Internet regorge de données, mais la plupart ne sont pas directement utilisables. Si tu as déjà essayé de copier les prix d’un concurrent, de te faire une liste de prospects à partir d’un annuaire en ligne ou de surveiller les nouveautés chez tes rivaux, tu sais à quel point c’est galère : c’est lent, répétitif et tu risques de faire des erreurs. C’est là que les extracteurs web entrent en jeu, devenant l’arme secrète des équipes commerciales, marketing et opérationnelles.
En fait, près de utilisent aujourd’hui des outils d’extraction de données ou de web scraping au quotidien. Que ce soit pour surveiller la concurrence, générer des leads ou analyser le marché, les extracteurs web sont passés du statut de gadget technique à celui d’outil indispensable. Mais alors, qu’est-ce qu’un extracteur web exactement ? Comment ça marche ? Et surtout, comment s’en servir sans être un as de l’informatique ? On va voir ça ensemble, étape par étape.
Qu’est-ce qu’un extracteur web ? Explication simple
 Un extracteur web est un logiciel (ou parfois un script) qui va automatiquement récupérer des infos sur des sites internet. Imagine-le comme un assistant robot super rapide et infatigable : au lieu de copier-coller à la main des données d’une page web vers un tableur, l’extracteur s’en occupe pour toi, en un temps record et sans se tromper. C’est comme avoir un stagiaire qui ne dort jamais, ne râle pas et ne demande jamais d’augmentation.
Un extracteur web est un logiciel (ou parfois un script) qui va automatiquement récupérer des infos sur des sites internet. Imagine-le comme un assistant robot super rapide et infatigable : au lieu de copier-coller à la main des données d’une page web vers un tableur, l’extracteur s’en occupe pour toi, en un temps record et sans se tromper. C’est comme avoir un stagiaire qui ne dort jamais, ne râle pas et ne demande jamais d’augmentation.
Pour que ce soit plus clair, voilà comment les extracteurs s’intègrent dans le monde de l’automatisation :
- Bot : Tout programme automatisé qui fait des tâches sur internet. Les extracteurs web sont une catégorie de bots.
- Crawler : Un bot qui parcourt le web, suit les liens et indexe les pages (comme Google le fait).
- Extracteur web : Un bot spécialisé dans l’extraction de données précises à partir de pages web, qui transforme un contenu en vrac en tableaux bien rangés.
Si le web est une immense bibliothèque, le crawler est le bibliothécaire qui recense tous les livres, alors que l’extracteur web est l’assistant qui recopie pour toi les infos qui t’intéressent dans ton carnet.
Les extracteurs web ne sont pas réservés aux geeks ou aux hackers. Ils servent à plein d’usages pros très légitimes : comparer les prix, collecter des données publiques pour la recherche, surveiller la concurrence, etc. L’essentiel, c’est qu’un extracteur transforme des données web faites pour les humains en infos structurées, prêtes à être exploitées par les ordinateurs (et les équipes métier).
Comment fonctionne un extracteur web ? Du site à la donnée structurée
On va démystifier le truc. Au fond, un extracteur web suit un déroulé très proche de ce que ferait un humain, mais à une vitesse de dingue :
- Point de départ : Tu indiques à l’extracteur la ou les pages web à viser (en général via des URLs).
- Chargement de la page : L’extracteur charge le contenu de la page, comme ton navigateur. Pour les sites plus complexes, il peut même « rendre » la page pour gérer le contenu dynamique ou le scroll infini.
- Analyse et détection des données : L’extracteur lit le code HTML de la page et repère les éléments à extraire (noms de produits, prix, emails, etc.). Sur les extracteurs classiques, tu dois lui dire où chercher (avec des « sélecteurs » ou des motifs). Les extracteurs IA modernes détectent souvent ça tout seuls.
- Extraction : Une fois les données repérées, l’extracteur les récupère : texte, chiffres, liens, images… Il peut aussi nettoyer ou transformer les données (par exemple, convertir « 19,99 € » en nombre).
- Itération : Besoin de données sur plusieurs pages ? L’extracteur peut suivre les liens, gérer la pagination ou traiter une liste d’URLs automatiquement.
- Export : Enfin, l’extracteur exporte les résultats dans un format structuré : CSV, Excel, Google Sheets ou base de données. Tu obtiens un tableau de données prêtes à l’emploi.
En résumé : visiter la page → repérer l’info → extraire → répéter → exporter. Ce qui prendrait des jours à un humain se fait en quelques minutes ou heures avec un bon extracteur web.
Les composants clés d’un extracteur web
On peut découper ça en plusieurs briques :
- Navigateur/Crawler : Il trouve et charge les pages à extraire. Il gère la pagination, suit les liens ou traite une liste d’URLs.
- Parseur/Extracteur : Il lit le HTML et repère les données à extraire, via des règles, des motifs ou l’IA.
- Nettoyeur de données : Il met en forme et structure les données (enlève les balises HTML, uniformise les formats, etc.).
- Exportateur : Il sauvegarde les résultats dans un fichier, un tableur ou une base de données, prêts à être utilisés.
Certains extracteurs sont de simples scripts, d’autres de vraies plateformes complètes. Mais le principe reste toujours : trouver, extraire, structurer, exporter.
Types d’extracteurs web : codés ou assistés par l’IA
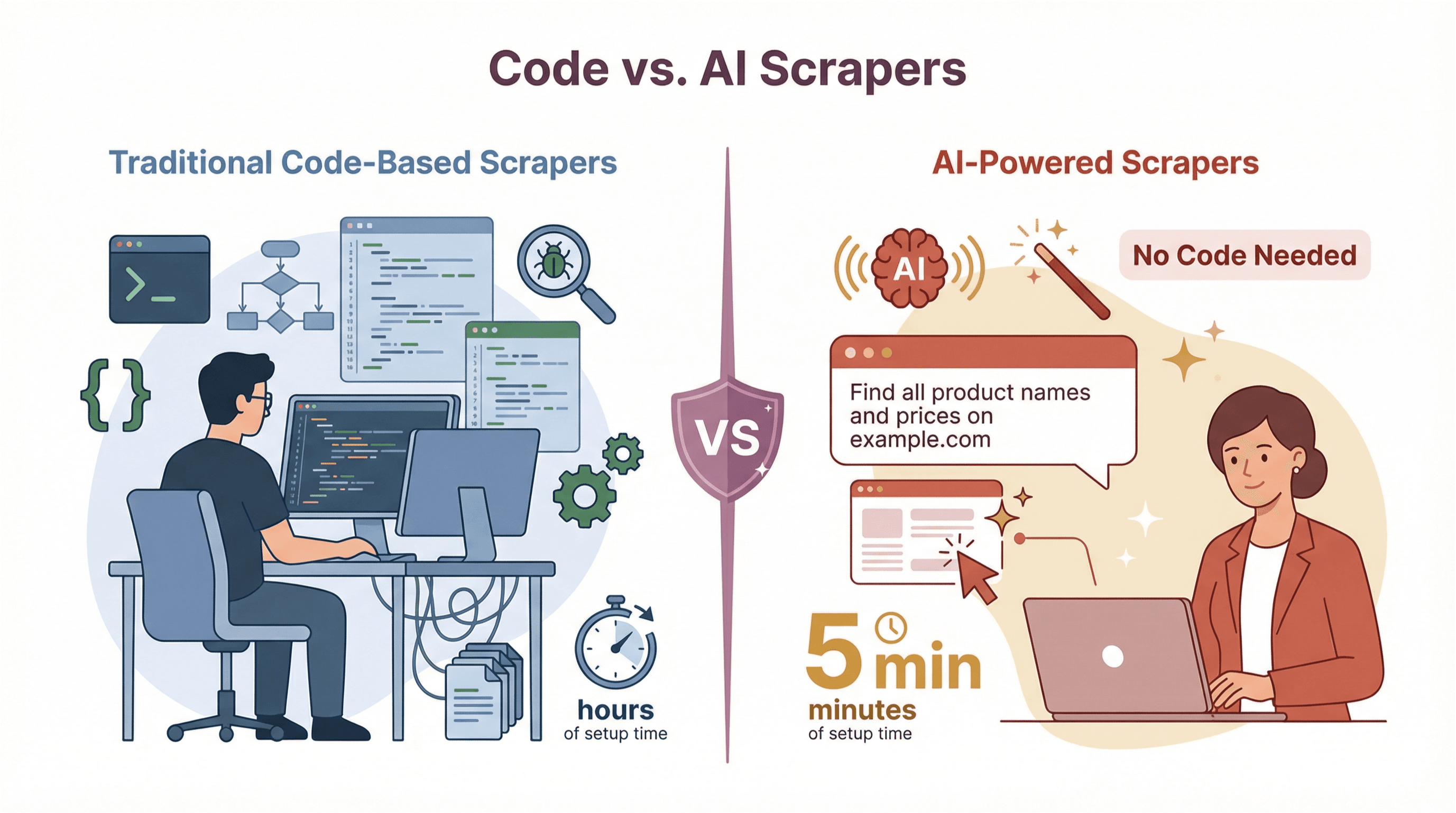 Tous les extracteurs web ne se valent pas. On distingue deux grandes familles :
Tous les extracteurs web ne se valent pas. On distingue deux grandes familles :
Extracteurs traditionnels (basés sur le code)
Ce sont les pionniers du web scraping. Il faut programmer, souvent en Python, JavaScript ou un autre langage de script. Toi (ou ton développeur) écris le code pour dire à l’extracteur quoi faire : quelles pages visiter, quels éléments HTML cibler, comment gérer la pagination, etc.
Avantages :
- Flexibilité maximale : tu peux t’adapter à presque tous les sites ou structures de données.
- Idéal pour les projets sur-mesure, complexes ou à grande échelle.
Inconvénients :
- Barrière technique élevée : il faut savoir coder.
- Fragile : le script casse facilement si la structure du site change.
- Maintenance importante : il faut souvent mettre à jour les scripts.
Extracteurs no-code et assistés par l’IA
Bienvenue dans l’ère moderne. Ces outils sont pensés pour les utilisateurs métier, pas les développeurs. Certains proposent des interfaces visuelles (point-and-click), tandis que la nouvelle génération – comme – s’appuie sur l’IA pour deviner quoi extraire, souvent à partir d’une simple consigne en français.
Avantages :
- Aucun code requis : tout le monde peut s’en servir.
- Mise en place ultra-rapide : opérationnel en quelques minutes.
- Adaptatif : l’IA gère les changements de structure et le contenu dynamique.
- Peu de maintenance : moins de temps perdu à réparer les extracteurs.
Inconvénients :
- Moins personnalisable pour des besoins très spécifiques.
- Parfois limité par les fonctionnalités de l’outil (mais l’écart se réduit vite).
Tableau comparatif : extracteurs codés vs. extracteurs IA
| Aspect | Extracteurs codés | Extracteurs IA/No-Code |
|---|---|---|
| Facilité d’utilisation | Nécessite de programmer | Aucun code requis |
| Vitesse de mise en place | Heures ou jours | Quelques minutes |
| Adaptabilité | Fragile – casse si le site change | Adaptatif – l’IA gère les changements |
| Maintenance | Élevée – mises à jour fréquentes | Faible – l’IA s’auto-adapte |
| Gestion du contenu dynamique | Outils supplémentaires nécessaires (ex : Selenium) | IA intégrée gère JS, scroll infini |
| Précision des données | Dépend de la configuration manuelle | Élevée – extraction contextuelle |
| Scalabilité | Scripts personnalisés pour passer à l’échelle | Scalabilité cloud intégrée |
| Export/Intégration | Sortie à coder manuellement | Export en un clic vers Sheets, Excel… |
| Coût | Outils gratuits mais coût humain élevé | Abonnement SaaS, souvent avec version gratuite |
Pour la majorité des pros, les extracteurs IA sont un vrai bond en avant : plus rapides, plus simples et plus fiables pour les tâches courantes.
Quand choisir chaque type d’extracteur ?
- Opte pour le code si tu as des besoins très spécifiques et un développeur sous la main.
- Choisis l’IA/no-code si tu veux démarrer vite, sans compétences techniques, ou extraire des données de plein de sites différents avec un minimum de configuration.
Pour la plupart des équipes commerciales, marketing ou opérationnelles, les outils IA comme Thunderbit sont la solution idéale.
Thunderbit : l’extracteur web repensé pour les pros
Voyons comment simplifie la vie des utilisateurs (et ce n’est pas juste du marketing !). Extension Chrome d’extraction web boostée à l’IA, Thunderbit s’adresse à ceux qui veulent des résultats sans prise de tête.
Ce qui fait la différence avec Thunderbit :
- Suggestion de champs par l’IA : Un clic, et l’IA de Thunderbit analyse la page et propose les colonnes à extraire (nom, prix, email, etc.). Plus besoin de toucher au HTML ou aux sélecteurs.
- Extraction en 2 clics : Après la suggestion, clique sur « Extraire » : Thunderbit récupère les données et les affiche dans un tableau prêt à l’export.
- Extraction de sous-pages & pagination : Besoin de détails ? Thunderbit visite automatiquement chaque sous-page (fiche produit, profil LinkedIn…) et enrichit ton tableau. Il gère aussi la pagination et le scroll infini.
- Mode cloud ou navigateur : Extrais dans ton navigateur (pratique pour les sites nécessitant une connexion) ou délègue au cloud Thunderbit (ultra-rapide pour les sites publics).
- Modèles instantanés : Pour les sites populaires (Amazon, Zillow, Instagram…), Thunderbit propose des modèles prêts à l’emploi : charge, extrais.
- Export gratuit et illimité : Exporte tes données vers Excel, Google Sheets, Airtable, Notion ou télécharge-les en CSV/JSON – même en version gratuite.
- Auto-remplissage IA : Automatise le remplissage de formulaires et les tâches web répétitives – aussi gratuit.
- Extraction programmée : Planifie tes extractions (ex : chaque matin) et laisse l’IA gérer le timing.
- Extracteurs spécialisés : Outils en un clic pour extraire emails, numéros de téléphone ou images – parfait pour les besoins rapides.
- Support multilingue : Thunderbit fonctionne dans 34 langues, pour extraire des données du monde entier.
Thunderbit est déjà adopté par , des freelances aux grandes équipes. C’est l’outil que j’aurais rêvé d’avoir quand je passais mes journées à copier-coller des données.
Les atouts clés de Thunderbit pour les pros
Voici la vraie valeur ajoutée de ses fonctionnalités phares :
- Suggestion IA de champs : Gagne des heures de configuration – un clic suffit.
- Extraction de sous-pages : Récupère des données enrichies (spécifications, contacts…) sans effort.
- Mode cloud ou navigateur : Flexibilité pour tous les types de sites (publics ou nécessitant une connexion).
- Modèles instantanés : Extraction en un clic sur les sites courants – aucune configuration.
- Export gratuit : Récupère tes données où tu veux, sans frais cachés.
Pour aller plus loin, jette un œil à la ou à notre .
Cas d’usage concrets : comment les entreprises utilisent les extracteurs web
Les extracteurs web ne sont pas réservés aux experts de la donnée : ils apportent des résultats concrets dans tous les secteurs. Voici quelques exemples :
| Secteur/Fonction | Cas d’usage de l’extracteur | Bénéfice métier |
|---|---|---|
| Vente & Prospection | Extraire des leads depuis des annuaires, enrichir le CRM | Listes de prospects plus larges et fraîches, prospection accélérée |
| Marketing | Extraire des articles concurrents, avis, tendances sociales | Campagnes pilotées par la donnée, veille concurrentielle |
| E-commerce | Surveiller les prix concurrents, mettre à jour le catalogue | Tarification dynamique, assortiment optimisé |
| Immobilier | Agréger les annonces, analyser les tendances du marché | Analyse plus rapide, meilleures opportunités |
| Finance/Investissement | Extraire actualités, dépôts, données alternatives | Avantage informationnel, analyses élargies |
| Recherche/Journalisme | Compiler des données publiques, analyser des tendances | Échantillons plus larges, analyses approfondies |
Focus sur la vente, le marketing et l’e-commerce
Vente :
Une équipe commerciale a besoin d’une liste de magasins dans sa région. Plutôt que de chercher à la main, elle utilise Thunderbit pour extraire un annuaire en ligne – noms, adresses, téléphones, tout est prêt dans un tableur en quelques minutes. Elle utilise même l’extraction de sous-pages pour récupérer les emails des propriétaires.
Marketing :
Un responsable marketing veut suivre les sujets de blog de ses concurrents et l’avis des clients. Thunderbit extrait les titres et dates des articles concurrents, ainsi que les avis ou tweets mentionnant la marque. L’équipe repère une tendance : 30 % des avis concurrents parlent d’un mauvais support – elle lance alors une campagne axée sur la qualité de son service client.
E-commerce :
Un responsable e-commerce configure Thunderbit pour surveiller les prix de 100 produits concurrents, extraction toutes les 6 heures. Il repère vite les écarts de prix et ajuste en conséquence, ce qui booste les ventes. Il extrait aussi les catalogues fournisseurs pour garder son offre à jour.
Le point commun ? Gain de temps, données plus fiables, décisions plus avisées.
Valeur stratégique et conformité : utiliser les extracteurs web de façon responsable
Avec la puissance de l’extraction vient la responsabilité (et quelques questions juridiques). Voici ce que les pros doivent garder en tête :
- Protection des données : Si tu extrais des données personnelles (emails, profils sociaux…), respecte les lois comme le RGPD ou le CCPA. Limite-toi aux infos publiques et non sensibles, sauf base légale claire.
- Conditions d’utilisation des sites : Beaucoup de sites interdisent l’extraction. Les tribunaux ont parfois donné raison aux extracteurs (surtout pour les données publiques), mais il vaut mieux vérifier les conditions et agir avec discernement.
- robots.txt : Ce fichier indique aux bots les zones autorisées. Ce n’est pas une loi, mais c’est une question de respect.
- Limitation de fréquence : N’inonde pas les sites – extrais à un rythme humain, sans surcharger les serveurs.
- Droits d’auteur : Extraire des données factuelles (prix, spécifications) est différent de republier des contenus entiers. Reste sur les faits, pas sur les contenus propriétaires.
Bonnes pratiques :
- Utilise les API officielles si elles existent.
- Vérifie robots.txt et les conditions d’utilisation.
- Limite-toi aux données publiques et non sensibles.
- Stocke les données extraites de façon sécurisée.
- Demande conseil pour les projets sensibles ou à grande échelle.
Pour en savoir plus, consulte le .
Choisir le bon extracteur web pour ton entreprise
Pour choisir un extracteur web, pose-toi les bonnes questions :
- Facilité d’utilisation : Ton équipe peut-elle l’utiliser sans coder ?
- Scalabilité : Peut-il gérer ton volume de données ?
- Adaptabilité : Résiste-t-il aux changements de sites ?
- Intégration : Peut-on exporter les données où on veut ?
- Conformité : L’outil aide-t-il à rester dans les clous ?
- Support : L’assistance est-elle dispo si besoin ?
- Coût : Le tarif colle-t-il à tes besoins et ton budget ?
Un tableau pour t’aider à décider :
| Besoin/Scénario | Type d’outil recommandé |
|---|---|
| Pas de compétences techniques, mise en place rapide | IA/no-code (Thunderbit) |
| Projet sur-mesure, complexe ou massif | Basé sur le code (Python, Scrapy) |
| Changements fréquents de sites | IA/no-code |
| Automatisation à grande échelle | Outils cloud, scalables |
| Exigences fortes de conformité | Outils avec fonctions de conformité |
Teste l’outil sur un projet pilote pour vérifier qu’il colle à tes besoins réels avant de le déployer à grande échelle.
Conclusion : l’avenir des extracteurs web dans l’automatisation des données
Les extracteurs web sont devenus un pilier de l’automatisation en entreprise. Ils ouvrent l’accès à la richesse cachée du web et transforment ces données en infos exploitables pour la vente, le marketing, l’e-commerce et bien plus. L’essor des outils IA comme permet à tout le monde – pas seulement aux développeurs – de profiter de cette puissance, souvent en quelques clics.
À mesure que le web se complexifie et que la prise de décision pilotée par la donnée devient la norme, les extracteurs web seront de plus en plus intelligents, rapides et intégrés au quotidien. Demain, ils ne seront plus de simples collecteurs, mais de vrais assistants IA, capables de résumer, catégoriser et livrer des insights en temps réel.
Tu n’as pas encore testé un extracteur moderne ? C’est le moment. Commence petit, respecte la conformité, et découvre tout ce que tu peux accomplir avec la donnée web à portée de main. Pour aller plus loin, explore le pour des guides, astuces et retours d’expérience.
FAQ
1. Quelle est la différence entre un extracteur web et un crawler ?
Un crawler parcourt le web pour découvrir et indexer les pages (comme un moteur de recherche). Un extracteur web se concentre sur l’extraction de données précises à partir de ces pages. Beaucoup d’extracteurs intègrent des fonctions de crawling, mais tous les crawlers ne sont pas des extracteurs.
2. Le web scraping est-il légal ?
L’extraction de données est légale si elle est pratiquée de façon responsable : limite-toi aux données publiques, respecte la vie privée et les conditions d’utilisation des sites. Évite d’extraire des infos sensibles ou protégées sans autorisation.
3. Faut-il savoir coder pour utiliser un extracteur web ?
Plus maintenant ! Les outils IA modernes comme permettent d’extraire des données sans coder, en quelques clics ou via une consigne en langage naturel.
4. Quelles données peut-on extraire avec un extracteur web ?
Tu peux extraire du texte, des chiffres, des prix, des emails, des images, des liens, etc. Certains extracteurs gèrent même les PDF, les images ou les sous-pages pour des données plus riches.
5. Comment choisir le bon extracteur web pour mon entreprise ?
Prends en compte les compétences de ton équipe, la complexité des sites ciblés, le volume de données, les exigences de conformité et les besoins d’intégration. Pour la plupart des pros, les outils IA comme Thunderbit offrent le meilleur compromis entre simplicité, rapidité et fiabilité.
Prêt à voir ce qu’un extracteur moderne peut faire ? et commence à transformer la donnée web en résultats concrets – sans coder.
Pour aller plus loin