

Imaginez la scène : vous lancez votre site, prêt à accueillir une foule de clients impatients, et vous réalisez que la moitié de votre trafic, c’est… des robots. Pas ceux de la science-fiction, mais des crawlers numériques — moteurs de recherche, bots IA, spiders d’analyse — qui arpentent votre site jour et nuit, tel un défilé sans fin d’invités invisibles. En 2026, ce n’est plus une anecdote rigolote au fond des logs serveur : c’est devenu la norme. Savoir qui — ou quoi — crawle votre site, à quelle fréquence et pour quelles raisons est désormais un enjeu central de toute activité en ligne.
Après des années passées dans le SaaS, l’automatisation et l’IA, j’ai vu le web crawling passer du statut de détail technique en coulisses à celui de véritable sujet stratégique. Les chiffres ont de quoi donner le tournis : les bots pèsent aujourd’hui près de la moitié du trafic internet et, dans certains cas, dépassent les humains. Avec la montée des crawlers pilotés par l’IA qui aspirent du contenu pour entraîner de grands modèles de langage, les enjeux n’ont jamais été aussi forts — pour votre infrastructure, votre budget et votre marque. Voyons ensemble les dernières statistiques sur le web crawling, les références sectorielles et ce que tout cela implique pour votre entreprise en 2026.
Le web crawling en 2026 : aperçu du paysage
Extraire des données de n’importe quel site avec l’IA Get Started Free
Le web crawling a changé d’échelle, en volume comme en complexité. Chaque jour, des milliards de requêtes automatisées sillonnent Internet, portées par une population de crawlers toujours plus dense. Historiquement, les bots des moteurs de recherche comme Googlebot et Bingbot tenaient le haut de l’affiche en indexant les pages pour que les internautes les retrouvent dans les résultats. Aujourd’hui, une nouvelle génération les a rejoints : crawlers de données IA, scrapers pour les réseaux sociaux, bots d’analyse, et bien d’autres.
Voici le chiffre clé — et il varie selon la source retenue. Le Year in Review 2025 de Cloudflare indiquait que les bots et les crawlers IA pesaient ensemble environ 53 % des requêtes HTML sur son réseau début décembre 2025, contre 47 % de trafic humain. De son côté, Imperva, en observant sa clientèle entreprise dans le Bad Bot Report 2026 (publié le 29 avril 2026), aboutit au même constat pour l’année civile 2025 : 53 % de bots, 47 % d’humains, contre 51/49 l’année précédente. Deux angles distincts, une même conclusion : le trafic automatisé représente désormais plus de la moitié du Web. Et ce qui bouge, ce n’est pas seulement le volume, mais aussi les acteurs en présence. Les indexeurs de recherche dominaient autrefois la colonne des bots. En 2026, une part grandissante revient aux crawlers d’entraînement IA qui nourrissent chatbots et moteurs de réponse.
Le paysage est plus varié que jamais :
- Les bons bots : indexeurs de recherche, outils de surveillance de disponibilité, scrapers de données légitimes.
- Les mauvais bots : spam, piratage, scraping non autorisé.
- Les crawlers IA : les petits nouveaux, qui collectent du contenu pour entraîner les IA et fournir des réponses en temps réel.
Les crawlers IA se comportent souvent autrement que leurs cousins des moteurs de recherche. Ils peuvent aspirer le contenu intégral des pages pour une analyse sémantique — et pas seulement indexer des mots-clés — et ils opèrent généralement à très grande échelle, au point de submerger certains sites de millions de requêtes en quelques jours. Bilan ? Le web crawling est aujourd’hui omniprésent, en pleine croissance et de plus en plus diversifié, entre indexation traditionnelle et appétit insatiable de l’IA pour les données.
Les statistiques clés du web crawling que toute entreprise devrait connaître
Place aux chiffres qui façonnent le Web en 2026. Ces données ne servent pas qu’à alimenter les conversations : ce sont des repères qui devraient guider votre infrastructure, votre stratégie de contenu et votre rentabilité.
Bots contre humains : qui remporte la bataille du trafic ?
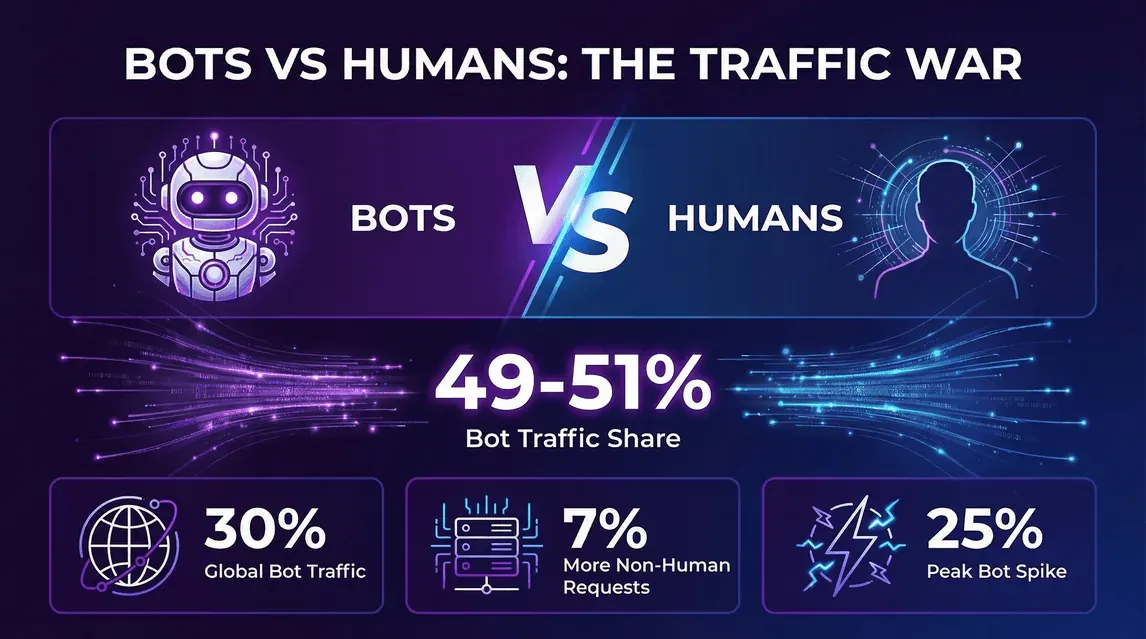
- Imperva, Bad Bot Report 2026 (avril 2026) : le trafic automatisé a atteint 53 % de l’ensemble du trafic web en 2025, contre 51 % en 2024. Le trafic humain est donc tombé de 49 % à 47 %.
- Cloudflare, Year in Review 2025 : au 2 décembre 2025, 47 % des requêtes HTML sur le réseau de Cloudflare provenaient d’êtres humains, 44 % de bots non IA, et environ 9 % de plus de bots IA et de Googlebot combinés.
- La tendance ne tient pas à un simple trimestre : Imperva montre une progression de la part des bots chaque année depuis 2019, et le bond entre 2024 et 2025 tient surtout aux crawlers d’entraînement IA, et non au cocktail habituel de scraping et de credential stuffing.
- Ce que cela change pour les propriétaires de sites : si vos analyses n’écartent pas les bots, environ la moitié de vos requêtes brutes ne provient pas d’une personne. Dimensionner l’infrastructure à partir des logs bruts sans segmenter les bots vous fera surestimer vos besoins — et sous-dimensionner la capacité dédiée aux bots pénalisera l’autre moitié, celle qui, elle, EST humaine.
L’envolée des crawlers IA
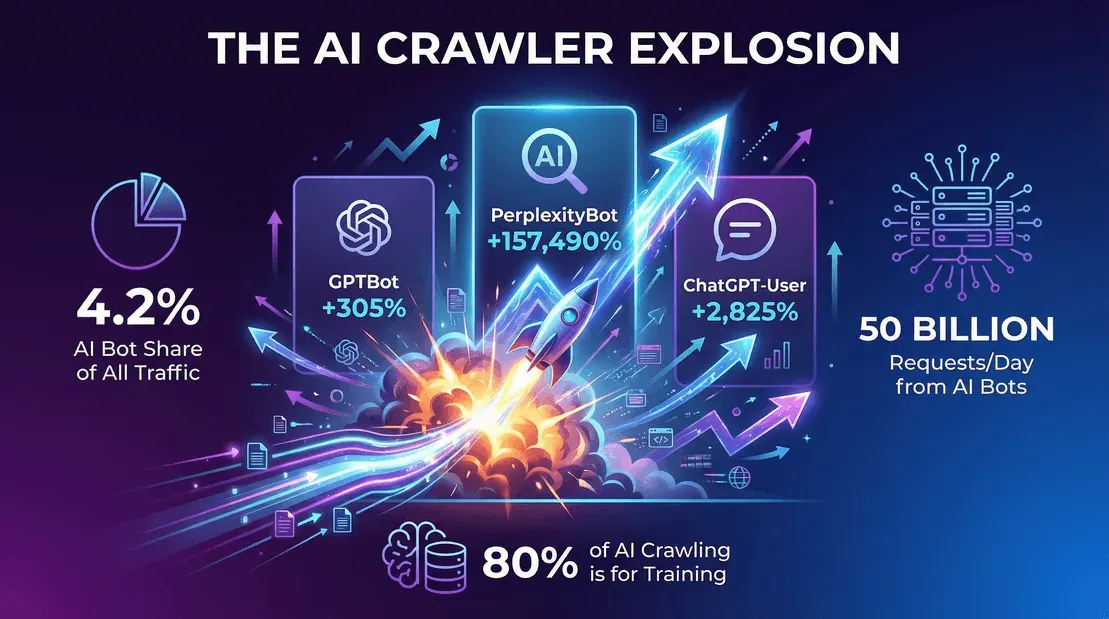
- La part de trafic des bots IA poursuit sa hausse. D’après le Year in Review 2025 de Cloudflare, les bots IA (hors Googlebot) pesaient environ 4,2 % des requêtes HTML fin 2025, Googlebot comptant à lui seul pour 4,5 % de plus. Une catégorie quasi inexistante il y a trois ans atteint désormais presque la taille de Googlebot.
- GPTBot d’OpenAI est passé de 7,7 % des requêtes de crawlers en mai 2025 à 3,6 % des requêtes sur pages uniques fin 2025 (Cloudflare YIR 2025) — le pourcentage semble plus faible, mais c’est parce que Cloudflare a changé de dénominateur pour les pages uniques et parce que le secteur s’est densifié. En volume brut, GPTBot reste l’un des trois premiers crawlers IA du Web ouvert.
- ClaudeBot d’Anthropic se place aux côtés de Meta-ExternalAgent, autour de 2,4 % des requêtes sur pages uniques fin 2025. La part relative de ClaudeBot a reculé d’une année sur l’autre (baisse de 46 % sur la fenêtre mai 2024–mai 2025 de Cloudflare) avant de rebondir avec l’intensification de l’entraînement chez Anthropic.
- PerplexityBot demeure minuscule en volume absolu — environ 0,06 % des requêtes sur pages uniques fin 2025 — mais affiche la plus forte trajectoire de croissance parmi les grands bots IA.
- Googlebot reste de loin le plus grand crawler du Web ouvert. Le Year in Review de Cloudflare le situe à environ 200 fois le volume de pages uniques de PerplexityBot.
Le trafic des crawlers remis en contexte
Voici un cas réel tiré d’un fil Reddit de fin 2025 — un développeur qui a passé au crible 30 jours de logs serveur :
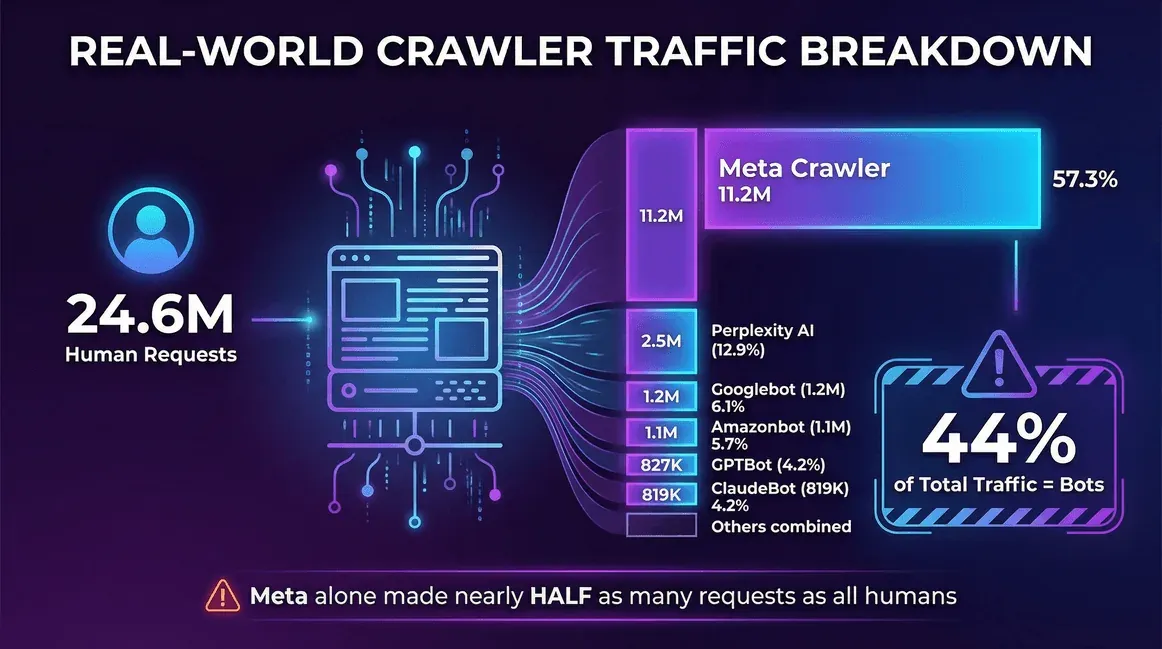
| Source du trafic | Requêtes (mensuelles) | Part des crawlers |
|---|---|---|
| Utilisateurs réels (humains) | 24,647,904 | -- |
| Meta Crawler (Facebook) | 11,175,701 | 57,3 % |
| Perplexity AI | 2,512,747 | 12,9 % |
| Googlebot | 1,180,737 | 6,1 % |
| Amazonbot | 1,120,382 | 5,7 % |
| OpenAI GPTBot | 827,204 | 4,2 % |
| ClaudeBot (Anthropic) | 819,256 | 4,2 % |
| Bingbot | 599,752 | 3,1 % |
| ChatGPT-User (OpenAI) | 557,511 | 2,9 % |
| Ahrefs Crawler | 449,161 | 2,3 % |
| ByteDance Spider | 267,393 | 1,4 % |
Sur ce site, les bots représentaient 44 % du trafic total — et le seul crawler de Meta a généré presque autant de requêtes que l’ensemble des vrais utilisateurs réunis.
Vue d’ensemble
- Le trafic des crawlers (moteurs de recherche + bots IA) a progressé de 18 % entre mai 2024 et mai 2025 sur un ensemble de sites constant (blog.cloudflare.com).
- Les bots d’entraînement pour les LLM représentaient près de 80 % de tout le trafic « bot » sur certains grands CDN (webscraft.org).
- Le réseau de Cloudflare a enregistré environ 50 milliards de requêtes de crawlers par jour pour les seuls bots IA fin 2025 (webscraft.org).
L’essor des crawlers IA : comment l’IA transforme le web crawling
Venons-en au sujet que tout le monde a en tête — ou plutôt au robot : les crawlers IA. Ces bots ne se contentent pas d’indexer votre site pour la recherche ; ils engloutissent du contenu pour entraîner de grands modèles de langage ou produire des réponses instantanées générées par l’IA. Et à une échelle qui ferait pâlir le plus ambitieux des moteurs de recherche.
Qu’est-ce qui alimente l’explosion des crawlers IA ?
- Des modèles d’IA assoiffés de données : les LLM modernes réclament des jeux de données immenses et variés. Le Web est leur buffet, et votre contenu figure au menu.
- Entraînement vs réponses en temps réel : environ 80 % du crawling des bots IA sert à l’entraînement, pas seulement à répondre aux requêtes en direct.
- De nouveaux schémas de crawl : les bots IA peuvent frapper un site par rafales massives, en parcourant parfois des millions de pages en quelques jours, notamment lors d’un réentraînement ou d’une mise à jour des modèles.
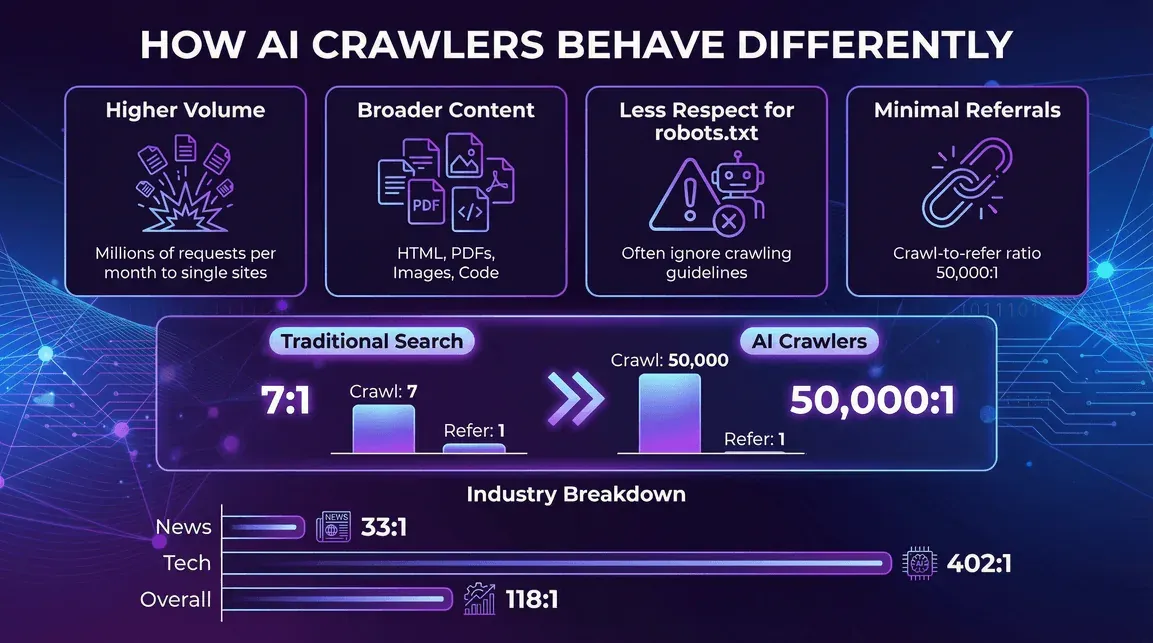
En quoi les crawlers IA se comportent-ils différemment ?
- Un volume par crawler plus élevé : un seul bot IA peut générer des millions de requêtes par mois sur un même site (exemple Reddit).
- Des types de contenu plus divers : pas uniquement du HTML — PDF, images, code, et tout le reste.
- Moins d’égard pour robots.txt : certains crawlers IA ignorent les consignes de crawl, ou ne les respectent qu’en partie (blog.cloudflare.com).
- Très peu de trafic de référence. C’est le point qui devrait le plus alarmer les éditeurs. L’analyse crawl-to-click de juillet 2025 de Cloudflare établit un ratio d’environ 38 000 pages crawlées pour une visite référée chez Anthropic, 1 091:1 pour OpenAI et 194:1 pour Perplexity. En comparaison, le crawler de recherche classique de Google renvoie encore une visite de référence toutes les quelques pages crawlées. Les crawlers IA prennent beaucoup et rendent très peu — et l’écart se creuse à mesure que les réponses s’affichent directement dans l’interface du chatbot, sans clic vers le site.
Trafic des crawlers IA par secteur
Tous les secteurs ne sont pas crawlés de la même façon. Quelques exemples :
- Actualités et publications : forte activité des crawlers IA, mais des ratios de référence un peu meilleurs (le ratio crawl-to-refer de Perplexity tombe à 33:1 sur les sites d’actualités, contre 118:1 au global) (blog.cloudflare.com).
- Technologie et électronique : GPTBot et Amazonbot dominent, avec des ratios crawl-to-refer toujours élevés (celui d’OpenAI atteint 402:1 dans la tech) (blog.cloudflare.com).
- Finance, enseignement supérieur et autres : chaque secteur a son propre dosage de bots et ses propres taux de référence, mais la tendance est limpide : les crawlers IA sont partout, et la plupart ne renvoient presque aucun trafic.
Les principaux crawlers Web en 2026 : qui crawle le plus le Web ?
Qui sont les têtes d’affiche de ce grand théâtre du crawling ? Voici le classement, fondé sur les données de Cloudflare de mi-2025 :
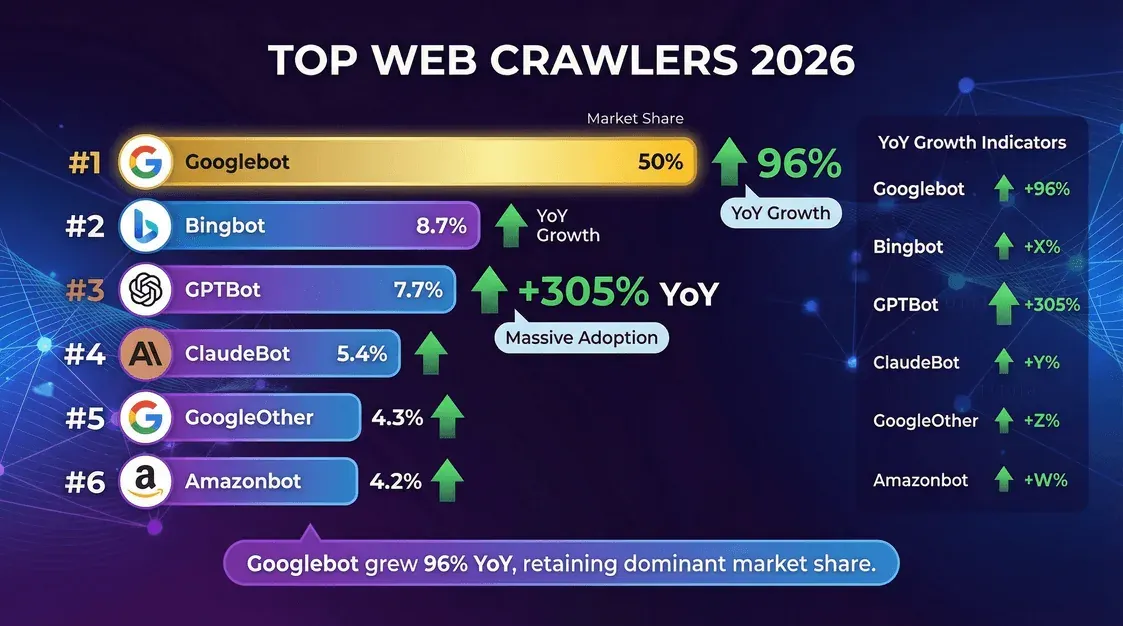
| Crawler (propriétaire) | Part des requêtes sur pages uniques (oct.-nov. 2025) | Remarques |
|---|---|---|
| Googlebot (Google) | 11,6 % | Toujours le plus grand crawler. Cloudflare YIR 2025 : environ 200 fois le volume de PerplexityBot. |
| GPTBot (OpenAI) | 3,6 % | Plus grand crawler d’entraînement IA dédié. En baisse par rapport à sa part de mai 2025 après le changement de dénominateur chez Cloudflare et la densification du secteur. |
| Bingbot (Microsoft) | 2,6 % | Alimente à la fois la recherche Bing et le grounding de Copilot. |
| Meta-ExternalAgent | 2,4 % | Crawler d’ingestion de contenu de Meta pour l’entraînement de Llama. Entré dans le top 5 en 2025. |
| ClaudeBot (Anthropic) | 2,4 % | Rebond fin 2025 après une forte baisse annuelle plus tôt dans l’année. |
| Applebot (Apple) | en forte hausse | A grimpé rapidement dans le premier groupe au T1 2026, selon une analyse secondaire des données Cloudflare. |
| PerplexityBot | 0,06 % | Part absolue minuscule, mais plus forte croissance relative parmi les grands bots IA. |
Source : Cloudflare Year in Review 2025, mesuré par la part de pages uniques crawlées entre octobre et novembre 2025. Remarque : le dénominateur diffère du chiffre de « part de toutes les requêtes des crawlers » utilisé dans les rapports précédents de mai 2025 — les classements sont comparables, mais pas les pourcentages.
Quelques enseignements clés :
- Googlebot reste le roi, à l’origine de la moitié de toute l’activité de crawling.
- GPTBot et le crawler de Meta sont ceux qui grimpent le plus vite, GPTBot ayant triplé sa part en un an.
- PerplexityBot et les agents ChatGPT-User restent modestes en part totale, mais progressent à grande vitesse.
Références du web crawling : taux de crawl, débit et performances
 Le web crawling ne se résume pas au volume : la vitesse et l’efficacité comptent tout autant. Voici ce qu’il faut retenir des taux de crawl et des références de performance en 2026.
Le web crawling ne se résume pas au volume : la vitesse et l’efficacité comptent tout autant. Voici ce qu’il faut retenir des taux de crawl et des références de performance en 2026.
Taux de crawl : à quelle vitesse les crawlers récupèrent-ils les pages ?
- Le taux de crawl se mesure généralement en pages par seconde (ou requêtes par seconde) (IBM).
- Threads/connexions parallèles : plus il y a de threads, plus le taux de crawl potentiel est élevé. Par exemple, 200 threads avec un délai de 2 secondes par site peuvent atteindre environ 100 pages par seconde (IBM).
- Références terrain : 100 à 200 pages par seconde, c’est courant pour un crawler bien optimisé tournant sur un cluster de serveurs correct.
- Google et Bing : ils récupèrent vraisemblablement des milliers de pages par seconde à l’échelle mondiale, répartis sur des millions de sites.
Facteurs qui pèsent sur le taux de crawl
- Nombre de threads / fetchers parallèles : plus de threads, plus de vitesse — jusqu’à se heurter à d’autres goulots d’étranglement.
- Nombre de sites actifs : crawler plusieurs domaines en parallèle multiplie le débit.
- Délai de crawl / temps d’attente : plus le délai est long, plus le crawl ralentit.
- Limites de ressources : bande passante, CPU et vitesse d’écriture en base peuvent tous devenir des goulots d’étranglement.
- Performances du site cible : des sites lents ou soumis à des limites de débit freinent le crawl.
Par exemple, si votre crawler dispose de 100 threads et d’un délai d’une seconde par site, vous pourriez récupérer environ 100 pages par seconde — sauf si votre base de données ne suit pas, auquel cas c’est le stockage, et non le réseau, qui devient le goulot d’étranglement.
L’impact business du web crawling : coûts, opportunités et risques
Le web crawling n’est pas qu’une curiosité technique : c’est un sujet business, avec de vrais coûts et de vraies opportunités.
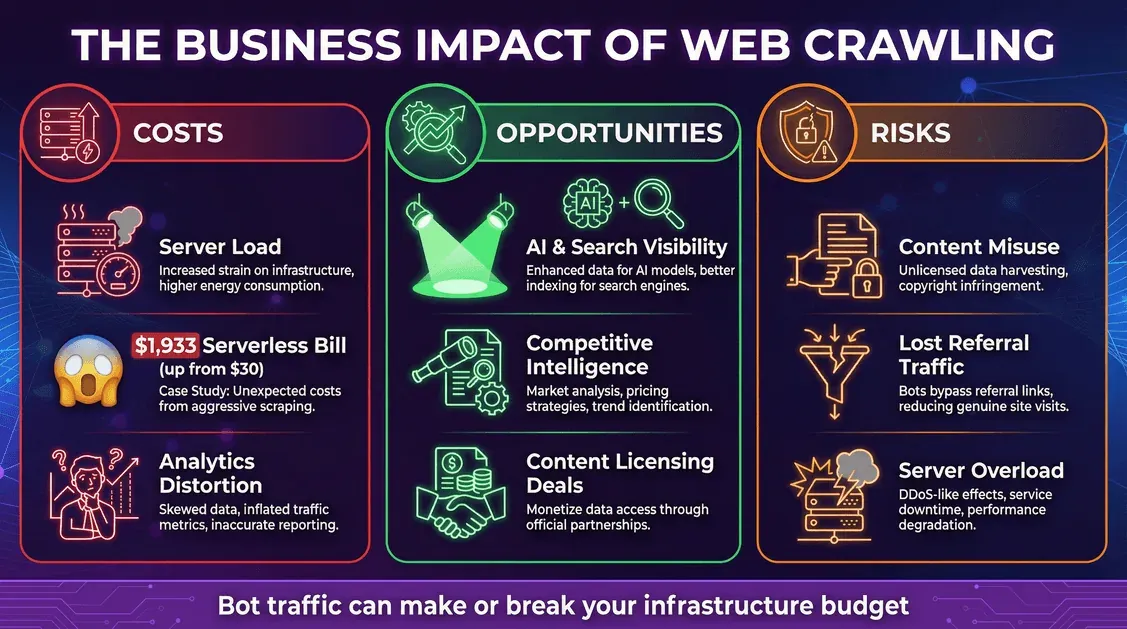
Coûts : infrastructure et factures inattendues
- Charge serveur : chaque requête d’un bot consomme du CPU, de la mémoire et de la bande passante.
- Factures cloud : sur un modèle à l’usage (comme le serverless), les bots peuvent faire grimper la note. Un développeur a vu le crawler de Meta générer 11 millions de requêtes en un mois, pour une facture serverless de 1 933 $ (contre 30 $ auparavant).
- Distorsion analytique : les bots peuvent fausser vos analyses web et compliquer la lecture du comportement réel des utilisateurs.
Opportunités : visibilité et valorisation des données
- Visibilité dans l’IA et la recherche : figurer dans les données d’entraînement des IA ou dans les index de recherche peut élargir la portée de votre marque (blog.cloudflare.com).
- Veille concurrentielle : les entreprises s’appuient sur les crawlers pour l’étude de marché, la surveillance des prix, etc.
- Monétisation : certains éditeurs accordent désormais des licences sur leur contenu à des entreprises d’IA.
Risques : usage abusif du contenu et perte de trafic
- Usage abusif du contenu : les crawlers IA peuvent intégrer votre contenu dans leurs modèles, parfois sans autorisation claire ni compensation.
- Perte de trafic de référence : les réponses IA peuvent satisfaire les utilisateurs sans les renvoyer vers votre site, d’où une « désintermédiation ».
- Sécurité et indisponibilité : des crawlers agressifs peuvent saturer vos serveurs et provoquer ralentissements ou coupures.
Gérer le trafic des crawlers Web : bonnes pratiques
Alors, comment éviter que les bots ne vous grignotent — votre site comme votre budget cloud ?
1. Optimisez votre robots.txt
- Utilisez
robots.txtpour autoriser ou interdire des bots précis. La plupart des crawlers sérieux (comme Googlebot) le respectent, mais beaucoup de bots IA s’en affranchissent (blog.cloudflare.com). - À la mi-2025, environ 14 % des principaux sites avaient commencé à ajouter des règles explicites pour les bots IA (blog.cloudflare.com).
2. Utilisez des outils de gestion des bots
- Les Web Application Firewalls (WAF) et les services de gestion des bots peuvent bloquer ou limiter le débit du trafic suspect.
- Cloudflare et d’autres fournisseurs proposent des fonctions d’atténuation des bots, ainsi que des outils de type « AI Audit » pour les créateurs de contenu (blog.cloudflare.com).
3. Mettez en place du rate limiting et du caching
- Limitez le débit des requêtes rapides issues d’un même bot.
- Servez du contenu mis en cache aux bots dès que possible — ne les laissez pas déclencher des fonctions serverless coûteuses ou des requêtes de base de données (exemple Reddit).
4. Surveillez et analysez le trafic des bots
- Gardez l’œil sur vos logs serveur. Sachez quels bots vous sollicitent, à quelle fréquence et à quels moments.
- Configurez des alertes en cas de pics de trafic inhabituels.
5. Gardez une longueur d’avance sur les standards émergents
- Surveillez les nouvelles balises méta ou en-têtes HTTP dédiés aux permissions d’usage par l’IA (par exemple,
<meta name="ai:allow" content="no">). - Suivez les initiatives du secteur comme ContentSignals.org) et les protocoles de paiement comme x402.
Tendances du web crawling à surveiller en 2026 et au-delà
Qu’est-ce que le data scraping et comment le faire en 2025 Get Started Free
Le paysage du web crawling évolue à vive allure. Voici ce que je surveille — et ce que vous devriez surveiller aussi :
- Le crawling piloté par l’IA ne fait que croître : attendez-vous à encore plus de bots IA, parcourant davantage de types de contenu (texte, images, vidéo).
- Licensing de contenu et standards de paiement. L’ère du « Far West » commence à dater. Anthropic a annoncé un accord de 1,5 milliard de dollars avec des auteurs au sujet des données d’entraînement fin 2025, le plus gros règlement éditeurs–IA à ce jour. Meta a signé des accords pluriannuels de licence de contenu avec CNN, Fox News, People Inc. et USA Today, et les accords AP–Google et Axios–OpenAI conclus plus tôt en 2025 font désormais figure de modèles plutôt que d’exceptions. De nouveaux procès continuent d’être déposés — cinq maisons d’édition ont attaqué Meta à Manhattan le 5 mai 2026 — si bien que le cadre juridique est loin d’être figé, mais la direction est nette : le contenu est désormais valorisé, rémunéré et source de litiges, et plus seulement scrappé. Côté protocole, x402 et ContentSignals.org commencent à s’imposer comme de sérieux candidats pour les couches machine-paiement et machine-autorisation, respectivement.
- La réglementation arrive : attendez-vous à davantage de clarté juridique sur ce que les bots peuvent ou non faire, en particulier pour les données d’entraînement IA (reuters.com).
- Des standards techniques pour l’usage du contenu : surveillez les nouvelles balises méta, les extensions de robots.txt et les déclarations de bots lisibles par machine.
- La collaboration éditeurs–IA : plutôt que de rester des cibles passives, davantage d’éditeurs négocieront des flux de données structurés ou des API pour les entreprises d’IA.
Conclusion : ce que ces statistiques sur le web crawling signifient pour votre entreprise
L’essentiel : le web crawling est une force dominante en 2026, et ce n’est pas près de ralentir. Les bots automatisés — en particulier les crawlers IA — pèsent désormais une énorme part de votre trafic, et leur impact sur votre infrastructure, votre budget et votre stratégie de contenu ne cesse de grandir.
Que devez-vous faire ?
- Anticipez un trafic bot conséquent : dimensionnez votre infrastructure, votre budget et votre suivi en conséquence.
- Apprenez à connaître vos crawlers : tous les bots ne se valent pas — adaptez votre approche à chacun.
- Surveillez vos métriques : suivez le trafic bot avec la même attention que vos visiteurs humains.
- Protégez votre contenu et votre budget : combinez contrôles techniques, accords juridiques et standards émergents.
- Tirez parti des avantages : figurer dans les index IA et de recherche peut renforcer votre marque — à condition d’en retirer une vraie valeur.
- Restez informé et adaptez-vous : le paysage du crawling bouge vite. Gardez l’œil sur les nouveaux standards, les réglementations et les modèles économiques.
Après des années à construire des outils d’automatisation et d’IA — et aujourd’hui chez Thunderbit — je peux vous l’affirmer : les entreprises qui prospèrent dans cette nouvelle ère sont celles qui traitent le web crawling comme une priorité stratégique, et non comme une simple nuisance technique. Que vous soyez dans la vente, l’e-commerce, le marketing ou l’immobilier, maîtriser les statistiques sur le web crawling et les références sectorielles est désormais un prérequis.
Alors, la prochaine fois que vous ouvrirez vos logs serveur et verrez défiler une procession de bots, ne vous contentez pas de soupirer avant de passer à autre chose. Exploitez les données. Comparez votre site. Ajustez vos tactiques. Et n’oubliez pas : à l’ère de l’IA, les bots ne sont pas en chemin — ils sont déjà là. Faites-les travailler pour vous, et non l’inverse.
Restez vigilant, restez curieux, et que vos logs serveur jouent toujours en votre faveur.
Essayez gratuitement Thunderbit AI Web Scraper
Envie d’en savoir plus sur le web scraping, l’automatisation et la productivité assistée par l’IA ? Parcourez le blog de Thunderbit pour des analyses approfondies, des guides pratiques et les dernières tendances. Et si vous êtes prêt à reprendre la main sur vos données, essayez l’extension Chrome Thunderbit pour un web scraping assisté par l’IA — sans code, sans effort, rien que des résultats.
Essayez AI Web Scraper Get Started Free
Citations et lectures complémentaires :
- De Googlebot à GPTBot : qui crawl votre site en 2025 (Cloudflare)
- Le rapport Cloudflare révèle que le trafic internet mondial a augmenté de 19 % en 2025 — mais une grande partie n’était que des bots (TechRadar)
- Comment fonctionne le crawling à l’ère de l’IA en 2025 (Webscraft)
- Le crawler de Meta a fait 11 millions de requêtes sur mon site en 30 jours (Reddit)
- Monitoring - Web Crawler Crawl Rate (IBM)
- Une chronologie des principaux accords entre éditeurs et entreprises d’IA en 2025 (Digiday)
- Lancement de la fondation x402 avec Coinbase (Cloudflare)




