Extracteur Next
Approuvé par des professionnels dans des entreprises leaders












Extraire facilement les données produits de Next
Thunderbit vous permet de scraper les données produits de Next de manière simple et fiable.
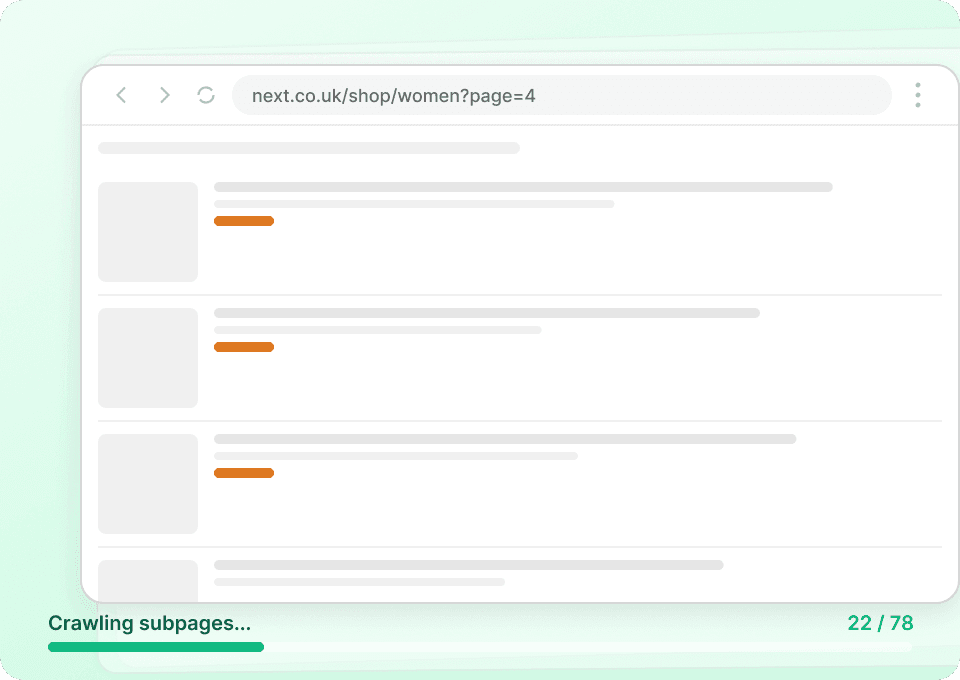
Obtenez la fiche produit complète
Les pages de listing ne montrent que l’essentiel. Récupérez toutes les informations de chaque page produit sur Next. Thunderbit visite automatiquement chaque sous-page, extrait les détails comme les descriptions complètes, les couleurs disponibles et les URL d’images en haute résolution, puis les ajoute sous forme de colonnes à côté des noms et prix des produits.
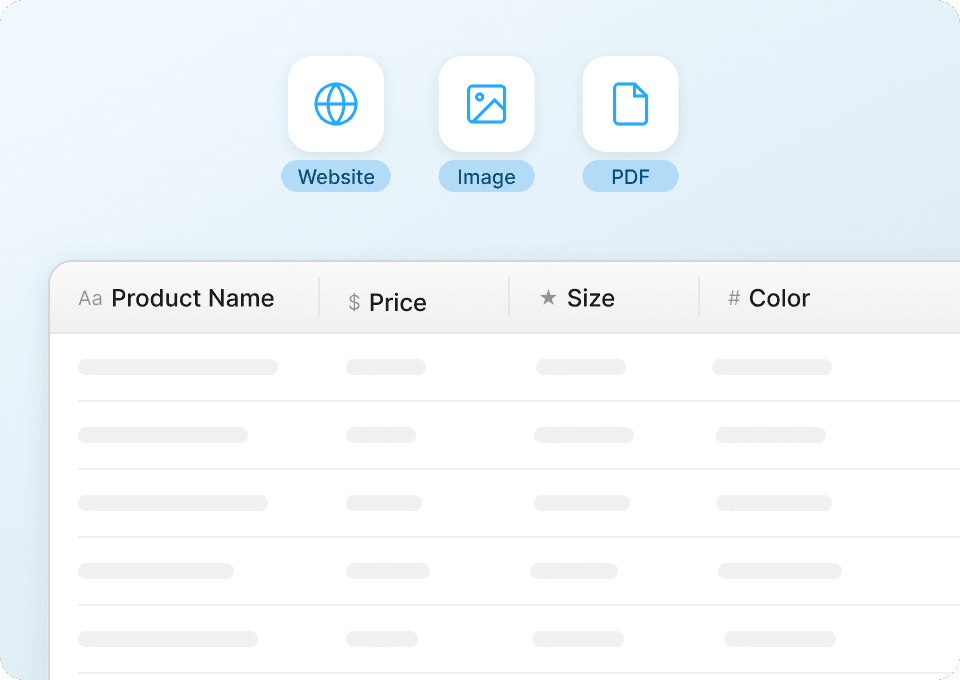
Nettoyez automatiquement les données produit
Les données brutes sont souvent désordonnées et longues à nettoyer. Thunderbit structure et formate automatiquement les données produits pendant l’extraction depuis Next. Exportez directement des noms, prix, descriptions et disponibilités propres vers Google Sheets ou Notion, prêts à être analysés ou utilisés.
S’adapte aux changements de mise en page de Next
Les scrapers qui cassent à chaque mise à jour d’un site sont une vraie galère. Thunderbit comprend le contenu des pages de façon sémantique, et non à l’aide de sélecteurs figés. Lorsque Next modifie sa mise en page, Thunderbit s’adapte automatiquement afin que vous puissiez continuer à extraire des données produits sans interruption.

Pourquoi Thunderbit est-il différent des scrapers Next traditionnels ?
Thunderbit s’adapte aux changements, contrairement aux méthodes d’extraction traditionnelles fragiles.
Scrapers traditionnels
La méthode classiqueThunderbit Ai
L’approche la plus intelligenteNe nous crois pas sur parole
Découvre ce que nos utilisateurs disent de Thunderbit.







Questions fréquentes
Associés cas d’usage
Explore d’autres cas d’usage de l’extracteur web Thunderbit.

Extracteur Pages Blanches
L’Extracteur White Pages de Thunderbit vous permet de collecter rapidement des données issues des annuaires téléphoniques et professionnels White Pages, avec des suggestions de champs intelligentes grâce à l’IA. Rassemblez noms, numéros de téléphone, adresses et sites web pour vos besoins de prospection, de marketing ou de recherche en quelques clics.
En savoir plus ->
Extracteur HKTVmall
Récupérez en quelques clics les noms de produits, les prix et même les notes clients depuis les annonces HKTVmall, sans aucune configuration complexe.
En savoir plus ->
Extracteur United Airlines
Cliquez simplement pour collecter les données de vol United Airlines, comme le numéro de vol, l’heure d’arrivée et l’aéroport de départ — Thunderbit IA s’occupe du reste.
En savoir plus ->Extracteur Substack
Obtenez les nombres d’abonnés Substack, les titres d’articles et les descriptions de publication dans un tableau clair — sans code, l’IA se charge de la structuration.
En savoir plus ->
Extracteur iBegin
L'Extracteur iBegin de Thunderbit vous permet d'extraire les résultats de recherche d'entreprises ainsi que des informations détaillées depuis le site iBegin. Grâce aux suggestions de champs alimentées par l'IA, rassemblez rapidement noms d'entreprises, coordonnées, adresses, notes et bien plus encore pour la génération de leads, la recherche ou l'analyse marketing.
En savoir plus ->
Extracteur de Listes d'Entreprises TripAdvisor
L’Extracteur TripAdvisor de Thunderbit vous permet de collecter des données issues des fiches d’établissements, du centre de ressources et du forum des propriétaires sur TripAdvisor. Grâce aux suggestions intelligentes de champs, rassemblez rapidement noms de ressources, liens, descriptions, sujets de forum, auteurs et contenus de posts pour vos besoins de recherche, de marketing ou d’analyse.
En savoir plus ->Prêt à accélérer l’extraction de tes données ?
Rejoins plus de 100 000 professionnels qui utilisent déjà Thunderbit pour automatiser leurs workflows de web scraping.
L’essai gratuit inclut des crédits illimités pour 8 pages web.