Als je ooit hebt geprobeerd een prijsoverzicht van concurrenten op te zetten, nieuw vastgoedaanbod te volgen of gewoon grip te houden op een enorme e-commercecatalogus, dan ken je de frustratie: urenlang kopiëren, plakken en rommelige data opschonen—om vervolgens te ontdekken dat de informatie alweer verouderd is zodra je klaar bent. In 2025, nu het web elk jaar met miljarden nieuwe pagina’s groeit, kan handmatige gegevensverzameling simpelweg niet meer bijbenen. Bedrijven zien steeds duidelijker een nieuwe realiteit: gestructureerde webdata is geen “leuk extraatje”, maar de ruggengraat van slimme besluitvorming, van sales en marketing tot operations en productstrategie.
Daar komen listing crawlers en geautomatiseerde listing-extractie om de hoek kijken. Ik heb uit eerste hand gezien hoe teams die AI-gestuurde tools zoals gebruiken, saaie, foutgevoelige research omzetten in een snel, schaalbaar en zelfs best leuk proces. Laten we eens kijken wat listing crawling nu echt betekent, hoe de nieuwste AI-oplossingen werken en hoe jij ze kunt inzetten om je bedrijf een serieus voordeel te geven—zonder ook maar één regel code te schrijven (of je gezonde verstand te verliezen).
Wat is een listing crawler? De basis van geautomatiseerde listing-extractie
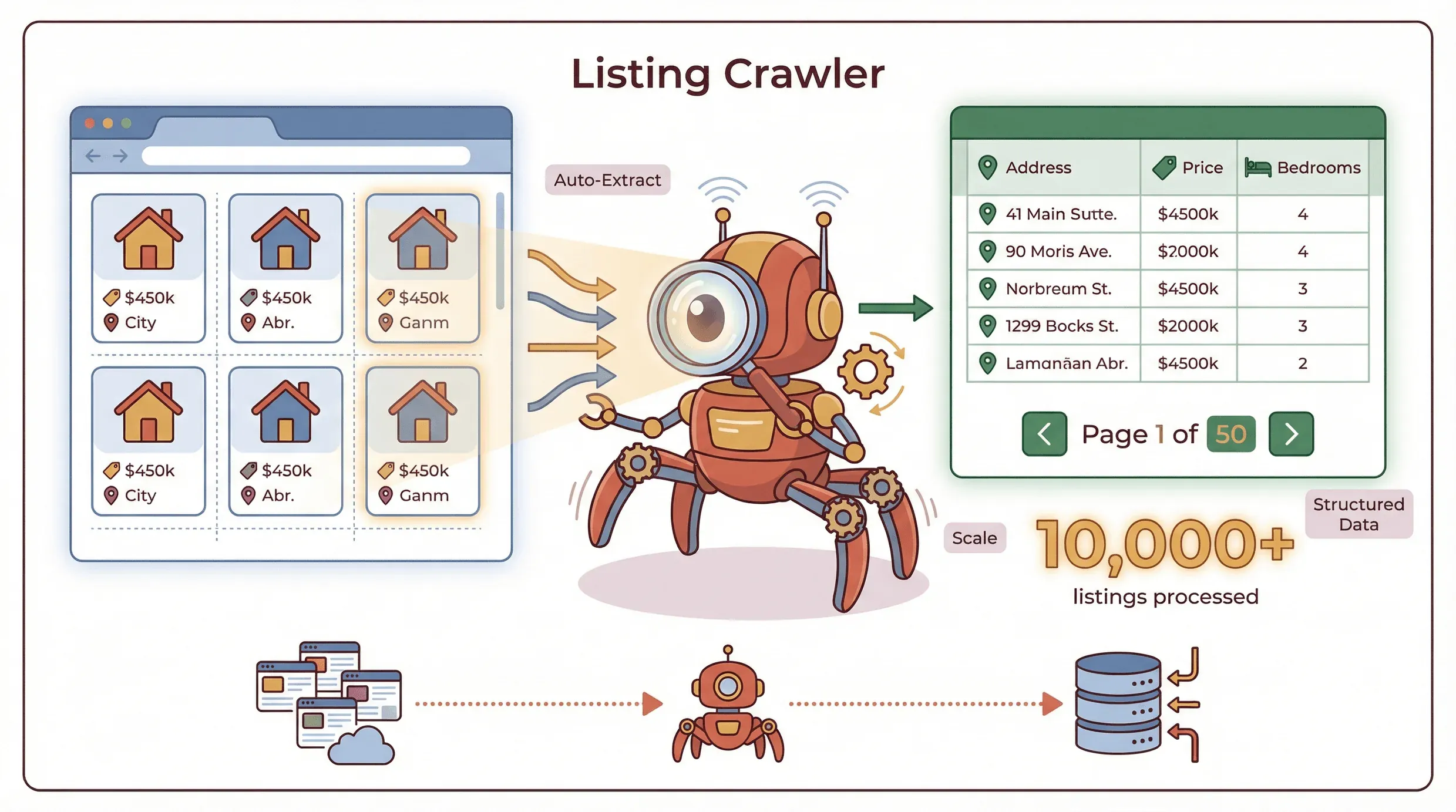 Een listing crawler is een gespecialiseerde tool die gestructureerde data extraheert van webpagina’s waarop meerdere items in een vaste indeling worden getoond—denk aan productcatalogi, woningaanbod, vacaturebanken of bedrijvengidsen. In tegenstelling tot algemene webscrapers, die data van vrijwel elke pagina kunnen halen (gestructureerd of niet), richt een listing crawler zich op repetitieve, gestructureerde content en kan hij moeiteloos opschalen over meerdere pagina’s, inclusief zaken als paginering en subpagina’s ().
Een listing crawler is een gespecialiseerde tool die gestructureerde data extraheert van webpagina’s waarop meerdere items in een vaste indeling worden getoond—denk aan productcatalogi, woningaanbod, vacaturebanken of bedrijvengidsen. In tegenstelling tot algemene webscrapers, die data van vrijwel elke pagina kunnen halen (gestructureerd of niet), richt een listing crawler zich op repetitieve, gestructureerde content en kan hij moeiteloos opschalen over meerdere pagina’s, inclusief zaken als paginering en subpagina’s ().
Hoe werkt het? Stel je voor dat je naar een vastgoedsite kijkt met 50 woningen per pagina. Een listing crawler kan automatisch de details van elke woning herkennen (adres, prijs, aantal slaapkamers, enz.), die netjes in een tabel zetten en vervolgens naar de volgende pagina “klikken” om door te gaan—zonder handmatig kopiëren. Geavanceerde crawlers kunnen zelfs links naar detailpagina’s (subpagina’s) volgen om extra informatie op te halen, zoals contactgegevens van de makelaar of beschrijvingen van de woning.
Belangrijkste verschil: Listing crawlers zijn gebouwd voor schaal en structuur. Het is alsof je een robotstagiair hebt die nooit moe wordt, nooit een typefout maakt en binnen enkele minuten duizenden listings kan verwerken.
Waarom geautomatiseerde listing-extractie belangrijk is voor bedrijven
Laten we praktisch worden: waarom geven zoveel teams—van sales tot product en operations—om geautomatiseerde listing-extractie? Hier zijn enkele van de belangrijkste toepassingen en de zakelijke waarde die ze opleveren:
| Use Case | Business Function | Benefit |
|---|---|---|
| Leadgeneratie (directories scrapen) | Sales / Biz Dev | Vul je CRM in minuten, niet in weken, met verse, gekwalificeerde leads |
| Prijsmonitoring van concurrenten (catalogi scrapen) | Marketing / Product | Realtime prijsinzichten, snellere strategische bijsturing, omzetgroei |
| Voorraad- en leveranciersmonitoring | Operations / Supply Chain | Actuele voorraadgegevens, voorkom tekorten, signaleer leveringswijzigingen direct |
| Marktonderzoek (listings/reviews bundelen) | Strategie / Analytics | Trendanalyse op schaal, betere productbeslissingen, volledig marktoverzicht |
| Vastgoedaanbod volgen | Vastgoed / Investeringen | Tijdige meldingen over nieuwe kansen, prijswijzigingen en vergelijkbare objecten |
De ROI is echt: bedrijven die geautomatiseerde listing crawlers gebruiken, rapporteren 30–40% tijdsbesparing bij dataverzameling (), en datanauwkeurigheid tot 99%—vergeleken met handmatige invoer, die 8× meer foutgevoelig is (). Wat vroeger een week kostte, kost nu minuten, en de data is klaar voor analyse in plaats van te blijven hangen in een spreadsheet.
Traditionele vs. AI-gestuurde listing crawlers: wat is het verschil?
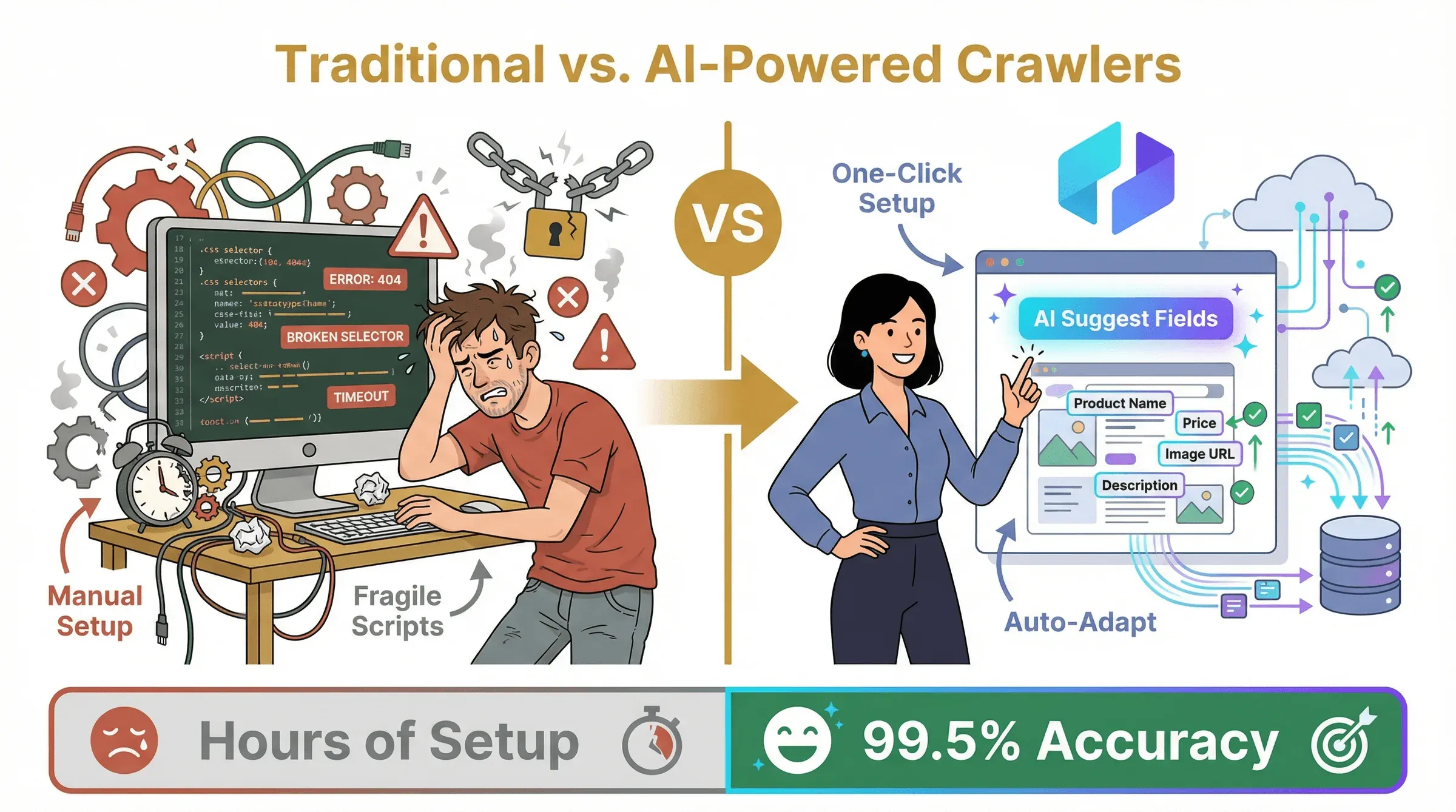 Laten we eerlijk zijn: traditionele listing crawlers (denk aan Scrapy, BeautifulSoup of zelfs sommige “no-code” tools) kunnen hun werk doen, maar ze brengen flink wat ballast met zich mee:
Laten we eerlijk zijn: traditionele listing crawlers (denk aan Scrapy, BeautifulSoup of zelfs sommige “no-code” tools) kunnen hun werk doen, maar ze brengen flink wat ballast met zich mee:
- Handmatige setup: Je moet CSS-selectors definiëren, scripts schrijven of templates bouwen voor elk veld dat je wilt extraheren.
- Kwetsbare workflows: Verandert de website van lay-out of class names, dan breekt je scraper—en begin je weer van voren af aan.
- Beperkte omgang met dynamische content: Infinite scroll, AJAX-content of interactieve elementen? Maak je klaar voor wat late avonden debuggen.
AI-gestuurde listing crawlers (zoals Thunderbit) draaien het om. In plaats van de tool te vertellen hoe hij data moet extraheren, laat je hem gewoon de pagina zien (of beschrijf je je doel), en laat je de AI de rest uitzoeken. De tool herkent patronen, past zich aan wijzigingen in de lay-out aan en kan zelfs dynamische content en subpagina’s aan—met minimale setup.
Belangrijkste voordelen van AI-gestuurde geautomatiseerde listing-extractie
- Snellere setup: Met één klik op “AI Suggest Fields” stelt de tool alle relevante kolommen voor—geen selectors of code nodig.
- Hogere nauwkeurigheid: AI-modellen herkennen data in context en schonen en dedupliceren onderweg. Nauwkeurigheid kan oplopen tot 99,5%, zelfs op rommelige pagina’s ().
- Bestand tegen wijzigingen: Als een site zijn HTML aanpast, past de AI zich aan—geen kapotte scripts of eindeloos onderhoud meer ().
- Kan overweg met dynamische content: Infinite scroll, pop-ups of AJAX? AI-crawlers kunnen met de pagina omgaan als een mens, zodat niets wordt gemist.
- Schaalbaarheid: Cloudgebaseerde AI-crawlers kunnen duizenden pagina’s parallel verwerken, met ingebouwde planning en automatisering.
Thunderbit listing crawler: snelle weg naar geautomatiseerde listing-extractie
Ik ben misschien een beetje bevooroordeeld—maar wel met reden. is gebouwd om listing crawling net zo makkelijk te maken als afhaalmaaltijden bestellen. Zo werkt het:
- Installeer de : Installeren kost twee klikken en je kunt meteen aan de slag.
- Navigeer naar een listingpagina: Open elke site—e-commerce, vastgoed, directories, noem maar op.
- Klik op “AI Suggest Fields”: Thunderbit’s AI scant de pagina en stelt de beste kolommen voor om te extraheren (bijv. Productnaam, Prijs, Afbeelding, URL).
- Pas kolommen aan (als je wilt): Hernoem, voeg toe of verwijder velden. Voeg aangepaste AI-prompts toe voor geavanceerde labels of opmaak.
- Klik op “Scrape”: Thunderbit haalt alle data op, handelt paginering af en kan zelfs subpagina’s bezoeken voor extra details.
- Exporteer direct: Stuur je data naar Excel, Google Sheets, Notion, Airtable of download als CSV/JSON—helemaal gratis.
Thunderbit wordt ook geleverd met directe templates voor populaire sites (Amazon, Zillow, Shopify, Instagram en meer), zodat je voor veelvoorkomende toepassingen helemaal geen setup nodig hebt. En als je PDF’s of afbeeldingen wilt scrapen, kan Thunderbit’s AI dat ook aan.
Thunderbit vs. andere listing crawlers: vergelijking naast elkaar
Zo verhoudt Thunderbit zich tot andere populaire tools:
| Feature | Thunderbit | Octoparse | Scrapy | Firecrawl | LinkUp |
|---|---|---|---|---|---|
| AI-veldvoorstel | ✅ | ⚠️ (basic) | ❌ | ✅ | ✅ |
| No-code setup | ✅ | ⚠️ | ❌ | ⚠️ | ⚠️ |
| Subpagina-scraping | ✅ | ⚠️ | ⚠️ | ✅ | ✅ |
| Voorgebouwde templates | ✅ | ✅ | ❌ | ❌ | ❌ |
| Export naar Sheets/Excel | ✅ | ✅ | ⚠️ | ⚠️ | ⚠️ |
| Gratis data-export | ✅ | ⚠️ | ✅ | ⚠️ | ⚠️ |
| Geplande scraping | ✅ | ✅ | ⚠️ | ✅ | ✅ |
| Onderhoud vereist | Minimaal | Gemiddeld | Hoog | Laag | Laag |
| Prijs (starter) | $15/maand | ~$119/maand | Gratis* | Varieert | Varieert |
*Scrapy is gratis, maar vereist ontwikkeltijd en infrastructuur.
Wat is Thunderbit’s sweet spot? Het is gebouwd voor niet-technische zakelijke gebruikers die snel resultaat willen—geen steile leercurve, geen verborgen exportkosten en geen gedoe wanneer websites veranderen.
Stapsgewijze handleiding: Thunderbit gebruiken voor geautomatiseerde listing-extractie
Klaar om het zelf te proberen? Zo gebruik je Thunderbit als je listing crawler:
1. Installeer Thunderbit
Ga naar de en voeg Thunderbit toe. Maak een gratis account aan (het gratis plan laat je tot 6 pagina’s scrapen, of 10 met een proefboost).
2. Open je doel-listingpagina
Navigeer naar de site die je wilt scrapen—bijvoorbeeld een productcategorie op Amazon, een Zillow-zoekopdracht of een bedrijvengids. Pas eventuele filters toe via de interface van de site zelf.
3. Klik op “AI Suggest Fields”
Klik op het Thunderbit-pictogram in je browser. Druk op “AI Suggest Fields”. Thunderbit’s AI leest de pagina en stelt kolommen voor zoals Productnaam, Prijs, URL, Afbeelding, enz.
4. Pas kolommen en prompts aan
Controleer de voorgestelde velden. Hernoem, voeg toe of verwijder kolommen waar nodig. Voor geavanceerde behoeften voeg je een Field AI Prompt toe (zoals “haal prijs alleen als getal op” of “label als ‘Luxe’ als prijs > $2.000”).
5. Paginering en subpagina’s afhandelen
Als je listing over meerdere pagina’s verspreid is, kan Thunderbit automatisch op “Volgende” klikken of een lijst met URL’s accepteren. Voor detailpagina’s klik je op “Scrape Subpages” en Thunderbit bezoekt elke link om extra informatie op te halen (zoals specificaties of contactgegevens).
6. Start de scrape
Klik op “Scrape”. Kijk hoe Thunderbit live een tabel vult met je data. Voor grote taken gebruik je Cloud Scraping voor snelheid (tot 50 pagina’s tegelijk).
7. Exporteer je data
Als je klaar bent, exporteer je direct naar Excel, Google Sheets, Notion of Airtable. Thunderbit uploadt indien nodig zelfs afbeeldingen naar Notion/Airtable.
Pro-tip: Sla je configuratie op als template voor later gebruik, of plan hem in zodat hij automatisch draait (zie hieronder).
Output aanpassen: filters en uitvoerformaten instellen
Thunderbit geeft je volledige controle over de output:
- Selecteer specifieke velden: Houd alleen de kolommen die je nodig hebt.
- Pas filters toe: Gebruik de filters van de website vóór het scrapen, of voeg logica toe in Field AI Prompts (bijv. “haal alleen listings op waar prijs < $500.000”).
- Kies uitvoerformaat: Exporteer als Excel, CSV, JSON, Google Sheets, Notion of Airtable.
- Geavanceerde transformatie: Gebruik Field AI Prompts voor opmaak, splitsen/samenvoegen van velden, conditionele extractie, categorisatie of zelfs vertaling (Thunderbit ondersteunt 34 talen).
Als je bijvoorbeeld listings wilt labelen als “Betaalbaar” of “Luxe” op basis van de prijs, voeg je gewoon een prompt toe: “Label als Luxe als prijs > $2.000, anders Betaalbaar.” Thunderbit doet de rest tijdens het scrapen.
Zakelijke upgrades: geautomatiseerde listing-extractie inzetten voor concurrentievoordeel
Zodra je gestructureerde listingdata hebt, zijn de mogelijkheden eindeloos:
- Concurrentieanalyse: Volg prijzen, nieuwe producten en voorraad van concurrenten in realtime. Een retailer verhoogde de omzet met 4% door gescrapete concurrentiedata te gebruiken ().
- Voorraadbeheer: Monitor sites van leveranciers op voorraadwijzigingen, prijsstijgingen of nieuwe SKU’s—automatisch.
- Leadgeneratie: Bouw gerichte lijsten op uit directories, LinkedIn of verenigingssites—en voer ze rechtstreeks in je CRM in.
- Marktonderzoek: Bundel reviews, productkenmerken of vastgoeddata voor trendanalyse en slimmere productbeslissingen.
- Content-aggregatie: Geef vergelijkingssites, review-aggregators of SEO-projecten power met altijd verse data.
Integreer je geëxporteerde data met analysetools (Tableau, PowerBI, Google Data Studio) voor dashboards, trendanalyse of voorspellende modellen. Met Thunderbit verzamel je niet alleen data—je bouwt een realtime concurrentieradar.
Dynamische monitoring: planning en realtime listing-extractie
Het web slaapt nooit, en jouw data zou dat ook niet moeten doen. Thunderbit’s Scheduled Scraper laat je doorlopende monitoring automatiseren:
- Stel een planning in: Beschrijf het gewoon in gewone taal (“elke dag om 7 uur” of “elke 4 uur”). Thunderbit’s AI regelt de rest.
- Voer je URL’s in: Scrape één pagina of een hele lijst—Thunderbit haalt ze volgens schema op.
- Exporteer naar Sheets/Airtable/Notion: Houd je data actueel en klaar voor je team elke ochtend.
Use cases:
- E-commerce: Volg dagelijks prijzen en voorraad van concurrenten—pas je eigen prijzen direct aan.
- Sales: Krijg wekelijks een verse leadlijst uit directories of vacaturebanken.
- Vastgoed: Monitor elk uur nieuwe listings of prijswijzigingen—wees als eerste in actie.
Geplande scraping betekent dat je altijd met de nieuwste data werkt—niet meer blind varen of haastig achter de feiten aan lopen.
Belangrijkste inzichten: schaal je data-extractie op met listing crawlers
- Gestructureerde webdata is onmisbaar voor modern zakendoen. Bedrijven die geautomatiseerde listing crawlers gebruiken, nemen sneller en slimmer beslissingen en zien echte ROI ().
- AI-tools zoals Thunderbit maken listing crawling toegankelijk voor iedereen. Geen code, geen templates, geen onderhoudsproblemen—alleen resultaat.
- Geautomatiseerde listing-extractie ontsluit concurrentievoordeel. Van prijsinformatie tot leadgeneratie: de data die je nodig hebt, is slechts een paar klikken verwijderd.
- Doorlopende monitoring is de nieuwe standaard. Met geplande scraping is je team altijd up-to-date—klaar om te reageren, analyseren en winnen.
- Beginnen is eenvoudig. Thunderbit biedt een royale gratis versie en directe exports—dus je kunt het zonder risico proberen op je volgende dataproject.
Klaar om handmatige dataverzameling achter je te laten? en ontdek hoe eenvoudig schaalbare, geautomatiseerde listing-extractie kan zijn. En als je dieper wilt gaan, bekijk dan de voor meer handleidingen, tips en praktijkvoorbeelden.
FAQ’s
1. Wat is het verschil tussen een listing crawler en een algemene webscraper?
Een listing crawler is gespecialiseerd in het extraheren van gestructureerde, repetitieve data (zoals producten of woningaanbod) van webpagina’s en kan paginering en subpagina’s op schaal verwerken. Algemene webscrapers kunnen data van alles extraheren, maar vereisen vaak meer handmatige setup en zijn niet geoptimaliseerd voor grote, gestructureerde lijsten.
2. Hoe bespaart Thunderbit’s AI-gestuurde listing crawler tijd vergeleken met handmatige methoden?
Thunderbit’s AI detecteert automatisch velden, verwerkt paginering en kan subpagina’s bezoeken—waardoor uren handmatig kopiëren en plakken veranderen in minuten geautomatiseerde extractie. De tool past zich ook aan aan websitewijzigingen, zodat je je workflow niet telkens opnieuw hoeft op te bouwen wanneer een site wordt bijgewerkt.
3. Kan ik Thunderbit gebruiken om prijzen van concurrenten of voorraad in realtime te monitoren?
Absoluut. Met Thunderbit’s geplande scraping kun je dagelijkse of uurlijkse monitoring instellen van listings, prijzen of voorraad van concurrenten. Data kan rechtstreeks worden geëxporteerd naar Google Sheets, Airtable of Notion voor live dashboards en meldingen.
4. Welke exportformaten ondersteunt Thunderbit?
Thunderbit laat je data exporteren naar Excel, CSV, JSON, Google Sheets, Notion en Airtable. Afbeeldingsvelden worden geüpload naar Notion/Airtable voor correcte weergave, en alle exports zijn gratis—zelfs in de gratis versie.
5. Heb ik technische vaardigheden nodig om Thunderbit te gebruiken voor geautomatiseerde listing-extractie?
Nee! Thunderbit is ontworpen voor zakelijke gebruikers—installeer gewoon de extensie, klik op “AI Suggest Fields” en je bent klaar om data te extraheren. Geen code, geen templates en geen onderhoud nodig.
Wil je Thunderbit in actie zien? of bekijk meer how-to-gidsen op de . Veel crawlplezier!
Meer lezen