
Si vous avez déjà essayé d’extraire des données d’un site qui charge son contenu au fil du défilement, masque ses prix derrière une connexion ou semble changer de mise en page toutes les deux semaines, vous savez à quel point la tâche peut être pénible. Les extracteurs statiques ne suffisent tout simplement plus. En réalité, plus de s’appuient désormais sur le web scraping pour obtenir des données alternatives, et automatisent la surveillance des prix de la concurrence. Mais voici le point clé : une grande partie de ces données se trouve sur des sites dynamiques, chargés par JavaScript et dissimulés derrière des interactions utilisateur. C’est là qu’entrent en jeu l’automatisation de navigateur sans interface graphique — et des outils comme Puppeteer.
Ayant passé des années à construire des outils d’automatisation et d’IA — et, oui, à extraire ma part de données de sites pour des équipes commerciales et opérations — j’ai pu constater de première main à quel point Puppeteer peut débloquer des données que les extracteurs traditionnels ratent. Mais j’ai aussi vu à quel point la charge de développement peut devenir un frein pour les utilisateurs métier. Dans ce guide, je vais donc vous montrer précisément ce qu’est un puppeteer scraper, comment l’utiliser pour le web scraping avec Puppeteer, et à quel moment il peut être plus judicieux d’opter pour quelque chose d’encore plus simple — comme , notre extracteur Web IA sans code.
Qu’est-ce qu’un Puppeteer Scraper ? Aperçu rapide
 Commençons par les bases. est une bibliothèque open source Node.js de Google qui permet de contrôler un navigateur Chrome ou Chromium sans interface graphique à l’aide de JavaScript. En clair : c’est comme avoir un robot capable d’ouvrir des pages web, cliquer sur des boutons, remplir des formulaires, faire défiler la page et — surtout — extraire des données, le tout sans rien afficher à l’écran.
Commençons par les bases. est une bibliothèque open source Node.js de Google qui permet de contrôler un navigateur Chrome ou Chromium sans interface graphique à l’aide de JavaScript. En clair : c’est comme avoir un robot capable d’ouvrir des pages web, cliquer sur des boutons, remplir des formulaires, faire défiler la page et — surtout — extraire des données, le tout sans rien afficher à l’écran.
Qu’est-ce qui rend Puppeteer spécial ?
- Il peut rendre du contenu dynamique : il attend que JavaScript se charge, comme le ferait un vrai utilisateur.
- Il peut simuler des actions utilisateur : clics, saisie, défilement, et même gestion des fenêtres contextuelles.
- Il est idéal pour extraire des sites où les données n’apparaissent qu’après interaction, comme des fiches e-commerce, des fils sociaux ou des tableaux de bord.
Comment se compare-t-il aux autres outils ?
- Selenium : le doyen de l’automatisation de navigateur. Il fonctionne avec de nombreux navigateurs et langages, mais il est plus lourd et un peu plus ancien. Très utile pour les tests cross-browser, tandis que Puppeteer est plus rapide pour les projets Chrome/Node.js.
- Thunderbit : là, j’enthousiasme un peu plus. Thunderbit est un extracteur Web sans code, propulsé par l’IA, qui fonctionne dans votre navigateur. Au lieu d’écrire des scripts, vous cliquez simplement sur « AI Suggest Fields » et laissez l’IA déterminer quoi extraire. C’est parfait pour les utilisateurs métier qui veulent des résultats sans coder (j’y reviens plus loin).
En résumé : Puppeteer = contrôle maximal (si vous codez). Thunderbit = simplicité maximale (si vous ne voulez pas coder).
Pourquoi le web scraping avec Puppeteer compte pour les utilisateurs métier
Soyons francs : le web scraping n’est plus réservé aux hackers ou aux data scientists. Les équipes commerciales, opérations, marketing et même les professionnels de l’immobilier utilisent les données web pour prendre une longueur d’avance. Et comme tant d’informations critiques pour l’entreprise sont enfermées derrière des sites dynamiques, Puppeteer est souvent la clé pour les débloquer.
Voici quelques cas d’usage concrets :
| Cas d’usage | Qui en bénéficie | Impact / ROI |
|---|---|---|
| Génération de leads | Ventes, développement commercial | Automatisation de la constitution de listes de prospects ; plus de 8 heures économisées par semaine et par commercial (étude de cas) |
| Surveillance des prix | E-commerce, opérations produit | Suivi concurrentiel en temps réel ; une entreprise a économisé 3,8 M$ par an (source) |
| Étude de marché | Marketing, stratégie, finance | 67 % des conseillers en investissement utilisent des données extraites du web ; jusqu’à 890 % de ROI dans certains cas (source) |
| Agrégation immobilière | Agents, analystes | Extraction de plus de 50 pages de biens en quelques minutes, et non en plusieurs heures (source) |
| Suivi de conformité | Opérations, juridique | Automatisation de la veille ; un assureur a évité 50 M$ de pénalités (source) |
Et n’oublions pas : consacrent un quart de leur semaine à des tâches répétitives comme la collecte de données. Automatiser cela avec le web scraping n’est pas un simple confort : c’est un avantage concurrentiel.
Bien démarrer : configurer votre Puppeteer Scraper
Prêt à retrousser vos manches ? Voici comment faire fonctionner Puppeteer en moins de 10 minutes (en supposant que vous soyez à l’aise avec un peu de JavaScript) :
1. Installez Node.js
Puppeteer fonctionne avec Node.js. Téléchargez la dernière version LTS depuis .
2. Créez un nouveau dossier de projet
Ouvrez votre terminal et exécutez :
1mkdir puppeteer-scraper-demo
2cd puppeteer-scraper-demo
3npm init -y3. Installez Puppeteer
1npm install puppeteerCela téléchargera aussi une version compatible de Chromium (environ 100 Mo).
4. Créez votre premier script
Créez un fichier nommé scrape.js :
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('https://example.com', { waitUntil: 'domcontentloaded' });
6 const title = await page.title();
7 console.log('Titre de la page :', title);
8 await browser.close();
9})();Lancez-le avec :
1node scrape.jsSi vous voyez « Titre de la page : Example Domain », félicitations : vous venez d’automatiser Chrome !
Créer votre premier script de web scraping avec Puppeteer
Passons à la pratique. Supposons que vous vouliez extraire des citations depuis (un site de démonstration pour les extracteurs).
Étape 1 : accédez à la page
1await page.goto('http://quotes.toscrape.com', { waitUntil: 'networkidle0' });Étape 2 : extrayez les données
1const quotes = await page.evaluate(() => {
2 return Array.from(document.querySelectorAll('.quote')).map(node => ({
3 text: node.querySelector('.text')?.innerText.trim(),
4 author: node.querySelector('.author')?.innerText.trim(),
5 tags: Array.from(node.querySelectorAll('.tag')).map(tag => tag.innerText.trim())
6 }));
7});
8console.log(quotes);Étape 3 : gérez la pagination
1let hasNext = true;
2let allQuotes = [];
3while (hasNext) {
4 // Extraire les citations comme ci-dessus
5 const quotes = await page.evaluate(/* ... */);
6 allQuotes.push(...quotes);
7 const nextButton = await page.$('li.next > a');
8 if (nextButton) {
9 await Promise.all([
10 page.click('li.next > a'),
11 page.waitForNavigation({ waitUntil: 'networkidle0' })
12 ]);
13 } else {
14 hasNext = false;
15 }
16}Étape 4 : enregistrez au format JSON
1const fs = require('fs');
2fs.writeFileSync('quotes.json', JSON.stringify(allQuotes, null, 2));Et voilà : un script Puppeteer de base qui navigue, extrait, pagine et enregistre les données.
Techniques avancées de Puppeteer Scraper : gérer le contenu dynamique
La plupart des sites réels sont plus complexes qu’une simple liste statique. Voici comment gérer les cas difficiles :
1. Attendre les éléments dynamiques
1await page.waitForSelector('.product-list-item');Cela garantit que le contenu souhaité est chargé avant que vous n’essayiez de l’extraire.
2. Simuler les actions utilisateur
- Cliquer sur un bouton :
await page.click('#load-more'); - Saisir du texte dans un champ :
await page.type('#search', 'laptop'); - Faire défiler pour le chargement infini :
1// Remarque : page.waitForTimeout a été supprimé dans Puppeteer v22. Utilisez plutôt une simple promesse. 2const sleep = (ms) => new Promise(r => setTimeout(r, ms)); 3let previousHeight = await page.evaluate('document.body.scrollHeight'); 4while (true) { 5 await page.evaluate('window.scrollTo(0, document.body.scrollHeight)'); 6 await sleep(1500); 7 const newHeight = await page.evaluate('document.body.scrollHeight'); 8 if (newHeight === previousHeight) break; 9 previousHeight = newHeight; 10}
1**3. Gérer les connexions**
2```javascript
3await page.goto('https://exampleshop.com/login');
4await page.type('#login-username', 'myusername');
5await page.type('#login-password', 'mypassword');
6await page.click('#login-button');
7await page.waitForNavigation({ waitUntil: 'networkidle0' });4. Traiter les données chargées en AJAX Parfois, les données ne se trouvent pas dans le DOM mais proviennent d’un appel API. Vous pouvez intercepter les réponses réseau avec :
1page.on('response', async response => {
2 if (response.url().includes('/api/products')) {
3 const data = await response.json();
4 // Traiter les données
5 }
6});Exemple concret : extraire des données produit d’un site e-commerce
Mettons tout ensemble. Imaginez que vous vouliez extraire les noms de produits, les prix et les images d’un site e-commerce (de démonstration) après vous être connecté.
1const puppeteer = require('puppeteer');
2const fs = require('fs');
3(async () => {
4 const browser = await puppeteer.launch({ headless: true });
5 const page = await browser.newPage();
6 // Étape 1 : connexion
7 await page.goto('https://exampleshop.com/login');
8 await page.type('#login-username', 'myusername');
9 await page.type('#login-password', 'mypassword');
10 await page.click('#login-button');
11 await page.waitForNavigation({ waitUntil: 'networkidle0' });
12 // Étape 2 : accéder à la page catégorie
13 await page.goto('https://exampleshop.com/category/laptops', { waitUntil: 'networkidle0' });
14 // Étape 3 : extraire les produits
15 const products = await page.evaluate(() => {
16 return Array.from(document.querySelectorAll('.product-item')).map(item => ({
17 name: item.querySelector('.product-title')?.innerText.trim() || '',
18 price: item.querySelector('.product-price')?.innerText.trim() || '',
19 image: item.querySelector('img.product-image')?.src || ''
20 }));
21 });
22 // Étape 4 : enregistrer au format JSON
23 fs.writeFileSync('products.json', JSON.stringify(products, null, 2));
24 await browser.close();
25})();Ce script se connecte, navigue, extrait et enregistre — le tout automatiquement. Pour des besoins plus avancés, vous pouvez ajouter des boucles de pagination ou même ouvrir chaque produit pour obtenir plus de détails.
Thunderbit : simplifier le scraping avec Puppeteer grâce à l’IA
À ce stade, si vous vous dites : « C’est super, mais je n’ai pas envie d’écrire du code à chaque fois que j’ai besoin d’un nouvel ensemble de données », vous n’êtes pas seul. C’est exactement pour cela que nous avons créé .
Qu’est-ce qui différencie Thunderbit ?
- Aucun code requis : installez simplement , ouvrez la page à extraire, puis cliquez sur « AI Suggest Fields ».
- Détection des champs par l’IA : Thunderbit lit la page et suggère les meilleures colonnes à extraire — comme « Nom du produit », « Prix », « Image », etc.
- Gère le contenu dynamique : défilement infini, fenêtres contextuelles et sous-pages ? L’IA de Thunderbit peut s’en charger, en cliquant dans la pagination ou même en visitant la page de détail de chaque produit pour enrichir vos données.
- Export instantané : envoyez vos données directement vers Excel, Google Sheets, Notion ou Airtable en un clic. Aucun surcoût pour les exports.
- Modèles pour les sites populaires : besoin d’extraire Amazon, Zillow ou LinkedIn ? Thunderbit propose des modèles instantanés — aucune configuration nécessaire.
- Extraction dans le cloud ou dans le navigateur : pour les gros volumes, Thunderbit peut extraire jusqu’à 50 pages à la fois dans le cloud.
J’ai vu des utilisateurs passer de « J’aimerais pouvoir obtenir ces données » à « Voici mon tableur » en moins de cinq minutes. Et le meilleur dans tout ça ? Plus besoin de s’inquiéter des scripts qui cassent quand le site change — l’IA de Thunderbit s’adapte en temps réel.
Puppeteer vs Thunderbit : choisir le bon outil de web scraping
Alors, lequel devriez-vous utiliser ? Voici comment je le résumerais pour les équipes :
| Facteur | Puppeteer (code) | Thunderbit (sans code, IA) |
|---|---|---|
| Facilité d’utilisation | Nécessite des connaissances en JavaScript et en DOM | Clic et sélection, l’IA propose les champs |
| Vitesse de mise en place | De quelques heures à plusieurs jours pour les tâches complexes | En quelques minutes — installez et c’est parti |
| Contrôle / flexibilité | Maximum : scriptisez toute logique personnalisée, intégrez d’autres codes | Élevé pour les cas standards ; moins adapté aux workflows très personnalisés |
| Contenu dynamique | Script manuel pour les attentes, clics et défilements | L’IA intégrée gère automatiquement le contenu dynamique, la pagination et les sous-pages |
| Maintenance | Vous gérez vos scripts — à mettre à jour quand les sites changent | L’IA s’adapte aux changements de mise en page ; moins de maintenance pour l’utilisateur |
| Export des données | Vous devez écrire votre propre logique d’export | Export en un clic vers Excel, Sheets, Notion, Airtable, CSV, JSON |
| Idéal pour | Développeurs, extractions très personnalisées ou à grande échelle | Utilisateurs métier, projets à délai court, équipes non techniques |
| Coût | Gratuit (hors temps passé et infrastructure éventuelle) | Offre gratuite disponible ; formules payantes par crédits (voir Tarifs Thunderbit) |
En bref :
- Utilisez Puppeteer si vous avez besoin d’un contrôle total, de ressources de développement, ou si vous devez intégrer le scraping dans une application plus large.
- Utilisez Thunderbit si vous voulez des résultats rapides, ne voulez pas coder, ou devez donner de l’autonomie à des collègues non techniques.
Honnêtement, j’ai vu des équipes utiliser les deux : Thunderbit pour les gains rapides et le prototypage, Puppeteer pour les intégrations profondes ou les cas particuliers.
Liste de contrôle étape par étape : réussir un projet de web scraping avec Puppeteer
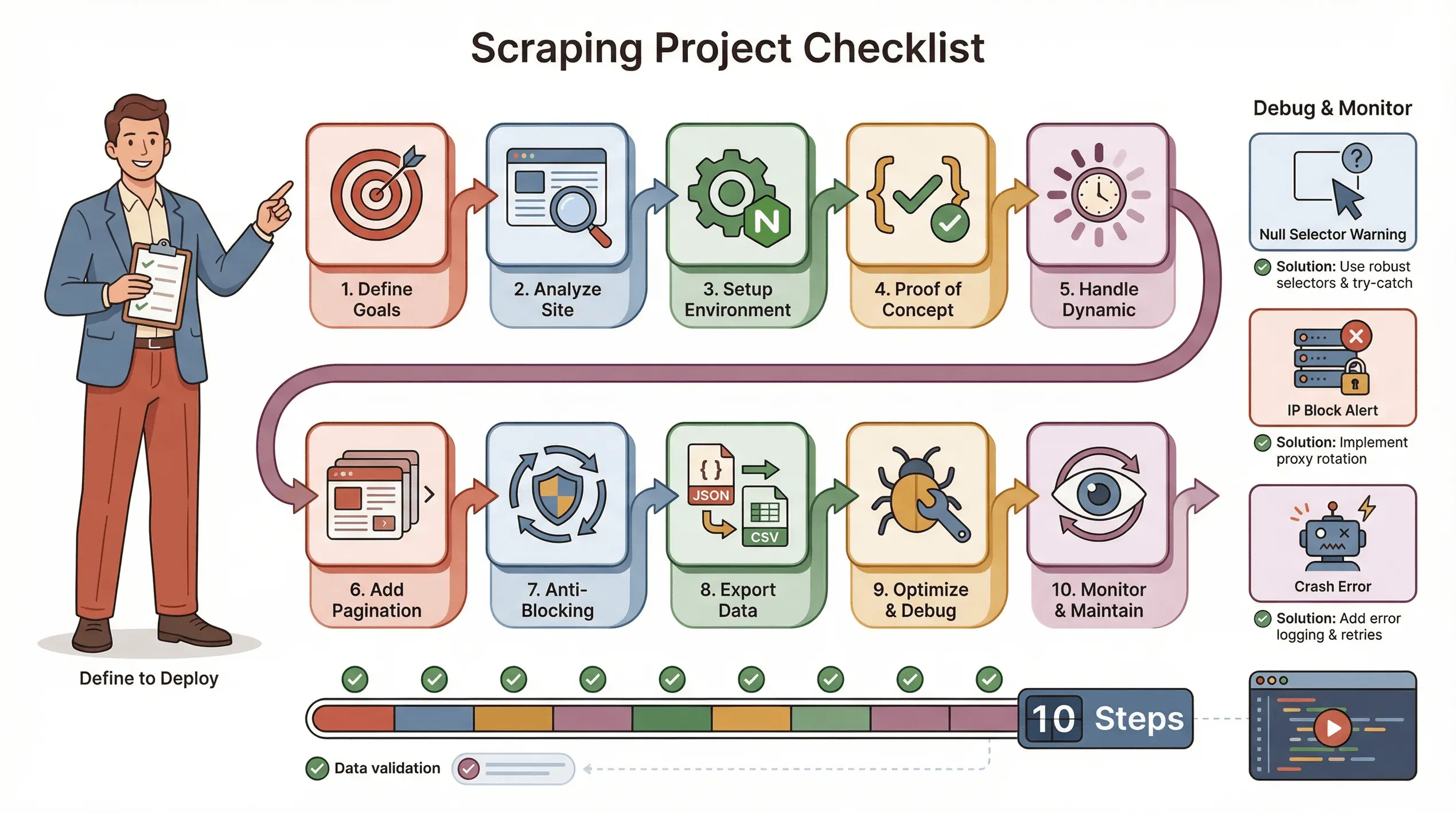 Voici ma liste de contrôle de référence pour un projet de scraping Puppeteer sans accroc :
Voici ma liste de contrôle de référence pour un projet de scraping Puppeteer sans accroc :
- Définissez vos objectifs : quelles données vous faut-il ? Où se trouvent-elles ?
- Analysez le site : est-il dynamique ? Une connexion est-elle nécessaire ? Y a-t-il des mesures anti-bot ?
- Configurez votre environnement : Node.js, Puppeteer et les éventuelles bibliothèques d’aide.
- Écrivez une preuve de concept : commencez par une page, identifiez correctement les sélecteurs.
- Gérez le contenu dynamique : utilisez
waitForSelectoret simulez clics/défilement si nécessaire. - Ajoutez la pagination ou des boucles : extrayez toutes les pages, pas seulement une.
- Mettez en place des tactiques anti-blocage : randomisez les délais, définissez un vrai User-Agent, utilisez des proxys si nécessaire.
- Exportez et validez les données : enregistrez en JSON/CSV et vérifiez l’exhaustivité.
- Optimisez et gérez les erreurs : ajoutez des blocs try/catch, journalisez la progression, gérez les données manquantes avec souplesse.
- Surveillez et maintenez : les sites changent — soyez prêt à mettre à jour votre script.
Conseils de dépannage :
- Si les sélecteurs renvoient
null, revérifiez le HTML et utilisez des attentes. - Si vous êtes bloqué, ralentissez, faites tourner les IP ou utilisez des plugins furtifs.
- Si votre script plante, vérifiez les fuites mémoire ou les exceptions non gérées.
Conclusion et points clés à retenir
Le web scraping est devenu une compétence indispensable pour les équipes orientées données. Puppeteer vous donne la puissance d’extraire des données même depuis les sites les plus dynamiques et les plus chargés en JavaScript — mais cela demande tout de même des compétences en code et une maintenance continue. Pour les utilisateurs métier qui veulent éviter le code et aller directement à la donnée, Thunderbit propose une alternative sans code, propulsée par l’IA, rapide, flexible et étonnamment robuste.
Voici ce que je recommanderais :
- Si vous êtes technique et avez besoin d’une personnalisation poussée, commencez avec Puppeteer.
- Si vous voulez de la rapidité, de la simplicité et moins de maintenance, essayez (la est un excellent point de départ).
- Pour la plupart des équipes, une combinaison des deux couvrira 99 % des besoins en données web.
Vous voulez découvrir d’autres guides comme celui-ci ? Consultez le pour des tutoriels, des comparatifs et les dernières nouveautés en web scraping propulsé par l’IA.
FAQ
1. Qu’est-ce qu’un puppeteer scraper et pourquoi est-il utilisé pour le web scraping ?
Puppeteer est une bibliothèque Node.js qui permet de contrôler un navigateur Chrome sans interface graphique avec JavaScript. Elle est utilisée pour le web scraping parce qu’elle peut charger du contenu dynamique, simuler des actions utilisateur et extraire des données de sites que les extracteurs traditionnels ne savent pas gérer.
2. Comment Puppeteer se compare-t-il à Selenium et Thunderbit ?
Selenium fonctionne avec plusieurs navigateurs et langages, mais il est plus lourd. Puppeteer est optimisé pour Chrome/Node.js et plus rapide pour de nombreuses tâches de scraping. Thunderbit, en revanche, est un outil sans code, propulsé par l’IA, qui permet aux utilisateurs non techniques d’extraire des données en quelques clics.
3. Quels sont les principaux avantages métier du web scraping avec Puppeteer ?
Automatiser la collecte de données fait gagner du temps, réduit les erreurs et permet d’obtenir des insights en temps réel pour les ventes, le marketing, les opérations, etc. Les cas d’usage vont de la génération de leads à la surveillance des prix et aux études de marché.
4. Quels sont les plus grands défis avec Puppeteer scraping ?
Les principaux défis sont la gestion du contenu dynamique, l’évitement des blocages anti-bot et la maintenance des scripts lorsque les sites web changent. Vous devrez écrire du code pour gérer les attentes, simuler les interactions et traiter les erreurs.
5. Quand devrais-je utiliser Thunderbit plutôt que Puppeteer ?
Utilisez Thunderbit si vous voulez éviter le codage, obtenir des résultats rapidement ou donner plus d’autonomie à des collègues non techniques. C’est idéal pour les tâches de scraping standard, les projets à délai court, ou lorsque vous souhaitez simplement exporter des données vers Excel ou Google Sheets sans difficulté.
Prêt à essayer une manière plus intelligente d’extraire des données ? ou allez plus loin avec d’autres guides sur le . Bon scraping !
En savoir plus