

בואו נחזור קצת אחורה, לא יותר מדי: אני יושב ליד השולחן, עם כוס קפה ביד, ומביט בגיליון אלקטרוני ריק יותר מהמקרר שלי בלילה של יום ראשון. צוות המכירות רוצה נתוני תמחור של המתחרים, אנשי השיווק רוצים לידים טריים, וצוות התפעול רוצה רשימות מוצרים מתריסר אתרים — אתמול. אני יודע שהנתונים שם בחוץ, אבל להגיע אליהם? זה כבר האתגר האמיתי. אם אי פעם הרגשתם כאילו אתם משחקים ב-“חבט-והחזר” דיגיטלי עם העתק-הדבק, אתם ממש לא לבד.
נקפוץ להיום, והנוף השתנה. גריפת אתרים הפכה מפרויקט צד חנוני לאסטרטגיית ליבה עסקית. JavaScript ו-Node.js נמצאים היום במרכז, ומניעים הכול — מסקריפטים חד-פעמיים ועד צינורות נתונים שלמים. אבל הנה העניין: למרות שהכלים חזקים מאי פעם, עקומת הלמידה עדיין יכולה להרגיש כמו טיפוס על האוורסט בכפכפים. לכן, בין אם אתם משתמשים עסקיים, חובבי נתונים, או פשוט אנשים שנמאס להם מהזנת נתונים ידנית, המדריך הזה בשבילכם. אפרק את האקוסיסטם, את הספריות החיוניות, את נקודות הכאב, ולמה לפעמים המהלך החכם ביותר הוא לתת ל-AI לעשות את העבודה הקשה.
למה גריפת אתרים עם JavaScript ו-Node.js חשובה לעסקים
נתחיל ב-“למה”. בשנת 2026, נתוני אינטרנט הם לא רק נחמדים שיש — הם קריטיים למשימה. לפי מחקרים עדכניים, 73% מהחברות מייחסות לנתוני רשת ציבוריים אפשרות לקבל החלטות מהירה ומדויקת יותר, וכ- 42% מתקציבי הנתונים הארגוניים מוקדשים כיום לאיסוף נתוני רשת. שוק הנתונים החלופיים (שכולל גם גריפת אתרים) כבר מגלגל 4.9 מיליארד דולר וגדל בקצב מהיר.
אז מה מניע את מרוץ הזהב הזה? הנה כמה ממקרי השימוש העסקיים הנפוצים ביותר:
- תמחור תחרותי ומסחר אלקטרוני: קמעונאים גורפים אתרי מתחרים כדי לאסוף נתוני תמחור ומלאי, ולעיתים מגדילים מכירות ב-4% או יותר.
- יצירת לידים ואינטליגנציה מכירתית: צוותי מכירות אוטומטיים את איסוף האימיילים, מספרי הטלפון ופרטי החברה ממדריכים ומפלטפורמות חברתיות.
- מחקר שוק ואיגוד תוכן: אנליסטים מושכים חדשות, ביקורות ונתוני סנטימנט כדי לזהות מגמות ולחזות התפתחויות.
- פרסום וטכנולוגיות פרסום: חברות Ad Tech עוקבות בזמן אמת אחרי מיקומי מודעות וקמפיינים של מתחרים.
- נדל״ן ותיירות: סוכנויות גורפות מודעות נכסים, מחירים וביקורות כדי להזין מודלי הערכה וניתוחי שוק.
- אגרגטורי תוכן ונתונים: פלטפורמות מאגדות נתונים ממקורות מרובים כדי להפעיל כלי השוואה ודשבורדים.
JavaScript ו-Node.js הפכו לסטאק המועדף למשימות האלה, במיוחד ככל שיותר אתרים מסתמכים על תוכן דינמי שמרונדר ב-JavaScript. Node.js מצטיין בפעולות אסינכרוניות, ולכן הוא התאמה טבעית לגריפה בהיקף גדול. ועם אקוסיסטם משגשג של ספריות, אפשר לבנות הכול — מסקריפטים מהירים ועד סקרייפרים חזקים ברמת production.
מהי גריפת נתונים ואיך עושים זאת ב-2025 Get Started Free
התהליך המרכזי: איך גריפת אתרים עם JavaScript ו-Node.js עובדת
בואו נפזר קצת את הערפל סביב תהליך גריפת האתרים הטיפוסי. בין אם אתם גורפים בלוג פשוט או אתר מסחר אלקטרוני עמוס ב-JavaScript, השלבים די עקביים:
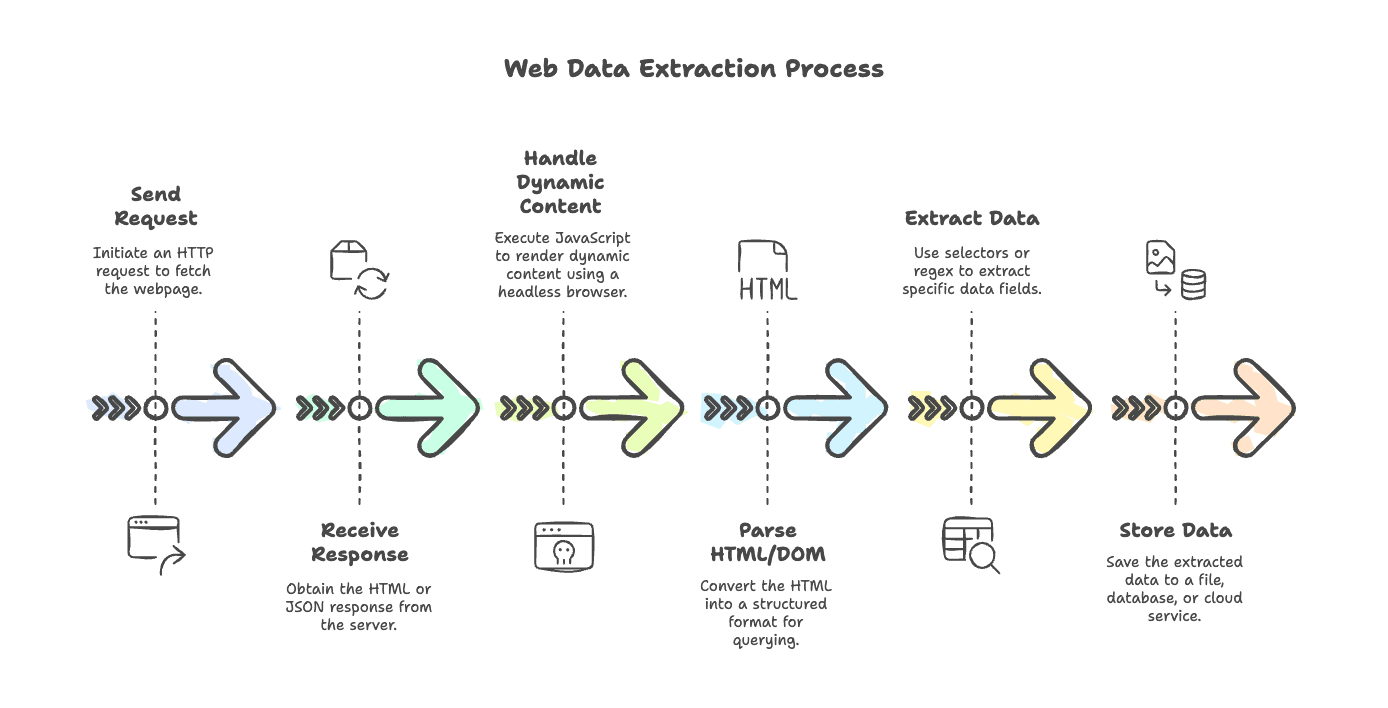
- שליחת בקשה: משתמשים בלקוח HTTP כדי להביא את הדף (למשל
axios,node-fetchאוgot). - קבלת תגובה: מקבלים חזרה את ה-HTML (ולפעמים JSON) מהשרת.
- טיפול בתוכן דינמי: אם הדף מרונדר באמצעות JavaScript, משתמשים בדפדפן חסר ממשק (כמו Puppeteer או Playwright) כדי להריץ סקריפטים ולקבל את התוכן הסופי.
- פירוק HTML/DOM: משתמשים במנתח (
cheerio,jsdom) כדי להפוך את ה-HTML למבנה שאפשר לשאול עליו. - חילוץ נתונים: משתמשים בסלקטורים או ב-Regex כדי לשלוף את השדות הדרושים.
- אחסון נתונים: שומרים את התוצאות בקובץ, במסד נתונים או בשירות ענן.
לכל שלב יש סט כלים ושיטות מומלצות משלו, ואליהם נצלול עכשיו.
ספריות HTTP חיוניות לגריפת אתרים ב-JavaScript
השלב הראשון בכל סקרייפר הוא שליחת בקשות HTTP. Node.js נותן לכם שפע אפשרויות — חלקן קלאסיות, חלקן מודרניות. הנה סקירה של הספריות הפופולריות ביותר:
1. Axios
לקוח HTTP מבוסס promises ל-Node ולדפדפנים. זהו ה”סכין השווייצרית” של רוב צרכי הגריפה.
const axios = require('axios');
const response = await axios.get('https://example.com/api/items', { timeout: 5000 });
console.log(response.data);
יתרונות: עשיר ביכולות, תומך ב-async/await, ניתוח JSON אוטומטי, interceptors ותמיכה בפרוקסי.
חסרונות: מעט כבד יותר, ולפעמים מרגיש קצת “קסום” באופן שבו הוא מטפל בנתונים.
2. node-fetch
מממש את API ה-fetch של הדפדפן בתוך Node.js. מינימליסטי ומודרני.
import fetch from 'node-fetch';
const res = await fetch('https://api.github.com/users/github');
const data = await res.json();
console.log(data);
יתרונות: קל משקל, API מוכר למי שמגיעים מ-JS בפרונט-אנד.
חסרונות: מעט תכונות, טיפול שגיאות ידני, והגדרת פרוקסי דורשת יותר קוד.
3. SuperAgent
ספריית HTTP ותיקה עם API שניתן לשרשור.
const superagent = require('superagent');
const res = await superagent.get('https://example.com/data');
console.log(res.body);
יתרונות: ותיקה, תומכת בטפסים, העלאת קבצים ותוספים.
חסרונות: ה-API מרגיש קצת מיושן, והתלות גדולה יותר.
4. Unirest
לקוח HTTP פשוט, ניטרלי לשפה.
const unirest = require('unirest');
unirest.get('https://httpbin.org/get?query=web')
.end(response => {
console.log(response.body);
});
יתרונות: תחביר פשוט, טוב לסקריפטים מהירים.
חסרונות: פחות תכונות, קהילה פחות פעילה.
5. Got
לקוח HTTP חזק ומהיר ל-Node.js עם יכולות מתקדמות.
import got from 'got';
const html = await got('https://example.com/page').text();
console.log(html.length);
יתרונות: מהיר, תומך ב-HTTP/2, נסיונות חוזרים ו-streams.
חסרונות: רק ל-Node, וה-API יכול להיות צפוף למתחילים.
6. ה-http/https המובנים של Node
תמיד אפשר לחזור לשיטה הישנה:
const https = require('https');
https.get('https://example.com/data', (res) => {
let data = '';
res.on('data', chunk => { data += chunk; });
res.on('end', () => {
console.log('Response length:', data.length);
});
});
יתרונות: אין תלויות.
חסרונות: מפורט מדי, מבוסס callbacks, בלי promises.
ראו כאן השוואת תכונות מפורטת ודוגמאות קוד.
איך לבחור את לקוח ה-HTTP הנכון לפרויקט שלכם
איך בוחרים את הכלי המתאים למשימה? הנה מה שאני מחפש:
- קלות שימוש: Axios ו-Got מצוינים עבור async/await ותחביר נקי.
- ביצועים: Got ו-node-fetch קלים ומהירים לגריפה בתפוקה גבוהה.
- תמיכה בפרוקסי: Axios ו-Got מקלים על החלפת פרוקסים.
- טיפול בשגיאות: Axios זורק שגיאות HTTP כברירת מחדל; node-fetch דורש בדיקות ידניות.
- קהילה: ל-Axios ול-Got יש קהילות פעילות והרבה דוגמאות.
ההמלצות המהירות שלי:
- סקריפטים מהירים או אבות-טיפוס: node-fetch או Unirest.
- גריפה ב-production: Axios (בזכות היכולות שלו) או Got (בזכות הביצועים).
- אוטומציית דפדפן: Puppeteer או Playwright מטפלים בבקשות מבפנים.
ניתוח HTML וחילוץ נתונים: Cheerio, jsdom ועוד
אחרי שהבאתם את ה-HTML, צריך להפוך אותו למשהו שאפשר באמת לעבוד איתו. כאן נכנסים המנתחים.
Cheerio
חשבו על Cheerio כמו jQuery לשרת. הוא מהיר, קל משקל, ומושלם ל-HTML סטטי.
const cheerio = require('cheerio');
const $ = cheerio.load('<ul><li class="item">Item 1</li></ul>');
$('.item').each((i, el) => {
console.log($(el).text());
});
יתרונות: מהיר מאוד, API מוכר, מתמודד היטב עם HTML מבולגן.
חסרונות: לא מריץ JavaScript — רואה רק את מה שקיים ב-HTML.
למדו עוד על המהירות והמקרי שימוש של Cheerio.
jsdom
jsdom מדמה DOM דמוי דפדפן בתוך Node.js. הוא יכול להריץ סקריפטים פשוטים והוא יותר “דפדפני” מ-Cheerio.
const { JSDOM } = require('jsdom');
const dom = new JSDOM(`<p id="greet">Hello</p><script>document.querySelector('#greet').textContent += ", world!";</script>`);
console.log(dom.window.document.querySelector('#greet').textContent);
יתרונות: יכול להריץ סקריפטים, תומך ב-API מלא של DOM.
חסרונות: איטי וכבד יותר מ-Cheerio, ולא דפדפן מלא.
השוואה מפורטת בין Cheerio ל-jsdom.
מתי להשתמש ב-Regex או בשיטות ניתוח אחרות
Regex בגריפת אתרים הוא כמו רוטב חריף — מצוין במידה, אבל לא צריך לשפוך אותו על הכול. Regex שימושי עבור:
- חילוץ תבניות מתוך טקסט (אימיילים, מספרי טלפון, מחירים).
- ניקוי או אימות של נתונים שנגרפו.
- שליפת נתונים מגושים של טקסט או מתגי script.
דוגמה: חילוץ מספר מטקסט
const text = "Total sales: 1,234 units";
const match = text.match(/([\d,]+)\s*units/);
if (match) {
const units = parseInt(match[1].replace(/,/g, ''));
console.log("Units sold:", units);
}
אבל אל תנסו לנתח HTML מלא עם Regex — בשביל זה השתמשו במנתח DOM. עוד טיפים ל-Regex בגריפה.
טיפול באתרים דינמיים: Puppeteer, Playwright ודפדפנים חסרי ממשק
אתרים מודרניים אוהבים JavaScript. לפעמים הנתונים שאתם צריכים לא נמצאים ב-HTML הראשוני — אלא מרונדרים על ידי סקריפטים אחרי טעינת הדף. כאן נכנסים הדפדפנים חסרי הממשק.
Puppeteer
ספריית Node.js של Google ששולטת ב-Chrome/Chromium. זה כמו שיש לכם רובוט שלוחץ וגולל בדפים בשבילכם.
const puppeteer = require('puppeteer');
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const title = await page.$eval('h1', el => el.textContent);
console.log(title);
await browser.close();
יתרונות: רינדור מלא של Chrome, API נוח, מצוין לתוכן דינמי.
חסרונות: רק Chromium, תובעני יותר במשאבים.
קראו עוד על החוזקות של Puppeteer.
Playwright
ספרייה חדשה יותר מבית Microsoft, Playwright תומכת ב-Chromium, Firefox ו-WebKit. אפשר לחשוב עליה כעל בן הדוד היותר מגניב ורב-דפדפני של Puppeteer.
const { chromium } = require('playwright');
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const content = await page.textContent('h1');
console.log(content);
await browser.close();
יתרונות: חוצה-דפדפנים, הקשרים מקבילים, ממתין אוטומטית לאלמנטים.
חסרונות: עקומת למידה מעט תלולה יותר, התקנה גדולה יותר.
Nightmare
כלי אוטומציה מבוסס Electron שהיה פופולרי לפני שנים. המאגר הועבר לארגון GitHub segment-boneyard — אזור האחסון של Segment לפרויקטים שהם הפסיקו לתמוך בהם — והגרסת npm האחרונה יצאה ב-2019. אני לא הייתי בוחר בו לשום דבר חדש ב-2026; אם אתם יורשים סקריפט שעדיין משתמש בו, בסדר, אבל לפרויקט חדש עדיף לעבור ישר ל-Playwright או Puppeteer.
השוואה בין פתרונות דפדפן חסרי ממשק
| היבט | Puppeteer (Chrome) | Playwright (רב-דפדפנים) | Nightmare (Electron) |
|---|---|---|---|
| תמיכת דפדפנים | Chrome/Edge | Chrome, Firefox, WebKit | Chrome (ישן) |
| ביצועים וסקייל | מהיר, אבל כבד | מהיר, מקביליות טובה יותר | איטי יותר, פחות יציב |
| גריפה דינמית | מצוין | מצוין + יותר יכולות | בסדר לאתרים פשוטים |
| תחזוקה | מתוחזק היטב | פעיל מאוד | בארכיון (segment-boneyard, פרסום npm אחרון ב-2019) |
| הכי מתאים ל | גריפה ב-Chrome | פרויקטים מורכבים, חוצי-דפדפנים | עבודות פשוטות וותיקות |
העצה שלי: השתמשו ב-Playwright לפרויקטים חדשים ומורכבים. Puppeteer עדיין מצוין למשימות שמתמקדות ב-Chrome בלבד. Nightmare הוא בעיקר לנוסטלגיה או לסקריפטים ישנים.
כלים תומכים: תזמון, סביבה, CLI ואחסון נתונים
סקרייפר אמיתי הוא הרבה יותר מ-fetch-and-parse. הנה כמה כלים תומכים שאני נשען עליהם:
תזמון: node-cron
מתזמנים סקרייפרים לריצה אוטומטית.
const cron = require('node-cron');
cron.schedule('0 9 * * MON', () => {
console.log('Scraping at 9 AM every Monday');
});
Node-cron מושלם לאוטומציה של משימות חוזרות.
ניהול סביבה: dotenv
שומרים סודות וקונפיגורציות מחוץ לקוד.
require('dotenv').config();
const apiKey = process.env.API_KEY;
כלי CLI: chalk, commander, inquirer
- chalk: צובע את פלט ה-console.
- commander: מנתח אפשרויות משורת הפקודה.
- inquirer: הנחיות אינטראקטיביות לקלט מהמשתמש.
אחסון נתונים
- fs: כתיבה לקבצים (JSON, CSV).
- lowdb: מסד נתונים JSON קל משקל.
- sqlite3: מסד נתונים SQL מקומי.
- mongodb: מסד נתונים NoSQL לפרויקטים גדולים יותר.
דוגמה: שמירת נתונים ל-JSON
const fs = require('fs');
fs.writeFileSync('output.json', JSON.stringify(data, null, 2));
נקודות הכאב של גריפת אתרים מסורתית עם JavaScript ו-Node.js
בואו נהיה כנים — גריפה מסורתית היא לא רק שמש ופרחים. הנה הכאבים הגדולים ביותר שראיתי (והרגשתי):

- עקומת למידה גבוהה: צריך להבין DOM, סלקטורים, לוגיקה אסינכרונית, ולפעמים גם מוזרויות של דפדפנים.
- עומס תחזוקה: אתרים משתנים, סלקטורים נשברים, ואתם כל הזמן מתקנים קוד.
- סקיילינג חלש: כל אתר צריך סקריפט משלו; שום דבר לא באמת מתאים לכולם.
- מורכבות בניקוי נתונים: נתונים שנגרפו הם מבולגנים — ניקוי, עיצוב והסרת כפילויות הם פרויקט בפני עצמו.
- מגבלות ביצועים: אוטומציית דפדפן איטית ועתירת משאבים לעבודה בהיקף גדול.
- חסימות ואמצעי נגד לבוטים: אתרים חוסמים סקרייפרים, מציגים CAPTCHAs, או מחביאים נתונים מאחורי התחברות.
- אזור אפור משפטי ואתי: צריך לנווט בין תנאי שימוש, פרטיות וציות.
קראו עוד על נקודות הכאב האלה ועל נתונים מהעולם האמיתי.
Thunderbit מול גריפת אתרים מסורתית: מהפכת פרודוקטיביות
עכשיו, בואו נדבר על הפיל שבחדר: מה אם אפשר היה לדלג על כל הקוד, הסלקטורים והתחזוקה?
כאן נכנס Thunderbit. כמי שמייסד-שותף ומנכ״ל, אני קצת משוחד, אבל תנו לי להסביר — Thunderbit נבנה עבור משתמשים עסקיים שרוצים נתונים, לא כאבי ראש.
איך Thunderbit משתווה
| היבט | Thunderbit (ללא קוד, מבוסס AI) | גריפת JS/Node מסורתית |
|---|---|---|
| הקמה | 2 קליקים, בלי קוד | כותבים סקריפטים, מבצעים ניפוי שגיאות |
| תוכן דינמי | מטופל בתוך הדפדפן | סקריפטים לדפדפן חסר ממשק |
| תחזוקה | AI מסתגל לשינויים | עדכוני קוד ידניים |
| חילוץ נתונים | AI מציע שדות | סלקטורים ידניים |
| גריפת תתי-עמודים | מובנה, בלחיצה אחת | לולאות וקוד לכל אתר |
| ייצוא | Excel, Sheets, Notion | אינטגרציה ידנית לקובץ/מסד נתונים |
| עיבוד לאחר מכן | סיכום, תיוג, עיצוב | קוד או כלים נוספים |
| מי יכול להשתמש | כל מי שיש לו דפדפן | רק מפתחים |
| ** | ** | ** |
ה-AI של Thunderbit קורא את הדף, מציע שדות, וגורף נתונים בכמה קליקים בלבד. הוא מטפל בתתי-עמודים, מסתגל לשינויי פריסה, ואפילו יכול לסכם, לתייג או לתרגם נתונים בזמן הגריפה. אפשר לייצא ל-Excel, Google Sheets, Airtable או Notion — בלי צורך בהגדרה טכנית.
מקרי שימוש שבהם Thunderbit מצטיין:
- צוותי e-commerce שעוקבים אחרי מק״טים ומחירים של מתחרים
- צוותי מכירות שגורפים לידים ופרטי קשר
- חוקרי שוק שמאגדים חדשות או ביקורות
- סוכני נדל״ן שמושכים מודעות ופרטי נכסים
לגריפה בתדירות גבוהה ובעלת חשיבות עסקית, Thunderbit חוסך המון זמן. לפרויקטים מותאמים, רחבי היקף או משולבים לעומק, לסקריפטים מסורתיים עדיין יש מקום — אבל עבור רוב הצוותים, Thunderbit הוא הדרך המהירה ביותר מ-“אני צריך נתונים” ל-“יש לי נתונים”.
ראו את תוסף Chrome של Thunderbit בפעולה או בדקו מקרי שימוש נוספים ב-בלוג של Thunderbit.
נסו את AI Web Scraper של Thunderbit
מדריך מהיר: ספריות פופולריות לגריפת אתרים ב-JavaScript וב-Node.js
הנה דף הרמזים שלכם לאקוסיסטם הגריפה ב-JavaScript בשנת 2026:
בקשות HTTP
- Axios: לקוח HTTP מבוסס promises ועשיר ביכולות.
- node-fetch: מימוש של Fetch API עבור Node.js.
- Got: לקוח HTTP מהיר ומתקדם.
- SuperAgent: בקשות HTTP ותיקות וניתנות לשרשור.
- Unirest: לקוח פשוט וניטרלי לשפה.
ניתוח HTML
תוכן דינמי
- Puppeteer: אוטומציית Chrome חסר ממשק.
- Playwright: אוטומציה לריבוי דפדפנים.
- Nightmare: אוטומציית דפדפן ותיקה מבוססת Electron.
תזמון
- node-cron: משימות Cron ב-Node.js.
CLI ושירותים
- chalk: עיצוב מחרוזות בטרמינל.
- commander: מנתח ארגומנטים ל-CLI.
- inquirer: הנחיות אינטראקטיביות ל-CLI.
- dotenv: טוען משתני סביבה.
אחסון
- fs: מערכת קבצים מובנית.
- lowdb: מסד JSON מקומי קטן.
- sqlite3: מסד SQL מקומי.
- mongodb: מסד נתונים NoSQL.
מסגרות
- Crawlee: מסגרת ברמה גבוהה לזחילה וגריפה מבית Apify. הגרסה של JavaScript/TypeScript נמצאת ב-v3.16 נכון למאי 2026 והיא המסלול הבשל יותר (גרסת ה-Python חדשה יותר). היא עוטפת את Puppeteer, Playwright, Cheerio ו-JSDOM ב-API אחד, עם סיבוב פרוקסים ותורים מובנים — שימושי אם אתם מוצאים את עצמכם בונים שוב ושוב את אותה תשתית סביב הסקרייפרים שלכם.
(תמיד בדקו את התיעוד והמאגרי GitHub העדכניים ביותר לקבלת עדכונים.)
מקורות מומלצים לשליטה בגריפת אתרים ב-JavaScript
רוצים להעמיק? הנה רשימה אוצרת של מקורות שיעזרו לכם לשדרג את מיומנויות הגריפה:
תיעוד ומדריכים רשמיים
- MDN Web Docs: Web Scraping
- תיעוד Puppeteer
- תיעוד Playwright
- תיעוד Crawlee
- Apify Web Scraping Academy
מדריכים וקורסים
- freeCodeCamp: המדריך המקיף לגריפת אתרים עם Node.js
- YouTube: גריפת אתרים עם Node.js (freeCodeCamp)
- DigitalOcean: איך לגרוף אתר באמצעות Node.js ו-Puppeteer
פרויקטים וקוד פתוח
קהילה ופורומים
ספרים ומדריכים מקיפים
- “Web Scraping with Python” של O’Reilly (עבור מושגים חוצי-שפות)
- קורסים ב-Udemy/Coursera: “Web Scraping in Node.js”
(תמיד בדקו את המהדורות והעדכונים האחרונים.)
איך לגרוף כל אתר באמצעות AI Get Started Free
סיכום: איך לבחור את הגישה הנכונה לצוות שלכם
השורה התחתונה: JavaScript ו-Node.js נותנים לכם עוצמה וגמישות אדירות לגריפת אתרים. אפשר לבנות הכול — מסקריפטים מהירים ומלוכלכים ועד סורקים חזקים וסקיילביליים. אבל עם כוח גדול מגיעה גם… תחזוקה גדולה. סקריפטים מסורתיים מתאימים במיוחד לפרויקטים מותאמים, עתירי הנדסה, שבהם דרוש לכם שליטה מלאה ואתם מוכנים לתחזוקה מתמשכת.
לכל השאר — למשתמשים עסקיים, אנליסטים, משווקים וכל מי שרק רוצה את הנתונים — פתרונות מודרניים ללא קוד כמו Thunderbit הם משב רוח מרענן. תוסף Chrome של Thunderbit, המבוסס AI, מאפשר לכם לגרוף, למבנה ולייצא נתונים בתוך דקות, לא ימים. בלי קוד, בלי סלקטורים, בלי כאבי ראש.
אז מה הגישה הנכונה? אם לצוות שלכם יש כוח הנדסי ודרישות ייחודיות, צללו לתוך ארגז הכלים של Node.js. אם אתם רוצים מהירות, פשטות והחופש להתמקד בתובנות במקום בתשתית, תנו ל-Thunderbit צ’אנס. כך או כך, הרשת היא מסד הנתונים שלכם — לכו תביאו את הנתונים.
ואם אי פעם תיתקעו, זכרו: אפילו הסקרייפרים הטובים ביותר התחילו מדף ריק וכוס קפה חזקה. גריפה שמחה.
רוצים ללמוד עוד על גריפה מבוססת AI או לראות את Thunderbit בפעולה?
- האתר הרשמי של Thunderbit
- הורדת תוסף Chrome של Thunderbit
- בלוג Thunderbit
- איך לגרוף כל אתר באמצעות AI
- מהי גריפת נתונים ואיך עושים זאת ב-2025
אם יש לכם שאלות, סיפורים או סיפורי אימה אהובים על גריפה, כתבו אותם בתגובות או צרו איתי קשר. אני אוהב לשמוע איך אנשים הופכים את הרשת למגרש המשחקים שלהם לנתונים.
תישארו סקרנים, תישארו עם קפאין, ותגרפו חכם יותר — לא קשה יותר.
הורידו את תוסף Chrome של Thunderbit
נסו AI Web Scraper Get Started Free
שאלות נפוצות:
1. למה להשתמש ב-JavaScript וב-Node.js לגריפת אתרים ב-2025?
כי רוב האתרים המודרניים בנויים עם JavaScript. Node.js מהיר, ידידותי ל-async, ויש לו אקוסיסטם עשיר (למשל Axios, Cheerio, Puppeteer) שתומך בהכול — משליפות פשוטות ועד גריפת תוכן דינמי בהיקף גדול.
2. מהו תהליך העבודה הטיפוסי לגריפת אתר עם Node.js?
בדרך כלל זה נראה כך:
בקשה → טיפול בתגובה → (הרצת JS אופציונלית) → ניתוח HTML → חילוץ נתונים → שמירה או ייצוא
כל שלב יכול להיות מטופל באמצעות כלים ייעודיים כמו axios, cheerio או puppeteer.
3. איך גורפים דפים דינמיים שמרונדרים ב-JavaScript?
משתמשים בדפדפנים חסרי ממשק כמו Puppeteer או Playwright. הם טוענים את כל הדף (כולל JS), וכך אפשר לגרוף את מה שהמשתמשים באמת רואים.
4. מהם האתגרים הגדולים ביותר בגריפה מסורתית?
- שינויי מבנה באתר
- זיהוי והגנה נגד בוטים
- עלויות משאבים של דפדפן
- ניקוי נתונים ידני
- תחזוקה גבוהה לאורך זמן
כל אלה מקשים לשמור על גריפה בהיקף גדול או כזו שאינה ידידותית למפתחים.
5. מתי כדאי להשתמש במשהו כמו Thunderbit במקום בקוד?
כדאי להשתמש ב-Thunderbit אם אתם צריכים מהירות, פשטות, ולא רוצים לכתוב או לתחזק קוד. הוא אידיאלי לצוותים במכירות, שיווק או מחקר שרוצים לחלץ ולבנות נתונים במהירות — במיוחד מאתרים מורכבים או רב-עמודיים.




