
몇 년 전만 해도 웹 스크래핑은 후드티 입은 해커나, 모니터를 여섯 대씩 켜 둔 데이터 과학자의 영역이라고 여겨졌어요. 지금은 사정이 완전히 달라졌죠. 웹사이트에서 데이터를 뽑아내는 일이 출근길에 커피 한 잔 사는 것만큼이나 평범한 업무가 됐어요. Python을 배울 필요도, 오전 내내 에스프레소를 들이부을 필요도 없고요. AI 웹 스크래퍼가 널리 퍼지면서, “HTML”을 무슨 샌드위치 이름쯤으로 아는 사람도 웹에서 구조화된 데이터를 문제없이 가져올 수 있게 됐어요.
제품 정보나 영업 리드, 가격표를 스프레드시트에 일일이 복사·붙여넣기 해본 적 있으신가요? 그렇다면 이 글이 딱 맞아요. 지금 약 73%의 기업이 시장 인사이트와 경쟁사 추적을 위해 웹 스크래핑을 쓰고 있어요. 웹 스크래핑 소프트웨어 시장은 2032년까지 24억 9천만 달러(약 3조 4천억 원) 규모로 커질 전망이고요. 웹 데이터 추출은 이제 소수 기술 엘리트만의 무기가 아니에요. 영업이든 마케팅이든, 아니면 그냥 수작업 데이터 입력에서 벗어나고 싶은 분이든, 이 가이드는 여러분을 위한 거예요. 기본 개념부터 전통 방식과 AI 방식의 차이, 실제 시작 방법까지 하나씩 짚어볼게요. 후드티는 안 챙기셔도 돼요.
웹 스크래퍼란: 웹사이트에서 데이터를 스크래핑한다는 게 뭘까요?
기초부터 볼게요. 웹 스크래퍼는 웹사이트에서 데이터를 자동으로 모아 주는 도구(또는 스크립트, Chrome 확장 프로그램)예요. 반복 작업을 아무리 시켜도 불평 한마디 없는 초고속 인턴이라고 생각하면 편해요. 여러분이 한 줄씩 복사·붙여넣기 할 필요 없이 몇 초 만에 다 끝내주고, 커피 브레이크도 안 달라고 하죠.
보통 다루게 되는 데이터는 두 종류예요.
- 구조화된 데이터: 제품명, 가격, 이메일처럼 스프레드시트에 바로 넣을 수 있게 정돈된 데이터예요. 라벨이 붙어 있고 분석하기도 편하죠.
- 비구조화된 데이터: 블로그 글, 리뷰, 이미지처럼 행과 열에 깔끔하게 안 들어맞는 데이터예요. 웹 스크래핑 프로젝트 대부분은 이 비구조화된 데이터를 구조화된 데이터로 바꾸는 게 목적이에요. 그래야 실제로 써먹을 수 있으니까요.
웹사이트의 표를 복사해서 Excel에 붙여넣어 본 적 있다면, 사실 이미 수동 웹 스크래핑을 해본 거예요. 이제 그걸 1만 페이지 분량으로 한다고 상상해 보세요. (진짜로는 하지 마시고요. 그러라고 있는 게 바로 웹 스크래퍼예요.)
왜 웹사이트 데이터를 스크래핑할까요: 비즈니스 관점의 핵심 이유
애초에 데이터를 스크래핑할 이유가 뭘까요? 답은 단순해요. 비즈니스는 데이터로 돌아가고, 웹은 세상에서 가장 큰 데이터베이스니까요. 영업, 마케팅, 이커머스, 부동산 어느 분야든 웹 데이터 추출은 확실한 경쟁 우위가 돼요.
가장 흔한 활용 사례를 정리하면 이래요.
| 활용 사례 | 설명 | 예상 ROI/효과 |
|---|---|---|
| 리드 생성 | 디렉터리나 소셜 사이트에서 연락처 정보, 이메일, 회사 목록 수집 | 영업팀이 시간을 절약하고 더 적합한 리드를 찾음 |
| 가격 모니터링 | 경쟁사 가격, 재고, 프로모션을 실시간 추적 | 소매업체가 가격을 동적으로 조정해 매출 4% 증가 |
| 시장 조사 | 리뷰, 뉴스, 소셜 반응을 모아 트렌드 파악 | 마케터가 실시간 소비자 인사이트에 맞춰 캠페인 조정 |
| 경쟁사 분석 | 경쟁사 제품 카탈로그, 출시, 콘텐츠 모니터링 | 기업이 시장 변화에 더 빠르게 대응 |
| 부동산 인텔리전스 | 매물, 가격, 가용성 스크래핑 | 에이전트와 투자자가 시장보다 먼저 기회를 포착 |
실제로 영국과 유럽의 소매업체 25~30%가 경쟁사 가격을 스크래핑해 동적 가격 전략을 운영하고 있어요. John Lewis, ASOS 같은 기업도 웹 데이터를 근거로 더 똑똑한 의사결정을 내리면서 눈에 띄는 매출 상승을 거뒀고요.
전통적인 웹 스크래퍼 도구는 어떻게 작동할까요?
AI가 본격적으로 등장하기 전, “정석” 방식의 데이터 스크래핑을 짚고 넘어갈게요. 전통적인 웹 스크래퍼는 보통 Python으로 짠 스크립트나 브라우저 확장 프로그램이에요. 정해진 규칙대로 움직이면서 원하는 데이터를 가져오죠.
과정은 대개 이렇게 흘러가요.
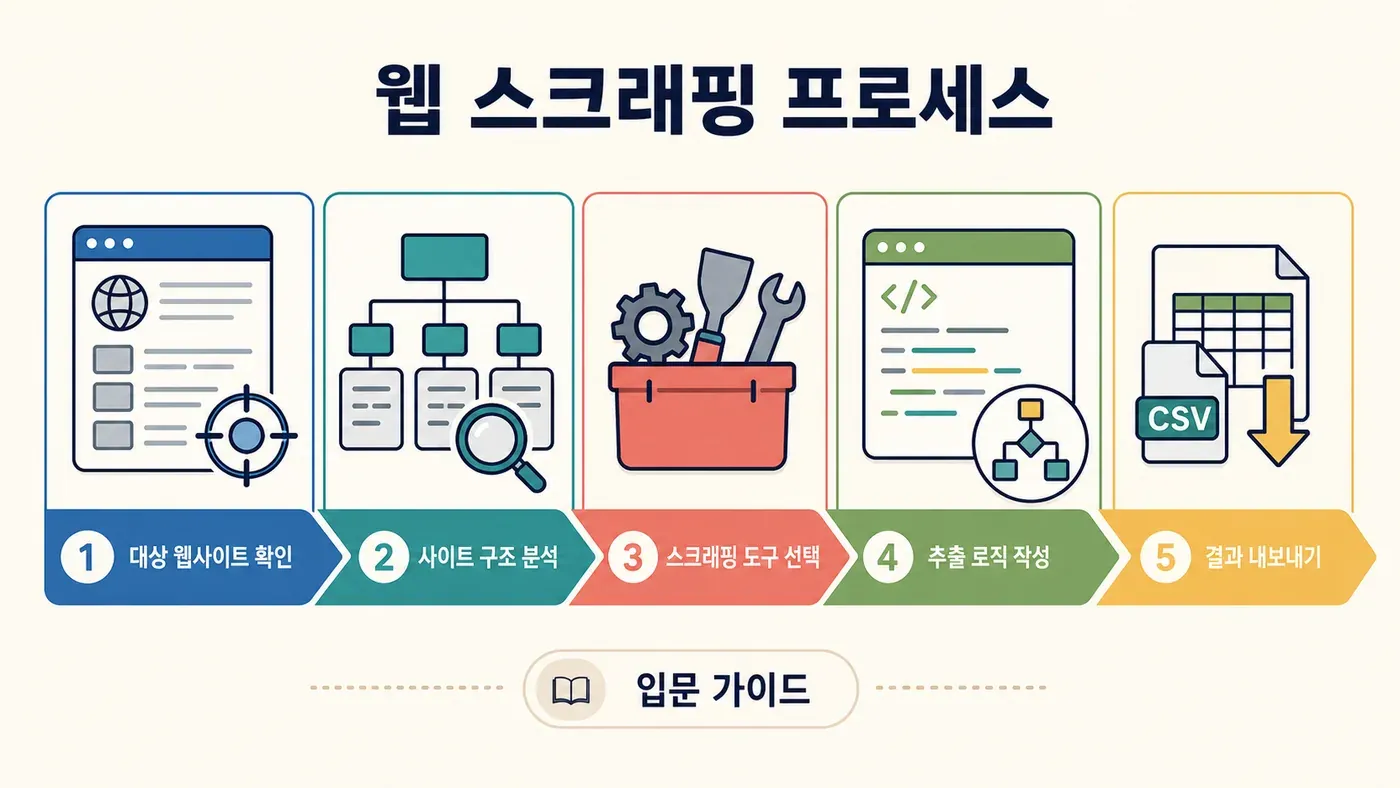
- 대상 웹사이트와 데이터 필드를 정해요.
- 웹사이트 구조를 분석해요. (브라우저 개발자 도구로 HTML을 뜯어보는 단계예요. 디지털 고고학에 가깝죠.)
- 도구를 골라요. 대표적으로 BeautifulSoup, Scrapy, 아니면 브라우저 플러그인이 있어요.
- 추출 로직을 작성해요. CSS 선택자나 XPath를 지정해서 도구가 데이터를 어떻게 찾을지 알려줘요.
- 스크래퍼를 실행해요. 여러 페이지에서 데이터가 수집되는 걸 지켜보세요.
- 결과를 내보내요. 보통 CSV, JSON, Excel로 바로 뽑아요.
실습으로 보기: 전통적인 웹 스크래퍼로 데이터 추출하기
이커머스 사이트에서 제품 목록을 스크래핑한다고 해볼게요. 처음 하는 분도 따라올 수 있게 풀어볼게요.
- STEP 1: Python과 BeautifulSoup 라이브러리를 설치해요.
- STEP 2: 브라우저로 제품 페이지를 검사해요. 제품명과 가격이 담긴 HTML 태그를 찾아요.
- STEP 3: 페이지를 가져와서 HTML을 파싱하고, 필요한 필드를 뽑아내는 짧은 스크립트를 작성해요.
- STEP 4: 여러 페이지를 순회해요(페이지네이션 처리).
- STEP 5: 데이터를 CSV 파일로 내보내요.
말은 쉬워 보이죠. 하지만 첫 스크립트는 한 번쯤은 반드시 깨진다고 보시면 돼요. (저도 첫 시도 때 클래스 이름을 잘못 적어서 “None”만 500줄을 긁어왔거든요. 아차 싶었죠.)
전통적인 웹 스크래퍼가 부딪히는 흔한 벽
여기서부터 슬슬 까다로워져요.
- 웹사이트 변경: 사이트 레이아웃이 아주 조금만 바뀌어도 스크래퍼가 깨질 수 있어요. 스크래퍼의 10~15%가 매주 이런 변경 탓에 고장 난다고 해요.
- 안티봇 대응: CAPTCHA, IP 차단, 요청 제한에 걸리면 아예 길이 막혀요. 프록시, 지연 시간, 때로는 CAPTCHA 우회까지 직접 감당해야 하죠.
- 필요한 기술: 코딩과 HTML/CSS를 어느 정도는 알아야 해요.
- 유지보수: 스크래퍼는 계속 손봐주고 업데이트해야 해요.
- 지저분한 데이터: 형식이 들쭉날쭉하거나 값이 비었거나 인코딩이 깨진 데이터를 정리하는 데 시간이 들어요.
처음 하는 분에게는, 레시피가 자꾸 바뀌고 가끔 오븐이 문까지 잠가버리는 상황에서 케이크를 굽는 기분일 거예요.
AI 웹 스크래퍼의 등장: 데이터 추출을 누구나 쉽게
AI를 사용해 어떤 웹사이트든 데이터 추출 Get Started Free
여기서부터가 재밌는 부분이에요. AI 웹 스크래퍼가 판을 뒤집고 있거든요. 코드를 짜거나 선택자를 붙들고 씨름할 필요 없이, 원하는 걸 그냥 평범한 말로 설명하면 나머지는 AI가 알아서 처리해요.
Thunderbit(네, 저희예요!)이 바로 이 새로운 세대를 대표하는 도구예요. Thunderbit를 쓰면 자연어만으로 어떤 웹사이트에서든 구조화된 데이터를 추출할 수 있어요. 코딩은 필요 없고요. 영업이든 마케팅이든 이커머스든, 며칠이 아니라 몇 분이면 필요한 데이터를 모을 수 있어요.
Thunderbit AI 웹 스크래퍼는 데이터 추출을 어떻게 단순하게 만들까요?
Thunderbit가 일을 어떻게 덜어주는지 보여드릴게요.
- AI 필드 추천: “AI 필드 추천”만 눌러도 Thunderbit가 웹사이트를 읽고 열 이름을 제안하고, 각 필드를 어떻게 추출할지까지 알려줘요.
- 하위 페이지 스크래핑: 더 상세한 정보가 필요한가요? Thunderbit는 개별 제품 페이지 같은 하위 페이지까지 방문해서 데이터 표를 자동으로 채워줘요.
- 바로 쓰는 템플릿: Amazon, Zillow처럼 인기 있는 사이트는 미리 만들어진 템플릿을 그대로 쓸 수 있어요. 따로 설정할 게 없죠.
- 무료 데이터 내보내기: Excel, Google Sheets, Airtable, Notion으로 내보내고 CSV나 JSON으로도 받을 수 있어요. 숨은 비용도 없고요.
- 예약 스크래핑: 정해진 주기로 스크래핑을 돌려서 데이터를 늘 최신으로 유지하세요. 가격 모니터링이나 리드 업데이트에 특히 잘 맞아요.
- AI 자동 입력: AI가 온라인 폼을 대신 채워줘요. 10페이지짜리 공급업체 온보딩 폼도 문제없어요.
- 이메일·전화번호·이미지 추출기: 연락처 정보나 이미지를 한 번에 가져올 수 있어요.
무엇보다 코드를 전혀 몰라도 된다는 게 가장 큰 장점이에요. Thunderbit Chrome 확장 프로그램은 여기에서 받을 수 있고, 공식 웹사이트에서 더 자세히 살펴볼 수 있어요.
Thunderbit AI 웹 스크래퍼를 무료로 사용해 보세요
전통적인 웹 스크래퍼 vs. AI 웹 스크래퍼
두 방식이 어떻게 다른지 한눈에 비교해 볼게요.
| 항목 | 전통적인 웹 스크래퍼 | AI 웹 스크래퍼(Thunderbit) |
|---|---|---|
| 사용 편의성 | 코딩 또는 복잡한 설정 필요 | 노코드, 자연어 인터페이스 |
| 적응성 | 사이트 변경에 쉽게 깨짐 | AI가 레이아웃 변경에 자동 적응 |
| 유지보수 | 높음 — 자주 업데이트 필요 | 낮음 — 대부분의 변경을 AI가 처리 |
| 기술 역량 | 프로그래밍과 HTML 지식 필요 | 비즈니스 사용자용으로 설계됨 |
| 설정 속도 | 몇 시간에서 며칠 | 몇 분 |
| 데이터 처리 | 수동 정리 필요 | AI가 데이터를 자동으로 정리하고 구조화 |
| 비용 | 무료(오픈 소스)이지만 시간 투입 큼 | 합리적인 요금제, 무료 내보내기 옵션 |
대부분의 비즈니스 사용자, 특히 초보자라면 속도·단순함·안정성 어느 쪽으로 봐도 Thunderbit 같은 AI 웹 스크래퍼가 확실히 앞서요. 물론 아주 정교한 맞춤 작업이나 대규모 프로젝트에서는 전통적인 도구가 여전히 제 역할을 하지만, 실무 사례의 95%는 AI로 충분해요.
초보자용 단계별 가이드: 웹사이트 데이터를 스크래핑하는 방법

STEP 1: 데이터 추출 목표를 정하세요
시작 전에 무엇이 필요한지부터 분명히 해두세요. 스스로 이렇게 물어보면 좋아요.
- 어떤 웹사이트를 스크래핑하려고 하나요?
- 어떤 데이터 필드가 중요한가요? (예: 제품명, 가격, 이메일, 전화번호)
- 이 데이터가 얼마나 자주 필요한가요? (한 번뿐인가요, 반복인가요?)
간단한 체크리스트로 적어두면 좋아요. 예를 들면 “XYZ.com의 첫 5페이지에서 제품명, 가격, 평점을 모은다” 정도로요.
STEP 2: 알맞은 웹 스크래퍼 도구를 고르세요
판단 기준은 간단해요.
- 코딩이 익숙하고 세밀한 통제가 필요하다면? BeautifulSoup이나 Scrapy 같은 전통적인 도구를 써보세요.
- 속도와 편의성, 노코드가 우선이라면? Thunderbit 같은 AI 웹 스크래퍼를 쓰세요.
고민된다면 일단 AI로 시작하세요. 더 깊이 파고드는 건 나중에 해도 늦지 않아요.
STEP 3: 데이터 추출을 설정하고 실행하세요
전통적인 방식
- 도구 설치: Python과 필요한 라이브러리를 설정해요.
- 웹사이트 점검: 브라우저 DevTools로 HTML 구조를 파악해요.
- 스크립트 작성: 각 데이터 필드를 어떻게 찾고 뽑을지 정의해요.
- 한 페이지에서 테스트: 원하는 데이터가 나오는지 확인해요.
- 확장: 더 많은 페이지를 처리하도록 페이지네이션이나 루프를 추가해요.
- 데이터 내보내기: CSV나 JSON으로 저장해요.
AI 방식(Thunderbit)
- Thunderbit Chrome 확장 프로그램 설치: 여기서 받으세요.
- 대상 웹사이트 열기: 스크래핑할 페이지로 이동해요.
- “AI 필드 추천” 클릭: Thunderbit가 페이지를 읽고 열을 추천해요.
- 미리보기 확인: 데이터가 제대로 잡혔는지 보고, 필요하면 열을 손봐요.
- “스크래핑” 클릭: Thunderbit가 데이터를 대신 모아줘요.
- 데이터 내보내기: Excel, Google Sheets, Airtable, Notion으로 받아요.
시각적인 안내가 필요하면 Thunderbit YouTube 채널을 참고해 보세요.
STEP 4: 데이터를 내보내고 활용하세요
데이터를 손에 넣었다면 이제 이렇게 써먹을 수 있어요.
- 자주 쓰는 도구로 내보내기: Excel, Google Sheets, Airtable, Notion, CSV, JSON 등으로 내보내세요.
- 업무 흐름에 연결하기: 영업 아웃리치, 가격 분석, 시장 조사처럼 필요한 곳에 바로 붙이세요.
- 정리하고 검증하기: AI를 썼더라도 정확성을 위해 샘플 점검은 한 번 해두는 게 좋아요.
데이터 추출을 성공시키는 팁: 흔한 함정 피하기

- 웹사이트 이용 약관 확인: 데이터를 스크래핑해도 되는지 먼저 확인하세요. 공개 정보만 다루고 민감한 개인정보는 피하세요. 한국이라면 GDPR뿐 아니라 개인정보보호법(PIPA)도 함께 챙겨야 해요.
- 웹사이트에 부하를 주지 마세요: 전통적인 도구를 쓴다면 요청 사이에 지연을 두고, Thunderbit를 쓴다면 도구가 알아서 조절하도록 맡기세요.
- 데이터를 검증하세요: 결과 일부는 꼭 샘플로 확인해서 정확성을 점검하세요.
- 변경에 대비하세요: 웹사이트는 늘 바뀌어요. Thunderbit 같은 AI 스크래퍼는 자동으로 적응하지만, 큰 변화는 계속 지켜보는 게 좋아요.
- 윤리적으로 쓰세요: 필요한 만큼만 스크래핑하고, 보고서나 출판물에 데이터를 쓸 때는 출처를 밝혀 주세요.
팁이 더 필요하면 데이터 스크래핑이란 무엇이고 2025년에 어떻게 하는가와 AI를 사용해 어떤 웹사이트든 스크래핑하는 방법도 함께 읽어보세요.
마무리와 핵심 정리
웹 스크래핑은 손으로 코드를 짜던 시절에서 오늘날의 AI 기반, 초보자 친화적 도구까지 크게 발전해 왔어요. 핵심 차이는 이거예요.
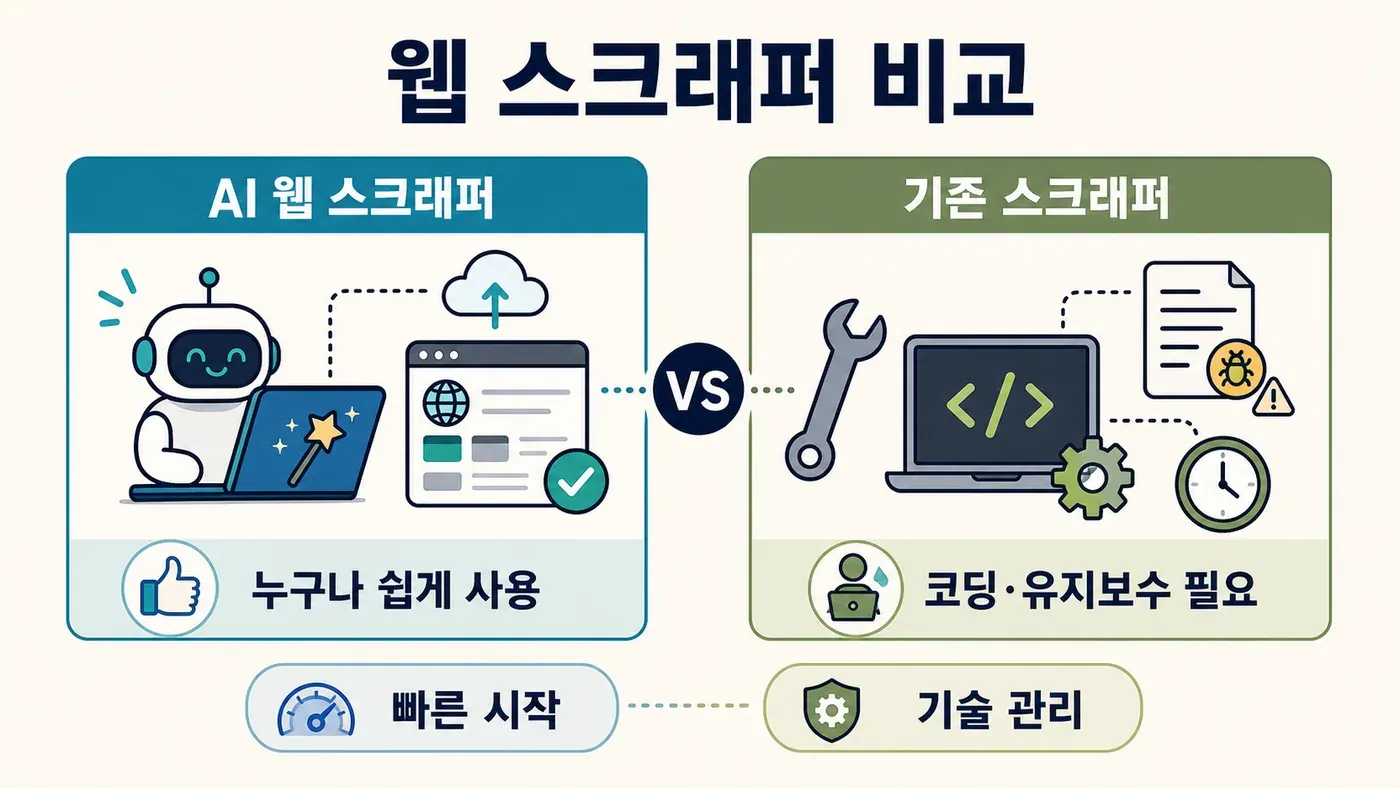
- 전통적인 스크래퍼는 통제력이 좋지만, 코딩과 유지보수, 그리고 인내심을 요구해요.
- Thunderbit 같은 AI 웹 스크래퍼는 자연어 명령, 즉시 미리보기, 하위 페이지·예약 스크래핑 같은 기능으로 누구나 데이터를 쉽게 뽑을 수 있게 해줘요.
웹 스크래핑이 처음이어도 겁낼 필요 없어요. 도구는 그 어느 때보다 쉬워졌고, 비즈니스 가치는 분명하니까요. 리드를 만들든, 가격을 모니터링하든, 그냥 복사·붙여넣기에서 벗어나고 싶든, AI 웹 스크래퍼는 든든한 조력자가 돼줄 거예요.
다음에 웹 데이터가 산더미처럼 쌓인 걸 마주하더라도 기억하세요. 컴퓨터공학 박사 학위도, 후드티도 필요 없어요. 분명한 목표와 알맞은 도구, 그리고 커피 한 잔이면 충분해요.
한번 직접 해보고 싶으신가요? Thunderbit를 설치하고 웹 데이터 추출이 얼마나 쉬운지 확인해 보세요.
더 알고 싶으신가요? Thunderbit 블로그에서 Amazon, Google, PDF 등 다양한 대상의 스크래핑을 깊이 있게 다루고 있어요.
지금 Thunderbit AI 웹 스크래퍼를 사용해 보세요 Get Started Free
자주 묻는 질문
Q1: 웹 스크래핑은 합법인가요? A: 네, 공개 데이터를 스크래핑하는 것은 많은 나라에서 대체로 합법입니다. 다만 항상 웹사이트의 이용 약관을 확인하고, 민감하거나 개인정보에 해당하는 데이터는 피해야 합니다.
Q2: 로그인해야 보이는 웹사이트도 스크래핑할 수 있나요? A: 네, 다만 더 복잡하고 사이트 정책을 위반할 수도 있습니다. 세션 처리나 인증된 스크래핑 도구가 필요하고, 법적 영향도 반드시 검토해야 합니다.
Q3: JavaScript가 많은 웹사이트의 데이터는 어떻게 스크래핑하나요? A: 헤드리스 브라우저처럼 동적 렌더링을 지원하는 도구나, 사람의 상호작용을 흉내 내며 JavaScript로 렌더링된 콘텐츠를 파싱하는 AI 스크래퍼를 사용하세요.
Q4: 차단당하지 않으려면 어떤 모범 사례를 따라야 하나요? A: 요청 제한, 무작위 지연, 사용자 에이전트 로테이션을 활용하고, 공격적으로 스크래핑하지 마세요. AI 기반 스크래퍼는 이런 전략을 자동으로 처리하는 경우가 많습니다.
더 읽어보기
-
웹 스크래핑의 합법성 이해하기: 글로벌 인사이트와 통계 법적 가이드라인, 업계 통계, 윤리적 모범 사례를 한눈에 볼 수 있는 개요예요.
-
2025 웹 스크래핑 현황 보고서 웹 데이터 추출의 트렌드, 시장 성장, 그리고 AI의 역할(2024~2025)을 다뤄요.
-
robots.txt 파일이란? 모범 사례와 문법 가이드 윤리적이고 합법적인 스크래핑을 위해 robots.txt 파일을 해석하는 방법을 배울 수 있어요.




