Extracteur Flickr
Approuvé par des professionnels dans des entreprises leaders












Extrayez les données Flickr en deux clics
Thunderbit simplifie l’extraction de données depuis Flickr, sans aucun codage.
Deux clics pour obtenir les données Flickr
Copier manuellement les titres des photos, les noms d’utilisateur des auteurs ou les dates de publication depuis Flickr prend du temps et fatigue vite. Thunderbit vous évite ces copier-coller. Il suffit de pointer les données souhaitées — comme la description de la photo ou le type de licence — et notre IA s’occupe du reste. En deux clics, vous extrayez vos données sans écrire une seule ligne de code.
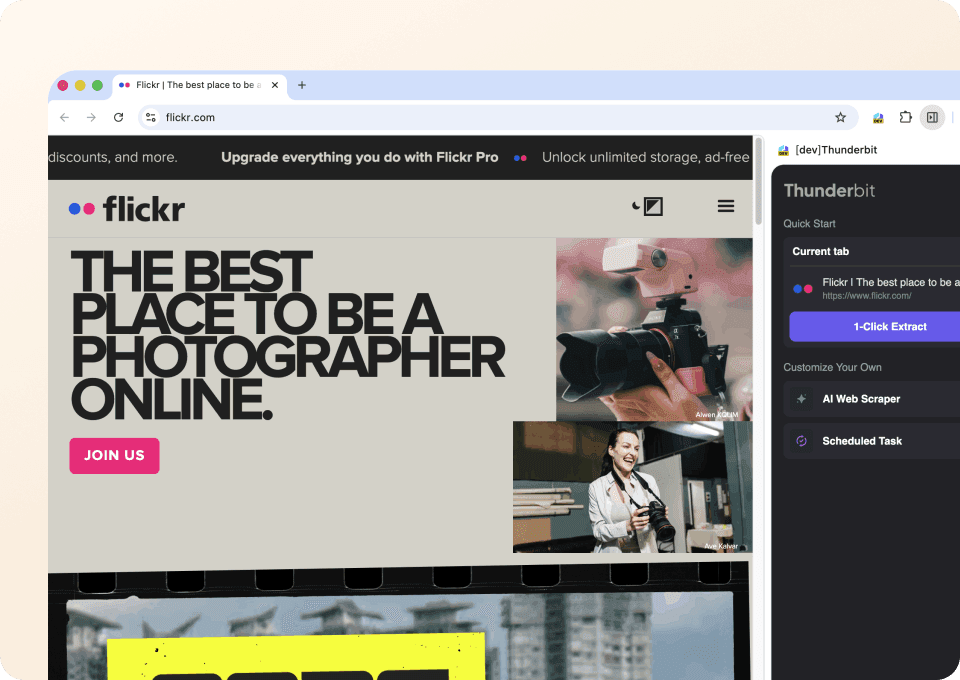
Obtenez tous les détails des photos Flickr
Les pages de recherche ou de galerie Flickr n’affichent que les informations de base. Pour obtenir une vision complète, il faut passer par la page individuelle de chaque photo. Thunderbit peut ouvrir automatiquement chaque sous-page liée, récupérer la description, les tags et d’autres détails, puis les ajouter sous forme de nouvelles colonnes dans votre export de données. Fini le clic-copier manuel sur chaque page.
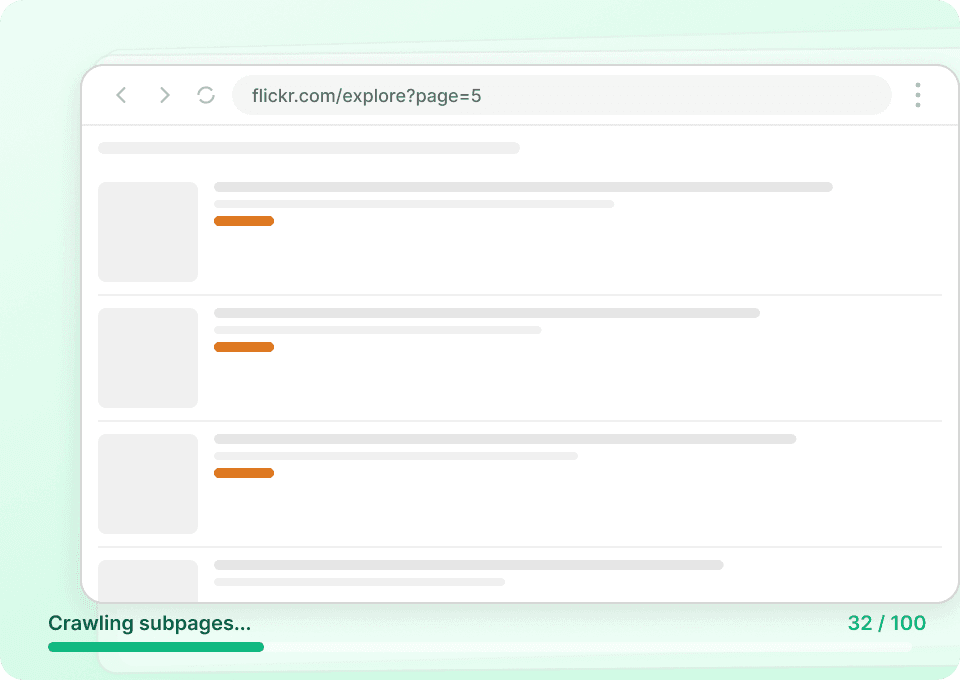
Extraction en masse des données Flickr
Extraire Flickr photo par photo est lent et peu pratique. Au lieu de naviguer manuellement sur chaque page et d’en extraire les données une par une, Thunderbit vous permet d’ajouter plusieurs URLs Flickr. L’outil visite ensuite chaque page, extrait le titre de la photo, le nom d’utilisateur de l’auteur et d’autres informations, puis regroupe le tout pour vous.

Pourquoi Thunderbit est-il différent des extracteurs Flickr traditionnels ?
Extrayez les données de Flickr sans les tracas du scraping traditionnel.
Extracteurs traditionnels
L’ancienne méthodeThunderbit IA
L’approche la plus intelligenteNe nous crois pas sur parole
Découvre ce que nos utilisateurs disent de Thunderbit.





Questions fréquentes
Associés cas d’usage
Explore d’autres cas d’usage de l’extracteur web Thunderbit.

Extracteur Amarillas.com
L’Extracteur Amarillas.com de Thunderbit vous permet d’extraire des données structurées depuis Amarillas.com, y compris les listes de motels et de restaurants. Grâce aux suggestions de champs alimentées par l’IA, récupérez rapidement les noms d’entreprises, adresses, numéros de contact, notes et avis pour vos besoins de recherche, de marketing ou de prospection.
En savoir plus ->
Extracteur HKTVmall
Récupérez en quelques clics les noms de produits, les prix et même les notes clients depuis les annonces HKTVmall, sans aucune configuration complexe.
En savoir plus ->Extracteur On the Beach
L’Extracteur On the Beach de Thunderbit vous permet d’extraire en quelques secondes les offres de vacances, les hôtels, les prix, les avis et bien plus encore depuis On the Beach. Profitez des suggestions intelligentes de champs pour collecter et organiser rapidement vos données de voyage, que ce soit pour l’analyse, la comparaison ou la planification. Parfait pour les professionnels du tourisme, les analystes et les organisateurs de séjours.
En savoir plus ->
Extracteur UpCity
L’Extracteur UpCity de Thunderbit vous permet de récupérer les données des listes d’agences publicitaires et des avis de prestataires sur UpCity. Grâce aux suggestions de champs intelligentes par IA, collectez rapidement noms d’agences, localisations, évaluations, coordonnées et avis détaillés pour vos analyses ou recherches. Parfait pour les marketeurs, chercheurs et entrepreneurs souhaitant obtenir des données structurées d’UpCity.
En savoir plus ->
Extracteur Pages Blanches
L’Extracteur White Pages de Thunderbit vous permet de collecter rapidement des données issues des annuaires téléphoniques et professionnels White Pages, avec des suggestions de champs intelligentes grâce à l’IA. Rassemblez noms, numéros de téléphone, adresses et sites web pour vos besoins de prospection, de marketing ou de recherche en quelques clics.
En savoir plus ->
Extracteur UNIQLO
Collectez en quelques clics les données produits UNIQLO, comme les noms, les prix et les tailles disponibles, grâce à l’extension Chrome de Thunderbit.
En savoir plus ->Prêt à accélérer l’extraction de tes données ?
Rejoins plus de 100 000 professionnels qui utilisent déjà Thunderbit pour automatiser leurs workflows de web scraping.
L’essai gratuit inclut des crédits illimités pour 8 pages web.