브라우저 자동화를 한 번이라도 시도해봤다면—예를 들어 상품 목록을 긁어오거나, 결제 과정을 테스트하거나, 반복되는 복붙 작업에서 벗어나고 싶었다면—아마도 Playwright와 Puppeteer 중 뭘 써야 할지 고민해본 적이 있을 거예요. SaaS와 자동화 업계에서 오래 일해온 입장에서 보면, 이 둘을 고르는 건 마치 배트맨이냐 아이언맨이냐를 고르는 것과 비슷합니다. 둘 다 엄청난 능력을 갖췄고, 각자만의 매력이 있으며, 어떤 상황에서는 완벽하게 문제를 해결해주기도 하고, 때로는 스크립트를 망가뜨리기도 하죠.
요즘 브라우저 자동화 시장은 정말 빠르게 변하고 있습니다. 데이터 수집, 업무 자동화, 스마트 시스템 구축 등 다양한 분야에서 자동화가 활발하게 이뤄지고 있고, 같은 AI 기반 도구가 등장하면서 개발자가 아니어도 누구나 쉽게 자동화에 도전할 수 있게 됐어요. 그렇다면 내 상황엔 어떤 도구가 더 잘 맞을까요? 마케팅 용어는 빼고, 실제 차이점과 공통점, 그리고 요즘 뜨는 노코드 대안까지 깔끔하게 정리해볼게요.
Playwright와 Puppeteer란? 왜 중요한가?
먼저 기본부터 짚고 넘어가죠. Puppeteer는 구글에서 만든 오픈소스 Node.js 라이브러리로, Chrome이나 Chromium 브라우저를 자동으로 조작할 수 있게 해줍니다. 사람이 직접 클릭하고, 스크롤하고, 입력하고, 데이터를 뽑아내는 것처럼 동작하지만, 훨씬 더 꼼꼼하고 실수도 적죠. 2017년 출시 이후, 동적이고 자바스크립트가 많은 웹사이트를 크롤링할 때 가장 많이 쓰이는 도구가 됐습니다 ().
Playwright는 Microsoft에서 내놓은 Puppeteer의 라이벌입니다. 2020년, Puppeteer 개발자들이 대거 합류해 만든 Playwright는 크롬뿐 아니라 파이어폭스, 사파리(WebKit)까지 지원하고, 여러 프로그래밍 언어도 쓸 수 있어요 (). 쉽게 말해, Playwright는 Puppeteer의 업그레이드 버전이자, 더 많은 브라우저와 언어를 지원하는 다재다능한 동생 같은 느낌입니다.
이 도구들이 왜 중요할까요? 요즘 웹사이트는 자바스크립트, 무한 스크롤, 다양한 인터랙션 등으로 점점 복잡해지고 있습니다. 기존 방식의 크롤러로는 제대로 데이터를 뽑아내기 힘들죠. 영업, 마케팅, 이커머스, 운영팀 등 다양한 부서에서 신뢰할 수 있는 데이터 추출과 웹 자동화가 필수가 되면서, Playwright와 Puppeteer가 점점 더 주목받고 있습니다.
공통점: Playwright와 Puppeteer의 자동화 기능
경쟁 구도이긴 하지만, 두 도구는 공통점도 많아요:
- 자바스크립트 기반: 둘 다 주로 JavaScript/TypeScript로 개발합니다(Playwright는 더 다양한 언어 지원, 아래에서 설명).
- 브라우저 자동화: 코드로 브라우저를 열고, 클릭하고, 폼을 입력하고, 스크린샷을 찍는 등 다양한 작업을 자동화할 수 있습니다.
- 동적 콘텐츠 처리: 자바스크립트가 많은 최신 웹사이트도 문제없이 렌더링하고 상호작용할 수 있습니다.
- 사용자 행동 시뮬레이션: 로그인, 스크롤, '더 보기' 클릭 등 실제 사용자의 행동을 그대로 흉내낼 수 있습니다.
- 헤드리스/헤드풀 모드: 서버에서 보이지 않게 실행(헤드리스)하거나, 실제 브라우저 화면을 보면서 실행(헤드풀)할 수 있습니다.
- 스크립트 실행: 페이지 내에서 직접 자바스크립트를 실행해 원하는 데이터를 추출할 수 있습니다.
- 네트워크 제어: 요청 가로채기, 디바이스/위치 에뮬레이션 등도 가능합니다. 지역별/모바일 데이터 수집에 유용하죠.
즉, 둘 다 브라우저 자동화의 만능툴입니다. 동적 웹사이트에서 구조화된 데이터를 추출하고 싶다면, 코딩에 익숙하다면 어느 쪽이든 원하는 결과를 얻을 수 있습니다.
차이점: Playwright와 Puppeteer의 크롤링 및 테스트 비교
이제 두 도구의 차이점을 살펴볼게요:
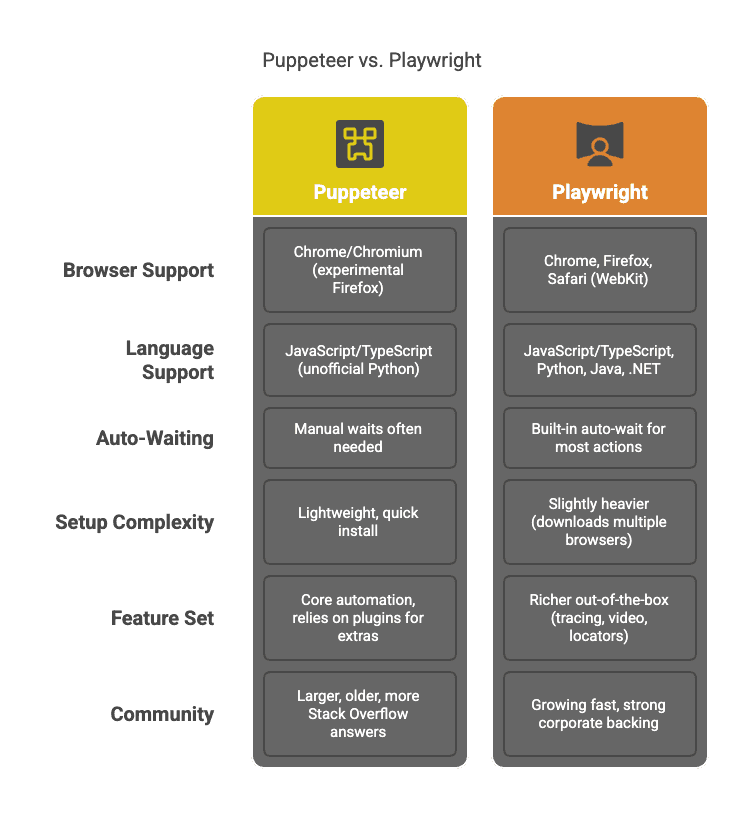
주요 포인트만 정리하면:
- 브라우저 지원: Puppeteer는 크롬 중심입니다. Playwright는 크롬, 파이어폭스, 사파리를 하나의 API로 모두 제어할 수 있어요 (). 여러 브라우저에서 테스트하거나, 탐지 우회를 위해 다양한 브라우저가 필요하다면 Playwright가 유리합니다.
- 언어 지원: Puppeteer는 Node.js(자바스크립트) 전용. Playwright는 Python, Java, .NET 등 다양한 언어를 지원합니다 ().
- 자동 대기: Playwright는 요소가 준비될 때까지 자동으로 기다려줍니다. 일일이
waitForSelector를 넣지 않아도 돼서, 동적 사이트에 특히 강력합니다 (). Puppeteer는 수동으로 대기 코드를 넣어야 하므로, 실수할 여지가 더 많아요. - 기능 세트: Playwright는 네트워크 가로채기, 내장 테스트 러너, 트레이싱 등 다양한 기능이 기본 탑재되어 있습니다. Puppeteer는 더 단순하지만, 고급 기능은 플러그인이나 추가 코드가 필요합니다.
- 커뮤니티: Puppeteer가 더 오래되어 자료가 많고, Playwright는 빠르게 커뮤니티가 성장 중입니다.
Puppeteer가 적합한 경우
Puppeteer는 이런 상황에 잘 맞아요:
- 크롬/크로미움만 필요할 때: 대부분의 크롤링/자동화 작업은 크롬만으로 충분합니다.
- 간단한 설치와 빠른 시작:
npm install한 번이면 바로 시작할 수 있습니다. - 단순함을 선호할 때: API가 직관적이고, 모든 과정을 직접 제어할 수 있습니다.
- 작고 단발성 스크립트: 빠르게 결과를 내야 할 때, Puppeteer의 심플함이 장점입니다.
- Node.js에 익숙한 팀: 자바스크립트 환경에 익숙하다면 Puppeteer가 자연스럽게 느껴집니다.
예시: 한 쇼핑몰에서 상품 가격만 빠르게 수집하거나, 로그인 자동화, CI 파이프라인에서 크롬 기반 테스트를 돌릴 때.
Playwright가 적합한 경우
Playwright는 이런 상황에서 빛을 발합니다:
- 여러 브라우저 지원이 필요할 때: 크롬, 파이어폭스, 사파리까지 한 번에 크롤링/테스트 가능 ().
- 고급 자동화가 필요할 때: 자동 대기, Locator API, 트레이싱 등 복잡한 사이트에 강력합니다.
- Python, Java, .NET 등 다양한 언어를 선호할 때: Node.js에 얽매이지 않습니다.
- 대규모 크롤링: 여러 브라우저 컨텍스트를 효율적으로 관리해, 병렬 크롤링/테스트에 유리합니다.
- 미래지향적 선택: Microsoft와 Puppeteer 원 개발자들의 지원으로 빠르게 발전 중입니다.
예시: 로그인, 팝업 등 여러 단계를 거치는 복잡한 크롤링, 다양한 브라우저에서 웹앱 테스트, 신뢰성과 확장성이 중요한 데이터 파이프라인 구축 등.
공통 한계: Playwright와 Puppeteer의 숨겨진 비용
두 도구 모두 강력하지만, 규모가 커질수록 이런 한계가 있습니다:
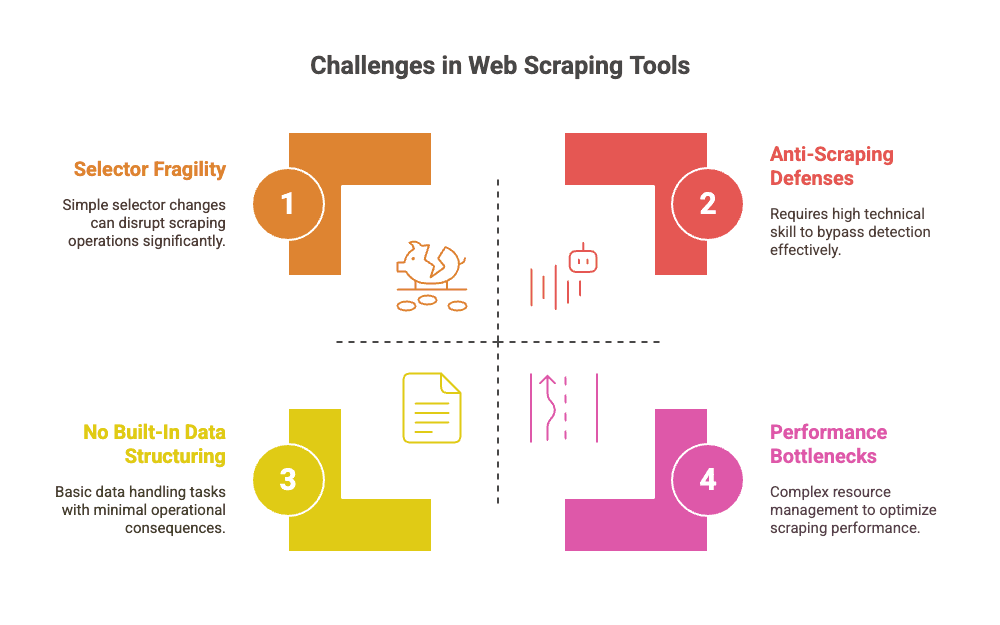
- 셀렉터 취약성: 웹사이트 구조나 CSS 클래스가 조금만 바뀌어도 스크립트가 쉽게 깨집니다 (). 유지보수가 끝없는 두더지잡기 게임이 되죠.
- 수동 유지보수: 개발자들이 셀렉터 수정, 로직 업데이트, 새로운 봇 방지 대응에 많은 시간을 씁니다 ().
- 성능 문제: 실제 브라우저를 돌리다 보니 리소스 소모가 큽니다. 수천~수만 페이지를 크롤링하려면 브라우저 팜, 병렬 처리, 메모리 관리 등 추가 인프라가 필요합니다 ().
- 데이터 구조화 미지원: 추출한 데이터는 가공되지 않은 상태로 제공됩니다. CSV/Excel로 정리하거나 파싱하는 작업은 직접 해야 합니다.
- 안티스크래핑 방어: 기본적으로 탐지 우회 기능이 없습니다. 프록시, 캡차 우회 등은 별도 플러그인이나 커스텀 코드가 필요합니다 ().
- 비개발자에겐 진입장벽: 코딩에 익숙하지 않다면, 두 도구 모두 사용이 쉽지 않습니다.
즉, Playwright와 Puppeteer는 강력하지만, 대규모로 쓸수록 유지보수와 인프라 비용이 커집니다.
Playwright vs Puppeteer 크롤링 실전 비교
예를 들어, 여러 페이지와 상세 링크가 있는 이커머스 사이트에서 상품 데이터를 추출한다고 가정해봅시다.
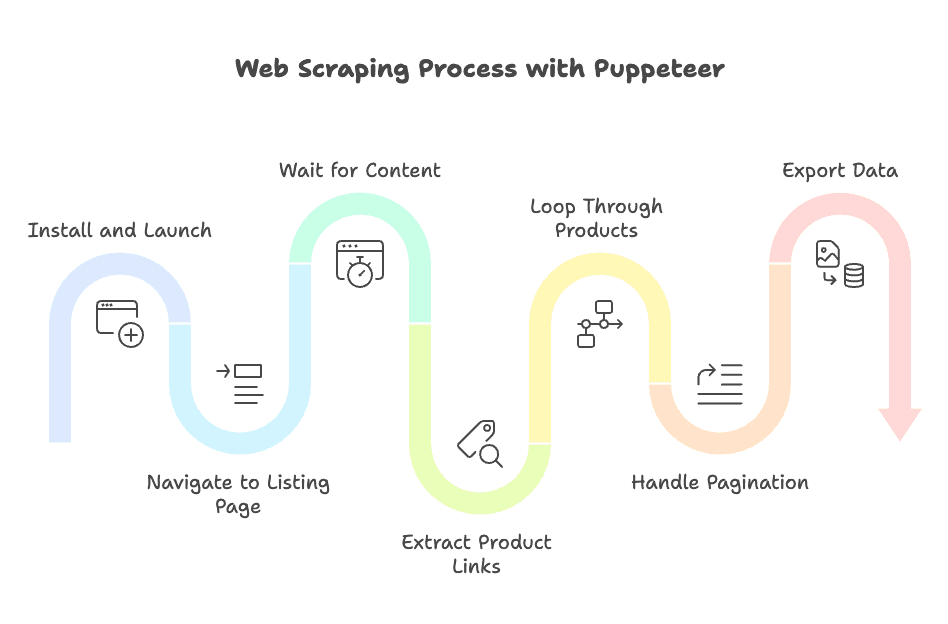
Puppeteer로 할 때
- 설치 및 실행:
npm install puppeteer후, 헤드리스 브라우저 실행 - 목록 페이지 이동:
page.goto()사용 - 콘텐츠 대기:
waitForSelector로 상품이 로드될 때까지 수동 대기 - 상품 링크 추출:
$$eval로 URL 수집 - 상품별 반복: 각 링크마다 새 페이지 열고, 셀렉터 대기, 데이터 추출, 페이지 닫기
- 페이지네이션 처리: '다음' 버튼을 직접 찾아 클릭, 반복
- 데이터 내보내기: CSV/JSON 저장 로직 직접 구현
Playwright로 할 때
- 설치 및 실행:
npm install playwright후, 원하는 브라우저 실행(크롬/파이어폭스/사파리) - 목록 페이지 이동:
page.goto()사용 - 자동 대기: Playwright의 액션(
page.click(),page.textContent()등)은 자동으로 요소가 준비될 때까지 기다림 - 상품 링크 추출: Locator API 또는
$$eval활용 - 상품별 반복: 새 페이지 열거나 재사용, 내장 대기 기능으로 데이터 추출
- 페이지네이션 처리:
page.click('a.next-page')만 입력하면 자동 대기까지 처리 - 데이터 내보내기: 결과 구조화 및 저장은 직접 구현 필요
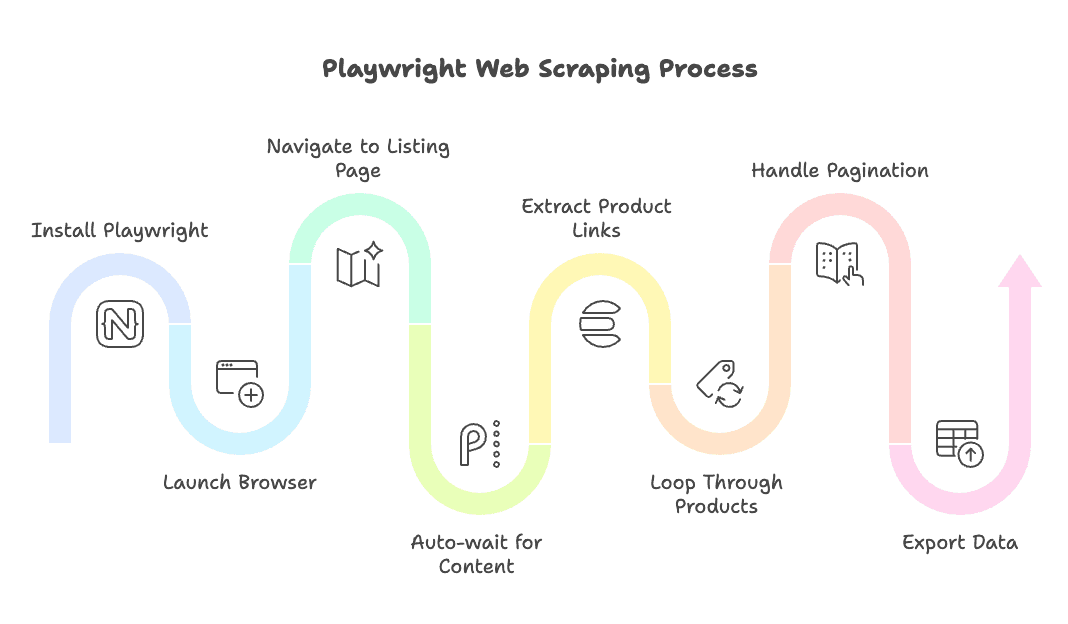
정리: 두 도구 모두 원하는 결과를 얻을 수 있지만, Playwright는 자동 대기와 멀티 브라우저 지원 덕분에 코드가 더 간결하고 오류가 적습니다. Puppeteer는 직접 제어가 가능해 세밀한 작업에 적합합니다.
AI 기반 크롤링의 부상: Thunderbit라는 노코드 대안
많은 비즈니스 사용자들이 가장 많이 하는 말이 있습니다. “그냥 데이터만 받고 싶은데, 왜 자바스크립트를 배워야 하죠? 매주 스크립트 고치는 것도 지겹고요.”
이런 고민을 해결하기 위해 이 탄생했습니다. Thunderbit는 으로, 개발 지식이 없어도 누구나 몇 번의 클릭만으로 웹사이트에서 데이터를 추출할 수 있습니다. 코드도, 셀렉터도, 복잡한 유지보수도 필요 없습니다.
어떻게 동작하나요?
- AI 필드 추천: Thunderbit의 AI가 페이지를 읽고, '상품명', '가격', '평점' 등 추출할 데이터를 자동으로 제안합니다. HTML 구조나 셀렉터를 직접 찾을 필요가 없습니다.
- 자동 상세페이지/페이지네이션 처리: 상세페이지 이동이나 수십 페이지에 걸친 목록도 AI가 알아서 처리합니다 ().
- 다양한 내보내기: 추출 결과를 엑셀, 구글 시트, Airtable, Notion 등으로 한 번에 내보낼 수 있습니다.
- 데이터 구조화 및 가공: Thunderbit는 크롤링과 동시에 요약, 분류, 번역 등 데이터 가공도 지원합니다 ().
- 대량/예약 크롤링: 수백 개 URL을 한 번에 크롤링하거나, 반복 작업을 예약할 수 있습니다. 별도의 서버나 크론 작업이 필요 없습니다.
Thunderbit는 결과 중심의 비즈니스 사용자를 위해 설계되었습니다. 소규모 작업은 무료로 체험할 수 있습니다.
Thunderbit vs Playwright vs Puppeteer: 기능 비교
아래 표에서 각 도구의 특징을 한눈에 비교해보세요:
This paragraph contains content that cannot be parsed and has been skipped.