

Is webscraping illegaal? Dat is de vraag die ik elke week hoor van founders, marketeers en data-nerds.
Met 51% van al het internetverkeer dat nu afkomstig is van bots—voor het eerst is geautomatiseerd verkeer groter dan menselijk verkeer—en een groot deel daarvan webscraping voor business intelligence, sales en AI-training, is het geen verrassing dat iedereen probeert uit te zoeken waar de juridische grenzen liggen.
De ene dag zie je een kop over een rechterlijke uitspraak waarin staat dat het scrapen van openbare data gewoon mag. De volgende dag waarschuwen toezichthouders voor "onrechtmatige" data harvesting van social media. Het is verwarrend, zelfs voor mensen zoals ik die hun dagen besteden aan het bouwen van AI-webscrapingtools bij Thunderbit.
Dus: is webscraping illegaal? Het antwoord is niet simpelweg ja of nee. Het hangt af van wat je scrapt, waar je het vandaan haalt, hoe je de data gebruikt en wat de wet zegt in jouw land.
In deze deep dive zet ik het juridische landschap uiteen, ontkracht ik een paar hardnekkige mythes en deel ik praktische tips (plus een paar lessen uit de praktijk) om compliant te blijven—of je nu solo founder bent of werkt in een datateam van een Fortune 500-bedrijf.
Webscraping en de wet: is er een duidelijke grens?
Als je hoopt op een antwoord in één zin, bespaar ik je graag wat tijd: de wet heeft nog geen heldere, scherpe grens getrokken rond webscraping.
In plaats daarvan is er een lappendeken van overlappende regels—eigendomsrechten op data, privacy, intellectueel eigendom, anti-hackwetten en die beruchte Terms of Service (ToS). Elk daarvan kan een rol spelen, en het antwoord hangt vaak af van jouw specifieke situatie (multilogin.com).
Laten we de drie grote juridische categorieën even uit elkaar trekken:
- Data-eigendom: Over het algemeen zijn feiten en openbare informatie (zoals prijzen of telefoonnummers) niet auteursrechtelijk beschermd. Maar creatieve content (artikelen, afbeeldingen) en eigen databases kunnen wel beschermd zijn—zeker in de EU, waar "database rights" bestaan (cliffordchance.com).
- Privacy: Moderne privacywetgeving (denk aan de GDPR in Europa, PIPL in China) ziet persoonsgegevens als een gereguleerd goed—zelfs als die openbaar zijn geplaatst. Namen, e-mails of socialprofielen scrapen zonder wettelijke grondslag kan je in de problemen brengen (ico.org.uk).
- Contracten (Terms of Service): Veel sites verbieden scraping expliciet in hun ToS. Hoewel ToS geen wet zijn, kunnen rechters ze als bindende contracten zien. Overtreding kan leiden tot rechtszaken en in sommige gevallen zelfs anti-hackstatuten activeren als je technische blokkades omzeilt (cliffordchance.com).
Dus: is webscraping illegaal? Soms ja, soms nee, en vaak is het antwoord: "het hangt ervan af." De duivel zit in de details.
Juridische perspectieven vergeleken: VS, EU, VK, China
Hier is een korte tabel die laat zien hoe grote regio's tegen webscraping aankijken:
| Regio | Scrapen van openbare data | Scrapen van persoonlijke/private data | Handhaving & opvallende punten |
|---|---|---|---|
| VS | Over het algemeen toegestaan voor openbare data (zie hiQ v. LinkedIn). Overtreding van ToS kan leiden tot civiele rechtszaken. | Beperkt/illegaal als je inloggegevens omzeilt of persoonsgegevens misbruikt. Staatswetten (zoals CCPA) kunnen van toepassing zijn. | Cease-and-desist-brieven, IP-blokkades, rechtszaken. CFAA geldt als je technische barrières omzeilt. |
| EU | Voorwaardelijk toegestaan voor niet-persoonlijke, openbare data. Database rights kunnen van toepassing zijn. De EU AI Act (2026) voegt transparantie-eisen toe voor AI-trainingsdata. | Streng gereguleerd onder GDPR—even openbare persoonsgegevens vereisen een wettelijke grondslag. | Gegevensbeschermingsautoriteiten kunnen boetes opleggen voor privacyschendingen. Auteursrecht/database rights worden ook gehandhaafd. De EU AI Act verbiedt het scrapen van gezichtsafbeeldingen voor AI. |
| VK | Vergelijkbaar met de EU. Openbare, niet-persoonlijke data mag worden gescrapet, maar datarechten en contracten moeten worden gerespecteerd. | Streng op persoonsgegevens—de UK GDPR is van toepassing. De Computer Misuse Act stelt ongeoorloofde toegang strafbaar. | ICO kan boetes opleggen voor overtredingen van gegevensbescherming. Rechters kunnen ToS afdwingen. |
| China | Strak gecontroleerd. Openbare, niet-persoonlijke data mag voor intern gebruik worden gescrapet, maar de omgeving is voorzichtig. | Sterk beperkt—de PIPL vereist toestemming voor persoonsgegevens. Anti-unfair competition laws zijn van toepassing. | Strafzaken voor grootschalig scrapen. Rechters gebruiken het mededingingsrecht om ongeoorloofd scrapen te stoppen. |
Is webscraping illegaal? Belangrijke juridische factoren om te overwegen
Wat bepaalt nu eigenlijk of jouw scrapingproject legaal of riskant is? Dit zijn de belangrijkste factoren:
- Openbare vs. privédata: Data scrapen die iedereen op het open web kan zien, is doorgaans veiliger. Iets scrapen achter een login, betaalmuur of technische barrière? Dan is het waarschijnlijk illegaal (thunderbit.com).
- Aard van de data: Persoonsgegevens (namen, e-mails, profielen) activeren privacywetgeving. Auteursrechtelijk beschermde content (artikelen, afbeeldingen) mag je niet zomaar volledig kopiëren. Zuivere feiten (prijzen, weergegevens) zijn meestal fair game (oxylabs.io).
- Beoogd gebruik: Intern analyseren of onderzoek doen wordt meestal milder beoordeeld dan het herpubliceren of verkopen van gescrapete data. Gescrapete data gebruiken om direct te concurreren met de bron? Dat vraagt om een rechtszaak (thunderbit.com).
- Naleving van websiteregels: Check altijd robots.txt en ToS. Robots.txt is niet juridisch bindend, maar het is wel goede praktijk om het te respecteren. Overtreding van ToS kan leiden tot civiele claims of erger (promptcloud.com).
- Technische maatregelen: Scrapen met menselijke snelheid en beveiligingsmaatregelen niet omzeilen is cruciaal. Een server overbelasten of CAPTCHAs omzeilen kan de grens naar hacking overschrijden (cliffordchance.com).
Wat veranderde er in 2024–2026: belangrijke rechtszaken en regels
Het juridische landschap rond webscraping is sinds 2023 flink veranderd. Dit zijn de ontwikkelingen die elke scraper moet kennen:
Belangrijke rechterlijke uitspraken
-
Meta v. Bright Data (2024): Een Amerikaanse federale rechtbank oordeelde dat Meta's Terms of Service het scrapen van openbare data door niet-ingelogde gebruikers niet verbieden. De rechter vond dat "een bezoeker niet als 'user' wordt gezien tenzij die een account heeft." Meta liet de resterende claims kort daarna vallen. Dit is een mijlpaal voor het scrapen van openbare data.
-
X Corp v. Bright Data (2024): Twitter (nu X) verloor een vergelijkbare rechtszaak, wat hetzelfde principe bevestigt: het scrapen van publiek toegankelijke data zonder in te loggen is geen ToS-schending, omdat de scraper nooit met die voorwaarden akkoord is gegaan.
-
Reddit v. Perplexity AI (oktober 2025): Reddit daagde Perplexity AI en meerdere scrapingproviders voor de rechter, met een beroep op de DMCA en een claim van omzeiling van anti-botsystemen. Dit wijst op een nieuwe juridische strategie: platforms schakelen over op auteursrecht- en anti-omzeilingsclaims in plaats van de CFAA.
-
NYT v. OpenAI (maart 2025): Een federale rechter liet de auteursrechtszaak van The New York Times tegen OpenAI doorgaan en verwierp het verzoek van OpenAI om afwijzing. Dit kan een belangrijk precedent zetten voor de vraag of het scrapen van content om AI-modellen te trainen als "fair use" geldt.
-
Anthropic-schikking (september 2025): Anthropic stemde ermee in $1,5 miljard te betalen om een Amerikaanse class action over het gebruik van auteursrechtelijk beschermde teksten voor AI-training te schikken—een duidelijk signaal dat de kosten van scrapen voor AI heel reëel zijn.
De grote trend: van CFAA naar contract- en auteursrecht
Het patroon is duidelijk: de CFAA (Computer Fraud and Abuse Act) verliest aan kracht als wapen tegen scrapers van openbare data. Bedrijven die de CFAA probeerden in te zetten tegen het scrapen van openbare data—Meta, X, LinkedIn—hebben grotendeels verloren. In plaats daarvan verschuift het juridische strijdtoneel naar:
- Contractrecht (ToS-schendingen—maar rechters zeggen dat niet-gebruikers niet gebonden zijn aan ToS)
- Auteursrechtclaims (vooral bij AI-trainingsdata)
- Anti-omzeilingsstatuten (DMCA Section 1201)
Voor scrapers betekent dit: het juridische risico is niet verdwenen—het is alleen verschoven.
Wijzigingen in regelgeving
- CCPA-updates 2026: De herziene CCPA-regels van Californië zijn op 1 januari 2026 van kracht geworden, met nieuwe regels voor geautomatiseerde besluitvorming (ADMT), risicobeoordelingen en verplichtingen voor data brokers.
- Nieuwe privacywetten in Amerikaanse staten: Indiana, Kentucky en Rhode Island hebben uitgebreide privacywetten aangenomen die in 2026 van kracht werden.
- EU AI Act: Volledige handhaving begint op 2 augustus 2026—AI-ontwikkelaars moeten bronnen van trainingsdata bekendmaken, auteursrechtelijke opt-outs respecteren en het scrapen van gezichtsafbeeldingen voor AI-systemen verbieden.
- AI Accountability for Publishers Act (februari 2026): Een voorgestelde Amerikaanse wet die AI-bedrijven zou verplichten om toestemming te vragen en uitgevers te betalen voordat ze hun content scrapen.
Scrapingbeleid van grote platforms: wat je moet weten
Niet elke website gaat hetzelfde om met scraping. Hier is een platform-voor-platform overzicht van wat de grootste sites toestaan, wat ze blokkeren en wat rechters hebben gezegd:
| Platform | ToS over scraping | Technische verdediging | Juridische handhaving | Wat in de praktijk veilig is |
|---|---|---|---|---|
| Google (Zoeken & Maps) | Verbiedt geautomatiseerde toegang in de ToS. Het Maps Platform heeft een expliciete "No Scraping"-clausule. | SearchGuard JS-uitdagingen, CAPTCHAs, rate limiting. Robots.txt werd in 2025 aangepast om AI-crawlers te blokkeren. | Daagde scrapers in dec. 2025 voor de rechter met een DMCA-claim. Blokkeert actief AI-crawlers (Anthropic, Meta, OpenAI). | Het scrapen van openbare Google Maps-bedrijfsdata is juridisch verdedigbaar (hiQ-precedent), maar reken op technische blokkades. Gebruik waar mogelijk officiële API's. |
| Amazon | Verbiedt expliciet alle scraping in de Conditions of Use ("no robot, spider, scraper, or other automated means"). | Agressieve botdetectie, CAPTCHA, IP-blokkering. robots.txt blokkeert alle bots behalve Googlebot/Bingbot. Blokkeert sinds 2025 ook expliciet AI-crawlers. | Daagde Perplexity AI in nov. 2025 voor de rechter. Stuurt regelmatig cease-and-desist-brieven. Werkte de BSA in maart 2026 bij met regels voor AI-agenten. | Open productdata (prijzen, vermeldingen) zijn feitelijk en onder de Amerikaanse wet te scrapen, maar Amazon vecht hard terug. Beperk verzoeken en vermijd persoonsgegevens. |
| Verbiedt scraping in de ToS; vereist gebruikersovereenkomst om toegang te krijgen tot de diensten. | Loginmuren voor de meeste profieldata, anti-botdetectie, rate limiting. | De hiQ-zaak bevestigde dat het scrapen van openbare profielen geen CFAA-schending is, maar LinkedIn won op contract- en oneerlijke concurrentieclaims toen valse accounts werden gebruikt. | Openbare profielen (zichtbaar zonder login) zijn juridisch verdedigbaar om te scrapen. Maak nooit nepaccounts aan en scrape geen data achter inlogschermen. | |
| Meta (Facebook & Instagram) | ToS verbieden scraping; aparte regels voor ingelogde versus uitgelogde data. | Loginmuren voor de meeste content, geavanceerde botdetectie. | Verloor in 2024 van Bright Data—de rechter oordeelde dat ToS niet gelden voor scrapers die niet zijn ingelogd. Liet de resterende claims vallen. | Openbare data (bedrijfspagina's, openbare posts) die zonder login zichtbaar is, staat juridisch sterker. Scrape nooit privéprofielen of data achter een login. |
| X (Twitter) | Werkte de ToS in 2023 bij om al het scrapen en crawlen zonder schriftelijke toestemming te verbieden. Schafte de oude robots.txt-uitzondering af. | robots.txt blokkeert alle crawlers (Disallow: /). Cloudflare Turnstile-uitdagingen. Strikte rate limits (300 verzoeken/uur). IP-reputatiescoring. | Verloor op openbare data van Bright Data, maar beperkt technische toegang agressief. | Openbare tweets en profielen zijn juridisch verdedigbaar, maar de technische barrières van X behoren in 2026 tot de zwaarste. Verwacht blokkades zonder premium proxy-infrastructuur. |
De kern: Rechters hebben consequent geoordeeld dat het scrapen van publiek zichtbare data zonder in te loggen geen CFAA-schending is. Maar platforms kunnen je nog steeds aanpakken op basis van contractrecht, auteursrecht of anti-omzeiling—en ze zullen het je technisch zo lastig mogelijk maken. Scrape dus altijd verantwoord.
AI-trainingsdata en webscraping: de nieuwe juridische voorhoede
Als je in 2026 het nieuws volgt, weet je dat data scrapen voor AI-modellen trainen het heetste juridische strijdtoneel is geworden. Dit gebeurt er:
- Auteursrechtszaken stapelen zich op. The New York Times, auteurs en uitgevers hebben OpenAI, Anthropic en anderen aangeklaagd, met de claim dat massaal scrapen van auteursrechtelijk beschermde content om LLM's te trainen geen "fair use" is. Anthropic schikte in 2025 een grote class action voor $1,5 miljard—een duidelijk teken dat de kosten van scrapen voor AI heel reëel zijn.
- Het fair-use-verweer is wankel. Amerikaanse rechtbanken hebben nog geen definitieve uitspraak gedaan over de vraag of het trainen van AI op gescrapete data onder fair use valt. Vroege uitspraken suggereren dat het sterk afhangt van hoe de data is verkregen en wat er met de AI-output wordt gedaan.
- Nieuwe wetgeving komt eraan. De AI Accountability for Publishers Act (ingediend in februari 2026) wil AI-bedrijven verplichten om toestemming te vragen en uitgevers te betalen voordat ze hun content scrapen.
- De EU AI Act (volledige handhaving augustus 2026) verplicht AI-ontwikkelaars om bronnen van trainingsdata bekend te maken, machine-readable copyright opt-outs te respecteren (onder de TDM-uitzondering van de Auteursrechtrichtlijn) en AI-gegenereerde content te labelen. Ook verbiedt de wet AI-systemen die gezichtsafbeeldingen van internet scrapen.
- AI/LLM-crawlers groeien explosief. AI-crawlers verviervoudigden hun aandeel in webverkeer van 2,6% naar 10,1% in slechts acht maanden. Alleen al OpenAI's GPTBot groeide met 305%. In reactie daarop passen grote sites (Amazon, Reddit, de NYT) hun robots.txt aan om AI-crawlers expliciet te blokkeren.
Wat dit voor jou betekent: Als je data scrapt voor traditionele zakelijke doeleinden (leadgeneratie, prijsmonitoring, marktonderzoek), dan gelden deze AI-specifieke regels mogelijk niet direct. Maar als je gescrapete data in AI-modellen stopt, wees dan extreem voorzichtig—en vraag juridisch advies.
Webscrapingwetten wereldwijd: een snelle vergelijking
Laten we uitzoomen en kijken hoe de regels wereldwijd uitpakken:
- Verenigde Staten: Geen algeheel verbod. Het scrapen van openbaar toegankelijke sites is in het algemeen toegestaan (hiQ v. LinkedIn), en de uitspraken van 2024 in Meta en X Corp hebben de positie voor het scrapen van openbare data verder versterkt. Maar scrapen achter logins of technische blokkades kan nog steeds de CFAA triggeren. De trend verschuift nu naar bedrijven die contractrecht en auteursrechtclaims inzetten. Privacywetten breiden snel uit: CCPA kreeg grote updates die op 1 januari 2026 ingingen, inclusief nieuwe regels voor geautomatiseerde besluitvorming en verplichtingen voor data brokers. Indiana, Kentucky en Rhode Island hebben in 2026 ook uitgebreide privacywetten aangenomen.
- Europese Unie: Strenge privacywetgeving. GDPR geldt zelfs voor openbare persoonsgegevens. Database rights kunnen grootschalig scrapen van gestructureerde data blokkeren (cliffordchance.com). NIEUW: De EU AI Act treedt volledig in werking op 2 augustus 2026, waardoor AI-ontwikkelaars hun bronnen van trainingsdata moeten bekendmaken en copyright opt-outs moeten respecteren. De wet verbiedt het scrapen van gezichtsafbeeldingen van internet voor AI-systemen.
- Verenigd Koninkrijk: Lijkt na Brexit op de EU-regels. Openbare data mag worden gescrapet, maar het scrapen van persoonsgegevens is streng gereguleerd. De Computer Misuse Act kan ongeoorloofde toegang strafbaar stellen.
- China: Zeer restrictief. De PIPL en Data Security Law vereisen toestemming voor persoonsgegevens. Rechters gebruiken het mededingingsrecht om scrapen te blokkeren dat bedrijven schaadt (malwarebytes.com).
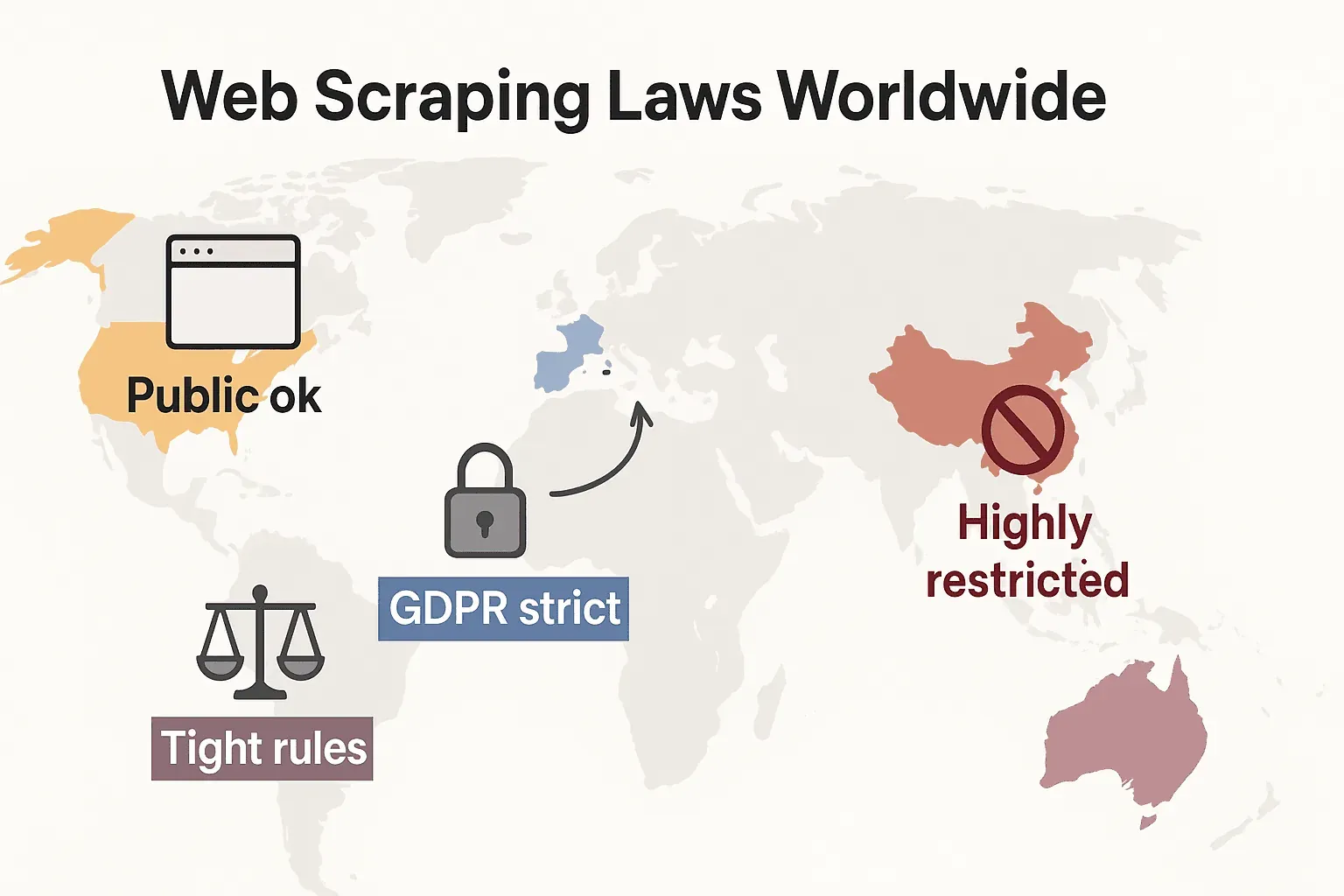
Kortom: het scrapen van openbare, niet-persoonlijke data voor intern gebruik is doorgaans het veiligst. Iets anders? Check de lokale wetgeving en wees voorzichtig.
Veelvoorkomende mythes over de legaliteit van webscraping
Laten we een paar mythes ontkrachten die ik voortdurend hoor:
- Mythe 1: "Webscraping is simpelweg illegaal."
Onjuist. Er is geen wet die alle vormen van webscraping verbiedt. Het draait om hoe en wat je scrapt (oxylabs.io). - Mythe 2: "Als data openbaar is, mag ik ermee doen wat ik wil."
Niet helemaal. Openbare data kan nog steeds beschermd zijn door privacy- of auteursrechtwetgeving, en ToS kunnen bepaalde toepassingen beperken (ico.org.uk). - Mythe 3: "Webscraping is hetzelfde als hacken."
Nee. Het scrapen van openbare webpagina's is geen hacken. Inlogschermen of technische barrières omzeilen is een ander verhaal (calawyers.org). - Mythe 4: "Als ik niet gepakt word, is het prima."
Risicovol denken. Veel sites gebruiken anti-bottechnologie en merken het op. Stilte is geen toestemming. - Mythe 5: "Bronvermelding geven of de data intern gebruiken maakt het oké."
Bronvermelding heft auteursrecht of privacywetgeving niet op. Intern gebruik is veiliger, maar geen vrijbrief. - Mythe 6: "Alle webscraping schendt privacy."
Niet elk scrapingproces draait om persoonsgegevens. Maar grote hoeveelheden persoonlijke informatie scrapen zonder waarborgen is bijna altijd illegaal (oxylabs.io). - Mythe 7: "Als een website in de ToS scraping verbiedt, is scrapen altijd illegaal."
Niet per se. In 2024 oordeelden rechters in Meta v. Bright Data en X Corp v. Bright Data dat ToS niet bindend zijn voor gebruikers die er nooit mee akkoord zijn gegaan—dus als je scrapt zonder in te loggen of een account aan te maken, gelden de ToS van de site mogelijk niet voor jou. Dit gebied is nog volop in ontwikkeling, maar het is wel een belangrijke verschuiving.
Hoe je data legaal scrapt: best practices voor compliance
Dit is mijn vaste checklist voor legaal en ethisch webscrapen:
- Lees en respecteer de Terms of Service van de site. Als daar staat "geen scraping", stop dan of vraag toestemming (ql2.com).
- Blijf bij openbare data. Als je een wachtwoord nodig hebt, is het afgeschermd—scrape het niet (thunderbit.com).
- Check robots.txt en crawl netjes. Niet juridisch bindend, maar wel goede etiquette. Overbelast servers niet—spreid je verzoeken (promptcloud.com).
- Vermijd persoonsgegevens tenzij je een wettelijke grondslag hebt. Moet je ze toch verzamelen, voldoe dan aan GDPR/CCPA en verzamel zo min mogelijk.
- Herpubliceer gescrapete content niet volledig. Voeg waarde of analyse toe, of vraag toestemming (thunderbit.com).
- Voer gescrapete content niet blind in AI-modellen in zonder auteursrecht te checken. Het juridische landschap verandert snel—vraag advies als dit jouw use case is.
- Gebruik waar mogelijk officiële API's of data-exports. Die zijn voor dit doel gemaakt en meestal veiliger (thunderbit.com).
- Wees transparant en verantwoord. Als je persoonsgegevens verzamelt, informeer mensen dan en houd een logboek bij van je activiteiten.
- Minimaliseer en beveilig je data. Verzamel alleen wat je nodig hebt, houd het accuraat en sla het veilig op.
- Blijf op de hoogte en vraag juridisch advies bij randgevallen. Wetten en rechterlijke uitspraken veranderen snel—zeker de EU AI Act en Amerikaanse privacywetten per staat. Bij twijfel: vraag een professional.
Probeer de Thunderbit Chrome-extensie voor compliant scrapen
Webscrapingtools legaal gebruiken: wat bedrijven moeten weten
Webscrapingtools zoals Thunderbit maken dataverzameling toegankelijk voor niet-programmeurs, maar je moet ze nog steeds verantwoord gebruiken:
- Kies tools met compliance als uitgangspunt. Thunderbit scrapt bijvoorbeeld alleen wat je in je browser kunt zien—geen stiekeme API-hacks of ongeoorloofde toegang (thunderbit.com).
- Blijf bij legitieme use cases. Interne analyses, marktonderzoek en concurrentieprijsmonitoring zijn doorgaans veilig. Gescrapete data herpubliceren of verkopen? Veel risicovoller.
- Configureer tools voor compliance. Stel crawlvertragingen in, respecteer robots.txt en gebruik sjablonen die alleen verzamelen wat je nodig hebt.
- Houd het intern. Gescrapete data intern gebruiken is veiliger dan het herpubliceren.
- Onderwijs je team. Zorg dat iedereen de regels en best practices begrijpt.
- Maak gebruik van ingebouwde compliance-functies. Thunderbit waarschuwt gebruikers voor risicovolle sites, scrapt met menselijke snelheid en slaat je data niet op zijn servers op.
- Forceer niets. Als een tool een site niet kan scrapen, probeer dan niet om er omheen te hacken. Niet alle data is zonder risico te verkrijgen.
Thunderbit's aanpak: compliant AI-webscraping mogelijk maken
Bij Thunderbit hebben we veel tijd besteed aan compliance. Zo helpt onze AI-webscraper gebruikers aan de juiste kant van de wet te blijven:
- Scrapt alleen wat je kunt zien. Thunderbit werkt in je browsersessie, dus het kan geen data ophalen die je niet handmatig zou kunnen kopiëren.
- Begeleidt gebruikers met waarschuwingen. Als je een site probeert te scrapen met strikte anti-scrapingregels, waarschuwt Thunderbit je.
- Menselijke scrapesnelheden. Of je nu lokaal of in de cloud scrapt, Thunderbit overbelast servers niet.
- Aanpasbare dataselectie. Onze AI stelt relevante kolommen voor, zodat je alleen verzamelt wat je nodig hebt.
- Ondersteuning voor subpagina's en paginering. Thunderbit navigeert door sites als een echte gebruiker en houdt rekening met hun structuur.
- Privacy en beveiliging. Jouw data blijft van jou—Thunderbit slaat het niet op en gebruikt het niet opnieuw.
- Compliance-vriendelijke exports. Exporteer direct naar Google Sheets, Airtable, Notion of CSV voor veilig intern gebruik.
- Planning en automatisering. Stel terugkerende scrapes in op verantwoorde intervallen.
- Ondersteuning voor meerdere talen. De UI van Thunderbit ondersteunt 34 talen, waardoor compliance wereldwijd toegankelijk wordt.
- Regelmatige sjabloonupdates. Onze instant templates voor populaire sites worden actueel gehouden met juridische en technische veranderingen.
Door compliance in het product te verankeren helpt Thunderbit teams de data te verzamelen die ze nodig hebben—zonder juridische hoofdpijn.
Vooroplopen: omgaan met juridische en technische veranderingen in webscraping
Ontdek meer gidsen over webscraping Get Started Free
Webscraping is geen kwestie van instellen en vergeten. Wetten en website-structuren veranderen voortdurend. Zo blijf je voorop:
- Volg juridische ontwikkelingen. Het tempo van verandering versnelde in 2024–2026—volg nieuws over techrecht, updates van toezichthouders en brancheblogs (zoals Thunderbit's). Houd de handhaving van de EU AI Act in de gaten (augustus 2026), nieuwe privacywetten in Amerikaanse staten en lopende auteursrechtzaken rond AI.
- Pas je aan aan technische veranderingen. Sites updaten hun lay-outs en anti-botverdediging voortdurend. Grote platforms (Amazon, X, Google) hebben hun beveiliging in 2025–2026 sterk aangescherpt. Thunderbit's AI en templates zijn ontworpen om zich automatisch aan te passen.
- Omarm officiële API's wanneer die beschikbaar zijn. Als een site overstapt op een betaald API-model, overweeg dan de overstap voor betrouwbaarheid en compliance.
- Audit je scraping regelmatig. Documenteer je bronnen, controleer ToS- of beleidswijzigingen en pas je strategie aan waar nodig.
- Gebruik Thunderbit's template-updates. Ons team houdt templates actueel, zodat jij je geen zorgen hoeft te maken over breaking changes of nieuwe compliance-eisen.
- Blijf flexibel. Als een databron te risicovol wordt, kies dan voor een andere bron of zoek een samenwerking.
Met de juiste tools en mindset kun je je datapijplijn draaiende houden—zonder op juridische landmijnen te stappen.
Conclusie: navigeren door het juridische landschap van webscraping
Webscraping is niet per definitie illegaal—het is een krachtig hulpmiddel voor business, onderzoek en innovatie. Maar zoals elk hulpmiddel kent het regels. Het draait om het begrijpen van wat je scrapt, hoe je scrapt en wat je met de data doet. Respecteer lokale wetten, volg websitebeleid en gebruik compliancegerichte tools zoals Thunderbit om je processen netjes en verantwoord te houden.
De rechterlijke uitspraken uit 2024–2026 (Meta v. Bright Data, X Corp v. Bright Data) hebben de positie voor het scrapen van openbare data versterkt, maar er ontstaan nieuwe risico's rond AI-trainingsdata, auteursrechtclaims en de EU AI Act. Het beleid verschilt sterk per platform—Google, Amazon, LinkedIn, Meta en X handhaven elk hun regels op een andere manier—dus ken het landschap voordat je gaat scrapen.
Als je twijfelt, vraag juridisch advies—zeker bij grote of gevoelige projecten. En vergeet niet: het juridische landschap verandert voortdurend, dus blijf op de hoogte en wendbaar.
Meer leren over webscraping, compliance en automatisering? Bekijk de Thunderbit Blog voor meer gidsen, of probeer Thunderbit's Chrome-extensie zelf.
Begin met compliant webscraping met Thunderbit
Veelgestelde vragen
1. Is webscraping overal illegaal?
Nee. Webscraping is niet per definitie illegaal, maar de legaliteit hangt af van wat je scrapt, hoe je dat doet en waar je bent. Het scrapen van openbare, niet-persoonlijke data voor intern gebruik is in de meeste regio's doorgaans toegestaan, maar het scrapen van persoonlijke of auteursrechtelijk beschermde data, of het overtreden van sitevoorwaarden, kan illegaal zijn (oxylabs.io).
2. Maakt robots.txt scrapen illegaal als ik het negeer?
Robots.txt is niet juridisch bindend, maar het is wel goed gebruik om het te respecteren. Robots.txt negeren levert op zichzelf niet meteen een rechtszaak op, maar het kan je in een conflict wel laten lijken op een "bad actor" (promptcloud.com).
3. Kan ik Google, Amazon of LinkedIn scrapen?
Dat is ingewikkeld. Alle drie verbieden scraping in hun ToS, maar rechters hebben geoordeeld dat ToS mogelijk niet bindend zijn voor niet-ingelogde gebruikers (zie Meta v. Bright Data en X Corp v. Bright Data, beide uit 2024). Het scrapen van publiek zichtbare data (productprijzen, bedrijfsvermeldingen, openbare profielen) is in de VS doorgaans juridisch verdedigbaar. Wel handhaaft elk platform anders: Amazon is het agressiefst met juridische stappen (het daagde Perplexity AI in november 2025 voor de rechter); LinkedIn leunt op technische blokkades en contractclaims; Google gebruikt steeds vaker handhaving op basis van de DMCA. Scrape altijd verantwoord en reken op technische tegenmaatregelen.
4. Kan ik Facebook of Instagram scrapen?
Na Meta v. Bright Data (2024) staat het scrapen van openbare data van Facebook en Instagram zonder in te loggen juridisch sterker. De rechter oordeelde dat Meta's ToS niet gelden voor niet-gebruikers. Maar maak nooit nepaccounts aan en scrape nooit data achter loginmuren—dan ga je over de grens.
5. Kan ik X (Twitter) scrapen?
X paste zijn ToS in 2023 aan om al het scrapen zonder schriftelijke toestemming te verbieden en heeft agressieve technische verdediging ingezet (Cloudflare Turnstile, limieten van 300 verzoeken/uur, IP-reputatiescoring). Toch won Bright Data in een vergelijkbare zaak: openbare data die zonder account is gescrapet, valt niet onder X's ToS. Technisch gezien is X in 2026 een van de moeilijkste platforms om te scrapen.
6. Is data scrapen voor AI-modellen legaal?
Dat is de grootste open vraag in 2026. Grote rechtszaken (NYT v. OpenAI, Anthropic's schikking van $1,5 miljard) wijzen op aanzienlijk juridisch risico. De EU AI Act vereist dat bronnen van trainingsdata worden bekendgemaakt en copyright opt-outs worden gerespecteerd. De voorgestelde AI Accountability for Publishers Act zou toestemming en betaling verplicht stellen. Als je scrapt om AI te trainen, vraag dan juridisch advies voordat je doorgaat.
7. Wat is de veiligste manier om webscrapingtools zoals Thunderbit te gebruiken?
Blijf bij het scrapen van openbare data, respecteer sitevoorwaarden, vermijd persoonlijke informatie tenzij je een wettelijke grondslag hebt en gebruik de data intern. Thunderbit is ontworpen om je te helpen compliant te blijven door alleen te scrapen wat zichtbaar is in je browser en je te waarschuwen voor risicovolle sites (thunderbit.com).
8. Kan ik data scrapen voor commercieel gebruik?
Dat hangt ervan af. Gescrapete data gebruiken voor interne analyses of onderzoek is doorgaans veiliger. Gescrapete data herpubliceren of verkopen, vooral als het auteursrechtelijk beschermd of persoonlijk is, is veel riskanter en kan toestemming of een licentie vereisen.
9. Hoe blijf ik op de hoogte van juridische en technische veranderingen in webscraping?
Volg nieuws over techrecht, monitor je doelwebsites op ToS- of beleidswijzigingen en gebruik tools zoals Thunderbit die hun templates en compliancefuncties regelmatig bijwerken. Belangrijke punten om in 2026 op te letten: handhaving van de EU AI Act (augustus), lopende AI-auteursrechtzaken en nieuwe privacywetten in Amerikaanse staten. Bij twijfel: raadpleeg een jurist.
Probeer AI-webscraper Get Started Free




