet en aanvoelt als het origineel.
- De inhoud klonen: Teksten, afbeeldingen, productinfo en andere zichtbare data overnemen.
- De functionaliteit klonen: Dingen als zoekbalken, formulieren of interactieve onderdelen namaken.
Voor de meeste zakelijke gebruikers draait het vooral om het kopiëren van zichtbare content en data—dus alles wat je kunt zien en analyseren, niet per se de achterliggende code of unieke logica. Zie het als een momentopname van de publieke kant van een website, die je omzet in een gestructureerde dataset voor analyse, prototyping of archivering.
En even voor de duidelijkheid: klonen is niet hetzelfde als stelen of plagiaat. De meeste toepassingen zijn helemaal legitiem—denk aan concurrentieonderzoek, snel prototypen of het maken van een offline archief voor compliance. Het doel is tijd besparen en inzichten opdoen door te leren van wat werkt, niet om het wiel opnieuw uit te vinden of andermans werk te jatten.
Waarom Zou Je Een Website Klonen? Zakelijke Redenen
Je zou versteld staan hoeveel teams dagelijks gebruikmaken van website klonen. Hier zijn een paar veelvoorkomende zakelijke toepassingen:
| Toepassing | Beschrijving & Zakelijk Voordeel |
|---|---|
| Prijsmonitoring bij concurrenten | Scrape productpagina’s van concurrenten om prijzen en voorraad te volgen. Maakt dynamische prijsstelling mogelijk—een Britse retailer zag een 4% stijging in de omzet. |
| Leadgeneratie & CRM-verrijking | Klonen van bedrijvengidsen of LinkedIn-pagina’s om leads te verzamelen. Automatisering hiervan kan tot 80% tijd besparen. |
| Content hergebruiken | FAQ’s, blogs of reviews dupliceren om inzichten te verzamelen of informatie opnieuw te verpakken voor je eigen doelgroep. |
| Snel prototypen & design | De front-end van bestaande sites klonen om nieuwe projecten snel te starten—prototypen in dagen in plaats van weken. |
| Back-up & archivering | Volledige kopieën van websites maken voor compliance of archiefdoeleinden. |
En dat is nog maar het begin. Onderzoekers klonen social media-pagina’s om trends te spotten, SEO-specialisten kopiëren sitestructuren voor offline analyse, en bijna 2.700 prijsvergelijkingswebsites draaien op gescrapete webdata. De winst zit in snelheid en inzicht—in plaats van handmatig data verzamelen of design namaken, heb je alles in één keer binnen.
De Uitdagingen van Website Klonen: Het Is Niet Gewoon Kopiëren en Plakken
Als het klonen van een website zo simpel was als “Kopieer > Plak”, zou iedereen het doen. Maar wie het geprobeerd heeft, weet dat het vaak wat lastiger ligt.
Waarom Simpel Kopiëren Niet Genoeg Is
- Dynamische content: Veel sites laden data via JavaScript, waardoor een simpele “Pagina opslaan als” je achterlaat met een lege pagina zonder afbeeldingen of actuele data (zie dit experiment).
- API’s en scripts: Sommige content wordt pas na het laden van de pagina opgehaald. Alleen de HTML kopiëren is dan niet voldoende.
- Inlogvereisten: Staat de info achter een login, dan heb je een tool nodig die met ingelogde sessies kan werken.
- Anti-scraping maatregelen: Sites kunnen CAPTCHAs, limieten of botdetectie inzetten om automatisch kopiëren te blokkeren.
- Juridische en ethische grenzen: Dat je iets kunt kopiëren, betekent niet dat je het mag. Auteursrecht en gebruiksvoorwaarden zijn belangrijk.
Kortom, een website klonen vraagt om technische kennis én verantwoordelijkheidsgevoel. Het draait niet alleen om data binnenhalen, maar om het goed en netjes te doen.
Vergelijking van Website Klonen Tools: Van Handmatig tot AI-gedreven
Laten we het over tools hebben. Er zijn verschillende manieren om een website te klonen, elk met hun eigen voor- en nadelen:
| Methode | Gebruiksgemak | Nauwkeurigheid | Dynamische Content | Exportopties | Juridische Naleving | Onderhoud |
|---|---|---|---|---|---|---|
| Handmatig kopiëren/downloaden | Gemiddeld | Laag | Slecht | HTML/CSS/JS | Afhankelijk van gebruiker | Hoog (breekt snel) |
| Traditionele webscraping | Laag | Hoog* | Goed* | CSV/Excel/JSON | Afhankelijk van gebruiker | Hoog (kwetsbaar) |
| AI-gedreven tools (Thunderbit) | Zeer hoog | Hoog | Uitstekend | Excel/Sheets/Notion | Gebruiksvriendelijk | Laag |
*Als je weet wat je doet en het goed instelt.
Handmatig Kopiëren/Downloaden
Tools als HTTrack of de “Pagina opslaan als”-functie van je browser werken voor simpele, statische sites, maar zijn arbeidsintensief en falen bij dynamische content. Je eindigt vaak met ontbrekende afbeeldingen, kapotte opmaak en een wirwar aan bestanden.
Traditionele Webscraping
Dit betekent zelf scripts schrijven (Python, BeautifulSoup, enz.) of visuele scrapers gebruiken waarbij je zelf aangeeft wat je wilt extraheren. Krachtig, maar je moet wel kunnen programmeren of veel instellen. Onderhoud is lastig—verandert de site, dan werkt je scraper vaak niet meer.
AI-gedreven Tools (Thunderbit)
Hier wordt het pas echt interessant. Thunderbit gebruikt AI om de pagina te “begrijpen”, zodat je niet alles handmatig hoeft aan te wijzen. Klik op “AI Suggest Fields” en de tool pikt automatisch relevante data op—zoals productnaam, prijs, afbeelding, beoordeling, enzovoort. Het werkt met dynamische content, kan meerdere pagina’s doorlopen en exporteert direct naar Excel, Google Sheets, Airtable of Notion. En het is gemaakt voor niet-technische gebruikers—je hoeft geen regel code te schrijven.
Wil je meer weten over webscraper Chrome-extensies? Check deze vergelijking.
Stappenplan: Zo Kloon Je Elke Website met Thunderbit
Hoe scrape je elke website met AI Get Started Free
Klaar om te beginnen? Zo kloon ik elke website met Thunderbit, stap voor stap.
Stap 1: Installeer en Zet Thunderbit Klaar
Ga eerst naar de Thunderbit website en maak gratis een account aan. Installeer daarna de Thunderbit AI-webscraper Chrome-extensie. Installeren is net zo makkelijk als elke andere extensie—een paar klikken en je bent klaar.
Na installatie zie je het Thunderbit-icoon in je Chrome-balk. Klik erop, log in en je kunt je eerste project starten. Tip: zet het icoon vast zodat je het altijd bij de hand hebt. Moet je een site scrapen waar je voor moet inloggen? Log dan eerst in—Thunderbit werkt met je huidige browsersessie.
Probeer Thunderbit AI-webscraper gratis
Stap 2: Gebruik AI om Data te Herkennen en Structureren
Navigeer naar de website die je wilt klonen (bijvoorbeeld een productpagina van een concurrent). Open het Thunderbit-zijpaneel en start een nieuw scrapingproject. Hier gebeurt het magische: klik op “AI Suggest Columns” (soms “AI Suggest Fields” genoemd) en Thunderbit’s AI scant de pagina en stelt automatisch relevante datavelden voor—zoals productnaam, prijs, afbeelding, beoordeling, enzovoort.
Je kunt de voorgestelde kolommen aanpassen of extra velden toevoegen. Wil je bijvoorbeeld “Beschikbaarheid” of “SKU-nummer” meenemen? Voeg het toe en de AI vult het zo goed mogelijk in. Je hoeft geen HTML te kennen—de AI doet het zware werk.
Stap 3: Scrape en Exporteer de Website Data
Als je kolommen klaar zijn, klik je op “Scrape” (of “Start”). Thunderbit haalt alle data op voor de geselecteerde velden, rij voor rij. Heeft de pagina meerdere items (zoals een productlijst), dan worden ze allemaal meegenomen.
En wat als er paginering of oneindig scrollen is? Thunderbit regelt dit meestal automatisch—bij een “Volgende”-knop of scroll-to-load patroon gaat hij gewoon door. Voor lastige gevallen kun je handmatig scrollen of geavanceerde instellingen gebruiken, maar voor de meeste zakelijke sites werkt het vlekkeloos.
Na het scrapen zie je je data overzichtelijk in een tabel. Exporteren is simpel: stuur het direct naar Excel, Google Sheets, Airtable of Notion. Geen gedoe met CSV’s—gewoon gestructureerde data, klaar voor gebruik.
Meer weten? Bekijk Thunderbit’s handleiding voor AI-webscraping.
Je Clone Uitbreiden: Subpagina’s Scrapen voor een Volledige Kopie
Subpagina’s scrapen met Thunderbit Get Started Free
Hier blinkt Thunderbit echt uit: subpagina’s scrapen. Veel websites tonen op de hoofdpagina alleen samenvattingen (zoals productnamen en prijzen), terwijl de details—beschrijvingen, specificaties, reviews—op aparte subpagina’s staan.
Met subpagina-scraping van Thunderbit kun je dieper gaan. Zet deze functie aan en de AI volgt automatisch links van de hoofdpagina naar elke detailpagina, haalt de extra informatie op en voegt die samen in je dataset. Stel, je kloont een e-commerce categorie “winterjassen”—Thunderbit klikt dan op elke jas, haalt materiaal, beschikbaarheid, klantreviews en meer op, en levert zo een complete, gestructureerde kopie van het hele productaanbod.
Dit bespaart enorm veel tijd. Of je nu een volledige leadlijst bouwt, een kennisbank archiveert of een compleet productassortiment analyseert—met subpagina-scraping mis je niets.
Bekijk Thunderbit’s subpagina-scraping in de praktijk.
Wettelijk en Veilig: Zo Kloon Je Websites op de Juiste Manier
Laten we het belangrijkste punt bespreken: Is het legaal om elke website te klonen?
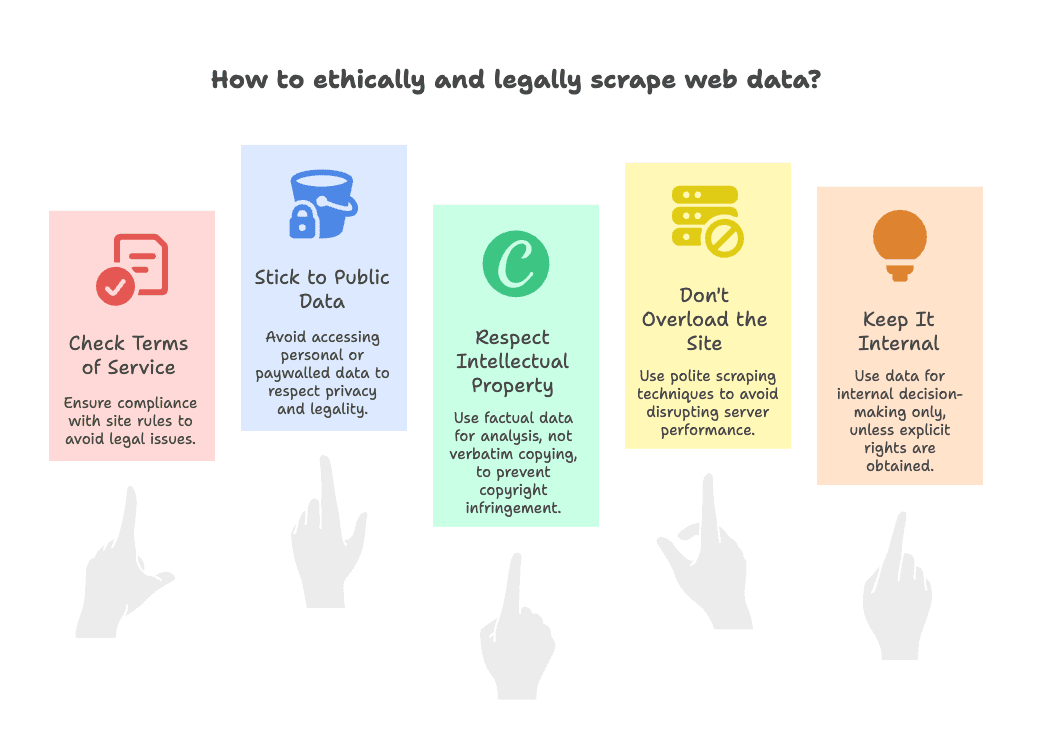
Het korte antwoord: meestal wel, zolang je je aan een paar basisregels houdt. Mijn compliance-checklist:
- Check de gebruiksvoorwaarden: Sommige sites verbieden scraping expliciet. Wees dan voorzichtig—gebruik de data alleen intern, niet voor publieke verspreiding (meer over juridisch risico).
- Blijf bij publieke data: Scrape alleen wat zichtbaar is zonder in te loggen. Vermijd persoonlijke gegevens, e-mails of alles achter een betaalmuur (zie juridische richtlijnen).
- Respecteer intellectueel eigendom: Feitelijke data (prijzen, productnamen) is meestal prima. Creatieve content letterlijk kopiëren (zoals blogs of afbeeldingen) kan een auteursrechtprobleem zijn—gebruik het voor analyse, niet om een kopie van de site te maken (meer over IP).
- Overbelast de site niet: Scrape netjes—stuur niet duizenden verzoeken per seconde. Thunderbit heeft ingebouwde limieten, maar wees altijd beleefd (robots.txt info).
- Gebruik het intern: Tenzij je expliciet toestemming hebt, gebruik gekloonde data alleen voor interne besluitvorming, niet voor publieke verspreiding.
Thunderbit helpt je compliant te blijven door data direct te exporteren naar veilige platforms zoals Google Sheets of Airtable, zodat je data binnen je organisatie blijft. Meer weten? Lees deze uitgebreide gids.
Geavanceerde Tips: Haal Alles uit Thunderbit bij het Klonen van Websites
Heb je de basis onder de knie? Met deze tips haal je nog meer uit website klonen:
- Pak dynamische en interactieve sites aan: Verschijnt content pas na een klik (zoals “Toon alle reviews”)? Voer de actie uit en start dan Thunderbit. De AI pakt alles wat zichtbaar is. Bij oneindig scrollen: scroll in delen of gebruik de ingebouwde paginering (meer tips hier).
- Aangepaste AI-prompts: Geef de AI duidelijke kolomnamen—zoals “Auteur (tekst na Door:)” of “Voordelen samenvatting”. Thunderbit’s AI herkent context, dus heldere namen werken als mini-instructies (zie voorbeelden).
- AI voor datatransformatie: Gebruik Thunderbit’s AI Samenvatten-functie of koppel met tools als ChatGPT om data direct te analyseren, categoriseren of vertalen (integratie-ideeën).
- Plannen voor doorlopende clones: Stel geplande scrapes in om sites periodiek te monitoren—ideaal voor prijsmonitoring of nieuwe vacatures (cloud scraping info).
- Bulk-URL scraping: Geef Thunderbit een lijst met URL’s en hij scrapet ze allemaal automatisch—handig als je de links al hebt verzameld.
- Templates voor populaire sites: Gebruik Thunderbit’s kant-en-klare sjablonen voor sites als Amazon of Zillow en pas ze aan naar wens (template details).
- Omgaan met uitzonderingen: Krijg je te maken met CAPTCHAs of vreemde layouts? Probeer de scraper in twee rondes of pas je kolommen aan. Thunderbit’s AI is flexibel, maar een snelle controle kan nooit kwaad.
Voor nog meer geavanceerde workflows, bekijk Thunderbit’s API- en integratieopties.
Kloon elke website met Thunderbit AI
Samenvatting & Belangrijkste Leerpunten: Kloon Websites met Vertrouwen
Websites klonen is niet langer alleen voor techneuten—het is een praktische, toegankelijke techniek voor sales, marketing en operations. Dit zijn de belangrijkste punten:
- Zakelijke waarde: Website klonen levert direct rendement op—of je nu sneller werkt, concurrenten voorblijft of slimmere beslissingen neemt (branchecijfers).
- Uitdagingen & oplossingen: Moderne sites zijn complex, maar met tools als Thunderbit wordt klonen snel, accuraat en eenvoudig—ook voor niet-technische gebruikers.
- Thunderbit-voordeel: Met functies als “AI Suggest Columns” en subpagina-scraping maak je van uren werk een kwestie van twee klikken.
- Compliance telt: Kloon altijd verantwoord—blijf bij publieke data, respecteer IP en gebruik de data voor analyse of interne besluitvorming.
- Ga verder: Met geavanceerde tips en integraties kan Thunderbit zelfs de lastigste sites en workflows aan.
Dus de volgende keer dat je een productpagina van een concurrent, een leads-directory of een kennisbank wilt analyseren—weet dat je nu de tools hebt om de data van die website met vertrouwen te klonen. Gebruik deze kracht verstandig, en laat je datagedreven projecten groeien.
Probeer Thunderbit AI-webscraper nu Get Started Free
Veelgestelde Vragen
1. Is het legaal om een website te klonen voor zakelijk gebruik?
Over het algemeen wel—zolang je je beperkt tot publieke data, intellectueel eigendom respecteert en de data intern gebruikt. Controleer altijd de gebruiksvoorwaarden van de site en scrape geen persoonlijke of auteursrechtelijk beschermde content zonder toestemming. Zie deze juridische gids.
2. Wat is het verschil tussen een website klonen en scrapen?
Klonen betekent meestal een kopie maken van de content, structuur of het design van een site, terwijl scrapen het gericht extraheren van specifieke data is. Met tools als Thunderbit vervaagt die grens—je kunt data scrapen en structureren om precies de onderdelen te klonen die je nodig hebt.
3. Kan Thunderbit omgaan met dynamische content en subpagina’s?
Zeker! Thunderbit’s AI is gemaakt om dynamische content (zoals data die via JavaScript wordt geladen) te verwerken en kan links volgen om subpagina’s te scrapen, waarbij alle info in één dataset wordt samengevoegd. Het is een van de makkelijkste manieren om een complete website te klonen.
4. Hoe exporteer ik gekloonde website-data naar Excel of Google Sheets?
Na het scrapen met Thunderbit kun je je data direct exporteren naar Excel, Google Sheets, Airtable of Notion—met slechts een paar klikken. Handmatig formatteren is niet nodig; je data is direct klaar voor analyse of delen.
5. Wat zijn geavanceerde tips voor het klonen van lastige websites?
Gebruik aangepaste AI-prompts voor nauwkeurige veldextractie, plan regelmatige scrapes voor doorlopende monitoring en maak gebruik van Thunderbit’s bulk-URL- en templatefuncties voor efficiëntie. Bij interactieve sites: voer handelingen handmatig uit vóór het scrapen en controleer altijd je data op juistheid.




