
Als je ooit hebt geprobeerd data te halen van een website die content pas laadt terwijl je scrolt, prijzen achter een login verstopt of het ontwerp om de paar weken wijzigt, dan weet je hoe frustrerend dat kan zijn. Statische scrapers schieten tegenwoordig simpelweg tekort. Sterker nog: meer dan vertrouwt inmiddels op webscraping voor alternatieve data, en automatiseert concurrentieprijsbewaking. Maar daar zit meteen de crux: een groot deel van die data staat op dynamische sites, wordt geladen met JavaScript en zit verstopt achter gebruikersinteracties. Daar komen headless browser-automatisering en tools zoals Puppeteer om de hoek kijken.
Als iemand die jarenlang heeft gebouwd aan automation- en AI-tools (en ja, ook zijn deel van websites heeft gescrapet voor sales- en ops-teams), heb ik uit eerste hand gezien hoe Puppeteer data kan ontsluiten die traditionele scrapers missen. Maar ik heb ook gezien hoe de hoeveelheid code voor zakelijke gebruikers een dealbreaker kan zijn. In deze gids leg ik je precies uit wat een Puppeteer scraper is, hoe je hem gebruikt voor webscraping en wanneer je misschien beter kunt kiezen voor iets nog simpelers — zoals , onze AI-gestuurde, no-code webscraper.
Wat is een Puppeteer Scraper? Een korte uitleg
 Laten we bij de basis beginnen. is een open-source Node.js-bibliotheek van Google waarmee je een headless Chrome- of Chromium-browser kunt aansturen met JavaScript. In gewone taal: het is alsof je een robot hebt die webpagina’s kan openen, op knoppen kan klikken, formulieren kan invullen, kan scrollen en — het belangrijkste — data kan extraheren, allemaal zonder dat er iets op je scherm zichtbaar is.
Laten we bij de basis beginnen. is een open-source Node.js-bibliotheek van Google waarmee je een headless Chrome- of Chromium-browser kunt aansturen met JavaScript. In gewone taal: het is alsof je een robot hebt die webpagina’s kan openen, op knoppen kan klikken, formulieren kan invullen, kan scrollen en — het belangrijkste — data kan extraheren, allemaal zonder dat er iets op je scherm zichtbaar is.
Wat maakt Puppeteer bijzonder?
- Het kan dynamische content renderen — dat betekent dat het wacht tot JavaScript is geladen, net als een echte gebruiker.
- Het kan gebruikersacties simuleren: klikken, typen, scrollen en zelfs pop-ups afhandelen.
- Het is ideaal voor het scrapen van sites waar data pas zichtbaar wordt na interactie, zoals e-commerceoverzichten, social feeds of dashboards.
Hoe verhoudt het zich tot andere tools?
- Selenium: de OG van browserautomatisering. Werkt met veel browsers en talen, maar is zwaarder en wat ouderwets. Geweldig voor cross-browser testing, maar Puppeteer is vlotter voor Chrome/Node.js-projecten.
- Thunderbit: hier word ik enthousiast van. Thunderbit is een no-code, AI-gestuurde webscraper die in je browser draait. In plaats van scripts te schrijven, klik je gewoon op ‘AI Suggest Fields’ en laat je de AI bepalen wat er moet worden uitgelezen. Perfect voor zakelijke gebruikers die resultaat willen zonder code (daarover later meer).
Kortom: Puppeteer = maximale controle (als je codeert). Thunderbit = maximaal gemak (als je niet wilt coderen).
Waarom Puppeteer-webscraping belangrijk is voor zakelijke gebruikers
Laten we eerlijk zijn: webscraping is allang niet meer alleen voor hackers of data scientists. Sales-, operations-, marketing- en zelfs vastgoedteams gebruiken webdata om voorsprong te krijgen. En met zoveel bedrijfskritische informatie die achter dynamische sites zit, is Puppeteer vaak de sleutel om die data vrij te spelen.
Hier zijn een paar praktijkvoorbeelden:
| Use case | Wie profiteert | Impact / ROI |
|---|---|---|
| Leadgeneratie | Sales, Biz Dev | Automatiseer het opbouwen van prospectlijsten; bespaar meer dan 8 uur per week per vertegenwoordiger (case study) |
| Prijsmonitoring | E-commerce, Product Ops | Tracking van concurrenten in realtime; één enterprise bespaarde $3,8M per jaar (bron) |
| Marktonderzoek | Marketing, Strategie, Finance | 67% van de beleggingsadviseurs gebruikt webscraped data; in sommige gevallen tot 890% ROI (bron) |
| Aggregatie van vastgoed | Makelaars, analisten | Scrape 50+ vastgoedpagina’s in minuten in plaats van uren (bron) |
| Compliance-monitoring | Operations, Legal | Automatiseer monitoring; één verzekeraar voorkwam $50M aan boetes (bron) |
En laten we niet vergeten: besteedt een kwart van de werkweek aan repetitieve taken zoals dataverzameling. Dit automatiseren met webscraping is dus niet alleen handig — het levert ook echt concurrentievoordeel op.
Aan de slag: je Puppeteer scraper opzetten
Klaar om de handen uit de mouwen te steken? Zo krijg je Puppeteer binnen 10 minuten aan de praat (ervan uitgaande dat je een beetje comfortabel bent met JavaScript):
1. Installeer Node.js
Puppeteer draait op Node.js. Download de nieuwste LTS-versie van .
2. Maak een nieuwe projectmap
Open je terminal en voer uit:
1mkdir puppeteer-scraper-demo
2cd puppeteer-scraper-demo
3npm init -y3. Installeer Puppeteer
1npm install puppeteerHiermee wordt ook een compatibele versie van Chromium gedownload (ongeveer 100 MB).
4. Maak je eerste script
Maak een bestand aan met de naam scrape.js:
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('https://example.com', { waitUntil: 'domcontentloaded' });
6 const title = await page.title();
7 console.log('Paginatitel:', title);
8 await browser.close();
9})();Start het met:
1node scrape.jsAls je “Paginatitel: Example Domain” ziet, gefeliciteerd — je hebt Chrome zojuist geautomatiseerd!
Je eerste Puppeteer webscraping-script bouwen
Laten we praktisch worden. Stel dat je quotes wilt scrapen van (een demo-site voor scrapers).
Stap 1: Ga naar de pagina
1await page.goto('http://quotes.toscrape.com', { waitUntil: 'networkidle0' });Stap 2: Extraheer data
1const quotes = await page.evaluate(() => {
2 return Array.from(document.querySelectorAll('.quote')).map(node => ({
3 text: node.querySelector('.text')?.innerText.trim(),
4 author: node.querySelector('.author')?.innerText.trim(),
5 tags: Array.from(node.querySelectorAll('.tag')).map(tag => tag.innerText.trim())
6 }));
7});
8console.log(quotes);Stap 3: Verwerk paginering
1let hasNext = true;
2let allQuotes = [];
3while (hasNext) {
4 // Quotes extraheren zoals hierboven
5 const quotes = await page.evaluate(/* ... */);
6 allQuotes.push(...quotes);
7 const nextButton = await page.$('li.next > a');
8 if (nextButton) {
9 await Promise.all([
10 page.click('li.next > a'),
11 page.waitForNavigation({ waitUntil: 'networkidle0' })
12 ]);
13 } else {
14 hasNext = false;
15 }
16}Stap 4: Opslaan als JSON
1const fs = require('fs');
2fs.writeFileSync('quotes.json', JSON.stringify(allQuotes, null, 2));En daar heb je het — een basis-Puppeteer scraper die navigeert, extraheert, pagineert en data opslaat.
Geavanceerde Puppeteer-scrapertechnieken: omgaan met dynamische content
De meeste echte sites zijn niet zo simpel als een statische lijst. Zo pak je de lastigere situaties aan:
1. Wachten op dynamische elementen
1await page.waitForSelector('.product-list-item');Zo weet je zeker dat de content die je nodig hebt geladen is voordat je hem probeert op te halen.
2. Gebruikersacties simuleren
- Klik op een knop:
await page.click('#load-more'); - Typ in een veld:
await page.type('#search', 'laptop'); - Scrollen voor infinite scroll:
1// Let op: page.waitForTimeout is verwijderd in Puppeteer v22. Gebruik in plaats daarvan een gewone promise. 2const sleep = (ms) => new Promise(r => setTimeout(r, ms)); 3let previousHeight = await page.evaluate('document.body.scrollHeight'); 4while (true) { 5 await page.evaluate('window.scrollTo(0, document.body.scrollHeight)'); 6 await sleep(1500); 7 const newHeight = await page.evaluate('document.body.scrollHeight'); 8 if (newHeight === previousHeight) break; 9 previousHeight = newHeight; 10}
1**3. Logins afhandelen**
2```javascript
3await page.goto('https://exampleshop.com/login');
4await page.type('#login-username', 'myusername');
5await page.type('#login-password', 'mypassword');
6await page.click('#login-button');
7await page.waitForNavigation({ waitUntil: 'networkidle0' });4. Omgaan met via AJAX geladen data Soms staat de data niet in de DOM, maar komt die via een API-call binnen. Je kunt netwerkresponses onderscheppen met:
1page.on('response', async response => {
2 if (response.url().includes('/api/products')) {
3 const data = await response.json();
4 // Verwerk data
5 }
6});Praktijkvoorbeeld: productdata scrapen van een e-commerce site
Laten we alles samenbrengen. Stel dat je productnamen, prijzen en afbeeldingen wilt scrapen van een (demo) e-commerce site na het inloggen.
1const puppeteer = require('puppeteer');
2const fs = require('fs');
3(async () => {
4 const browser = await puppeteer.launch({ headless: true });
5 const page = await browser.newPage();
6 // Stap 1: Inloggen
7 await page.goto('https://exampleshop.com/login');
8 await page.type('#login-username', 'myusername');
9 await page.type('#login-password', 'mypassword');
10 await page.click('#login-button');
11 await page.waitForNavigation({ waitUntil: 'networkidle0' });
12 // Stap 2: Ga naar de categoriepagina
13 await page.goto('https://exampleshop.com/category/laptops', { waitUntil: 'networkidle0' });
14 // Stap 3: Producten extraheren
15 const products = await page.evaluate(() => {
16 return Array.from(document.querySelectorAll('.product-item')).map(item => ({
17 name: item.querySelector('.product-title')?.innerText.trim() || '',
18 price: item.querySelector('.product-price')?.innerText.trim() || '',
19 image: item.querySelector('img.product-image')?.src || ''
20 }));
21 });
22 // Stap 4: Opslaan als JSON
23 fs.writeFileSync('products.json', JSON.stringify(products, null, 2));
24 await browser.close();
25})();Dit script logt in, navigeert, scrape’t en slaat alles automatisch op. Voor geavanceerdere behoeften kun je loops toevoegen voor paginering of zelfs op elk product klikken voor meer details.
Thunderbit: Puppeteer scraper eenvoudiger maken met AI
Als je zover bent gekomen en denkt: “Mooi, maar ik wil niet elke keer code schrijven als ik een nieuwe dataset nodig heb,” dan ben je niet de enige. Precies daarom hebben we gebouwd.
Wat maakt Thunderbit anders?
- Geen code nodig: installeer gewoon de , open de pagina die je wilt scrapen en klik op “AI Suggest Fields”.
- AI-gestuurde veldherkenning: Thunderbit leest de pagina en stelt de beste kolommen voor om te extraheren — zoals “Productnaam”, “Prijs”, “Afbeelding”, enzovoort.
- Kan met dynamische content overweg: infinite scroll, pop-ups en subpagina’s? De AI van Thunderbit kan ermee omgaan, door paginering te doorlopen of zelfs de detailpagina van elk product te bezoeken om je data te verrijken.
- Direct exporteren: stuur je data met één klik rechtstreeks naar Excel, Google Sheets, Notion of Airtable. Geen extra kosten voor exports.
- Templates voor populaire sites: Amazon, Zillow of LinkedIn scrapen? Thunderbit heeft direct inzetbare templates — geen setup nodig.
- Cloud- of browserscraping: voor grote klussen kan Thunderbit tot 50 pagina’s tegelijk in de cloud scrapen.
Ik heb gebruikers zien gaan van “Ik wou dat ik deze data kon krijgen” naar “Hier is mijn spreadsheet” in minder dan vijf minuten. En het mooiste? Geen gedoe meer met scripts die breken zodra een website verandert — de AI van Thunderbit past zich automatisch aan.
Puppeteer vs. Thunderbit: de juiste webscrapingtool kiezen
Dus, welke moet je gebruiken? Zo zou ik het voor teams opsplitsen:
| Factor | Puppeteer (code) | Thunderbit (no-code, AI) |
|---|---|---|
| Gebruiksgemak | Vereist JavaScript- en DOM-kennis | Klikken-en-klaar, AI stelt velden voor |
| Opstartsnelheid | Uren tot dagen voor complexe taken | Minuten — gewoon installeren en gaan |
| Controle/flexibiliteit | Maximaal: schrijf elke gewenste logica en koppel aan andere code | Sterk voor standaardgevallen; minder geschikt voor sterk aangepaste workflows |
| Dynamische content | Handmatig scripting voor waits, clicks en scrolls | Ingebouwde AI verwerkt dynamische content, paginering en subpagina’s automatisch |
| Onderhoud | Jij beheert de scripts — bijwerken wanneer sites veranderen | AI past zich aan lay-outwijzigingen aan; minder onderhoud voor de gebruiker |
| Data-export | Schrijf je eigen exportlogica | Export met één klik naar Excel, Sheets, Notion, Airtable, CSV, JSON |
| Het beste voor | Ontwikkelaars, sterk aangepaste of grootschalige scrapes | Zakelijke gebruikers, snelle projecten, niet-technische teams |
| Kosten | Gratis (behalve je tijd en eventuele infrastructuur) | Gratis tier beschikbaar; betaalde plannen op basis van credits (zie Thunderbit-prijzen) |
Kort samengevat:
- Gebruik Puppeteer als je totale controle nodig hebt, codecapaciteit hebt of scraping wilt integreren in een grotere app.
- Gebruik Thunderbit als je snel resultaat wilt, niet wilt coderen of niet-technische teamgenoten wilt ondersteunen.
Eerlijk gezegd heb ik teams beide zien gebruiken: Thunderbit voor snelle successen en prototypes, Puppeteer voor diepere integraties of randgevallen.
Stap-voor-stap checklist: een succesvol Puppeteer-webscrapingproject draaien
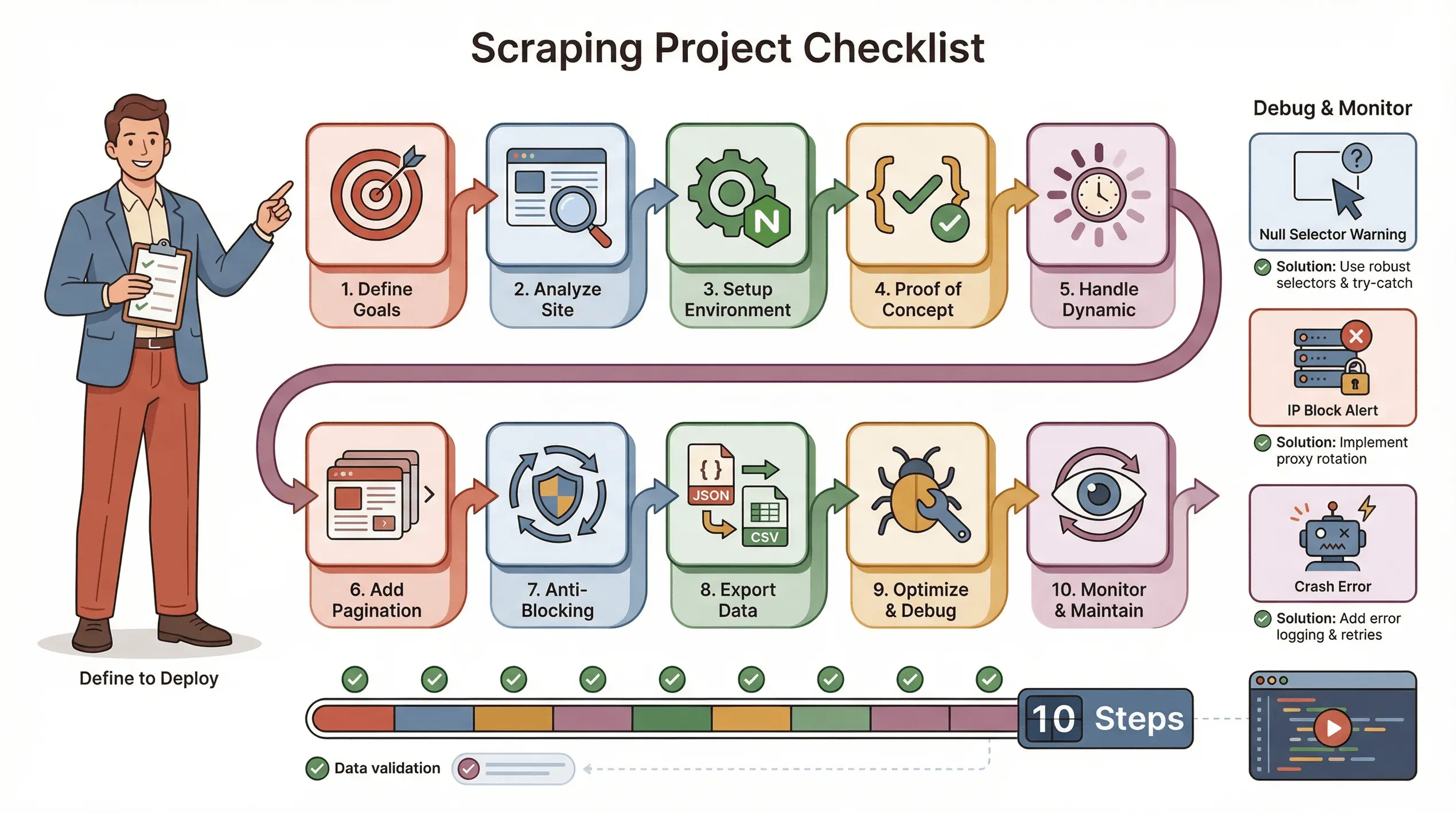 Hier is mijn vaste checklist voor een soepel Puppeteer-scrapingproject:
Hier is mijn vaste checklist voor een soepel Puppeteer-scrapingproject:
- Bepaal je doelen: welke data heb je nodig? Waar staat die?
- Analyseer de site: is die dynamisch? Is een login nodig? Zijn er anti-botmaatregelen?
- Richt je omgeving in: Node.js, Puppeteer en eventuele hulplibraries.
- Schrijf een proof of concept: begin met één pagina en krijg de selectors goed.
- Pak dynamische content aan: gebruik
waitForSelectoren simuleer indien nodig clicks/scrolls. - Voeg paginering of loops toe: scrape alle pagina’s, niet alleen één.
- Implementeer anti-blokkeermaatregelen: randomiseer vertragingen, stel een echte User-Agent in, gebruik indien nodig proxies.
- Exporteer en valideer data: sla op als JSON/CSV en controleer op volledigheid.
- Optimaliseer en handel fouten af: voeg try/catch toe, log voortgang en vang ontbrekende data netjes af.
- Monitor en onderhoud: sites veranderen — wees klaar om je script bij te werken.
Tips voor probleemoplossing:
- Als selectors null teruggeven, controleer de HTML en gebruik waits.
- Als je wordt geblokkeerd, vertraag, roteer IP’s of gebruik stealth-plug-ins.
- Als je script crasht, controleer op memory leaks of niet-afgehandelde exceptions.
Conclusie en belangrijkste lessen
Webscraping is uitgegroeid tot een onmisbare vaardigheid voor data-gedreven teams. Puppeteer geeft je de kracht om data te halen uit zelfs de meest dynamische, JavaScript-zware sites — maar daar heb je wel wat programmeerkennis en onderhoud voor nodig. Voor zakelijke gebruikers die de code willen overslaan en direct bij de data willen uitkomen, biedt Thunderbit een AI-gestuurd no-code alternatief dat snel, flexibel en verrassend robuust is.
Dit zou ik aanraden:
- Ben je technisch en heb je diepgaande maatwerkopties nodig? Begin dan met Puppeteer.
- Wil je snelheid, eenvoud en minder onderhoud? Probeer eens (de is een uitstekend startpunt).
- Voor de meeste teams dekt een mix van beide 99% van de behoeften aan webdata.
Meer van dit soort gidsen zien? Bekijk de voor tutorials, vergelijkingen en het laatste nieuws over AI-gestuurde webscraping.
FAQ’s
1. Wat is een Puppeteer scraper en waarom wordt die gebruikt voor webscraping?
Puppeteer is een Node.js-bibliotheek waarmee je een headless Chrome-browser kunt aansturen met JavaScript. Je gebruikt het voor webscraping omdat het dynamische content kan laden, gebruikersacties kan simuleren en data kan ophalen van sites die traditionele scrapers niet aankunnen.
2. Hoe verhoudt Puppeteer zich tot Selenium en Thunderbit?
Selenium werkt met meerdere browsers en talen, maar is zwaarder. Puppeteer is gestroomlijnd voor Chrome/Node.js en is voor veel scrapingtaken sneller. Thunderbit is daarentegen een no-code, AI-gestuurde tool waarmee niet-technische gebruikers met slechts een paar klikken data kunnen scrapen.
3. Wat zijn de belangrijkste zakelijke voordelen van Puppeteer-webscraping?
Het automatiseren van dataverzameling bespaart tijd, vermindert fouten en maakt realtime inzichten mogelijk voor sales, marketing, operations en meer. Use cases variëren van leadgeneratie tot prijsmonitoring en marktonderzoek.
4. Wat zijn de grootste uitdagingen bij Puppeteer-scraping?
De grootste uitdagingen zijn het omgaan met dynamische content, het ontwijken van anti-botblokkades en het onderhouden van scripts wanneer websites veranderen. Je moet code schrijven om waits te beheren, interacties te simuleren en fouten af te handelen.
5. Երբ moet ik Thunderbit gebruiken in plaats van Puppeteer?
Gebruik Thunderbit als je wilt coderen overslaan, snel resultaat nodig hebt of niet-technische teamgenoten wilt ondersteunen. Het is ideaal voor standaard scrapingtaken, snelle projecten of wanneer je data gewoon met minimale moeite naar Excel of Google Sheets wilt exporteren.
Klaar om een slimmere manier van scrapen te proberen? of verdiep je verder met meer gidsen op de . Veel scrape-plezier!
Meer weten