

Er is een grap onder sales- en operationsmensen: “Ik heb me niet aangemeld voor een carrière in knip-en-plakwerk.” En toch zitten we hier — verdrinkend in pdf’s, webformulieren, facturen en spreadsheets, allemaal smekend om iemand die de juiste stukjes informatie eruit trekt en op een nuttige plek zet. Ik heb het zelf gezien: teams die uren (en hersencapaciteit) verliezen om data van de ene plek naar de andere te krijgen. En het is niet eens een klein ongemak. Branchecijfers bevestigen dit: verkopers verliezen ongeveer 6 uur per week aan handmatige datainvoer, en het IDP-marktrapport van Docsumo uit 2025 ontdekte dat het automatiseren van documentextractie de verwerkingstijden met 50% of meer kan verkorten en een ROI van 30–200% in het eerste jaar kan opleveren. Dat is niet zomaar wat extra koffiepauzetijd — het is een revolutie in je workflow.
Probeer Thunderbit voor AI-gestuurde data-extractie Get Started Free
Wat is dan het geheime ingrediënt? Dat heet key information extraction (KIE), en het verandert de manier waarop bedrijven met data omgaan. In deze post leg ik uit wat KIE echt betekent, wie het nodig heeft, hoe het werkt (zonder jargon), en waarom tools zoals Thunderbit het makkelijker dan ooit maken om documentchaos om te zetten in gestructureerde, bruikbare informatie. En ja, ik deel ook een paar praktijkverhalen, wat handige tips, en misschien zelfs een paar flauwe vadergrappen — want als je niet kunt lachen om datainvoer, waar kun je dan om lachen?
Wat is Key Information Extraction? Een eenvoudige gids voor Key Value Pair Extraction
Laten we bij de basis beginnen. Key information extraction draait om het automatisch vinden en eruit halen van belangrijke details uit documenten, webpagina’s, pdf’s, e-mails of zelfs afbeeldingen, en die omzetten in gestructureerde, bruikbare data. Zie het als je computer leren doen wat jij zou doen met een markeerstift en een stapel formulieren — maar dan veel sneller, en zonder het risico op een papierwond.
De kern van KIE is iets dat key value pair extraction heet. Dáár gebeurt het echte werk: de software zoekt naar “keys” (labels zoals “Bedrijfsnaam”, “Factuurnummer” of “Contact e-mail”) en haalt daar de bijbehorende “values” uit (zoals “Thunderbit”, “11897” of “info@thunderbit.com”). Het is alsof je een spreadsheet invult, maar dan leest en typt de computer voor je.
Bijvoorbeeld: van een bedrijfsregistratiepagina kan een KIE-tool het volgende extraheren:
- Bedrijfsnaam: Thunderbit
- Contact e-mail: info@thunderbit.com
- Telefoon: +1-555-1234
Dit proces is de ruggengraat van document information extraction — een bredere term voor elke methode om gestructureerde data uit ongestructureerde of semi-gestructureerde content te halen. Of je nu werkt met een pdf-factuur, een online bedrijvengids of een gescand contract, het doel blijft hetzelfde: rommelige, mensvriendelijke content omzetten in machinevriendelijke tabellen.
Waarom is dat belangrijk? Omdat gestructureerde data goud waard is. Daarmee kun je workflows automatiseren, trends analyseren en beslissingen nemen — zonder je dagenlang bezig te houden met knippen en plakken.
Wie heeft Key Information Extraction nodig? Toepassingen per team
Eerlijk gezegd kan bijna elk team dat met documenten of webdata werkt baat hebben bij KIE. Maar laten we het concreet maken. Hier is een snelle opsomming van wie het gebruikt en waarom:
| Afdeling/Functie | Use case voor key-value-extractie | Probleem zonder automatisering |
|---|---|---|
| Sales & Marketing | Leads verzamelen van websites, evenementenlijsten, e-mails | Handmatige CRM-invoer, vertragingen, verloren leads, typefouten |
| E-commerce Operations | Productdata scrapen (naam, prijs, voorraad van concurrentiesites) | Verouderde prijzen, gemiste marktveranderingen, handmatig onderhoud |
| Finance/Accounting | Factuur- en bonnetjesverwerking (leverancier, datum, bedrag) | Uren typen, fouten, betaalproblemen, herstelwerk |
| HR & Recruiting | Cv’s analyseren (naam, vaardigheden, ervaring uit cv’s) | Trage werving, inconsistente beoordelingen, gemiste details |
| Compliance & Legal | KYC-controles, extractie van contractclausules | Tijdrovende verificatie, risico op het missen van kritieke info |
Laten we eerlijk zijn: zonder automatisering zitten deze teams vast in een loop van handmatige invoer, trage opvolging en al die “oeps”-momenten die ontstaan door menselijke fouten. Ik heb sales teams kansen zien missen omdat de data niet snel genoeg in de CRM stond, en finance teams dagen zien besteden aan het afstemmen van facturen die in minuten verwerkt hadden kunnen worden.
En de pijn is echt. Een vastgoedbedrijf dat leadcaptatie automatiseerde, zag een stijging van 35% in hoogwaardige leads en verminderde de tijd voor datainvoer met 30%. Dat is niet alleen winst voor de winst-en-verliesrekening — het is winst voor ieders gemoedsrust.
Waarom Key Information Extraction belangrijk is voor workflowefficiëntie
Laten we het over het “waarom” hebben. Het automatiseren van document information extraction gaat niet alleen over een paar minuten besparen — het gaat over het veranderen van de manier waarop je team werkt.
De grote voordelen:
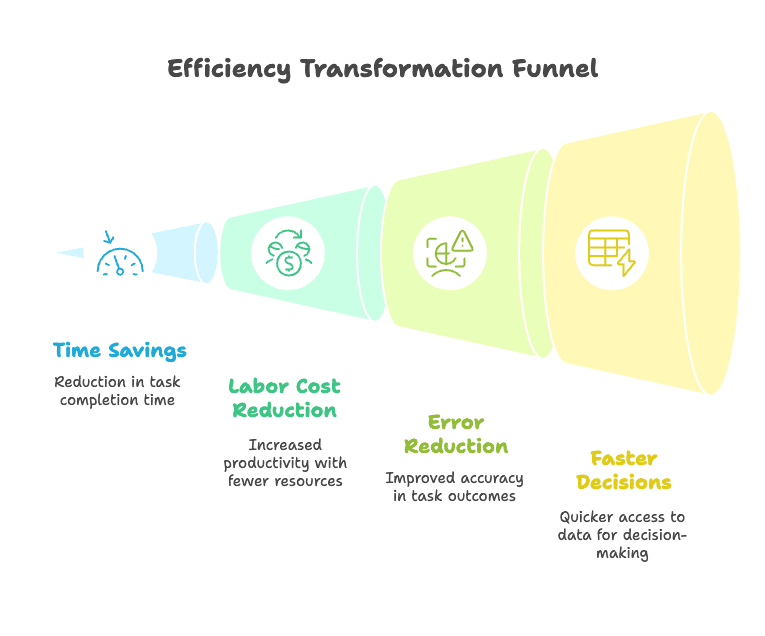
- Tijdbesparing: Taken die uren of dagen kostten, duren nu minuten. Een logistiek bedrijf bracht de verwerkingstijd van documenten terug van meer dan 7 minuten per bestand naar minder dan 30 seconden — een vermindering van >90%.
- Lagere arbeidskosten: Teams kunnen meer doen met minder, of mensen inzetten voor werk met meer waarde. Sommige bedrijven zagen 30–200% ROI in het eerste jaar.
- Minder fouten: Geavanceerde extractiesystemen kunnen 99%+ nauwkeurigheid halen, en bedrijven zagen foutpercentages met meer dan 52% dalen.
- Snellere beslissingen: Data is eerder beschikbaar, waardoor teams sneller kunnen handelen — of dat nu het opvolgen van een lead is, prijzen aanpassen of een factuur betalen.
Voor-en-na: de echte impact
Voor automatisering: Een claimgoedkeuring bij een verzekeringsmaatschappij kon makkelijk twee weken duren, vooral door datainvoer en verificatie.
Na automatisering: Claims worden binnen een dag of twee verwerkt, omdat relevante data door AI wordt geëxtraheerd en geverifieerd. Medewerkers kunnen sneller goedkeuren, en klanten krijgen eerder uitbetaald. In sommige gevallen zijn verwerkingstijden van claims gedaald van weken naar minuten (bron).
De kern? Key information extraction maakt je processen sneller, goedkoper en beter. Het gaat niet alleen om harder werken — het gaat om slimmer werken.
Hoe werkt Key Information Extraction? Van OCR tot AI-gestuurde extractie
Je hoeft geen data scientist te zijn om te begrijpen hoe dit werkt (gelukkig maar). Hier is de uitleg in gewone taal over de typische workflow:
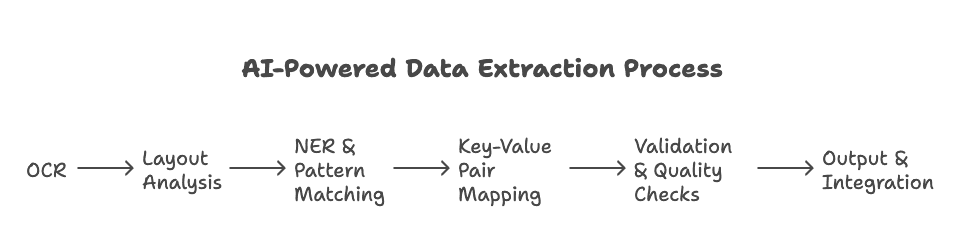
- OCR (Optical Character Recognition): Voor gescande documenten of afbeeldingen zet OCR afbeeldingen van tekst om in echte tekst. Moderne OCR, aangedreven door AI, kan zelfs handschrift en rommelige scans aan (meer weten).
- Lay-outanalyse: Het systeem bepaalt waar de keys en values staan — bijvoorbeeld door “Totaalbedrag:” te koppelen aan “€5.000” op een factuur, zelfs als de lay-out vreemd is of de velden alle kanten op staan (details).
- Named Entity Recognition (NER) & patroonherkenning: AI zoekt naar zaken als namen, datums, bedragen of e-mails, met zowel aangeleerde patronen als regels (meer).
- Mapping van key-valueparen: De software koppelt de labels aan de data en bouwt zo een gestructureerd record op (denk: “Naam” → “John Doe”).
- Validatie & kwaliteitscontroles: Geautomatiseerde controles (en soms een snelle menselijke review) zorgen ervoor dat de data klopt.
- Output & integratie: De gestructureerde data wordt geëxporteerd naar Excel, Google Sheets, een database, of zelfs direct naar je CRM- of ERP-systeem (zie hoe).
De rol van AI in document information extraction
AI is de motor achter het geheel. Het is wat deze tools in staat stelt om:
- complexe of onbekende lay-outs aan te kunnen (geen gedoe meer met “template brak omdat het veld verschoof”)
- meerdere talen te ondersteunen (Thunderbit ondersteunt bijvoorbeeld 55 talen vanaf de release in mei 2026)
- velden automatisch voor te stellen (zoals Thunderbit’s “AI Suggest Fields”)
- data onderweg op te schonen, te standaardiseren en zelfs te vertalen
Met andere woorden: AI maakt van KIE iets dat van “misschien werkt het als alles perfect is” verandert in “het werkt gewoon, zelfs als het rommelig wordt.”
4 populaire tools voor Key Information Extraction (en waarom Thunderbit voorop loopt)
Er zijn genoeg tools op de markt, maar ze zijn niet allemaal gelijk. Hier zijn vier die het waard zijn om te kennen, met Thunderbit bovenaan (en terecht):
1. Thunderbit: de eenvoudigste AI-webscraper voor Key Information Extraction
Thunderbit is een AI-gestuurde Chrome-extensie die web- en documentdata-extractie toegankelijk maakt voor iedereen — geen code, geen gedoe met installatie. Dit is waarom ik fan ben:
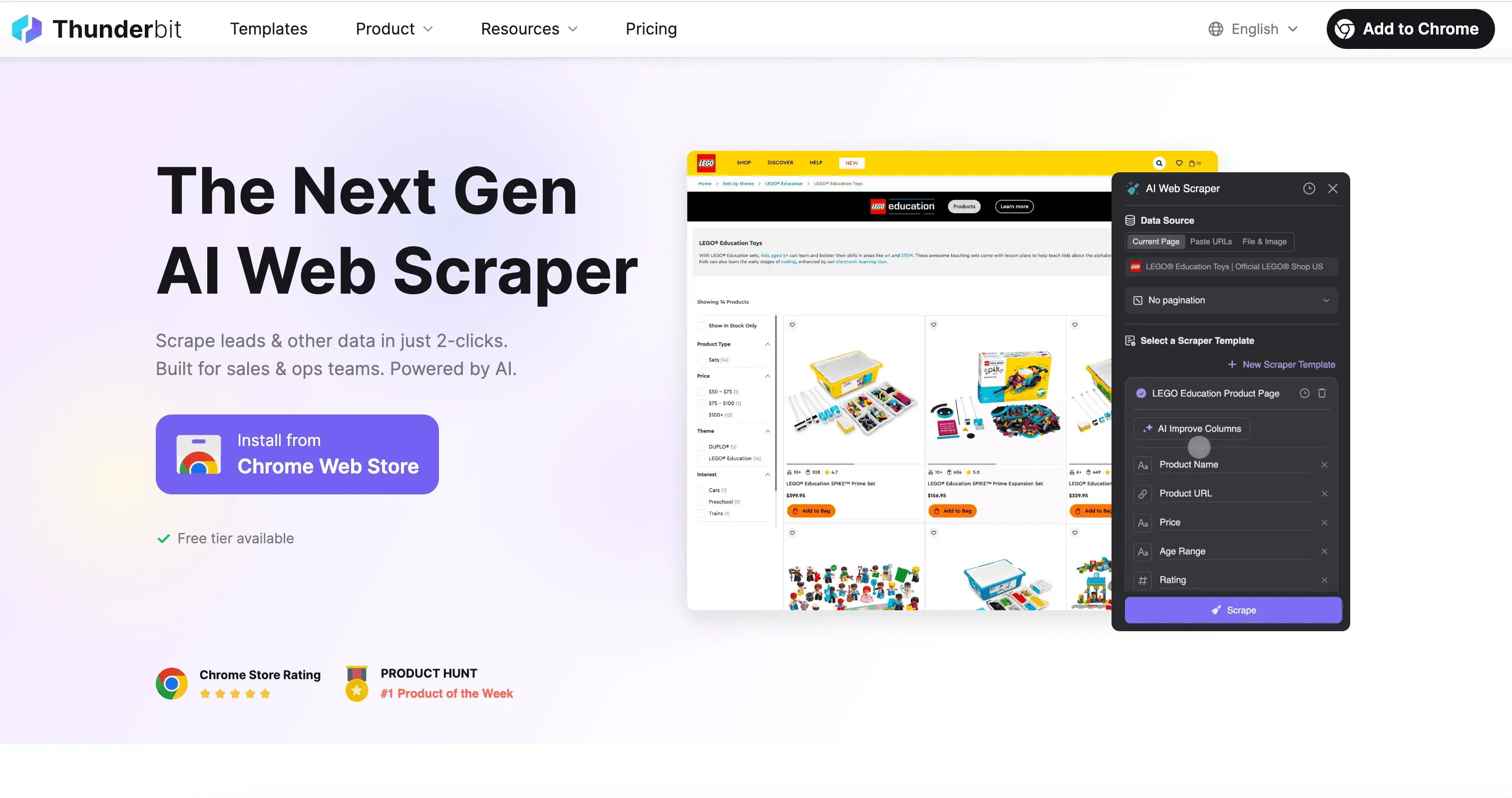
- Geautomatiseerde lead-data-extractie: Haal direct bedrijfs-, contact-, e-mailgegevens en meer op van evenementpagina’s, vacaturebanken of bedrijfsprofielen — zonder handmatige verzameling.
- Slimme veldherkenning en standaardisatie: Thunderbit’s AI herkent en formatteert velden zoals bedrijfsnaam, e-mail, telefoon en zelfs brancheclassificatie. Het kan telefoonnummers standaardiseren, veldnamen vertalen en meer.
- Kan complexe structuren aan: Pagina’s met meerdere pagina’s, subpagina’s (zoals het profiel van elke exposant op een beurs) of pdf’s met meerdere pagina’s scrapen? Thunderbit regelt het.
- Meertaligheid & veldvertaling: Ondersteunt 55 talen en kan velden vertalen voor internationale teams.
Locatie 3 — onder de bullet “Overcoming Common Challenges...”:
- No-code, direct resultaat: Klik op “AI Suggest Fields”, controleer de kolommen en klik op “Scrape”. Exporteer naar Excel, Google Sheets, Airtable of Notion — zonder extra kosten.
Laat me je meenemen in een praktijkvoorbeeld:
Scenario: Je bereidt een campagne voor gericht op bedrijven van een tech-event. De eventsite toont exposanten (met links naar profielpagina’s), en je hebt een pdf-brochure met extra details.
- Met Thunderbit open je de exposantenpagina, klik je op “AI Suggest Columns”, en de AI stelt velden voor zoals Bedrijfsnaam, Branche, Website.
- Klik op “Scrape”, en Thunderbit haalt alle bedrijven binnen.
- Wil je meer details van elk profiel? Gebruik Subpage Scraping — Thunderbit bezoekt elke link, haalt e-mails en telefoonnummers op en voegt ze toe aan je tabel.
- Heb je een pdf? Open die in Chrome, gebruik Thunderbit’s pdf-parser en extraheer tabellen of tekst.
- Exporteer alles naar Google Sheets, klaar voor je campagne.
Totale tijd: misschien 10–15 minuten. Geen code, geen knip-en-plakwerk, geen hoofdpijn.
Thunderbit springt eruit door zijn AI-gedreven gebruiksgemak, brede functionaliteit en focus op webgebaseerde data-extractie. Het is gebouwd voor zakelijke gebruikers in sales, marketing, e-commerce, vastgoed en meer. En met functies zoals geplande scraping (je hoeft alleen te beschrijven wanneer het moet draaien), houdt het je data automatisch actueel.
Wil je het in actie zien? Bekijk de Thunderbit Chrome-extensie of blader door de Thunderbit-blog voor meer use cases.
Probeer Thunderbit voor Key Information Extraction
2. Kili Technology
 Kili Technology draait helemaal om custom AI voor complexe documenten. Als je zeer gespecialiseerde formulieren hebt of een model wilt trainen voor je unieke use case (denk aan: verzekeringsclaims, identiteitsdocumenten uit verschillende landen), kun je met Kili data labelen, modellen trainen en je eigen extractor bouwen. Het is krachtig, maar vooral geschikt voor organisaties met machinelearning-expertise en veel variatie in hun documenten.
Kili Technology draait helemaal om custom AI voor complexe documenten. Als je zeer gespecialiseerde formulieren hebt of een model wilt trainen voor je unieke use case (denk aan: verzekeringsclaims, identiteitsdocumenten uit verschillende landen), kun je met Kili data labelen, modellen trainen en je eigen extractor bouwen. Het is krachtig, maar vooral geschikt voor organisaties met machinelearning-expertise en veel variatie in hun documenten.
3. Klippa DocHorizon
 Klippa DocHorizon is een alles-in-één platform voor documentverwerking met sterke OCR en AI. Het is vooral populair in finance en accounting (facturen, bonnen, contracten, identiteitsbewijzen) en biedt API’s voor integratie. Klippa kan een brede variatie aan documenttypen out-of-the-box verwerken, met hoge nauwkeurigheid en flexibele exportopties (JSON, XML, Excel, enz.). Het is een uitstekende match voor bedrijven die backoffice-taken op schaal automatiseren.
Klippa DocHorizon is een alles-in-één platform voor documentverwerking met sterke OCR en AI. Het is vooral populair in finance en accounting (facturen, bonnen, contracten, identiteitsbewijzen) en biedt API’s voor integratie. Klippa kan een brede variatie aan documenttypen out-of-the-box verwerken, met hoge nauwkeurigheid en flexibele exportopties (JSON, XML, Excel, enz.). Het is een uitstekende match voor bedrijven die backoffice-taken op schaal automatiseren.
4. Rossum
 Rossum is een AI-platform voor documentverwerking met grote volumes, vooral in accounts payable en logistiek. Het combineert AI-extractie met een human-in-the-loop-validatie-UI, zodat je duizenden documenten met hoge nauwkeurigheid en minimale handmatige inspanning kunt verwerken. Rossum is ideaal voor ondernemingen die end-to-end automatisering zoeken met stevige kwaliteitscontrole.
Rossum is een AI-platform voor documentverwerking met grote volumes, vooral in accounts payable en logistiek. Het combineert AI-extractie met een human-in-the-loop-validatie-UI, zodat je duizenden documenten met hoge nauwkeurigheid en minimale handmatige inspanning kunt verwerken. Rossum is ideaal voor ondernemingen die end-to-end automatisering zoeken met stevige kwaliteitscontrole.
Veelvoorkomende uitdagingen bij Key Information Extraction overwinnen
Zelfs de beste tools lopen tegen wat hobbels aan. Dit heb ik gezien, en zo lossen moderne oplossingen (vooral Thunderbit) dat op:
- Variatie in documenten/lay-out: AI-gebaseerde extractors leren patronen, geen vaste posities. Thunderbit’s “AI Suggest Fields” past zich aan nieuwe lay-outs aan zonder handmatige herconfiguratie.
- Taalbarrières: Meertalige OCR en vertaalfuncties (Thunderbit ondersteunt 55 talen) zorgen ervoor dat je uit wereldwijde bronnen kunt extraheren.
- Datakwaliteit: Ingebouwde normalisatie en veldprompts helpen data op te schonen en te standaardiseren tijdens de extractie.
- Integratie: Direct exporteren naar Google Sheets, Airtable, Notion of API’s zorgt ervoor dat je data direct in je workflow terechtkomt.
- Privacy & compliance: Kies tools met sterke beveiliging, encryptie en compliancefuncties. Extraheer en sla alleen op wat je nodig hebt.
- Adoptie door gebruikers: Hoe makkelijker de tool, hoe sneller je team hem omarmt. Thunderbit’s workflow met twee klikken is hier een grote winst.
Tips voor het beste resultaat:
- Gebruik AI-veldvoorstellen en prompts om de extractie te verfijnen.
- Controleer en werk je extractiesjablonen regelmatig bij.
- Maak gebruik van vertaalfuncties voor meertalige data.
- Documenteer je proces en houd mensen in de loop voor kwaliteitscontrole.
Stappenplan: hoe je Key Information Extraction in je workflow gebruikt
Klaar om te beginnen? Hier is een eenvoudig, uitvoerbaar proces:
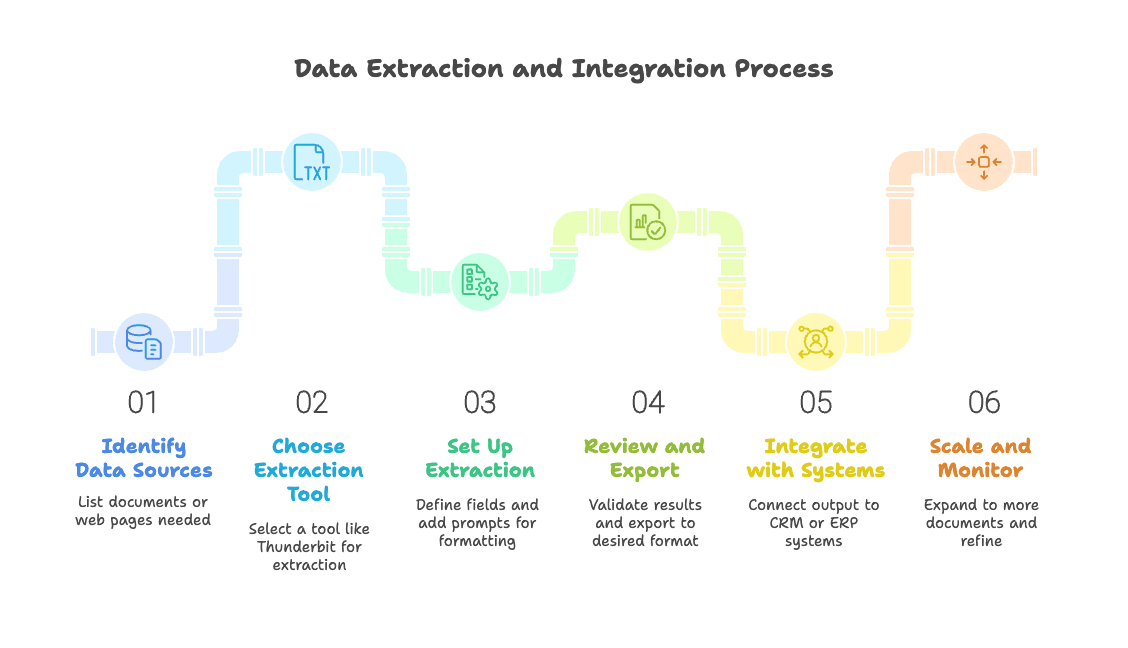
- Breng je bronnen in kaart: Maak een lijst van de documenten of webpagina’s waaruit je data nodig hebt. Geef prioriteit aan use cases met grote impact.
- Kies een tool: Voor web- en documentextractie met minimale setup is Thunderbit een uitstekende keuze. Test gerust een paar tools als je unieke behoeften hebt.
- Stel de extractie in: Gebruik AI-voorstellen om velden te definiëren. Pas aan waar nodig en voeg prompts toe voor speciale opmaak of vertaling.
- Controleer & exporteer: Draai een testextractie, valideer de resultaten en exporteer naar Excel, Google Sheets, Airtable of Notion.
- Integreer: Koppel je output aan je CRM, ERP of andere systemen. Gebruik planningsfuncties voor terugkerende taken.
- Schaal op & monitor: Rol uit naar meer documenten of pagina’s. Controleer steekproefsgewijs de output en verfijn onderweg.
Snelle checklist:
- ✔ Bepaal welke informatie en bronnen je nodig hebt
- ✔ Kies de juiste tool
- ✔ Stel velden in (gebruik AI-voorstellen)
- ✔ Test en valideer de extractie
- ✔ Exporteer/integreer met je workflow
- ✔ Monitor en verfijn regelmatig
Key Value Pair Extraction in de praktijk: voorbeelden uit de echte wereld
Laten we het tot leven brengen met een paar korte verhalen:
Voorbeeld 1: Sales leads genereren uit evenementen
Voor: Salescoördinatoren besteedden een hele dag aan het kopiëren van deelnemersinformatie uit evenementlijsten naar de CRM. Tegen de tijd dat de leads klaar waren, was de “hype” van het event al voorbij.
Na: Met Thunderbit haalt de coördinator binnen ongeveer 10 minuten alle relevante velden van de eventpagina of uit de pdf. Leads staan dezelfde dag nog in de CRM, en het team zag een stijging van 20% in conversieratio.
Voorbeeld 2: prijsmonitoring in e-commerce
Voor: Een stagiair besteedde wekelijks uren aan het controleren van concurrentieprijzen voor 100 producten, en miste daarbij vaak updates.
Na: De manager stelt Thunderbit in om concurrentiepagina’s ’s nachts te scrapen. Data komt in Google Sheets terecht, en prijswijzigingen worden automatisch gemarkeerd. Het bedrijf reageert sneller, blijft concurrerend en de wekelijks bespaarde uren worden ingezet voor analyse.
Voorbeeld 3: factuurverwerking in finance
Voor: Medewerkers van accounts payable voerden factuurgegevens handmatig in, wat 5–10 minuten per factuur kostte en fouten opleverde.
Na: Een AI-gestuurde tool (zoals Rossum of Doxis AI.dp) extraheert alle velden met tot 99% nauwkeurigheid. De verwerkingstijd daalt met 50% of meer, en fouten worden zeldzaam.
Beste praktijken voor succes met document information extraction
Dit heb ik geleerd (soms op de harde manier):
- Gebruik AI-voorstellen: Gebruik functies zoals Thunderbit’s “AI Suggest Columns” om tijd te besparen en velden te vinden die je anders zou missen.
- Houd sjablonen actueel: Websites en formulieren veranderen — controleer je extractie-instellingen regelmatig.
- Gebruik meertalige functies: Standaardiseer veldnamen en waarden over talen heen voor internationale teams.
- Integreer & automatiseer: Exporteer direct naar de tools die je team al gebruikt. Automatiseer terugkerende taken.
- Zorg voor privacy & compliance: Extraheer alleen wat je nodig hebt, beveilig je data en volg de regels.
- Houd mensen in de loop: Controleer outputs periodiek op kwaliteit, vooral bij kritieke data.
- Documenteer je proces: Houd notities bij over wat je extraheert, hoe en waar het naartoe gaat.
- Blijf bij: Volg de updates van je tool — nieuwe functies kunnen je leven nog makkelijker maken.
Conclusie: ontgrendel workflowefficiëntie met Key Information Extraction
Meer leren over data scraping met AI Get Started Free
In de zakenwereld van vandaag zijn tijd en nauwkeurigheid de nieuwe valuta. Het automatiseren van key information extraction is niet zomaar een leuke extra — het is een must voor teams die snel willen bewegen, concurrerend willen blijven en de gevreesde knip-en-plak-burn-out willen vermijden. Van sales tot finance tot HR: de voordelen zijn duidelijk — snellere processen, minder fouten en meer tijd voor werk dat er echt toe doet.
AI-gestuurde tools zoals Thunderbit lopen voorop en maken extractie toegankelijk voor iedereen — geen code, geen hoofdpijn, gewoon resultaat. Of je nu leads van een website haalt, data uit een pdf trekt of concurrenten in de gaten houdt, KIE kan je workflow transformeren.
Dus hier is mijn uitdaging: kies één proces in je organisatie dat wordt vertraagd door handmatige datainvoer. Probeer key information extraction — misschien met de gratis versie van Thunderbit — en ervaar zelf het verschil. De tijd die je bespaart, de fouten die je voorkomt en de inzichten die je ontsluit, laten je misschien afvragen hoe je ooit zonder kon.
En als je ooit heimwee krijgt naar de oude knip-en-plakdagen, maak je geen zorgen — ik hoor dat daar een steungroep voor is. Ze komen elke vrijdag samen op spreadsheets.
Meer weten?
- Thunderbit-blog
- Wat is data scraping en hoe doe je het
- Hoe je websitegegevens met AI naar Excel schraapt
- Thunderbit Chrome-extensie downloadpagina
Klaar om je workflowefficiëntie te ontgrendelen? Laten we gaan extraheren.
Probeer Thunderbit AI Webscraper gratis Get Started Free
FAQ’s
1. Wat is key information extraction (KIE) en waarom is het belangrijk?
Key information extraction (KIE) is het geautomatiseerde proces waarbij specifieke, waardevolle data — zoals namen, e-mails, factuurtotalen of productdetails — wordt geïdentificeerd en eruit gehaald uit ongestructureerde bronnen zoals pdf’s, e-mails, webpagina’s of gescande documenten. Het is cruciaal om rommelige, menselijk leesbare content om te zetten in schone, gestructureerde data die automatisering, analyse en snellere besluitvorming mogelijk maakt.
2. Welke teams profiteren het meest van KIE-tools?
KIE komt ten goede aan een brede groep teams, waaronder sales en marketing (voor leadcaptatie), e-commerce (voor prijsmonitoring), finance (voor factuurverwerking), HR (voor cv-analyse) en legal/compliance (voor documentverificatie). Elke rol met repetitieve datainvoer uit documenten kan grote winst boeken in tijd en nauwkeurigheid.
3. Hoe werkt key-value-pair-extractie?
Key-value-pair-extractie identificeert “keys” (zoals “Factuurnummer” of “Bedrijfsnaam”) en koppelt die aan de bijbehorende “values” (zoals “#93843” of “Thunderbit”). Het proces gebruikt AI-aangedreven OCR, lay-outanalyse, named entity recognition (NER) en patroonherkenning om de data te mappen en te exporteren in een gestructureerd formaat zoals spreadsheets of CRM-databases.
4. Wat maakt Thunderbit anders dan andere KIE-tools?
Thunderbit combineert AI-gestuurde veldherkenning, meertalige ondersteuning, pdf-analyse, subpage scraping en veldvoorstellen met één klik in een gebruiksvriendelijke Chrome-extensie. Het is ontworpen voor niet-programmeurs en ondersteunt export naar tools zoals Google Sheets, Airtable en Notion. Het is vooral sterk in webgebaseerde leadgeneratie, event scraping en het op schaal vastleggen van gestructureerde data.
5. Wat zijn enkele praktijkvoorbeelden van KIE in actie?
- Sales teams gebruiken Thunderbit om leaddata van eventpagina’s te scrapen en binnen enkele minuten te uploaden naar CRM’s.
- E-commerce managers automatiseren het monitoren van concurrentieprijzen van websites.
- Finance-afdelingen verwerken facturen in minder dan 30 seconden met AI-extractie, waardoor fouten afnemen en wekelijks uren worden bespaard.
Deze voorbeelden laten zien hoe KIE trage, foutgevoelige handmatige processen kan omzetten in efficiënte, betrouwbare workflows.




