
Si tu as déjà essayé de récupérer des données sur un site qui charge son contenu au fur et à mesure que tu descends la page, qui planque les prix derrière une connexion ou qui change de design toutes les deux semaines, tu sais à quel point ça peut vite devenir galère. Les extracteurs classiques, c’est dépassé. D’ailleurs, plus de s’appuient aujourd’hui sur l’extraction web pour choper des données alternatives, et automatisent la surveillance des prix de leurs concurrents. Mais le vrai souci, c’est que la majorité de ces infos sont planquées sur des sites dynamiques, générés en JavaScript et accessibles uniquement via des actions utilisateur. C’est là que l’automatisation via navigateur sans interface – et des outils comme Puppeteer – deviennent indispensables.
Après avoir passé des années à bricoler des outils d’automatisation et d’IA (et, oui, à scraper pas mal de sites pour des équipes commerciales et opérationnelles), j’ai pu voir à quel point Puppeteer permet d’accéder à des données inaccessibles avec les extracteurs classiques. Mais j’ai aussi remarqué que le fait de devoir coder en rebute plus d’un côté business. Dans ce guide, je vais t’expliquer ce qu’est un extracteur Puppeteer, comment t’en servir pour extraire des données web, et dans quels cas il vaut mieux opter pour une solution encore plus simple – comme , notre extracteur web IA sans code.
C’est quoi un Extracteur Puppeteer ? Petit tour rapide
 On commence par la base. c’est une librairie open-source pour Node.js, développée par Google, qui permet de piloter Chrome ou Chromium sans interface, directement en JavaScript. En gros : c’est comme avoir un robot qui peut ouvrir des pages web, cliquer sur des boutons, remplir des formulaires, scroller et – surtout – extraire des données, tout ça sans rien afficher à l’écran.
On commence par la base. c’est une librairie open-source pour Node.js, développée par Google, qui permet de piloter Chrome ou Chromium sans interface, directement en JavaScript. En gros : c’est comme avoir un robot qui peut ouvrir des pages web, cliquer sur des boutons, remplir des formulaires, scroller et – surtout – extraire des données, tout ça sans rien afficher à l’écran.
Pourquoi Puppeteer est-il aussi puissant ?
- Il peut afficher du contenu dynamique – c’est-à-dire attendre que le JavaScript ait tout chargé, comme un vrai internaute.
- Il peut imiter des actions humaines : clics, saisies, scroll, gestion des pop-ups…
- Il est parfait pour extraire des infos qui n’apparaissent qu’après une action, comme les annonces e-commerce, les fils d’actu ou les dashboards.
Comment il se compare aux autres outils ?
- Selenium : Le dinosaure de l’automatisation de navigateur. Il marche avec plein de navigateurs et de langages, mais il est plus lourd et un peu old school. Idéal pour les tests multi-navigateurs, mais Puppeteer est plus rapide pour les projets Chrome/Node.js.
- Thunderbit : Là, je suis fan. Thunderbit, c’est un extracteur web IA sans code qui s’intègre à ton navigateur. Pas besoin de scripts : tu cliques sur « Suggérer les champs par l’IA » et l’IA repère direct les données à extraire. Parfait pour ceux qui veulent des résultats sans se prendre la tête avec du code (on en reparle plus bas).
En résumé : Puppeteer = contrôle total (si tu codes). Thunderbit = simplicité ultime (si tu veux pas coder).
Pourquoi l’Extraction Web avec Puppeteer est-elle Indispensable pour les Boîtes ?
Soyons clairs : l’extraction web, ce n’est plus réservé aux hackers ou aux data scientists. Les équipes commerciales, opérationnelles, marketing, même dans l’immobilier, utilisent les données web pour prendre l’avantage. Et comme beaucoup d’infos stratégiques sont cachées derrière des sites dynamiques, Puppeteer est souvent la clé pour y accéder.
Voici quelques exemples concrets :
| Cas d’usage | Bénéficiaires | Impact / ROI |
|---|---|---|
| Génération de leads | Commerciaux, Biz Dev | Prospection automatisée ; plus de 8h gagnées par semaine par commercial (étude de cas) |
| Veille tarifaire | E-commerce, Opérations Produit | Suivi en temps réel des concurrents ; une boîte a économisé 3,8 M$/an (source) |
| Études de marché | Marketing, Stratégie, Finance | 67 % des conseillers utilisent des données extraites ; jusqu’à 890 % de ROI dans certains cas (source) |
| Agrégation immobilière | Agents, Analystes | Extraction de 50+ annonces en quelques minutes (source) |
| Suivi de conformité | Opérations, Juridique | Veille automatisée ; un assureur a évité 50 M$ de pénalités (source) |
Et n’oublie pas : passent un quart de leur semaine sur des tâches répétitives comme la collecte de données. Automatiser ça avec l’extraction web, ce n’est plus un gadget, c’est un vrai boost de compétitivité.
Premiers Pas : Installer ton Extracteur Puppeteer
Prêt à te lancer ? Voilà comment démarrer avec Puppeteer en moins de 10 minutes (si tu es à l’aise avec un peu de JavaScript) :
1. Installe Node.js
Puppeteer tourne avec Node.js. Télécharge la dernière version LTS sur .
2. Crée un nouveau dossier de projet
Ouvre ton terminal et tape :
1mkdir puppeteer-scraper-demo
2cd puppeteer-scraper-demo
3npm init -y3. Installe Puppeteer
1npm install puppeteerÇa va aussi télécharger une version de Chromium (environ 100 Mo).
4. Crée ton premier script
Crée un fichier scrape.js :
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('https://example.com', { waitUntil: 'domcontentloaded' });
6 const title = await page.title();
7 console.log('Page title:', title);
8 await browser.close();
9})();Lance-le avec :
1node scrape.jsSi tu vois « Page title: Example Domain », bravo : tu viens d’automatiser Chrome !
Construire ton Premier Script d’Extraction Web avec Puppeteer
Passons à la pratique. Imaginons que tu veuilles extraire des citations depuis (un site de démo pour extracteurs).
Étape 1 : Va sur la page
1await page.goto('http://quotes.toscrape.com', { waitUntil: 'networkidle0' });Étape 2 : Récupère les données
1const quotes = await page.evaluate(() => {
2 return Array.from(document.querySelectorAll('.quote')).map(node => ({
3 text: node.querySelector('.text')?.innerText.trim(),
4 author: node.querySelector('.author')?.innerText.trim(),
5 tags: Array.from(node.querySelectorAll('.tag')).map(tag => tag.innerText.trim())
6 }));
7});
8console.log(quotes);Étape 3 : Gère la pagination
1let hasNext = true;
2let allQuotes = [];
3while (hasNext) {
4 // Extraction comme ci-dessus
5 const quotes = await page.evaluate(/* ... */);
6 allQuotes.push(...quotes);
7 const nextButton = await page.$('li.next > a');
8 if (nextButton) {
9 await Promise.all([
10 page.click('li.next > a'),
11 page.waitForNavigation({ waitUntil: 'networkidle0' })
12 ]);
13 } else {
14 hasNext = false;
15 }
16}Étape 4 : Sauvegarde en JSON
1const fs = require('fs');
2fs.writeFileSync('quotes.json', JSON.stringify(allQuotes, null, 2));Et voilà : un extracteur Puppeteer basique qui navigue, extrait, gère la pagination et sauvegarde les données.
Techniques Avancées avec Puppeteer : Gérer le Contenu Dynamique
La plupart des sites réels sont bien plus tordus qu’une simple liste statique. Voilà comment gérer les cas corsés :
1. Attendre les éléments dynamiques
1await page.waitForSelector('.product-list-item');Ça garantit que le contenu voulu est bien chargé avant de l’extraire.
2. Simuler des actions utilisateur
- Cliquer sur un bouton :
await page.click('#load-more'); - Saisir dans un champ :
await page.type('#search', 'laptop'); - Scroller pour l’infinite scroll :
1let previousHeight = await page.evaluate('document.body.scrollHeight'); 2while (true) { 3 await page.evaluate('window.scrollTo(0, document.body.scrollHeight)'); 4 await page.waitForTimeout(1500); 5 const newHeight = await page.evaluate('document.body.scrollHeight'); 6 if (newHeight === previousHeight) break; 7 previousHeight = newHeight; 8}
3. Gérer les connexions
1await page.goto('https://exampleshop.com/login');
2await page.type('#login-username', 'myusername');
3await page.type('#login-password', 'mypassword');
4await page.click('#login-button');
5await page.waitForNavigation({ waitUntil: 'networkidle0' });4. Gérer les données chargées en AJAX Parfois, les données ne sont pas dans le DOM mais viennent d’un appel API. Tu peux intercepter les réponses réseau avec :
1page.on('response', async response => {
2 if (response.url().includes('/api/products')) {
3 const data = await response.json();
4 // Traite les données ici
5 }
6});Exemple Concret : Extraire des Données Produits d’un Site E-commerce
On met tout ça en pratique. Imaginons que tu veuilles extraire les noms, prix et images de produits d’un site e-commerce (de démo) après connexion.
1const puppeteer = require('puppeteer');
2const fs = require('fs');
3(async () => {
4 const browser = await puppeteer.launch({ headless: true });
5 const page = await browser.newPage();
6 // Étape 1 : Connexion
7 await page.goto('https://exampleshop.com/login');
8 await page.type('#login-username', 'myusername');
9 await page.type('#login-password', 'mypassword');
10 await page.click('#login-button');
11 await page.waitForNavigation({ waitUntil: 'networkidle0' });
12 // Étape 2 : Va sur la page catégorie
13 await page.goto('https://exampleshop.com/category/laptops', { waitUntil: 'networkidle0' });
14 // Étape 3 : Récupère les produits
15 const products = await page.evaluate(() => {
16 return Array.from(document.querySelectorAll('.product-item')).map(item => ({
17 name: item.querySelector('.product-title')?.innerText.trim() || '',
18 price: item.querySelector('.product-price')?.innerText.trim() || '',
19 image: item.querySelector('img.product-image')?.src || ''
20 }));
21 });
22 // Étape 4 : Sauvegarde en JSON
23 fs.writeFileSync('products.json', JSON.stringify(products, null, 2));
24 await browser.close();
25})();Ce script se connecte, navigue, extrait et sauvegarde – tout ça en automatique. Pour aller plus loin, tu peux ajouter des boucles pour la pagination ou cliquer sur chaque produit pour plus de détails.
Thunderbit : Rendre Puppeteer Ultra Simple avec l’IA
Si tu es arrivé jusqu’ici et que tu te dis « C’est cool, mais j’ai pas envie de coder à chaque fois que j’ai besoin de données », t’inquiète, t’es pas le seul. C’est exactement pour ça qu’on a créé .
Qu’est-ce qui rend Thunderbit unique ?
- Aucune ligne de code à écrire : Installe juste l’, ouvre la page à extraire et clique sur « Suggérer les champs par l’IA ».
- Détection intelligente des champs : Thunderbit analyse la page et te propose direct les colonnes à extraire – « Nom du produit », « Prix », « Image », etc.
- Gestion du contenu dynamique : Scroll infini, pop-ups, sous-pages ? L’IA de Thunderbit gère tout, clique sur la pagination ou visite chaque fiche produit pour enrichir tes données.
- Export instantané : Balance tes données direct dans Excel, Google Sheets, Notion ou Airtable en un clic. Pas de surcoût pour l’export.
- Modèles pour les sites connus : Besoin d’extraire Amazon, Zillow ou LinkedIn ? Thunderbit a des modèles prêts à l’emploi – rien à configurer.
- Extraction cloud ou navigateur : Pour les gros volumes, Thunderbit peut extraire jusqu’à 50 pages en même temps dans le cloud.
J’ai vu des utilisateurs passer de « J’aimerais bien avoir ces données » à « Voilà mon tableau Excel » en moins de cinq minutes. Et le top ? Plus besoin de flipper que ton script casse si le site change – l’IA de Thunderbit s’adapte toute seule.
Puppeteer vs Thunderbit : Quel Extracteur Web Choisir ?
Alors, tu choisis quoi ? Voilà comment je conseille les équipes :
| Critère | Puppeteer (avec code) | Thunderbit (Sans code, IA) |
|---|---|---|
| Facilité d’utilisation | Faut connaître JavaScript et le DOM | Interface intuitive, l’IA suggère les champs |
| Vitesse de mise en place | De quelques heures à plusieurs jours pour les tâches complexes | Quelques minutes – tu installes et tu lances |
| Contrôle/Flexibilité | Contrôle total : logique personnalisée, intégration à d’autres scripts | Très flexible pour les cas standards ; moins adapté aux workflows ultra personnalisés |
| Contenu dynamique | Gestion manuelle des attentes, clics, scrolls | L’IA gère automatiquement le contenu dynamique, la pagination et les sous-pages |
| Maintenance | Tu gères les scripts – à mettre à jour si le site change | L’IA s’adapte aux changements de mise en page ; moins de maintenance pour toi |
| Export des données | Export à coder soi-même | Export en un clic vers Excel, Sheets, Notion, Airtable, CSV, JSON |
| Idéal pour | Développeurs, extractions personnalisées ou à grande échelle | Utilisateurs métier, projets rapides, équipes non techniques |
| Coût | Gratuit (hors temps passé et infrastructure) | Offre gratuite dispo ; formules payantes selon crédits (voir tarifs Thunderbit) |
En résumé :
- Prends Puppeteer si tu veux un contrôle total, que tu as des ressources dev ou que tu veux intégrer l’extraction à une appli plus large.
- Choisis Thunderbit si tu veux des résultats rapides, sans coder, ou pour rendre tes collègues non techniques autonomes.
Franchement, beaucoup d’équipes mixent les deux : Thunderbit pour les besoins rapides et le prototypage, Puppeteer pour les intégrations poussées ou les cas particuliers.
Checklist : Réussir ton Projet d’Extraction Web avec Puppeteer
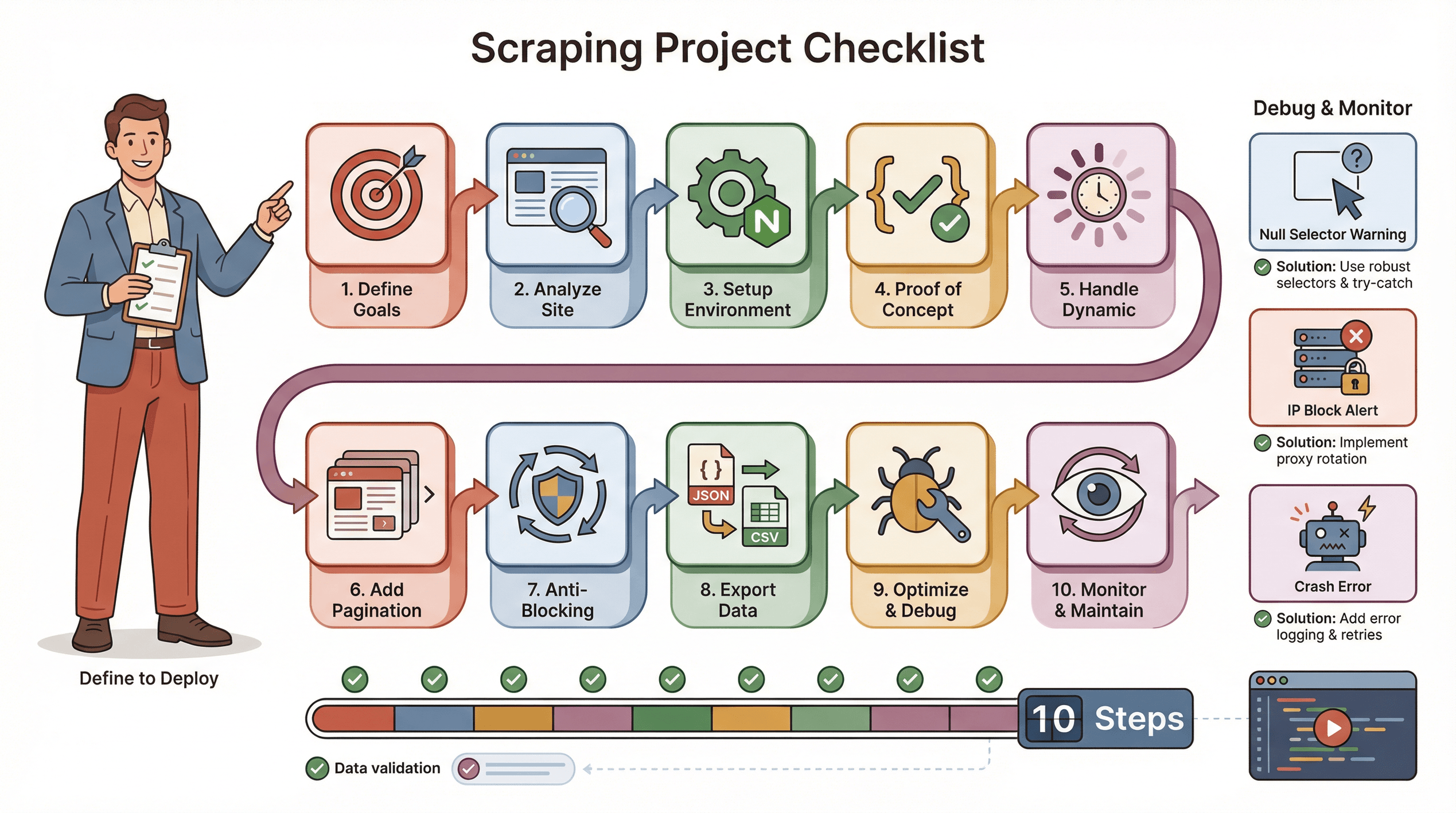 Voici ma checklist pour un projet d’extraction réussi avec Puppeteer :
Voici ma checklist pour un projet d’extraction réussi avec Puppeteer :
- Définis tes objectifs : Quelles données ? Où les trouver ?
- Analyse le site : Est-il dynamique ? Faut-il se connecter ? Y a-t-il des protections anti-bot ?
- Prépare l’environnement : Node.js, Puppeteer, bibliothèques annexes.
- Écris un POC : Commence par une page, valide les sélecteurs.
- Gère le contenu dynamique : Utilise
waitForSelector, simule les clics/scrolls si besoin. - Ajoute la pagination ou des boucles : Extrais toutes les pages, pas juste une.
- Prévois l’anti-blocage : Délais aléatoires, User-Agent réaliste, proxies si besoin.
- Exporte et valide les données : Sauvegarde en JSON/CSV, vérifie la complétude.
- Optimise et gère les erreurs : Ajoute des try/catch, log la progression, gère les données manquantes.
- Surveille et maintiens : Les sites changent – sois prêt à adapter ton script.
Astuces de dépannage :
- Si les sélecteurs renvoient null, vérifie le HTML et ajoute des attentes.
- Si tu es bloqué, ralentis, change d’IP ou utilise des plugins furtifs.
- Si le script plante, regarde les fuites mémoire ou exceptions non gérées.
Conclusion & Points Clés à Retenir
L’extraction web est devenue une compétence clé pour toutes les équipes qui bossent avec la data. Puppeteer te donne la puissance pour extraire des données même sur les sites les plus dynamiques et tordus – mais il faut savoir coder et assurer la maintenance. Pour ceux qui veulent aller droit au but, Thunderbit propose une alternative IA sans code, rapide, flexible et franchement bluffante.
Mon conseil :
- Si tu es technique et que tu veux personnaliser à fond, commence par Puppeteer.
- Si tu veux aller vite, faire simple et être tranquille, teste (l’ est parfaite pour débuter).
- Pour la plupart des équipes, mixer les deux couvre 99 % des besoins en données web.
Envie d’autres tutos comme celui-ci ? Va faire un tour sur le pour des guides, des comparatifs et toutes les nouveautés de l’extraction web boostée à l’IA.
FAQ
1. C’est quoi un extracteur Puppeteer et pourquoi l’utiliser pour l’extraction web ?
Puppeteer est une librairie Node.js qui permet de piloter Chrome sans interface via JavaScript. On l’utilise pour extraire des données car il peut charger du contenu dynamique, simuler des actions utilisateur et accéder à des sites inaccessibles aux extracteurs classiques.
2. Quelle différence entre Puppeteer, Selenium et Thunderbit ?
Selenium marche avec plusieurs navigateurs et langages mais il est plus lourd. Puppeteer est optimisé pour Chrome/Node.js et plus rapide dans beaucoup de cas. Thunderbit, c’est un outil sans code, boosté à l’IA, qui permet à tout le monde d’extraire des données en quelques clics.
3. Quels sont les principaux bénéfices métier de l’extraction web avec Puppeteer ?
Automatiser la collecte de données fait gagner du temps, réduit les erreurs et donne des insights en temps réel pour la vente, le marketing, les opérations, etc. Les usages vont de la génération de leads à la veille tarifaire et aux études de marché.
4. Quels sont les plus gros défis avec Puppeteer ?
Les principaux obstacles sont la gestion du contenu dynamique, éviter les blocages anti-bot et la maintenance des scripts quand les sites changent. Il faut coder pour gérer les attentes, simuler les interactions et traiter les erreurs.
5. Quand privilégier Thunderbit plutôt que Puppeteer ?
Utilise Thunderbit si tu veux éviter le code, obtenir des résultats vite ou rendre tes collègues non techniques autonomes. C’est parfait pour les extractions standards, les projets rapides ou pour exporter des données vers Excel ou Google Sheets sans prise de tête.
Prêt à découvrir une nouvelle façon d’extraire des données ? ou explore d’autres guides sur le . Bonne extraction !
Pour aller plus loin