
הביקוש לנתונים מתויגים באיכות גבוהה בלמידת מכונה מעולם לא היה גבוה יותר. בכל פעם שאני מדבר עם צוותים שבונים מודלי AI חדשים — בין אם זה לחיזוי מכירות, להמלצות מוצרים או לניתוח סנטימנט של לקוחות — אותם כאבי ראש חוזרים שוב ושוב: תיוג נתונים ידני הוא איטי, יקר, ובכנות, קצת שובר נשמה. ראיתי פרויקטים נתקעים במשך שבועות (או חודשים) רק כי חיכו מספיק דוגמאות מתויגות כדי לאמן מודל סביר. וכשהתוויות לא עקביות? ובכן, נגיד רק שהתחזיות של המודל יכולות להיות בערך כמו הניסיונות שלי לחנות במקביל.
אבל הנה החדשות הטובות: תיוג נתונים אוטומטי באמצעות למידת מכונה משנה את כללי המשחק. כשנותנים ל-AI לעשות את העבודה הכבדה, עסקים לא רק מאיצים את תהליך התיוג, אלא גם משפרים דיוק ועקביות — שני דברים שיכולים להכריע את פרויקט ה-ML שלך. במדריך הזה אראה לך איך תיוג נתונים אוטומטי עובד, למה הוא כל כך קריטי לבניית מודלים חזקים, ואיך אפשר להשתמש בכלים כמו כדי להקים תהליך תיוג אוטומטי משלך — בלי לכתוב קוד בכלל.
מהו תיוג נתונים אוטומטי באמצעות למידת מכונה?
נפרק את זה. תיוג נתונים אוטומטי באמצעות למידת מכונה פירושו שימוש באלגוריתמים ובכלי AI כדי להקצות תוויות (כמו “ספאם” או “לא ספאם”, “חתול” או “כלב”, “חיובי” או “שלילי”) לנתונים הגולמיים שלך — בלי שאדם יצטרך לעבור על כל דוגמה ודוגמה. תחשוב על זה כמו ההבדל בין תיוג ידני של אלפי תמונות חופשה לבין שימוש בזיהוי פנים כדי למיין אותן אוטומטית לפי אדם, מיקום או אפילו מצב רוח.
תיוג ידני מסורתי הוא בדיוק מה שזה נשמע: אנשים שסוקרים נתונים פריט אחר פריט ומקצים את התווית הנכונה. זה מדויק לפעמים, אבל איטי, יקר וקשה להרחבה. תיוג אוטומטי, לעומת זאת, משתמש במודלי למידת מכונה — שאומנו על סט קטן יותר של נתונים שתויגו ידנית — כדי לחזות תוויות לשאר מערך הנתונים. התוצאה? תיוג מהיר יותר, עקבי יותר וניתן להרחבה בקלות ().
עבור משתמשים עסקיים, זה אומר שאפשר לבנות מודלים טובים יותר, מהר יותר, ועם הרבה פחות עבודה ידנית מפרכת. ובעולם מונע-הנתונים של היום, זה יתרון תחרותי רציני.
למה תיוג נתונים אוטומטי הוא המפתח למודלי למידת מכונה איכותיים
העניין הוא כזה: איכות הנתונים המתויגים שלך משפיעה ישירות על הביצועים של מודלי למידת המכונה שלך. כמו שאומרים, “זבל נכנס, זבל יוצא”. אם התוויות שלך אינן עקביות או שגויות, המודל ילמד דפוסים שגויים — והתחזיות שלו יסבלו ().
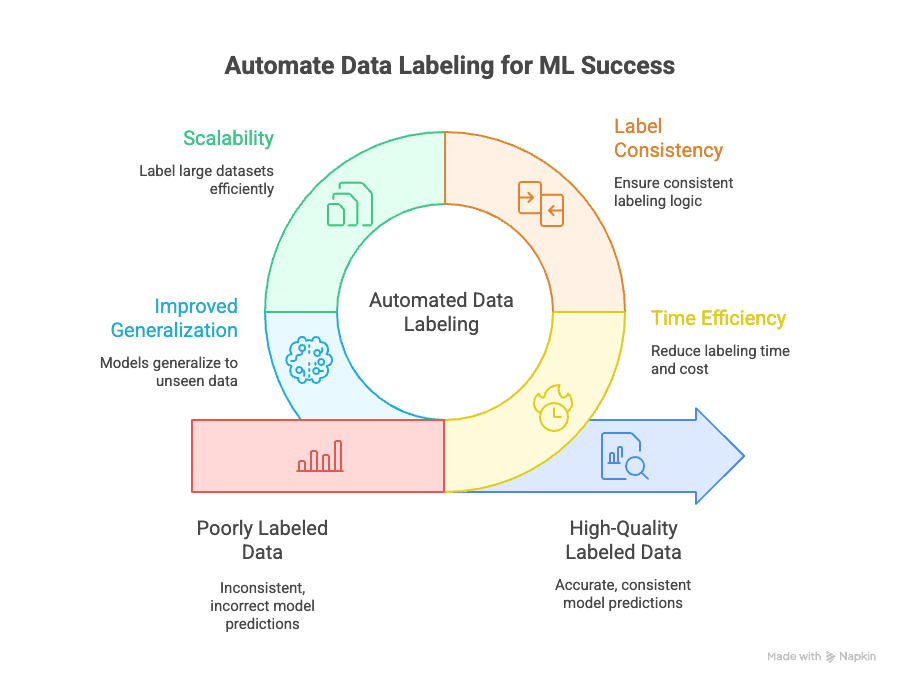
תיוג נתונים אוטומטי מתמודד עם כמה אתגרים מרכזיים:
- חיסכון בזמן: תיוג ידני יכול לבלוע של פרויקט ML. אוטומציה מקטינה את זה לשבריר, ומאפשרת לך לבצע איטרציות ולפרוס מודלים מהר יותר.
- עקביות בתוויות: מכונות לא מתעייפות ולא מוסחות. תיוג אוטומטי מבטיח שכל נקודת נתון תתויג לפי אותה לוגיקה, וכך מפחית טעויות אנוש והטיות ().
- יכולת הרחבה: צריך לתייג 10,000, 100,000 או אפילו מיליון נקודות נתון? אוטומציה הופכת את זה לאפשרי — בלי לגייס צבא של מסמנים ().
- שיפור בהכללה: תוויות עקביות ואיכותיות עוזרות למודלים להכליל טוב יותר לנתונים חדשים שלא נראו קודם, וזו הרי המטרה הסופית בלמידת מכונה ().
וההשפעה העסקית ממשית: Keylabs מדווחת שתהליכי עבודה היברידיים, שמשלבים תיוג בעזרת AI עם סקירה אנושית, יכולים לעומת תהליכים ידניים בלבד — מה שמתורגם ישירות לאיטרציה מהירה יותר על מודלים ולתחזיות אמינות יותר בהמשך הדרך.
השוואה בין תיוג ידני לתיוג אוטומטי
נעמיד את זה זה מול זה:
| גורם | תיוג ידני | תיוג אוטומטי עם ML |
|---|---|---|
| מהירות | איטי (שבועות/חודשים למערכי נתונים גדולים) | מהיר (דקות/שעות למערכי נתונים גדולים) |
| דיוק | גבוה, אבל רגיש לטעויות/חוסר עקביות אנושיים | גבוה, עם לוגיקה עקבית ופחות שגיאות |
| יכולת הרחבה | מוגבל על ידי משאבי אנוש | מתרחב בקלות למיליוני נקודות נתון |
| עלות | יקר (דורש עבודה רבה) | עלויות נמוכות יותר בטווח הארוך (Keylabs) |
| הכי מתאים ל | מערכי נתונים קטנים, מורכבים או עמומים | מערכי נתונים גדולים, חוזרים או מוגדרים היטב |
תיוג ידני עדיין יש לו מקום — במיוחד במקרי קצה או בנתונים עמומים — אבל ברוב היישומים העסקיים, אוטומציה היא הדרך קדימה.
השלבים הבסיסיים של תיוג נתונים אוטומטי באמצעות למידת מכונה
אז איך תיוג נתונים אוטומטי עובד בפועל? הנה הזרימה מקצה לקצה שאני ממליץ עליה (וגם משתמש בה בעצמי):
- איסוף ועיבוד מקדים של נתונים
- חילוץ והכנה של מאפיינים
- תיוג אוטומטי באמצעות למידת מכונה
- בקרת איכות ובדיקה אנושית
נפרק כל שלב.
שלב 1: איסוף ועיבוד מקדים של נתונים
לפני שאפשר לתייג משהו, צריך לאסוף ולנקות את הנתונים. זה יכול לכלול גריפת רשימות מוצרים מאתרים, ייצוא ביקורות לקוחות או איסוף תמונות ממאגרי מידע פנימיים. המפתח כאן הוא איכות: נתונים גרועים מובילים לתוויות גרועות, שמובילות למודלים גרועים ().
שיטות מומלצות:
- להסיר כפילויות ורשומות לא רלוונטיות
- לתקנן פורמטים (תאריכים, מטבעות וכו׳)
- לטפל בנתונים חסרים או לא מלאים
שלב 2: חילוץ והכנה של מאפיינים
אחר כך מזהים את המאפיינים החשובים למשימת התיוג. למשל, אם אתם מתייגים רשימות מוצרים, אפשר לחלץ מאפיינים כמו מחיר, מותג, קטגוריה ותיאור. במכירות או בשיווק, זה יכול להיות חילוץ שמות חברות, פרטי קשר או סנטימנט מתוך אימיילים.
דוגמה עסקית: באמצעות , אפשר לגרוף נתונים מובנים מדפי אינטרנט — כמו מפרטי מוצר, ביקורות או פרטי קשר — בלי לכתוב אפילו שורת קוד אחת.
שלב 3: תיוג אוטומטי באמצעות למידת מכונה
כאן הקסם קורה. משתמשים במודלי למידת מכונה (שאומנו על מערך נתונים קטן יותר, שתויג ידנית) כדי לחזות תוויות לשאר הנתונים. טכניקות נפוצות כוללות:
- מודלים מונחים: מאמנים מסווג על דוגמאות מתויגות, ואז משתמשים בו כדי לתייג נתונים חדשים.
- תיוג מבוסס חוקים: משתמשים בכללים מוגדרים מראש (למשל, “אם המחיר > 1000$, תייג כ‘פרימיום’”) למקרים פשוטים.
- למידה פעילה: המודל מבקש קלט אנושי במקרים לא ודאיים, ומשתפר לאורך הזמן ().
- למידת העברה: משתמשים במודלים מאומנים מראש כדי להאיץ את התיוג בתחומים חדשים ().
התוצאה? תוויות עקביות ואיכותיות — בהיקף גדול.
שלב 4: בקרת איכות ובדיקה אנושית
אפילו המודלים הטובים ביותר צריכים בדיקת שפיות. סקירה אנושית תקופתית עוזרת לזהות מקרי קצה, נתונים עמומים או drift של המודל. שלבי QA מעשיים כוללים:
- דגימה אקראית של נתונים מתויגים לבדיקה ידנית
- השוואת תוויות אוטומטיות לסט “זהב” (gold standard)
- שימוש במדדי הסכמה בין מסמנים כדי למדוד עקביות ()
איך להשתמש ב-Thunderbit לתיוג נתונים אוטומטי באמצעות למידת מכונה
עכשיו נעבור לעבודה מעשית. הוא Web Scraper מבוסס AI וכלי לתיוג נתונים שנבנה עבור משתמשים עסקיים — בלי צורך בקוד. כך אפשר להשתמש בו כדי לאוטומט את תהליך תיוג הנתונים שלך:
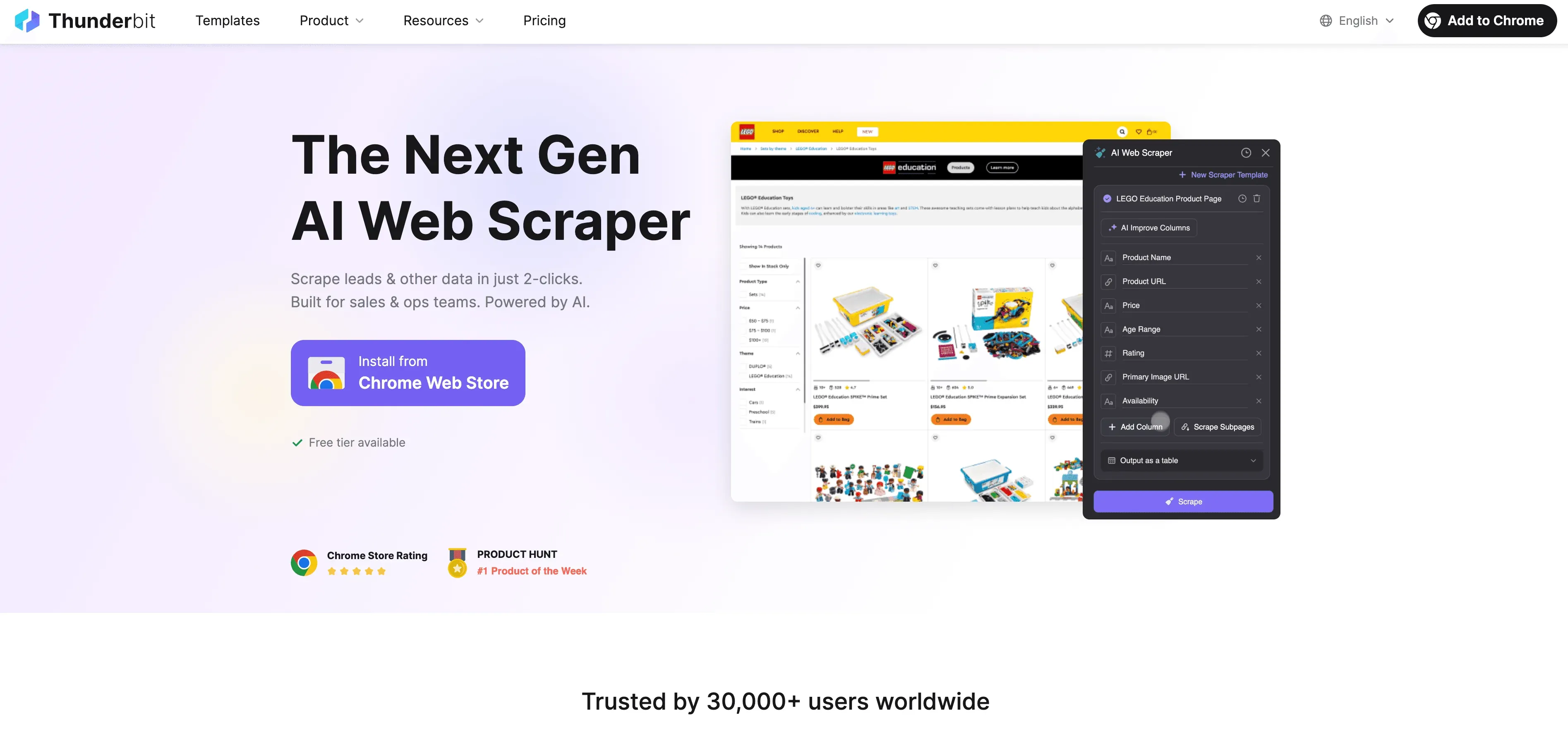
מדריך שלב-אחר-שלב
- גריפת נתונים מאתרים: השתמשו ב- כדי לאסוף נתונים מובנים מכל אתר. פשוט פותחים את התוסף, בוחרים את מקור הנתונים, ונותנים ל-AI של Thunderbit להציע את השדות הטובים ביותר לחילוץ.
- הגדרת הוראות תיוג: השתמשו בפקודות בשפה טבעית של Thunderbit כדי לומר ל-AI איך לתייג את הנתונים. למשל, “תייגו את כל המוצרים מעל 500$ כ‘פרימיום’” או “סמנו ביקורות עם סנטימנט חיובי”.
- החלת תיוג אוטומטי: תכונת Field AI Prompt של Thunderbit מאפשרת להתאים ולשפר את אופן הקצאת התוויות — מושלם למשימות תיוג מרובות שדות או מורכבות.
- ייצוא הנתונים המתויגים: לאחר שהנתונים שלכם תויגו, אפשר לייצא אותם ישירות ל-Excel, Google Sheets, Airtable או Notion — מוכנים לאימון המודל או לניתוח.
החלק הכי טוב? Thunderbit נבנה עבור משתמשים לא טכניים בתחומי מכירות, שיווק, תפעול ועוד. לא צריך לכתוב אפילו שורת קוד אחת או להיאבק עם תבניות מורכבות.
הפקודות בשפה טבעית של Thunderbit ותכונות Field AI
אחת התכונות האהובות עליי היא היכולת להגדיר לוגיקת תיוג באנגלית פשוטה. רוצים לסווג לידים לפי אזור, לתייג מוצרים לפי קטגוריה, או לסמן אימיילים עם שפה דחופה? פשוט תארו מה אתם רוצים, וה-AI של Thunderbit יעשה את השאר.
דוגמאות לפקודות:
- “תייגו את כל אנשי הקשר עם אימייל שמסתיים ב-‘.edu’ כמגזר ‘חינוך’.”
- “אם הביקורת מזכירה ‘משלוח מהיר’, סמנו כ‘חוויית משלוח חיובית’.”
- “קבצו מוצרים לפי מותג וטווח מחירים.”
Field AI Prompt של Thunderbit מאפשר לכם לרדת אפילו יותר לרזולוציה — להתאים את לוגיקת התיוג לכל עמודה, לשלב כללים, או אפילו לתרגם תוויות למספר שפות.
גריפת תתי-עמודים ותיוג רב-שדות
מבני נתונים מורכבים? אין בעיה. תכונת גריפת תתי-העמודים של Thunderbit מאפשרת לחלץ ולתייג נתונים מעמודים מקוננים (כמו פרטי מוצר או ביוגרפיות של מחברים) ולמזג הכול לטבלה אחת מובנית. אפשר לתייג כמה שדות בבת אחת — ולחסוך עוד יותר זמן.
מקרה שימוש מהעולם האמיתי: גריפת רשימות מוצרים מאתר ecommerce, ואז מעבר על כל קישור מוצר כדי לחלץ ולתייג מפרטים, ביקורות ופרטי מוכר — הכול בזרימת עבודה אחת.
שילוב של כמה כלי תיוג נתונים לדיוק ויעילות גבוהים יותר
למרות ש-Thunderbit מכסה המון שטח, לפעמים צריך כלים ייעודיים לסוגי נתונים מסוימים — כמו הערות על תמונות או תיוג וידאו. כאן נכנסות פלטפורמות כמו או .
טיפ מקצועי: השתמשו ב-Thunderbit כדי לטפל בחילוץ נתוני אינטרנט ובתיוג ראשוני, ואז ייצאו את הנתונים ל-Label Studio או Supervisely לצורך הערות מתקדמות (כמו תיבות תיחום על תמונות או תגיות וידאו פריים-אחר-פריים). הגישה הרב-כלית הזו מאפשרת לנצל את החוזקות של כל פלטפורמה, ומשפרת גם דיוק וגם יעילות ().
מתי להשתמש בכלים ייעודיים לצד Thunderbit
- הערות על תמונות: למשימות כמו זיהוי אובייקטים או סגמנטציה, השתמשו ב-Supervisely או ב-Label Studio.
- תיוג וידאו: כלים ייעודיים לוידאו מטפלים בהערות ומעקב פריים-אחר-פריים.
- משימות מורכבות עם כמה תוויות: שלבו את חילוץ הנתונים המובנים של Thunderbit עם כלי הערות מתקדמים כדי להשיג את התוצאות הטובות ביותר.
שיטה מומלצת: התחילו עם Thunderbit לתיוג מהיר וניתן להרחבה של נתונים מובנים וחצי-מובנים, ואז הוסיפו כלים ייעודיים לפי הצורך להערות מעמיקות.
שיטות מומלצות לתיוג נתונים אוטומטי באמצעות למידת מכונה
רוצים להוציא את המקסימום מתהליך התיוג האוטומטי שלכם? הנה הטיפים המובילים שלי:
- הגדירו הנחיות תיוג ברורות: תוויות עמומות מובילות לנתונים לא עקביים — היו ספציפיים לגבי משמעותה של כל תווית.
- התחילו עם סט זרעים איכותי: תייגו ידנית דגימה קטנה ומייצגת כדי לאמן את המודל הראשוני.
- בצעו איטרציה ושפרו: השתמשו בלמידה פעילה כדי לחדד את המודל לאורך זמן, ולהתמקד בבדיקה האנושית במקרים הקשים ביותר.
- אמתו באופן קבוע: בדקו מדי פעם דגימה אקראית של נתונים מתויגים כדי לאתר שגיאות או drift.
- שלבו ואוטומטו: השתמשו בכלים כמו Thunderbit כדי לחבר איסוף נתונים, תיוג וייצוא בזרימת עבודה אחת.
אתגרים נפוצים ואיך להתמודד איתם
תיוג נתונים אוטומטי לא חף מקשיים. כך מתמודדים עם הנפוצים שבהם:
- נתונים עמומים: השתמשו בהגדרות תיוג ברורות ומפורטות וספקו דוגמאות למקרי קצה.
- Drift של המודל: אימנו מחדש את מודל התיוג שלכם באופן קבוע עם נתונים חדשים שעברו סקירה ידנית.
- מקרי קצה: הקימו תהליך לבדיקה אנושית של נקודות נתון לא ודאיות או חדשות.
- בעיות אינטגרציה: בחרו כלים (כמו Thunderbit) שמציעים ייצוא קל לפלטפורמות המועדפות עליכם.
סיכום ומסקנות מרכזיות
תיוג נתונים אוטומטי באמצעות למידת מכונה הוא הרוטב הסודי מאחורי מודלי ה-AI היעילים ביותר של היום. הוא חוסך זמן, מצמצם עלויות, ובעיקר — מספק את התוויות העקביות והאיכותיות שהמודלים שלכם צריכים כדי לפעול במיטבם. כשמשלבים כלים כמו עם פלטפורמות הערות ייעודיות, אפשר לבנות תהליך תיוג מהיר, מדויק וניתן להרחבה — לא משנה מה הרקע הטכני שלכם.
מוכנים לראות את ההבדל בעצמכם? , נסו תיוג אוטומטי בפרויקט הבא שלכם, ותראו את מודלי למידת המכונה שלכם נעשים חכמים ומהירים יותר. ואם אתם צמאים לעוד טיפים ושיטות עבודה מומלצות, בקרו ב- למדריכים מעמיקים ולקורסים קצרים.
שאלות נפוצות
1. מהו תיוג נתונים אוטומטי באמצעות למידת מכונה?
זהו תהליך של שימוש במודלי AI ו-ML כדי להקצות תוויות לנתונים באופן אוטומטי, במקום שבני אדם יעשו זאת ידנית. הגישה הזו מאיצה את התיוג, משפרת עקביות, ויכולה לעבוד גם על מערכי נתונים גדולים.
2. למה איכות התיוג חשובה ללמידת מכונה?
מודלים לומדים רק את הדפוסים שהתוויות שלהם מקודדות, ולכן תוויות לא עקביות או שגויות מלמדות את המודל את הדבר הלא נכון. כתבות מקצועיות של ספקי תיוג כמו Keylabs מצאו שתהליכי עבודה היברידיים של AI ואדם יכולים להעלות את דיוק התיוג עד 80% לעומת תהליכים ידניים בלבד — והעלייה הזו משפיעה ישירות על ביצועי המודל.
3. איך Thunderbit עוזר בתיוג נתונים אוטומטי?
Thunderbit מאפשר לגרוף ולתייג נתוני אינטרנט בעזרת AI, עם פקודות בשפה טבעית ולוגיקת שדות שניתן להתאים אישית — בלי צורך בקוד. זה אידיאלי למשתמשים עסקיים במכירות, שיווק ותפעול.
4. אפשר לשלב את Thunderbit עם כלים אחרים לתיוג?
בהחלט. השתמשו ב-Thunderbit לחילוץ נתונים מובנים ולתיוג ראשוני, ואז ייצאו לכלים כמו Label Studio או Supervisely להערות מתקדמות על תמונות או וידאו.
5. מהן שיטות העבודה המומלצות לתיוג נתונים אוטומטי?
הגדירו הנחיות תיוג ברורות, התחילו עם סט זרעים איכותי, בצעו איטרציה עם למידה פעילה, בצעו ולידציה באופן קבוע, והשתמשו בכלים משולבים כדי לייעל את התהליך.
מוכנים לאוטומט את תיוג הנתונים שלכם ולהאיץ את פרויקטי למידת המכונה שלכם? נסו את Thunderbit ותראו כמה זמן — וכמה תסכול — אפשר לחסוך.
מידע נוסף: