데이터는 소중한 자산이며, 시스템보다 더 오래 남는다.
- , 월드 와이드 웹 창시자, 컴퓨터 과학자
구글은 매일 의 검색을 처리하고 있습니다. 이 엄청난 숫자는 단순히 궁금증을 해결하는 데 그치지 않고, 시장 트렌드, 경쟁사 동향, 소비자 인사이트 등 비즈니스에 꼭 필요한 방대한 정보를 담고 있죠. 영업, 담당자, 마케터라면 이 데이터를 제대로 활용해 전략을 세울 수 있습니다.
아직도 일일이 복사해서 붙여넣기 하며 데이터 모으고 계신가요? 이제는 더 똑똑하게, 효율적으로 수집할 때입니다.
이 글에서는 Google SERP가 무엇인지, 어떤 데이터가 담겨 있는지, 그리고 구글 검색 결과 추출을 위한 3가지 방법(가장 쉬운 AI 웹 스크래퍼 포함)을 소개합니다.
Google 검색 결과 페이지(SERP)란?
(검색 엔진 결과 페이지)는 , , 등에서 키워드를 입력하면 나오는 결과 화면을 말합니다. 웹사이트로 들어가기 전, 모든 트래픽이 시작되는 첫 관문이죠.
SERP의 가장 큰 특징은 실시간으로 계속 바뀐다는 점입니다. 알고리즘 변화, 새로운 SERP 기능, 키워드 트렌드, 웹사이트 내용 변화 등이 결과에 영향을 줍니다. 또, 검색 기록이나 위치에 따라 개인별로 다른 결과가 보이기 때문에, 같은 시간에 검색해도 각자 다른 SERP를 볼 수 있습니다. 이런 이유로, 비전문가가 이 비정형 데이터를 효율적으로 뽑아내는 건 쉽지 않습니다.
전 세계 검색 엔진 시장의 을 차지하는 구글의 SERP 구조와 활용법을 제대로 아는 것이 비즈니스 성공의 핵심입니다.
Google SERP에는 어떤 데이터가 담겨 있을까?
Google SERP의 구조
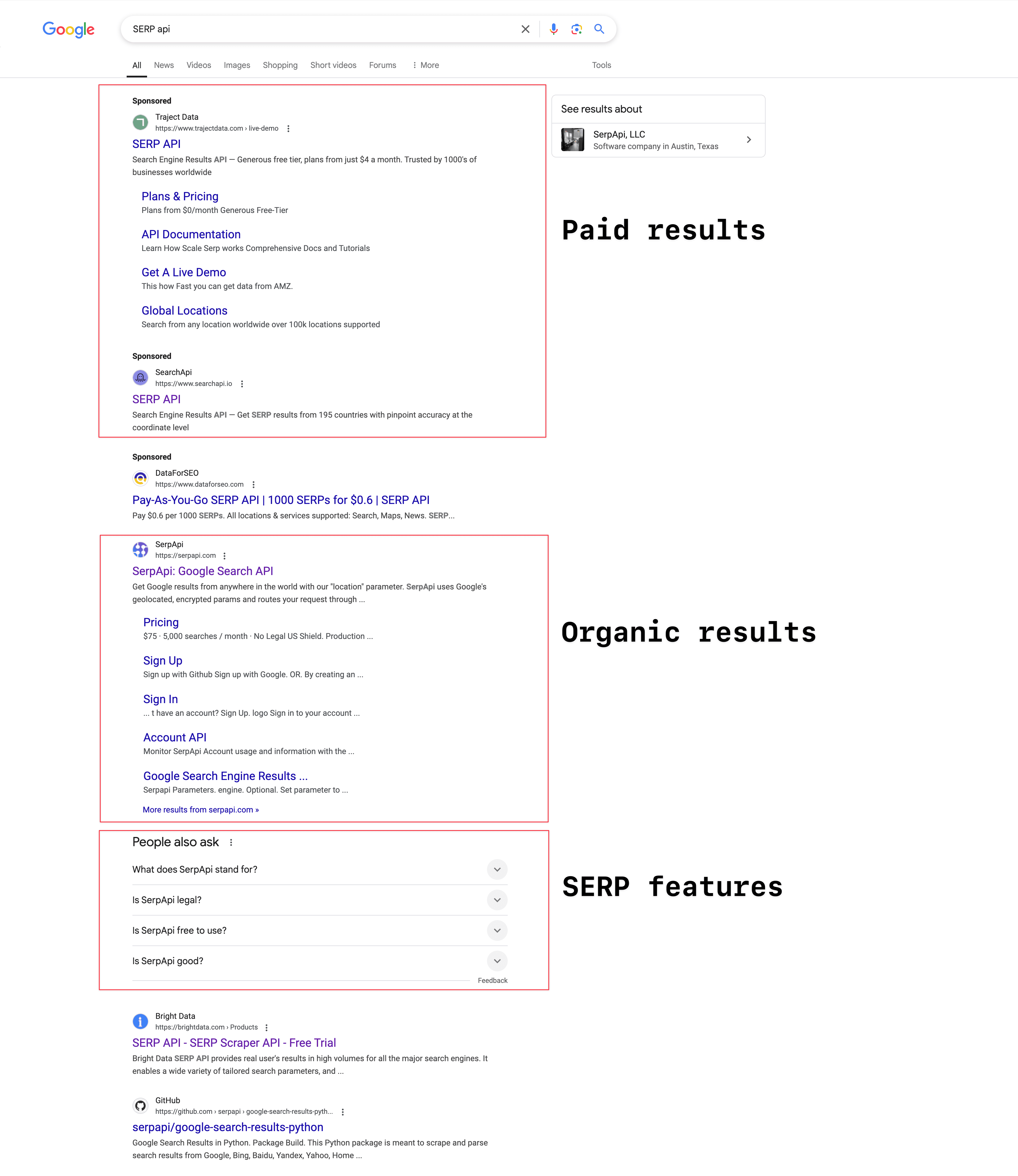
검색어에 따라 SERP의 모습은 달라지지만, 보통 세 가지 주요 영역으로 나뉩니다:
-
유료 광고 영역: "광고" 또는 "스폰서"로 표시된 결과로, 구글에 광고비를 내고 상단이나 하단에 노출되는 영역입니다. 검색어에 따라 광고가 안 보일 수도 있습니다. 2023년 구글 광고 매출은 무려 2,645억 9,000만 달러에 달했습니다().
-
자연 검색 결과: 광고가 아닌, 검색어와의 연관성과 페이지 순위에 따라 노출되는 결과입니다. 각 결과에는 제목, 설명, URL이 포함되어 있습니다.
-
SERP 기능: 구글이 사용자 경험을 높이기 위해 제공하는 다양한 기능입니다. 대표적으로 특성 스니펫, AI 요약, People Also Ask(PAA), 지식 패널, 지역 정보, 동영상, 이미지, 쇼핑 결과 등이 있습니다.
추출 가능한 데이터 종류
SERP 구조를 이해하면, 아래와 같은 다양한 정보를 뽑아낼 수 있습니다:
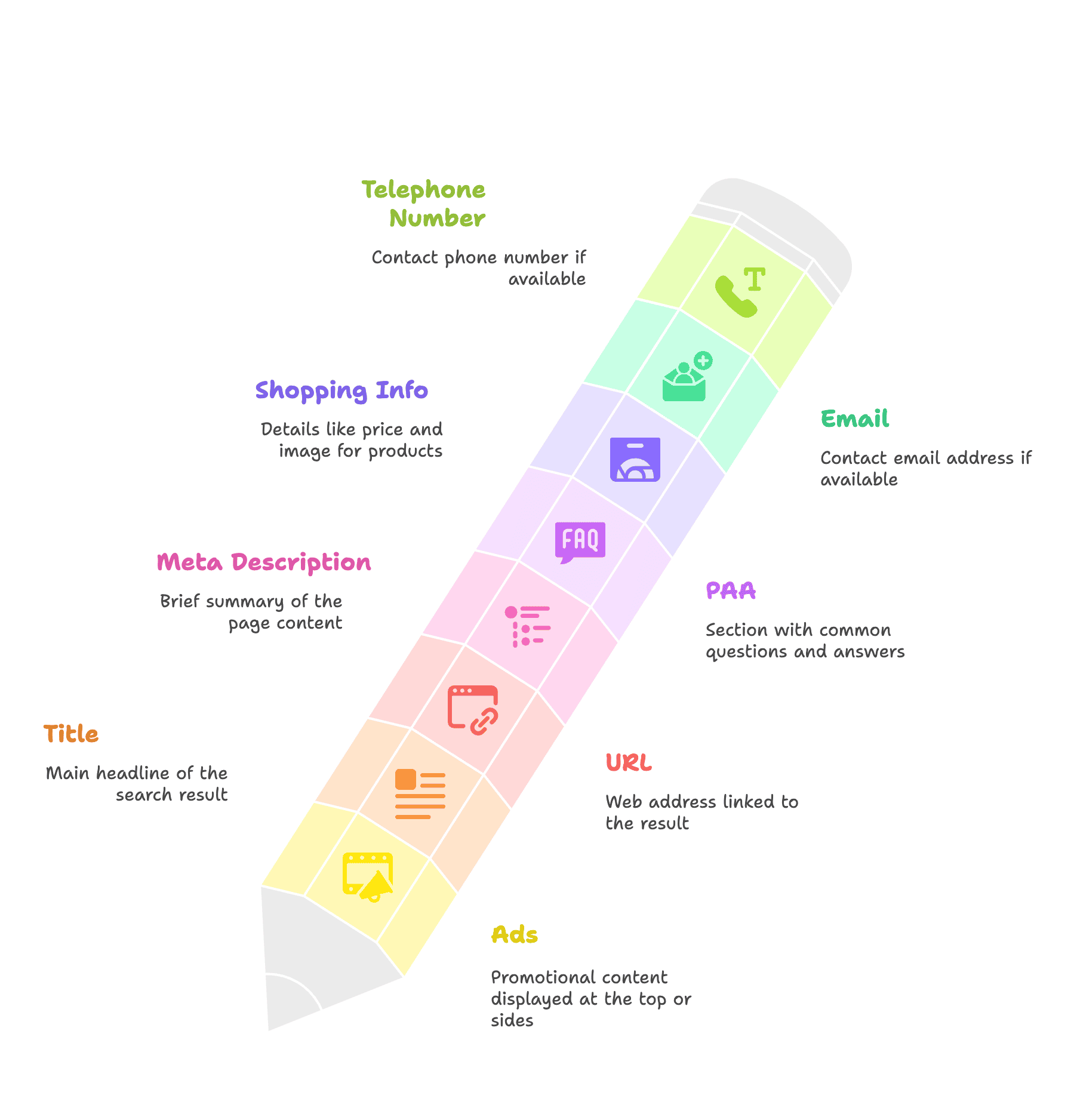
- 광고
- 제목
- URL
- 메타 설명
- PAA(관련 질문) 박스
- 쇼핑 정보(가격, 이미지 등)
- 이메일
- 전화번호
SERP 데이터로 할 수 있는 일
영업 리드 발굴
정확한 검색어만 잘 쓰면, 영업팀은 경쟁사보다 빠르게 잠재 고객을 찾을 수 있습니다. 구글을 활용해 인스타그램 등 소셜 플랫폼에서 이메일, 전화번호 등 고객 연락처를 추출해 영업 기회를 극대화할 수 있죠. 아래에서 인스타그램 리드 추출 방법도 자세히 알려드릴게요.
시장 조사
SERP 데이터는 마케터에게도 큰 무기입니다. 예를 들어, 경쟁사 광고와 상품 정보를 추출해 경쟁사의 전략을 파악하고, 우리 마케팅 전략을 더 똑똑하게 만들 수 있습니다.
또한, SERP는 시장 트렌드를 예측하는 데도 유용합니다. 특정 키워드 검색량이 급증하면 새로운 시장 기회가 생겼다는 신호일 수 있죠. 예를 들어, 의류 매장을 운영하는데 "지속가능 패션" 검색이 늘어난다면, 관련 상품을 추가할 타이밍일 수 있습니다.
SEO 분석
SERP 데이터는 SEO 담당자에게 필수 자료입니다. 키워드 전략을 조정하고, 웹사이트 콘텐츠를 최적화해 검색 순위를 올릴 수 있습니다.
예를 들어, PAA(관련 질문) 데이터를 뽑아 분석하면, 사람들이 궁금해하는 추가 질문을 파악해 웹사이트 콘텐츠를 보완할 수 있습니다.
콘텐츠 분석
기자나 콘텐츠 제작자는 구글 뉴스 결과를 추출해 트렌드와 대중의 관심사를 분석할 수 있습니다. 웹 스크래퍼를 활용한 기사 추출 방법은 별도 가이드에서 확인할 수 있습니다.
Google 검색 결과 페이지 데이터 추출 방법
SERP 데이터를 어떻게 활용할지 알았다면, 이제 실제로 어떻게 모을 수 있을까요?
수작업 복붙은 소량 데이터에는 괜찮지만, 대량 데이터에는 너무 비효율적입니다. 요즘은 AI 등 기술 발전 덕분에 웹 스크래퍼를 활용해 대규모 데이터를 자동으로 수집할 수 있습니다. 대표적인 3가지 방법을 소개합니다.
Thunderbit AI 웹 스크래퍼 활용법
은 코딩 없이 누구나 쓸 수 있는 AI 웹 스크래퍼입니다. 을 활용하거나, 원하는 컬럼을 직접 설정할 수도 있죠. 여기서는 영업 리드 발굴 예시로, Thunderbit로 잠재 고객을 찾는 과정을 단계별로 안내합니다.
-
1단계: Chrome 확장 프로그램에 Thunderbit을 추가하고, Google 계정이나 이메일로 로그인합니다.
-
2단계: 검색어 입력
검색 결과를 더 정확하게 좁히고 싶다면 를 활용해보세요.
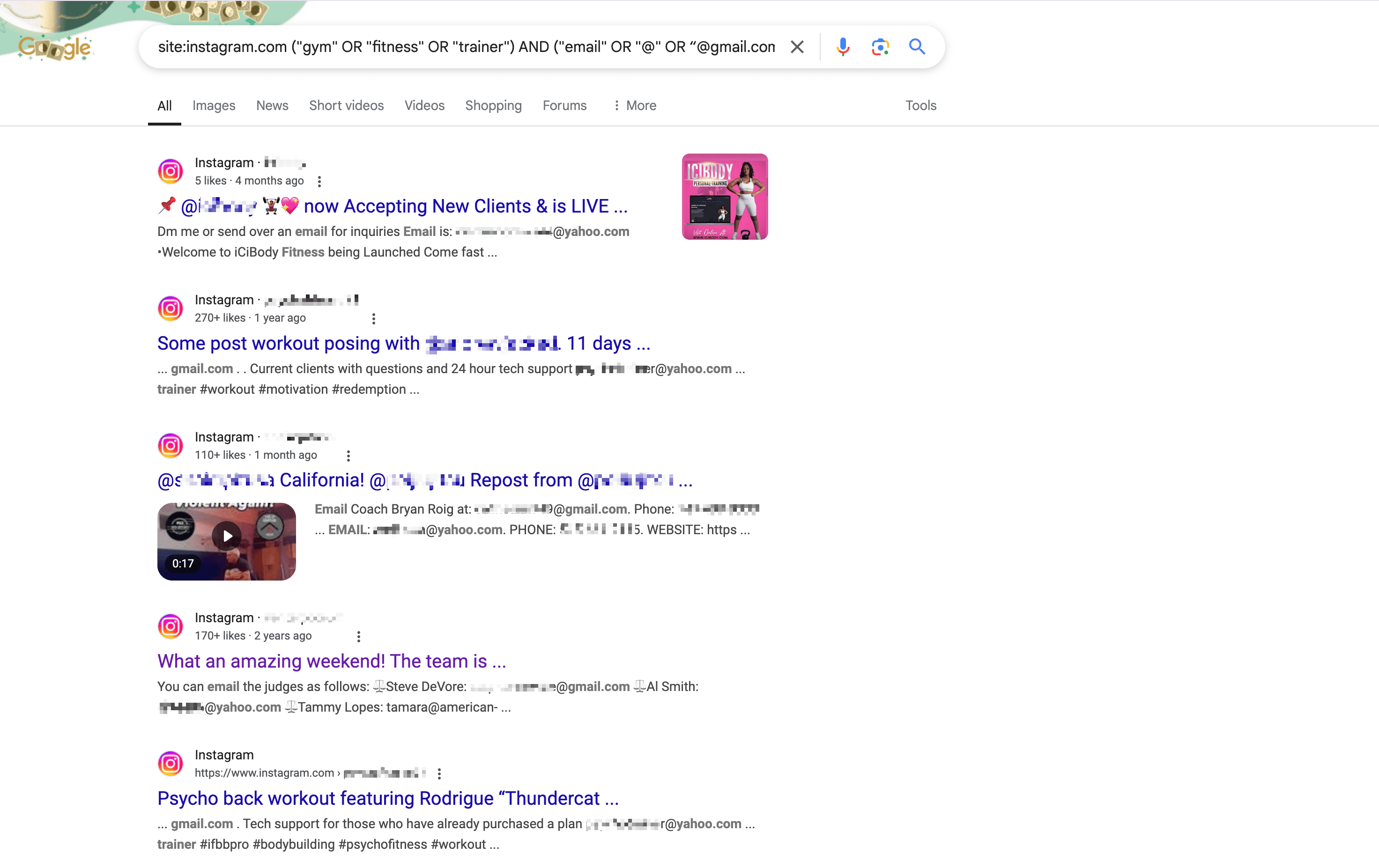
예를 들어, 가 만들어준 아래 검색어는 LA 지역 헬스장 관련 인스타그램 계정의 이메일을 찾는 쿼리입니다:
1site:instagram.com ("gym" OR "fitness" OR "trainer") AND ("email" OR "@" OR “@gmail.com“ or ”@yahoo.com“ ) AND ("Los Angeles" OR "LA" OR "California")구글에 검색어를 입력하고 Enter를 누르면, 원하는 정보가 담긴 결과가 쭉 나옵니다.
-
3단계: Thunderbit 실행 후 데이터 추출
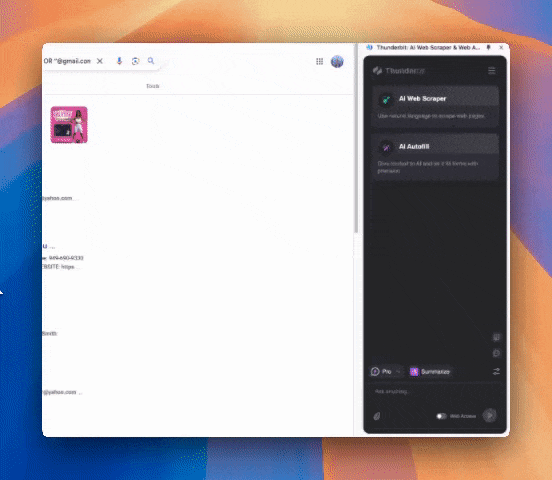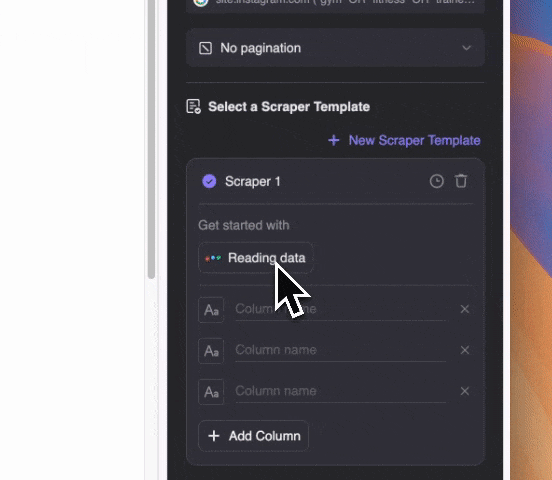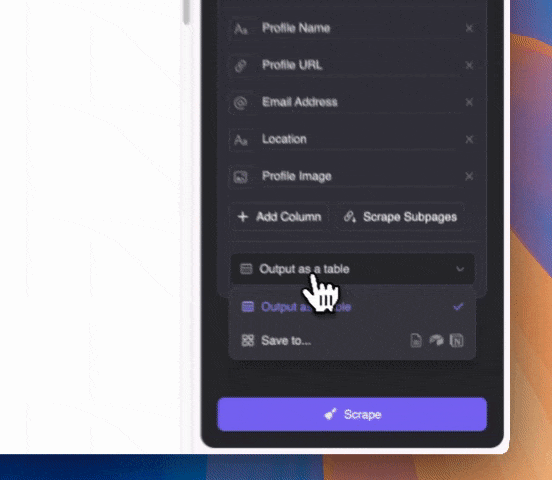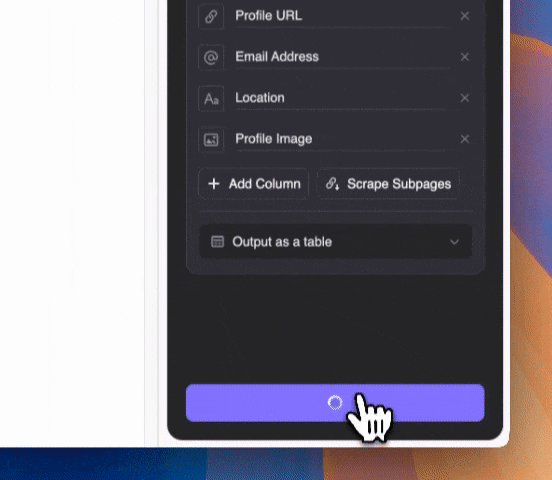 추출하고 싶은 내용을 자연어로 입력하세요(더 세부적으로 지정하려면 "컬럼 상세 설명 추가"를 클릭). 추출 결과는 표, Notion, Airtable, Google Sheets 등으로 바로 내보낼 수 있습니다.
추출하고 싶은 내용을 자연어로 입력하세요(더 세부적으로 지정하려면 "컬럼 상세 설명 추가"를 클릭). 추출 결과는 표, Notion, Airtable, Google Sheets 등으로 바로 내보낼 수 있습니다.Thunderbit은 AI를 활용해, 구글 SERP의 스니펫에 이메일이 다른 텍스트와 섞여 있어도 정확하게 이메일만 뽑아줍니다.
"스크랩" 버튼만 누르고 결과를 기다리면 끝!
전통적인 웹 스크래퍼 사용법
전통적인 웹 스크래퍼도 Google SERP 데이터를 대량으로 추출할 수 있습니다. WebScraper.io를 예로 들면:
- Web Scraper 확장 프로그램을 설치한 뒤, Chrome 개발자 도구를 엽니다.
- “새 사이트맵 생성”을 클릭하고 시작 URL에 구글 검색 결과 페이지 주소를 입력합니다.
- 추출할 데이터를 선택자로 지정합니다.
| Selector Name | Type | Selector | Multiple? |
|---|---|---|---|
| name | Text | 사용자의 이름 선택 | No ❌ |
| profile | Text | 이 페이지의 메타 설명 선택 | No ❌ |
-
스크래퍼를 실행해 데이터를 추출하고, 결과를 내보냅니다.
-
추출한 프로필에서 이메일만 뽑으려면 Excel에서 정규식 함수를 사용해야 합니다:
1text=REGEXEXTRACT(A2,"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}")(A2 셀에 프로필 텍스트가 있다고 가정)
이 방법으로 원하는 이메일 주소만 뽑아낼 수 있습니다.
이 방법의 단점은 웹 구조에 대한 이해가 필요하고, 웹사이트 구조가 조금만 바뀌어도(하루 만에 바뀔 수도 있음) 선택자를 다시 설정해야 한다는 점입니다.
Google 공식 API 또는 서드파티 SERP API 활용
구글은 라는 공식 API를 제공합니다. 이를 통해 프로그래밍 방식으로 검색 결과를 받아올 수 있습니다. 을 만들고, API 키를 받아 Python requests 라이브러리로 요청을 보내면 됩니다. 다만, 제공되는 데이터만 받을 수 있고, 사용량 제한이 엄격합니다. 맞춤형 데이터가 필요하다면 적합하지 않을 수 있습니다.
더 일반적인 방법은 Zen SERP, SerpApi, ScrapingBee 등 서드파티 SERP 스크래퍼 API를 활용하는 것입니다. 이 역시 복잡한 설정과 요청 과정이 필요하며, 설치 후에는 인스타그램 프로필 URL을 모두 수집하고, 각 프로필의 bio에서 이메일을 추출하는 코드를 작성해야 합니다. 코딩 경험이 없는 비즈니스 사용자에게는 진입장벽이 높을 수 있습니다.
1import requests
2from bs4 import BeautifulSoup
3import re
4# SerpApi credentials
5SERP_API_KEY = "your_serpapi_key"
6SEARCH_QUERY = "marketing consultant site:instagram.com"
7# Step 1: Fetch Instagram profile URLs from SerpApi
8def get_instagram_profiles(query):
9 url = "https://serpapi.com/search"
10 params = {
11 "engine": "google",
12 "q": query,
13 "api_key": SERP_API_KEY
14 }
15 response = requests.get(url, params=params)
16 data = response.json()
17 profile_urls = []
18 for result in data.get("organic_results", []):
19 link = result.get("link")
20 if "instagram.com" in link:
21 profile_urls.append(link)
22 return profile_urls
23# Step 2: Extract email from Instagram bio section
24def extract_email_from_bio(profile_url):
25 headers = {"User-Agent": "Mozilla/5.0"}
26 response = requests.get(profile_url, headers=headers)
27 if response.status_code != 200:
28 return None
29 soup = BeautifulSoup(response.text, "html.parser")
30 bio_section = soup.find("meta", attrs={"name": "description"})
31 if bio_section:
32 bio_content = bio_section.get("content", "")
33 emails = re.findall(r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}", bio_content)
34 return emails if emails else None
35 return None
36# Example usage
37if __name__ == "__main__":
38 profiles = get_instagram_profiles(SEARCH_QUERY)
39 print("Found Instagram Profiles:", profiles)
40 for profile in profiles:
41 emails = extract_email_from_bio(profile)
42 if emails:
43 print(f"Emails found in \{profile\}: \{emails\}")
44 else:
45 print(f"No email found in \{profile\}")3가지 방법 비교
비전문가도 쉽고 빠르게 데이터를 추출하고 싶다면? → 추천
데이터 필드를 세밀하게 제어하고, HTML/CSS 지식이 있다면? → 전통적인 웹 스크래퍼 사용
수백만 건의 데이터를 저렴하게, 기술 전문가와 함께 활용하고 싶다면? → 서드파티 SERP API 활용
구글 스크래퍼, 합법일까?
웹 스크래핑의 합법성은 많은 분들이 궁금해하는 부분입니다. ? 정답은 상황에 따라 다릅니다. 국가별 법률, 스크래핑 목적, 서비스 약관, 추출 데이터의 성격에 따라 달라지기 때문입니다.
구글의 에서는 자동화된 방식으로 서비스에 접근하는 것을 금지하고 있습니다. 하지만, 는 것이 법적 해석입니다. 상업적/비영리적 목적에 따라 합법성도 달라질 수 있습니다.
윤리적이고 합법적으로 스크래핑하려면, 서비스 약관을 꼼꼼히 확인하고, 공개된 데이터만 추출하며, 불법적인 용도로 사용하지 않는 것이 중요합니다. 대규모 스크래핑을 계획한다면, 법률 전문가의 자문을 받는 것도 추천합니다.
마무리
데이터는 “”이며, Google SERP는 아직 활용되지 않은 금광입니다. SERP 데이터를 빠르게 전략으로 전환하는 기업이 시장에서 앞서 나갈 수 있습니다. 리드 발굴, 시장 조사, 검색 엔진 최적화 등 다양한 분야에서 SERP 데이터가 활용됩니다.
기술 수준, 예산, 데이터 규모, 활용 목적에 따라 AI 웹 스크래퍼 Thunderbit, 전통적 웹 스크래퍼, SERP API 등 다양한 방법을 소개했습니다.
비즈니스 실무자가 클릭 한 번으로 모든 결과를 추출하고 싶다면, Thunderbit이 최고의 선택입니다. 지금 바로 .
FAQ
1. Google 검색 결과 페이지(SERP)에서 어떤 데이터를 추출할 수 있나요?
제목, URL, 메타 설명, 광고, 특성 스니펫, 쇼핑 정보(가격, 이미지), People Also Ask(관련 질문), 이메일, 전화번호 등 다양한 데이터를 추출할 수 있습니다.
2. Thunderbit은 기존 웹 스크래퍼나 SERP API와 어떻게 다른가요?
은 코딩이나 복잡한 설정 없이, 자연어로 원하는 데이터를 입력하면 AI가 구조화된 데이터를 추출해주는 크롬 확장 프로그램입니다. 기존 스크래퍼는 기술적 설정이 필요하고, API는 코딩과 데이터 제한이 있습니다.
3. Thunderbit으로 구글 검색 결과를 추출하려면 기술 지식이 필요한가요?
아니요. Thunderbit은 비전문가도 쉽게 사용할 수 있도록 설계되었습니다. 원하는 데이터를 평범한 문장으로 입력하면 AI가 알아서 추출해줍니다.
4. 추출한 데이터를 Google Sheets나 Notion 등으로 내보낼 수 있나요?
네. Thunderbit은 Google Sheets, Airtable, Notion 등으로 바로 내보내거나, 표로 다운로드할 수 있어 데이터 활용이 매우 편리합니다.
5. Google SERP 데이터를 추출하는 실질적인 활용 사례는?
대표적으로 리드 발굴, 경쟁사 분석, SEO 분석, 트렌드 파악, 콘텐츠 기획 등에 활용됩니다. 예를 들어, 영업팀은 연락처를 찾고, 마케터는 광고 위치를 분석하며, SEO 담당자는 키워드 성과와 관련 질문을 추적할 수 있습니다.