Extracteur Pixiv
Approuvé par des professionnels dans des entreprises leaders












Extraction de données Pixiv simplifiée
Extrayez des données Pixiv comme les titres, les auteurs et les détails de section sans copier-coller manuel.
Extraction en masse de données Pixiv à grande échelle
Collecter manuellement des données Pixiv page par page devient vite lent, surtout quand vous avez besoin de dizaines ou de centaines de titres, de résumés d’articles, d’auteurs, de dates de publication, de sources d’actualité et de sections. Thunderbit vous permet d’extraire une liste d’URL en une seule fois, afin de passer de quelques pages à un grand ensemble d’enregistrements Pixiv sans perdre de temps en tâches répétitives.

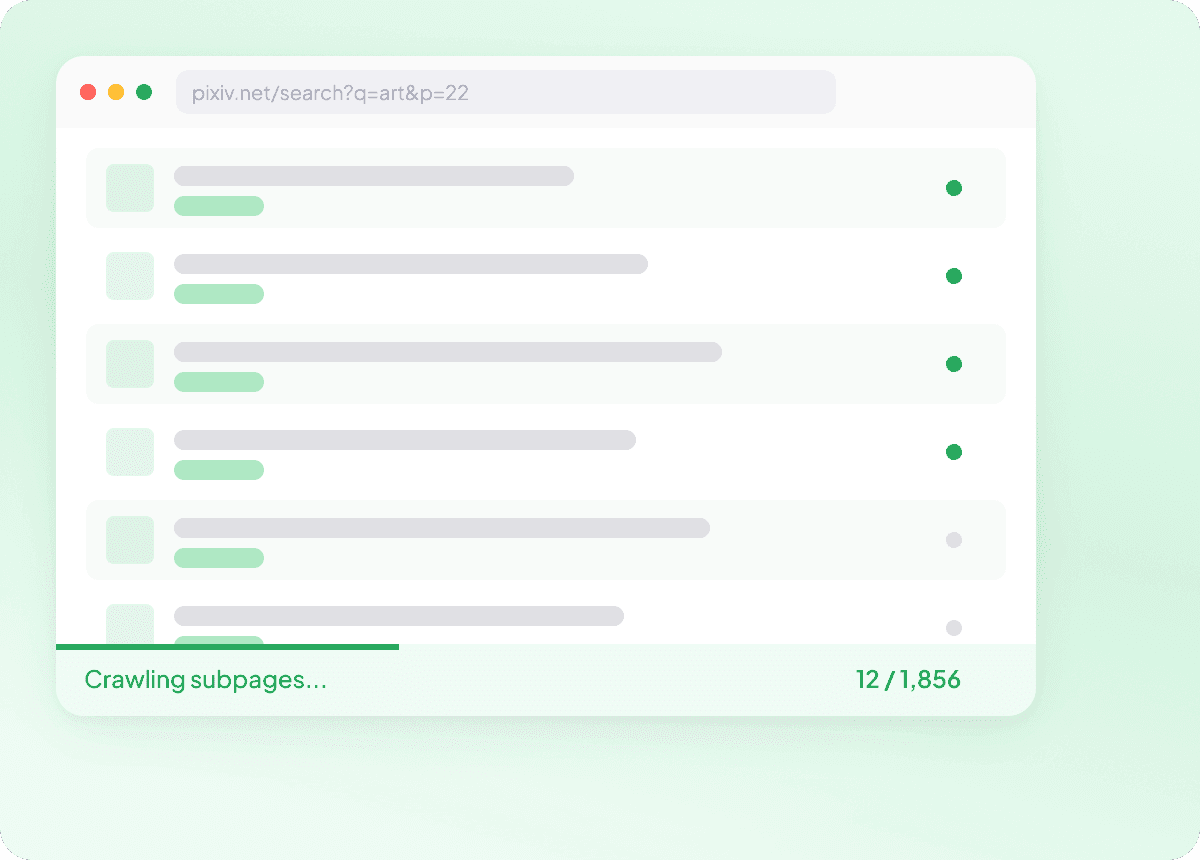
Capturez tous les détails des sous-pages Pixiv
Les pages de liste sur Pixiv n’affichent souvent que les informations de base, tandis que les vrais détails se trouvent dans chaque sous-page d’article ou de publication. Thunderbit visite chaque sous-page liée et récupère l’ensemble des informations, vous donnant des données plus riches comme le résumé de l’article, l’auteur, la date de publication, la source d’actualité et la section dans une structure propre.
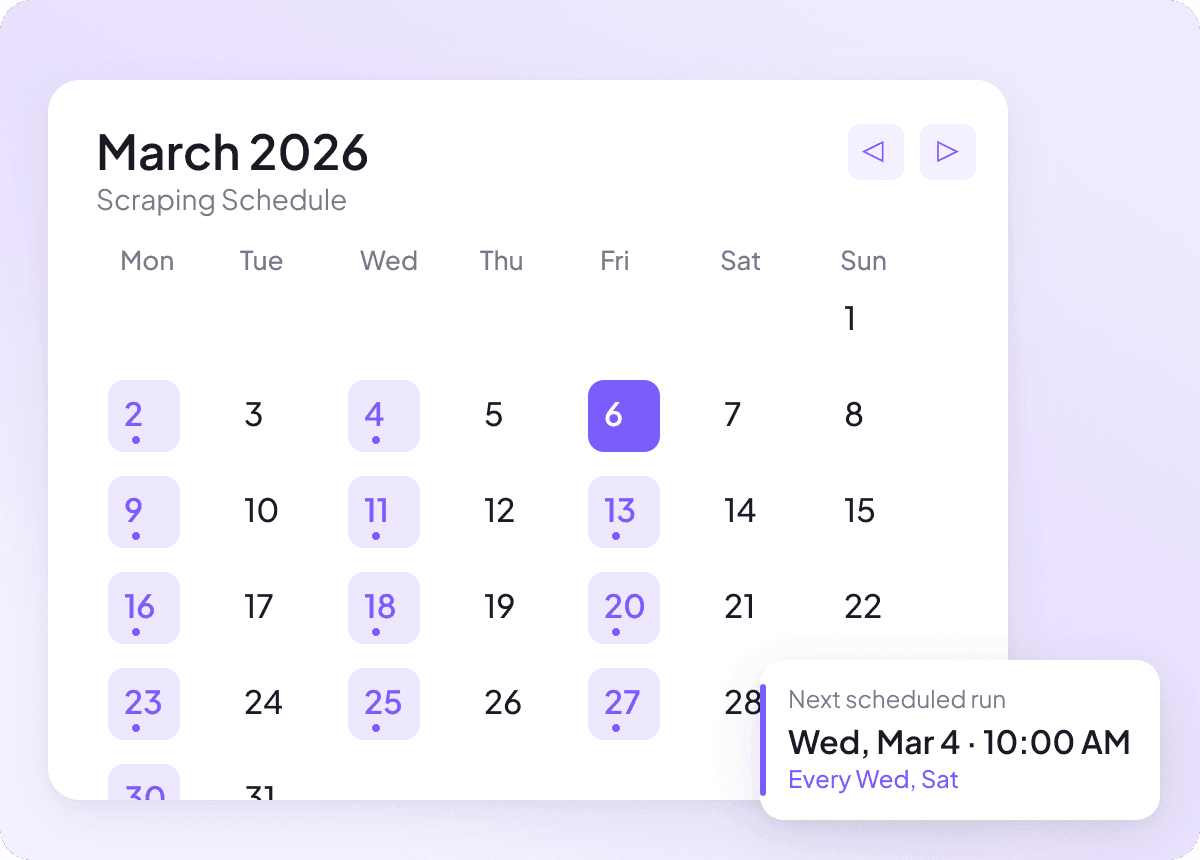
Gardez les données Pixiv à jour en pilote automatique
Le contenu Pixiv peut changer chaque jour, et le suivre manuellement signifie consulter les mêmes pages encore et encore. Avec l’extraction programmée, Thunderbit fonctionne en pilote automatique et livre régulièrement des données Pixiv fraîches dans votre tableur, afin que le suivi du titre, de l’auteur et de la section reste à jour sans que vous ayez à lever le petit doigt.
Pourquoi Thunderbit est-il différent des extracteurs Pixiv traditionnels ?
Une méthode plus simple pour extraire Pixiv sans sélecteurs fragiles ni nettoyage fastidieux.
Extracteurs traditionnels
L’ancienne façon de faireThunderbit IA
L’approche la plus intelligenteNe nous crois pas sur parole
Découvre ce que nos utilisateurs disent de Thunderbit.







Foire aux questions
Associés cas d’usage
Explore d’autres cas d’usage de l’extracteur web Thunderbit.

Extracteur Amarillas.com
L’Extracteur Amarillas.com de Thunderbit vous permet d’extraire des données structurées depuis Amarillas.com, y compris les listes de motels et de restaurants. Grâce aux suggestions de champs alimentées par l’IA, récupérez rapidement les noms d’entreprises, adresses, numéros de contact, notes et avis pour vos besoins de recherche, de marketing ou de prospection.
En savoir plus ->
Extracteur People-Search
L’Extracteur People-Search de Thunderbit vous permet d’extraire facilement des données structurées à partir de profils People-Search et de pages de recherche inversée de numéros. Grâce aux suggestions intelligentes de champs alimentées par l’IA, collectez rapidement noms, adresses, numéros de téléphone, emails et bien plus pour vos besoins de recherche, de prospection ou de génération de leads. Parfait pour les marketeurs, chercheurs et entreprises à la recherche de contacts et d’informations publiques.
En savoir plus ->
Extracteur Pages Blanches
L’Extracteur White Pages de Thunderbit vous permet de collecter rapidement des données issues des annuaires téléphoniques et professionnels White Pages, avec des suggestions de champs intelligentes grâce à l’IA. Rassemblez noms, numéros de téléphone, adresses et sites web pour vos besoins de prospection, de marketing ou de recherche en quelques clics.
En savoir plus ->
Extracteur BestPrice GR
L’Extracteur BestPrice GR de Thunderbit, propulsé par l’IA, vous permet de collecter en quelques clics les fiches produits, les prix et toutes les informations détaillées depuis BestPrice.gr. Idéal pour les équipes commerciales, marketing et e-commerce qui souhaitent obtenir rapidement des données structurées et fiables.
En savoir plus ->Extracteur Substack
Obtenez les nombres d’abonnés Substack, les titres d’articles et les descriptions de publication dans un tableau clair — sans code, l’IA se charge de la structuration.
En savoir plus ->
Extracteur Rakuten Travel
L’Extracteur Rakuten Travel de Thunderbit vous permet de collecter facilement les données des listes et fiches d’hôtels sur Rakuten Travel. Grâce aux suggestions intelligentes de champs, récupérez rapidement noms d’hôtels, tarifs, évaluations, types de chambres et équipements pour vos recherches ou l’organisation de voyages. Parfait pour les agences de voyage, les chercheurs et les entreprises qui ont besoin de données structurées sur le secteur du tourisme.
En savoir plus ->Prêt à accélérer l’extraction de tes données ?
Rejoins plus de 100 000 professionnels qui utilisent déjà Thunderbit pour automatiser leurs workflows de web scraping.
L’essai gratuit inclut des crédits illimités pour 8 pages web.