Een GitHub-zoekopdracht naar "tiktok scraper" levert op. Ongeveer is al meer dan een jaar niet meer bijgewerkt, en minstens .
Als je ooit een populaire TikTok-scraperrepo hebt gekloond, een uur hebt zitten worstelen met dependencies en daarna nul output kreeg — je bent niet de enige. De TikTok-scraper op GitHub met de meeste sterren, drawrowfly/tiktok-scraper, heeft nog steeds ruim 5.000 sterren. Toch staat de issue tracker vol met threads zoals en — beide melden nul output. Bij Thunderbit volg ik al maanden de staat van TikTok-scrapingrepos, en het patroon is glashelder: deze tools lopen snel vast, en de meeste worden nooit meer gefixt. Dit artikel is de praktische overlevingsgids waarvan ik had gewild dat hij bestond toen ik deze repos voor het eerst beoordeelde. We behandelen wat nog leeft, wat dood is, wat je in plaats daarvan kunt doen en hoe je voorkomt dat je uren verspilt aan code die al stopte met werken voordat je hem überhaupt vond.
Waarom de meeste TikTok-scrapers op GitHub stukgaan (en stuk blijven)
TikTok is geen standaard scrapingdoel. De webomgeving verandert voortdurend. In tegenstelling tot een statische productpagina van een webshop of een bedrijvengids wijzigt TikTok endpoints, vernieuwt het anti-bot fingerprinting, past het de manier van renderen aan en introduceert het nieuwe sessie- en tokenvereisten — soms al binnen weken na de vorige wijziging.
Open-source maintainers zijn vrijwilligers. Wanneer TikTok een update doorvoert die het requestpad van de scraper breekt, kan een repo dagen, weken of voorgoed stuk blijven. Dat is geen kritiek op de maintainers — het is een structurele mismatch tussen een snel bewegend, goed gefinancierd platform en onbetaalde ontwikkelaars met een gewone baan.
Zelfs de beste TikTok-scraperrepos leven op een break-fix-treadmill. Als je er een wilt gebruiken, heb je een strategie nodig om te beoordelen, problemen op te lossen en een back-upplan te hebben.
TikTok's anti-botverdediging: waar je tegenaan loopt
- Rate limiting. TikTok's documenteert expliciet requestquota's, zelfs voor goedgekeurde integraties. Onofficiële scrapers lopen veel sneller tegen deze limieten aan.
- Cookie- en sessieafscherming. Moderne repos zoals vereisen een
ms_token; oudere repos zoals tonentt_webid_v2in hun voorbeelden; documenteertmsToken,ttwid,X-BogusenA_Bogus. TikTok controleert of je request lijkt te komen uit een echte browsersessie. - Browser fingerprinting. legt uit waarom sites headers, cookies, TLS-signatures en via JavaScript zichtbare browserkenmerken vergelijken met echt gebruikersverkeer. Hun behandelt Canvas-, WebGL-, WebRTC-, font- en runtime-signalen. Fingerprinting is alsof TikTok je browser-ID controleert — als browser, cookies, timing en netwerksignatuur niet bij elkaar passen, lijkt het request nep nog vóór er content wordt teruggestuurd.
- Gedragsdetectie. over TikTok-scraping noemen vaak dat verse Playwright-sessies CAPTCHA-prompts activeren. Communityposts uit beschrijven steeds vaker detectie die kijkt naar timing en interactiekwaliteit, niet alleen naar hergebruik van IP's.
- Versleutelde/gesigneerde requestparameters. Evil0ctal documenteert
X-BogusenA_Bogus; oudere communitygists draaien vaak om URL-signing en token generatie. TikTok verwacht steeds vaker requests met dezelfde "stempels" als het eigen browser- of appverkeer. - CAPTCHA- en verificatiestromen. Het bestaan van en bevestigt dat CAPTCHA nog steeds deel uitmaakt van het anti-botlandschap.
Waarom open-source maintainers niet kunnen bijbenen
De levenscyclus is altijd hetzelfde. Een ontwikkelaar bouwt een TikTok-scraper. Die gaat viraal op GitHub. TikTok patcht hem. De maintainer fixt het probleem of gaat verder.
Twee repos laten dat patroon perfect zien:
- drawrowfly/tiktok-scraper heeft nog steeds 5.052 sterren en 889 forks, maar de . Het is de TikTok-scraper met de meeste sterren op GitHub op basis van die exacte zoekterm, en hij leest als een historisch artefact: veel zichtbaarheid, veel vertrouwen, geen actief onderhoud.
- davidteather/TikTok-Api laat zien. De toont zinvol onderhoud in april 2025, juli 2025, oktober 2025 en april 2026 — inclusief fixes voor het crawlen van gebruikersvideo's en nieuwe proxy-/sessiecontroles. Maar zelfs dit gezondere project waarschuwt openlijk dat TikTok requests blokkeert en dat gebruikers mogelijk proxies, Playwright en aangepaste sessielogica nodig hebben.
Het patroon is simpel:
- Een verouderde TikTok-scraperrepo is waarschijnlijk dood.
- Een actieve TikTok-scraperrepo is waarschijnlijk nog steeds kwetsbaar.
- Het enige echte verschil is of er deze maand nog iemand beschikbaar is om de breuk te patchen.
De 60-seconden Repo Vitals Checklist: hoe je elke TikTok-scraper op GitHub beoordeelt
Voordat je iets kloont, loop deze checklist door. Het kost minder dan een minuut en bespaart je uren frustratie.
| Signaal | 🟢 Gezond | 🟡 Risicovol | 🔴 Dood |
|---|---|---|---|
| Laatste zinvolle push | < 3 maanden geleden | 3–12 maanden geleden | 12+ maanden geleden |
| Aantal open issues | Laag, recente issues krijgen antwoord | Groeiende stapel met enige maintaineractiviteit | Veel onbeantwoorde meldingen over "stuk/geblokkeerd/werkt niet" |
| Recente klachten van gebruikers | Vooral vragen over installatie | Mix van installatietips en klachten over breuken | Herhaalde meldingen van "nul output", "403", "werkt het nog?" |
| Huidig auth-/sessiemodel | Sessie's/cookiepad gedocumenteerd | Token-zwaar maar gedocumenteerd | Vertrouwt op oude web-endpoints zonder actuele auth-informatie |
| Installatie-oppervlak | Reproduceerbare, geteste setup | Enkele handmatige stappen | Oude dependencies, geen moderne setupnotities |
| CI/tests | Tests bestaan en zijn actueel | Tests bestaan, maar dekking is onduidelijk | Geen tests of verouderde actions |
| Geschiktheid van datascope | Sluit aan op je echte use-case | Ondersteunt slechts een deel van de use-case | Lost een heel ander probleem op |
Hoe je elk signaal binnen 60 seconden controleert
- Datum van de laatste push: Kijk in de repository-header op GitHub. Staat er "last pushed 2 years ago", dan ben je klaar.
- Open issues: Klik op het tabblad Issues. Lees de nieuwste titels snel door. Zoek op
not working,403,blocked,captchaofzero output. - Klachten van gebruikers: Als de top 5 open issues allemaal variaties zijn van "dit werkt niet meer", dan heb je je antwoord.
- Auth-/sessiemodel: Open de README. Zoek naar actuele aanwijzingen zoals
ms_token, Playwright-setup of proxy-notities. Als de README endpoints uit 2023 noemt, loop dan door. - Installatie-oppervlak: Kijk of er een requirements-bestand, Docker-ondersteuning of duidelijke setup-instructies zijn. Als de README zegt "npm install" en de laatste geteste Node-versie 14 was, verwacht dan problemen.
- CI/tests: Controleer het tabblad Actions. Als tests falen of ontbreken, is elke breuk een gok.
- Datascope: Beschrijft de repo daadwerkelijk de datatypes die jij nodig hebt (profielen, videometadata, reacties, hashtags)? Veel repos doen alleen videodownloads, geen gestructureerde data-extractie.
Rode vlaggen die betekenen: "wegwezen"
- De repo is gearchiveerd.
- De README zegt "niet langer onderhouden".
- De laatste commit verwijst naar een TikTok-API-versie van meer dan 2 jaar geleden.
- Issues stromen vol met meldingen dat het niet werkt en de maintainer reageert al maanden niet.
- De repo heeft veel sterren maar geen recente forks of pull requests.
Pro-tip: zoek in het Issues-tabblad op is:issue is:open "not working" of is:issue is:open "403". Zijn de resultaten dicht en recent, dan is de repo waarschijnlijk stuk.
Populaire TikTok-scraper GitHub-repos: een eerlijke statuscheck (2026)
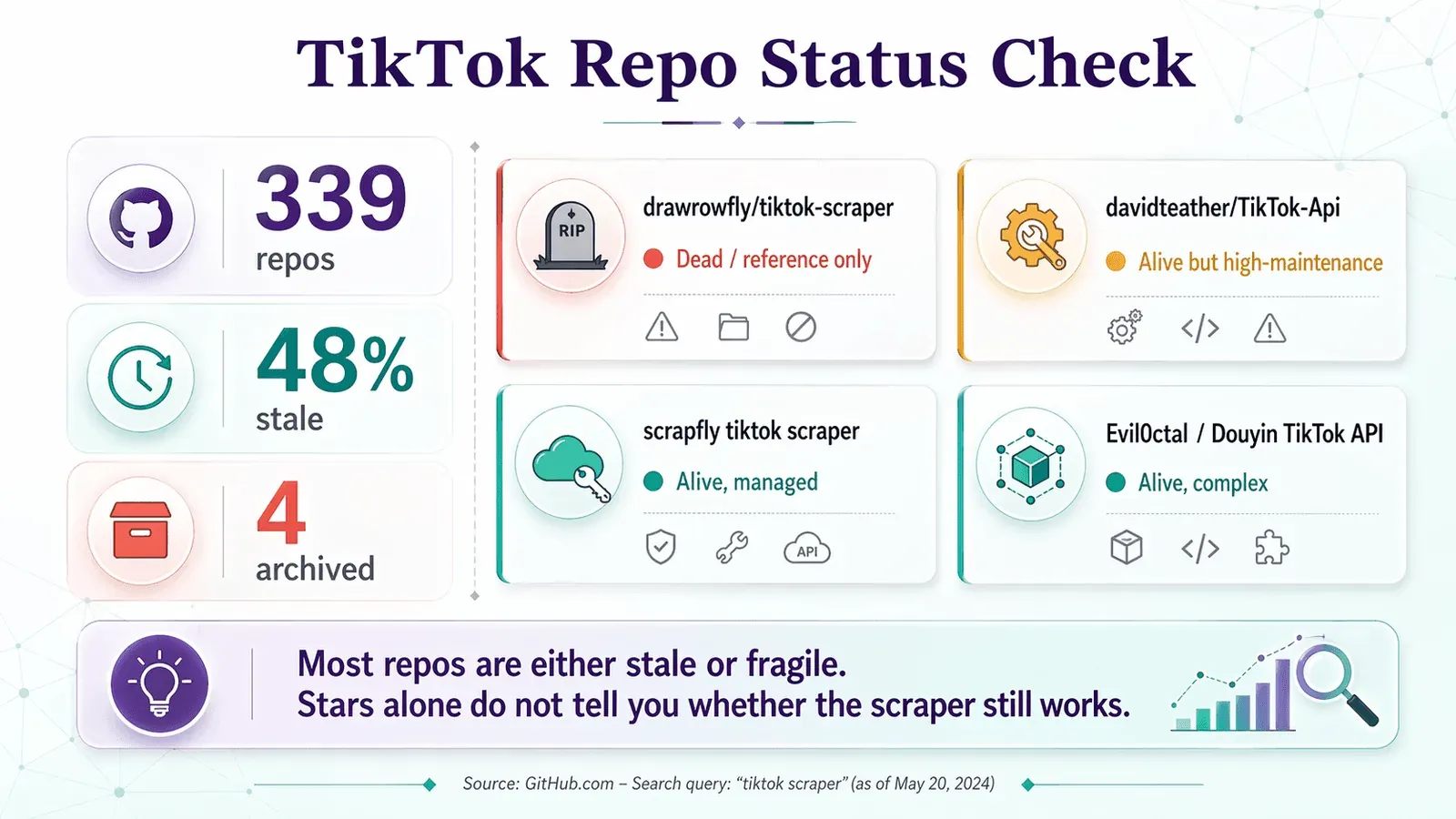
Hier is de Repo Vitals Checklist toegepast op de repos die je echt tegenkomt als je op GitHub zoekt naar "tiktok scraper":
| Repo | Laatste push | Sterren | Open issues | Oordeel | Opmerking |
|---|---|---|---|---|---|
| drawrowfly/tiktok-scraper | 2023-05-19 | 5,052 | 58 | 🔴 Dood / alleen als referentie | Nog steeds beroemd, maar te verouderd voor productiegebruik in 2026 |
| davidteather/TikTok-Api | 2026-04-01 | 6,301 | 134 | 🟡 Levend maar onderhoudsintensief | Sterkste OSS-keuze; verwacht Playwright, tokens en vaak proxies |
| scrapfly/scrapfly-scrapers/tiktok-scraper | 2026-04-21 | 938 (parent) | ~0 (monorepo) | 🟡 Levend, maar geen pure OSS | Actueel en nuttig, maar vereist een ScrapFly API-sleutel |
| Evil0ctal/Douyin_TikTok_Download_API | 2025-10-12 | 17,397 | 135 | 🟡 Levend, breed, complex | Functierijk multi-platformproject; meer iets voor power users |
| naseif/tiktok-scraper | 2024-07-26 | 107 | 13 | 🟡 Risicovol | Kleinere repo met open klachten over user-info- en hashtagflows |
| loewehancara1rmyv/Tiktok-scraper | 2026-01-12 | 4 | 0 | 🔴 Te nieuw om te vertrouwen | Showcase-repo, niet bewezen door de community |
drawrowfly/tiktok-scraper
Jarenlang was deze TypeScript-scraper/downloader het standaardantwoord op "tiktok scraper github" — voor gebruikersfeeds, trends, hashtags en muziekfeeds. In 2026 kun je hem het best zien als historische documentatie. De , en de issuewachtrij bevat nog steeds onbeantwoorde meldingen van en uit 2023–2025. Als je dit artikel leest omdat je deze repo hebt gekloond en niets kreeg, ben je in goed gezelschap.
davidteather/TikTok-Api
De meest geloofwaardige open-source TikTok-datawrapper die in 2026 nog leeft. Hij is actief, heeft en documenteert expliciet Playwright-setup, asynchroon gebruik, tokenafhandeling, proxy-ondersteuning en sessieherstelfuncties. Maar het is geen "kloon en klaar"-tool. De eigen README zegt dat EmptyResponseException meestal betekent dat TikTok het verzoek blokkeert, en de laat terugkerende problemen zien rond ms_token, kapotte commentextractie, KeyError: 'ItemModule' en endpoint-specifieke fouten. Oordeel: levend, nuttig, alleen voor ontwikkelaars en onderhoudsintensief.
Andere opvallende repos
- : Actueel en technisch relevant, maar de README vereist een
SCRAPFLY_KEY. Dit is een codevoorbeeld voor een beheerd scrapingplatform, geen gratis losstaande tool. - : Dekt TikTok en Douyin, documenteert signing-logica (
X-Bogus,A_Bogus,msToken) en ondersteunt reacties, volgers, afspeellijsten en meer. Het is technisch veeleisend en steeds sterker verweven met betaalde API-referenties. De issue tracker laat in 2026 nog steeds bugmeldingen zien rond videolinks en user-info-endpoints. Levend en functierijk, maar complex. - : Kleiner, met open klachten. Risicovol voor productiegebruik.
- : 4 sterren, 0 issues, te nieuw om te vertrouwen. Het Medium-artikel dat hem promootte deed dat zonder kritische blik.
TikTok officiële API vs. GitHub-scrapers vs. no-code tools: een besliskader
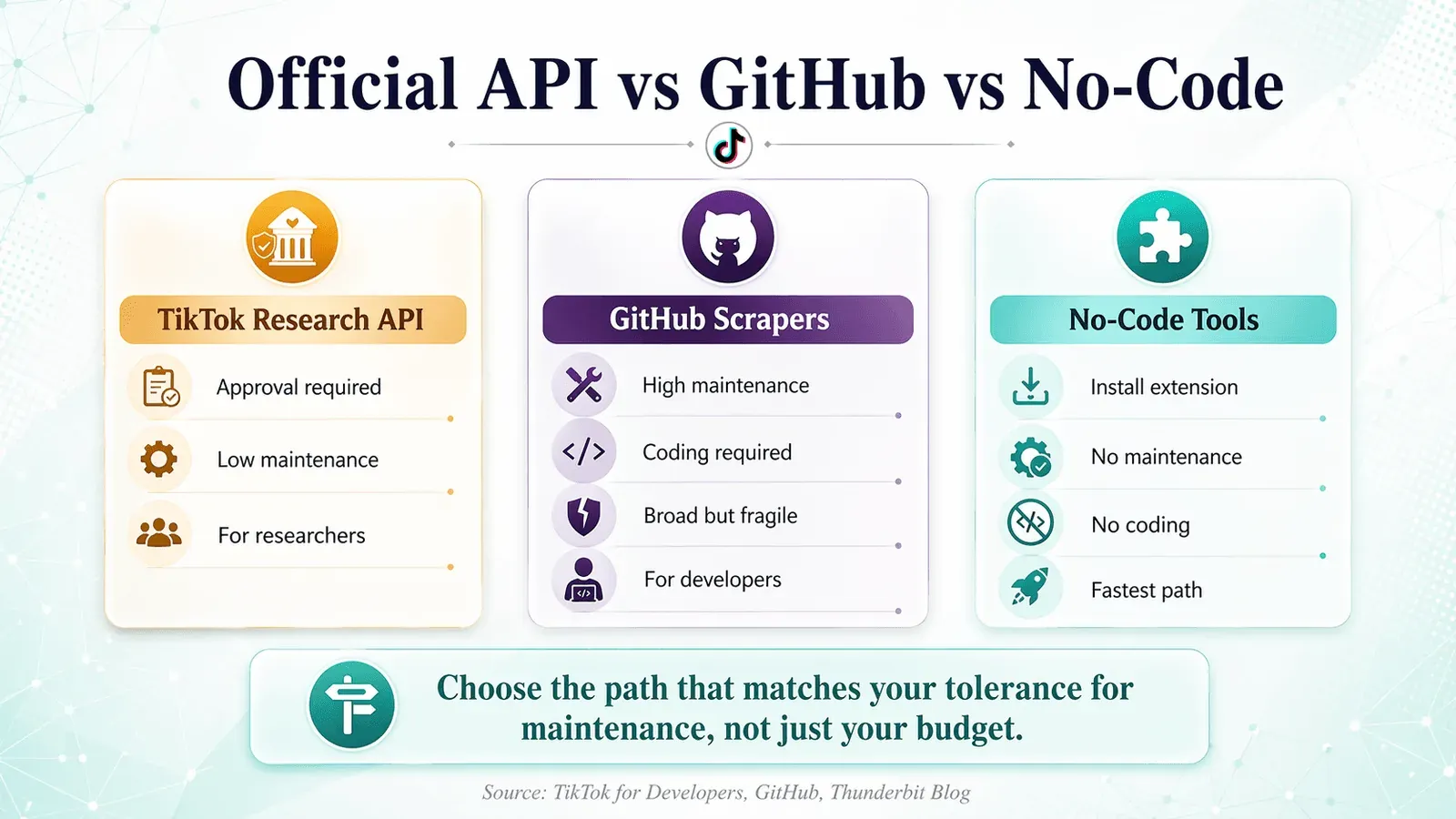
De meeste concurrerende artikelen negeren TikTok's officiële toegangspaden of springen meteen van "gebruik GitHub" naar "koop onze dienst". Hier is een neutrale vergelijking van alle drie de routes:
| Factor | TikTok Research API | GitHub-scrapers | No-code tools (bijv. Thunderbit) |
|---|---|---|---|
| Toegangsbarrière | Academische/zakelijke aanvraag vereist; ~4 weken voor goedkeuring | Git clone + setup | Browserextensie installeren |
| Datascope | Alleen goedgekeurde endpoints (accounts, video's, reacties, shops) | Breed (profielen, video's, reacties, hashtags, shops) | Zichtbare paginadata (profielen, video's, engagement, hashtags) |
| Onderhoudslast | Laag (officieel, stabiel) | Hoog (repos breken wanneer TikTok update) | Geen (AI past zich aan lay-outwijzigingen aan) |
| Anti-ban-risico | Geen (geautoriseerd) | Hoog | Laag (browsergebaseerd, bootst echte gebruiker na) |
| Kosten | Gratis (als goedgekeurd) | Gratis (maar kost veel tijd) | Gratis tier beschikbaar; creditgebaseerde pakketten vanaf $15/maand |
| Coderen vereist | Ja (Python/R) | Ja (Python/Node.js) | Nee |
| Het beste voor | Onderzoekers, academici, goedgekeurde organisaties | Ontwikkelaars die onderhoud aankunnen | Marketeers, salesteams, operations, niet-ontwikkelaars |
Wanneer de TikTok Research API logisch is
TikTok's is de schoonste officiële route als je ervoor in aanmerking komt. Gekwalificeerde onderzoekers in kunnen zich aanmelden om openbare content en accountdata te bestuderen. Beschikbare datacategorieën zijn onder meer accounts, volgers/volgend, gelikete video's, vastgezette video's, opnieuw geplaatste video's, content, reacties en shops. De toont velden zoals video_description, view_count, like_count, comment_count, share_count en commentniveauvelden zoals text, reply_count en create_time.
Het nadeel: de toelating is beperkt tot academische instellingen en in aanmerking komende non-profit-/independent researchers in specifieke regio's, plus . Ben je een growthteam of bureau dat snel operationele data nodig heeft, dan is dit niet jouw route.
TikTok biedt ook een voor advertentie- en adverteerderscontentdata, wat nuttig is voor transparantieonderzoek maar niet voor algemene scraping.
Wanneer een GitHub-scraper nog steeds logisch is
GitHub-scrapers zijn nog steeds logisch voor ontwikkelaars die onofficiële toegang nodig hebben tot openbare data buiten de goedkeuringspoort van de officiële API, en bereid zijn de stack te onderhouden. Denk aan use-cases zoals het scrapen van zichtbare profielroosters, hashtags, reacties, afspeellijsten of videometadata in een aangepaste pipeline waarin het accepteren van een fork en het patchen ervan prima is.
De eerlijke kanttekening: dit is geen eenmalige setup. Zelfs de meest betrouwbare repo van 2026, , vertelt gebruikers nog steeds dat ze Playwright, cookies/tokens, proxies en aangepaste page-/session factories nodig kunnen hebben.
Wanneer een no-code tool zoals Thunderbit logisch is
Geen ontwikkelaar? Of een ontwikkelaar die genoeg heeft van de break-fix-cyclus? Een browsergebaseerde AI-tool is de snelste route naar gestructureerde TikTok-data.
We bouwden als een AI-webscraper die werkt als Chrome-extensie. Op TikTok leest het elke zichtbare pagina (profiel, video, hashtag, zoekresultaten), stelt kolommen voor via "AI Suggest Fields" en laat je op "Scrape" klikken om gestructureerde data te extraheren. De documenteert velden zoals plaatsingsdatum, videoduur, likes, shares, saves, reacties, views en hashtags. De laat zien hoe je postthumbnails, URL's, bijschriften, creator-handles en engagementsignalen van profielpagina's verzamelt. De behandelt video-URL, gebruikersnaam van de maker, beschrijving, plaatsingstijd, views, likes, reacties, shares, geluid/audio en de URL van de coverafbeelding.
Met subpagescraping kun je vanaf een profieloverzicht elke videopagina bezoeken en de tabel verrijken met engagementmetrics, bijschriften en hashtags — handig voor marketeers die influencer-databases of concurrentiecontentaudits bouwen.
Geen onderhoud, geen installatiegedoe, geen anti-banconfiguratie. AI past zich automatisch aan lay-outwijzigingen aan. Exporteren kan gratis naar Google Sheets, Excel, Airtable, Notion, CSV of JSON.
Als je uren hebt verbrand aan kapotte GitHub-repos, is dit een legitiem alternatief — geen geforceerde verkooppraat.
Installatiediagnose: de 5 meest voorkomende TikTok-scraper GitHub-setupfouten oplossen
Installatiefouten zijn het derde meest genoemde pijnpunt in TikTok-scrapingforums, en geen enkele grote gids helpt je echt om ze op te lossen. Dit gaat er mis.
Node.js-versieconflicten
Probleem: Veel oudere TikTok-scraperrepos (vooral drawrowfly/tiktok-scraper) zijn gebouwd voor Node.js 14–16. Als je Node 20+ draait, kan npm install stilletjes mislukken of incompatibele binaries opleveren.
Oplossing: Gebruik nvm (Node Version Manager) om de juiste versie te installeren en te kiezen:
1nvm install 16
2nvm use 16
3npm installAls de repo geen Node-versie opgeeft, kijk dan naar het engines-veld in package.json of bekijk de CI-configuratie.
Python-dependencyproblemen en Playwright-setup
Probleem: vereist en Playwright met specifieke browserbinaries. Gebruikers krijgen fouten zoals "browser not found" of dependencyconflicten.
Oplossing: Gebruik altijd een virtual environment en installeer daarna expliciet de Playwright-browsers:
1python -m venv .venv
2source .venv/bin/activate # Op Windows: .venv\Scripts\activate
3pip install TikTokApi
4python -m playwright installAls playwright install mislukt, controleer dan via je package manager of er systeemdependencies ontbreken (bijv. libnss3 op Ubuntu).
Linux/Ubuntu-permissiefouten
Probleem: sudo pip install corrumpeert de systeem-Pythonomgeving en leidt tot kettingreacties van dependencyproblemen.
Oplossing: Gebruik nooit sudo pip install. Maak altijd eerst een virtual environment aan:
1python3 -m venv .venv
2source .venv/bin/activate
3pip install -r requirements.txtHiermee worden de dependencies van de scraper geïsoleerd van je systeem-Python.
Windows-pad- en coderingsproblemen
Probleem: Windows CMD heeft coderingsproblemen en beperkingen in padlengte die scraperinstallaties breken, vooral wanneer Playwright browserbinaries downloadt naar diep geneste mappen.
Oplossing: Gebruik WSL (Windows Subsystem for Linux) of Git Bash in plaats van CMD. WSL geeft je een volledige Linux-omgeving binnen Windows:
1wsl --install
2# Open daarna een WSL-terminal en volg de Linux-setupstappenDe Docker-kortweg: sla dependencyproblemen helemaal over
Probleem: Alles hierboven.
Oplossing: Als je met Docker overweg kunt, containeriseer dan de scraperomgeving. Een basis-Dockerfile voor een Python-gebaseerde TikTok-scraper ziet er zo uit:
1FROM python:3.11-slim
2RUN apt-get update && apt-get install -y libnss3 libatk-bridge2.0-0 libdrm2 libxcomposite1 libxdamage1 libxrandr2 libgbm1 libasound2
3RUN pip install TikTokApi playwright && python -m playwright install --with-deps chromium
4WORKDIR /app
5COPY . .
6CMD ["python", "scrape.py"]Dit garandeert een reproduceerbare omgeving, ongeacht je host-OS. Als de scraper in Docker werkt, is elke fout buiten Docker een omgevingsprobleem, geen codeprobleem.
Flowchart voor probleemoplossing:
- Kan de repo zijn eigen voorbeeld succesvol uitvoeren? → Zo nee, controleer de runtimeversie.
- Runtimeversie correct? → Controleer browser-/Playwright-installatie.
- Browser geïnstalleerd? → Controleer tokens/cookies.
- Tokens/cookies geldig? → Controleer of TikTok de sessie blokkeert.
- Alles hierboven mislukt? → Ga uit van repo-breuk, niet van gebruikersfout. Wissel van tool.
Best practices tegen blokkades bij TikTok-scraping (zonder te betalen voor proxies)
Forumgebruikers klagen herhaaldelijk over bans en detectie: "ze bannen je accounts, wat extra kosten oplevert" en "zonder Apify of dure betaalde API's te gebruiken." Hier zijn gratis, praktische workarounds waarvoor je geen betaald proxyabonnement nodig hebt.

| Praktijk | Moeilijkheid | Kosten | Effectiviteit |
|---|---|---|---|
| Willekeurige vertragingen tussen requests (2–8s jitter) | Makkelijk | Gratis | Gemiddeld |
| Sessie's/cookie-rotatie | Gemiddeld | Gratis | Gemiddeld |
| Alleen openbare pagina's zonder login scrapen | Makkelijk | Gratis | Gemiddeld |
robots.txt + rate-limitheaders respecteren | Makkelijk | Gratis | Basis |
| Fingerprint-randomisatie in headless browsers (Playwright) | Gemiddeld | Gratis | Hoog |
| TikTok's mobiele API-endpoints gebruiken (minder detectie) | Moeilijk | Gratis | Hoog |
| Residential proxy-rotatie | Gemiddeld | $20–100/maand | Hoog |
Gratis technieken die echt helpen
Willekeurige requestvertragingen. Stuur requests niet in een strakke loop. Voeg 2–8 seconden willekeurige jitter toe tussen requests. Dit is het eenvoudigste wat je kunt doen:
1import time, random
2time.sleep(random.uniform(2, 8))Hergebruik van sessie en cookies. Maak niet voor elke request een volledig nieuwe sessie aan. Hergebruik cookies en sessiestatus over een batch requests en roteer daarna. Dat is precies waarom moderne repos om ms_token vragen in plaats van stateless scraping te beloven.
Scrape openbare pagina's zonder login. dat het geen gebruikersgeauthenticeerde routes ondersteunt en alleen werkt op data die zichtbaar is wanneer je bent uitgelogd. Scraping zonder login heeft een lager detectieprofiel dan geauthenticeerde sessies.
Respecteer robots.txt. TikTok's blokkeert veel agents volledig en staat voor algemeen crawlen maar een beperkte set openbare paden toe. Het is geen groen licht voor agressief scrapen, maar het respecteren ervan verkleint de kans op directe IP-blacklisting.
Gevorderde technieken voor hogere slagingspercentages
Fingerprint-randomisatie in headless browsers. Als je Playwright gebruikt, randomiseer per sessie de viewportgrootte, user-agentstring, tijdzone en locale. Daardoor lijkt je scraper telkens op een andere echte gebruiker in plaats van dezelfde bot met een nieuw IP.
TikTok's mobiele API-endpoints gebruiken. Sommige communityleden melden lagere detectie wanneer ze mobile-style endpoints gebruiken in plaats van de webfrontend. Dit is lastiger te implementeren en minder goed gedocumenteerd, maar het is een echte techniek voor gevorderde gebruikers.
Wanneer je toch een proxy nodig hebt (en betaalbare opties)
Op schaal zijn gratis technieken niet genoeg. Residential proxy-rotatie is de standaardaanpak voor TikTok-scraping in grote volumes. Ik noem hier geen specifieke betaalde proxyservice, maar het algemene advies is: vermijd datacenterproxies (TikTok markeert die agressief) en zoek naar residential- of mobiele proxy-pools met rotatie per request.
Browsergebaseerde tools zoals omzeilen de proxyvraag volledig, omdat ze in je eigen browsersessie draaien en een echte gebruiker nabootsen. Dat maakt ze niet immuun voor detectie op schaal, maar voor typische marketing- of onderzoeksuse-cases (tientallen tot honderden pagina's, niet miljoenen) is het een veel eenvoudiger pad.
Welke data krijg je eigenlijk? Echte outputvoorbeelden van TikTok-scrapers
Gebruikers willen vóór ze zich aan een tool verbinden weten welke data ze echt krijgen — en de meeste gidsen slaan dat volledig over. Hier zijn representatieve veldstructuren, gebaseerd op brondocumentatie.
Profielgegevens
| Gebruikersnaam | Weergavenaam | Volgers | Volgend | Totaal aantal likes | Bio | Geverifieerd | Profiel-URL |
|---|---|---|---|---|---|---|---|
| @examplecreator | Jane Doe | 1,240,000 | 312 | 48,700,000 | "Koken + comedy 🍳" | ✅ | tiktok.com/@examplecreator |
| @travelwithmark | Mark S. | 890,000 | 150 | 22,100,000 | "Travel vlogger 🌍" | ❌ | tiktok.com/@travelwithmark |
| @fitnessmaya | Maya L. | 2,100,000 | 88 | 91,300,000 | "Workouts & wellness" | ✅ | tiktok.com/@fitnessmaya |
Beschikbaar via: GitHub-scrapers (TikTok-Api, Evil0ctal), Research API, Thunderbit (van zichtbare profielpagina's).
Videometadata
| Video-URL | Bijschrift | Views | Likes | Reacties | Shares | Muziek | Hashtags | Plaatsingsdatum | Duur |
|---|---|---|---|---|---|---|---|---|---|
| tiktok.com/@ex/video/123 | "Beste pastatruc ooit 🍝" | 4,200,000 | 312,000 | 8,400 | 21,000 | "Italian Vibes – DJ Marco" | #pasta #cooking #hack | 2026-03-15 | 0:42 |
| tiktok.com/@ex/video/456 | "POV: je kat oordeelt over je" | 9,100,000 | 1,100,000 | 23,000 | 55,000 | "Original Sound" | #cat #pov #funny | 2026-04-01 | 0:18 |
| tiktok.com/@ex/video/789 | "Morning routine die niemand had gevraagd" | 1,800,000 | 98,000 | 3,200 | 7,500 | "Chill Morning – LoFi" | #routine #morning | 2026-04-10 | 1:02 |
Beschikbaar via: GitHub-scrapers (TikTok-Api, Evil0ctal), (velden omvatten video_description, view_count, like_count, comment_count, share_count, music_id, hashtag_names, video_duration), Thunderbit ().
Reactiegegevens
| Reageerder | Reactietekst | Likes | Tijdstempel | Antwoorden |
|---|---|---|---|---|
| @user_abc | "Ik heb dit geprobeerd en het werkt echt 😂" | 1,200 | 2026-03-16T08:12:00Z | 14 |
| @chef_dan | "Voeg de volgende keer knoflook toe, geloof me" | 890 | 2026-03-16T09:45:00Z | 7 |
| @randomfan99 | "Hier ben ik voor gekomen" | 340 | 2026-03-16T11:30:00Z | 2 |
Beschikbaar via: GitHub-scrapers (TikTok-Api, Evil0ctal), (velden omvatten text, like_count, reply_count, create_time), Thunderbit (van zichtbare reactiesecties).
Hashtag- en zoekgegevens
| Hashtag | Topvideo-URL | Gecombineerde views | Trending |
|---|---|---|---|
| #pasta | tiktok.com/@ex/video/123 | 4,200,000 | Ja |
| #cooking | tiktok.com/@chef/video/321 | 11,000,000 | Ja |
| #hack | tiktok.com/@tips/video/654 | 2,900,000 | Nee |
Beschikbaar via: GitHub-scrapers (verschilt per repo), Thunderbit ().
Let op: geen enkele repo garandeert alle velden altijd. TikTok-responsstructuren verschuiven, en zelfs maintainers waarschuwen daarvoor. Zie deze voorbeelden als representatief, niet als gegarandeerd.
Hoe je TikTok-data in 2 klikken scrape met Thunderbit (stap voor stap)
Genoeg van de break-fix-cyclus? Hier is de no-code route — de uitweg voor iedereen die GitHub-repos heeft geprobeerd en gefaald.
- Installeer de .
- Navigeer naar de TikTok-pagina die je wilt scrapen — een profiel, zoekresultatenpagina, hashtagpagina of individuele video.
- Klik op "AI Suggest Fields". Thunderbit's AI leest de pagina en stelt kolommen voor: gebruikersnaam, volgers, videobijschrift, likes, hashtags, enz.
- Pas de velden aan indien nodig en klik op "Scrape". De data wordt ingevuld in een gestructureerde tabel.
- Gebruik Subpage Scraping om data te verrijken. Klik vanuit een profieloverzicht door naar elke videopagina en haal extra velden op: volledig bijschrift, muziekinformatie, aantal reacties, aantal shares.
- Exporteer naar Google Sheets, Excel, Airtable of Notion — helemaal gratis.
Geen onderhoud, geen installatiegedoe, geen anti-banconfiguratie. De AI past zich automatisch aan TikTok-lay-outwijzigingen aan.
TikTok-data verrijken met subpagescraping
Nadat je een lijst video's van een profiel- of hashtagpagina hebt gescrapet, klik je op "Scrape Subpages" zodat de AI elke videopagina bezoekt en extra velden ophaalt. Dit is vooral handig voor marketeers die influencer-databases bouwen of concurrentiecontentaudits uitvoeren — je krijgt een complete tabel met engagementdata op videoniveau zonder handmatig door tientallen pagina's te klikken.
Je TikTok-data exporteren en gebruiken
Thunderbit exporteert gratis naar Google Sheets, Excel, Airtable, Notion, CSV of JSON. Veelvoorkomende use-cases:
- Zet de data in een spreadsheet voor engagementanalyse.
- Stuur het naar Airtable voor een CRM-achtige influencertracker.
- Zet het in Notion voor teamsamenwerking rond contentonderzoek.
Voor een diepere blik op hoe Thunderbit webdata-extractie aanpakt, bekijk onze of volg tutorials op het .
Binnen de wet blijven: TikTok-voorwaarden en scraping-compliance
TikTok's juridische standpunt is duidelijk. De van het platform zegt dat de Servicevoorwaarden geautomatiseerde scripts verbieden die informatie verzamelen of op niet-geautoriseerde manieren met de dienst omgaan, en noemt expliciet het omzeilen van toegangsbeperkingen. TikTok's verbieden ook misleidende pogingen om informatie te verkrijgen via geautomatiseerde scripts of webcrawling.
Praktisch advies:
- Blijf bij publiek beschikbare data. Scrape geen privé- of login-afgeschermde content.
- Respecteer rate limits. Bestook TikTok's servers niet.
- Voldoe aan privacywetgeving. GDPR en CCPA blijven gelden als je persoonlijke data verzamelt, opslaat of analyseert.
- Gebruik de Research API wanneer je daarvoor in aanmerking komt. Dat is vanuit compliance-oogpunt het veiligste pad.
- Dit is geen juridisch advies. Raadpleeg een professional voor jouw specifieke situatie.
Voor meer over het juridische landschap, zie onze gids over .
Wat je moet doen wanneer je TikTok-scraper GitHub-repo sterft
De korte versie:
- Voer altijd de 60-seconden Repo Vitals Checklist uit voordat je een TikTok-scraper van GitHub kloont. De meeste repos zijn al dood.
- Begrijp je opties. De officiële API, GitHub-scrapers en no-code tools dienen verschillende gebruikers en use-cases.
- Als je de GitHub-route kiest, reserveer dan tijd voor installatieproblemen en anti-banconfiguratie. Reken op doorlopend onderhoud.
- Weet welke data je echt krijgt voordat je je aan een tool commit. Kijk naar de outputvelden, niet alleen naar het aantal sterren.
- Als je geen ontwikkelaar bent (of moe bent van kapotte repos), probeer dan een no-code tool zoals — twee klikken, gestructureerde data, gratis export.
De TikTok-data die je nodig hebt is toegankelijk. De vraag is alleen of je je tijd wilt besteden aan het onderhouden van een scraper of aan het daadwerkelijk gebruiken van de data. Kies de aanpak die past bij je vaardigheidsniveau en use-case, en laat een dode GitHub-repo niet nog een middag verspillen.
Veelgestelde vragen
Zijn er nog TikTok-scrapers op GitHub die in 2026 werken?
Ja, maar de lijst is kort. is de meest geloofwaardige open-sourceoptie met actief onderhoud per april 2026. leeft ook nog, maar is complexer. De repo met de meeste sterren, drawrowfly/tiktok-scraper, is sinds mei 2023 niet meer bijgewerkt en is feitelijk dood. Voer altijd de Repo Vitals Checklist uit voordat je tijd in een repo stopt.
Is het legaal om TikTok te scrapen?
TikTok's Servicevoorwaarden verbieden expliciet geautomatiseerd scrapen. Publiek zichtbare data bevindt zich in een juridische grijze zone die per jurisdictie verschilt. De veiligste route is de officiële voor in aanmerking komende onderzoekers. Als je openbare data scrapt, houd je dan aan publiek toegankelijke content, respecteer rate limits en voldoe aan GDPR/CCPA. Dit is geen juridisch advies — raadpleeg een professional voor jouw situatie.
Kan ik TikTok scrapen zonder te coderen?
Ja. Browsergebaseerde AI-tools zoals laten je gestructureerde TikTok-data extraheren (profielen, videometadata, hashtags, engagementmetrics) zonder code te schrijven. De TikTok Research API vereist voor goedgekeurde aanvragers ook maar weinig coderen. Voor niet-ontwikkelaars zijn no-code tools de snelste en betrouwbaarste route.
Welke data kan ik krijgen van een TikTok-scraper?
Veelvoorkomende datatypes zijn profielinformatie (gebruikersnaam, volgers, bio, verificatiestatus), videometadata (bijschrift, views, likes, reacties, shares, muziek, hashtags, duur, plaatsingsdatum), reacties (tekst, likes, tijdstempel, antwoorden) en hashtag-/zoekgegevens (topvideo's, totale views, trendingstatus). De exacte velden hangen af van de tool en methode — zie hierboven het gedeelte met outputvoorbeelden voor details.
Waarom wordt mijn TikTok-scraper steeds geblokkeerd?
TikTok gebruikt meerdere lagen anti-botverdediging: rate limiting, cookie-/sessieafscherming, browser fingerprinting, gedragsdetectie, versleutelde requestparameters en CAPTCHA-stromen. Veelvoorkomende oorzaken van blokkades zijn te snel requests sturen, voor elke request een schone/nieuwe sessie gebruiken, een headless browser met standaardfingerprints draaien of datacenterproxies gebruiken. Zie hierboven het gedeelte met best practices tegen blokkades voor gratis en betaalde workarounds.