Extracteur IDCrawl
Approuvé par des professionnels dans des entreprises leaders












Des données Idcrawl qui restent exploitables
Utilisez idcrawl pour extraire des données plus vite, plus proprement et à grande échelle avec Thunderbit.
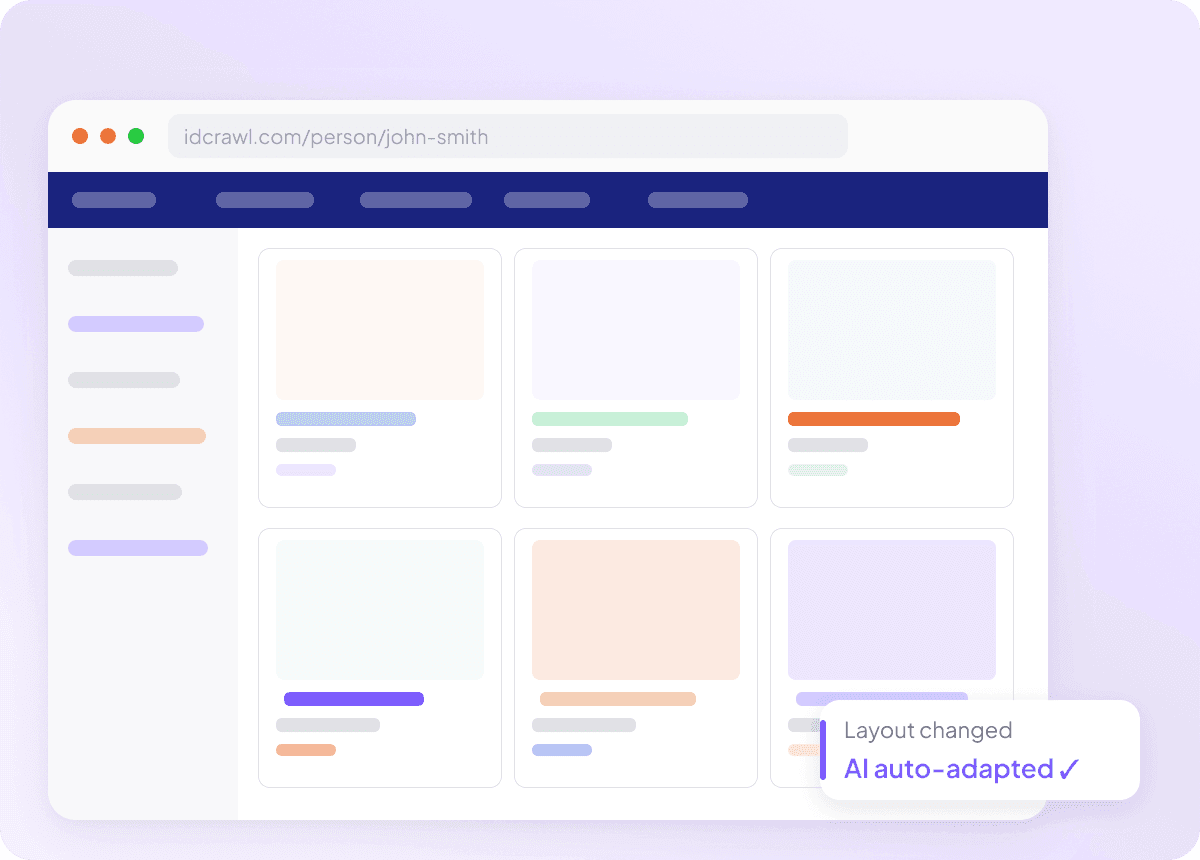
S’adapte lorsque Idcrawl change
Les extracteurs qui cassent à chaque mise à jour du site ne servent à rien, surtout quand vous essayez d’extraire un nom complet, un intitulé de poste, un nom d’entreprise, une adresse e-mail, un numéro de téléphone et un profil LinkedIn depuis idcrawl. Thunderbit lit la page par le sens, et non via des sélecteurs figés, ce qui lui permet de s’adapter lorsque la mise en page change. Vous passez moins de temps à réparer des extracteurs et plus de temps à obtenir les données dont vous avez besoin.
Des données propres dès le départ
Les données brutes ne sont que le début du vrai travail, et les résultats d’idcrawl nécessitent souvent un nettoyage avant d’être utiles. Thunderbit structure et formate les données pendant l’extraction, de sorte que ce que vous exportez est déjà propre et prêt à l’emploi. Cela signifie moins de tri, moins de retouches et une transmission plus fluide à votre équipe.
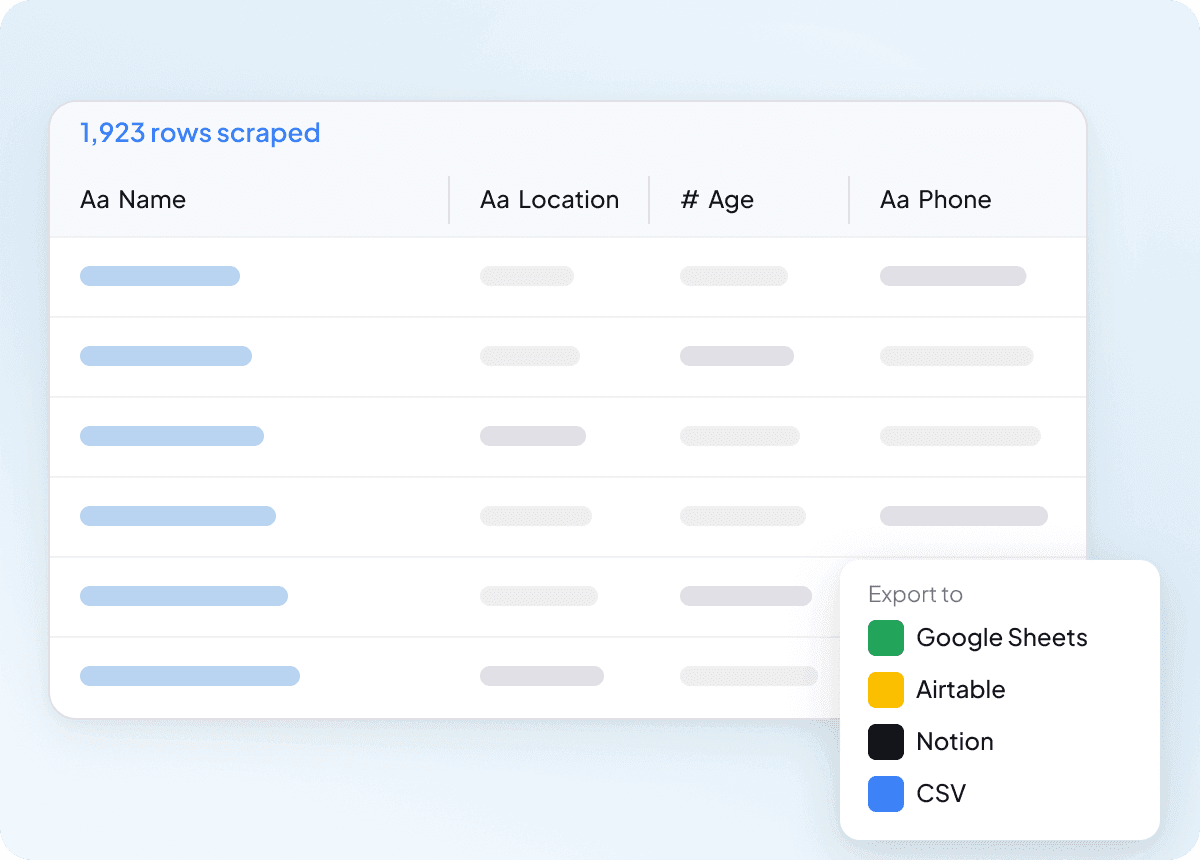
Extraction en masse d’Idcrawl en une seule fois
Extraire une page idcrawl à la fois ne passe pas à l’échelle lorsque vous avez besoin d’une longue liste de contacts. Thunderbit peut extraire en masse des centaines de pages en une seule fois, afin que vous puissiez lui fournir une liste d’URL et en extraire les noms complets, intitulés de poste, noms d’entreprise, adresses e-mail, numéros de téléphone et profils LinkedIn. C’est une bien meilleure façon de transformer une grande liste en données exploitables.

Pourquoi Thunderbit est-il différent des extracteurs idcrawl traditionnels ?
Une façon plus simple d’extraire des données idcrawl sans corrections constantes.
Extracteurs traditionnels
L’ancienne méthodeThunderbit IA
L’approche la plus intelligenteNe nous crois pas sur parole
Découvre ce que nos utilisateurs disent de Thunderbit.







Questions fréquemment posées
Associés cas d’usage
Explore d’autres cas d’usage de l’extracteur web Thunderbit.

Extracteur de Listes d'Entreprises TripAdvisor
L’Extracteur TripAdvisor de Thunderbit vous permet de collecter des données issues des fiches d’établissements, du centre de ressources et du forum des propriétaires sur TripAdvisor. Grâce aux suggestions intelligentes de champs, rassemblez rapidement noms de ressources, liens, descriptions, sujets de forum, auteurs et contenus de posts pour vos besoins de recherche, de marketing ou d’analyse.
En savoir plus ->
Extracteur Pages Blanches
L’Extracteur White Pages de Thunderbit vous permet de collecter rapidement des données issues des annuaires téléphoniques et professionnels White Pages, avec des suggestions de champs intelligentes grâce à l’IA. Rassemblez noms, numéros de téléphone, adresses et sites web pour vos besoins de prospection, de marketing ou de recherche en quelques clics.
En savoir plus ->
Extracteur Amarillas.com
L’Extracteur Amarillas.com de Thunderbit vous permet d’extraire des données structurées depuis Amarillas.com, y compris les listes de motels et de restaurants. Grâce aux suggestions de champs alimentées par l’IA, récupérez rapidement les noms d’entreprises, adresses, numéros de contact, notes et avis pour vos besoins de recherche, de marketing ou de prospection.
En savoir plus ->Extracteur DialIndia
L’Extracteur DialIndia de Thunderbit vous permet de collecter les données des profils d’entreprises et des annuaires de voyage de DialIndia grâce à des suggestions de champs intelligentes par IA. Rassemblez en quelques clics noms d’entreprises, coordonnées, adresses et descriptions pour vos besoins de recherche, de marketing ou de prospection.
En savoir plus ->Extracteur Substack
Obtenez les nombres d’abonnés Substack, les titres d’articles et les descriptions de publication dans un tableau clair — sans code, l’IA se charge de la structuration.
En savoir plus ->
Extracteur United Airlines
Cliquez simplement pour collecter les données de vol United Airlines, comme le numéro de vol, l’heure d’arrivée et l’aéroport de départ — Thunderbit IA s’occupe du reste.
En savoir plus ->Prêt à accélérer l’extraction de tes données ?
Rejoins plus de 100 000 professionnels qui utilisent déjà Thunderbit pour automatiser leurs workflows de web scraping.
L’essai gratuit inclut des crédits illimités pour 8 pages web.