

Le web avance à une vitesse folle, et les besoins des boîtes suivent le rythme. Après avoir passé pas mal d’années dans le SaaS et l’automatisation, j’ai remarqué un truc : pour aller vite, il faut parfois s’appuyer sur ce qui existe déjà. Que tu veuilles analyser un concurrent, lancer un nouveau service ou juste sauvegarder ton propre site, savoir cloner un site web—c’est-à-dire capturer son contenu, sa structure, voire certaines fonctionnalités—peut vraiment booster ton équipe. Et avec l’arrivée d’outils boostés à l’IA comme Thunderbit, ce qui était réservé aux devs est maintenant accessible à tout le monde, direct depuis ton navigateur.
Soyons clairs : cloner un site web, ce n’est pas juste faire « Enregistrer sous » et basta. Les sites d’aujourd’hui sont dynamiques, interactifs, et parfois aussi fuyants qu’une anguille. Dans ce guide, je t’explique ce que ça veut vraiment dire de « cloner un site web », pourquoi c’est utile pour les pros, les galères à prévoir, et surtout—comment le faire efficacement, en toute sécurité et dans les règles grâce à des outils comme Thunderbit.
Cloner un site web : qu’est-ce que ça veut dire concrètement ?
On va mettre les choses à plat. Quand on parle de « cloner un site », ça peut vouloir dire plusieurs choses :
- Cloner le design : Reprendre l’apparence et l’ergonomie d’un site.
- Cloner le contenu : Copier les textes, images, fiches produits et toutes les infos visibles.
- Cloner les fonctionnalités : Reproduire des éléments interactifs comme les barres de recherche, formulaires ou filtres.
Pour la plupart des pros, l’intérêt principal, c’est de copier le contenu visible et les données—ce qu’on peut voir et analyser, sans forcément toucher au code source ou à la logique du site. Imagine ça comme une capture structurée de la « vitrine » d’un site, transformée en base de données exploitable pour l’analyse, le prototypage ou l’archivage.
Et pour éviter tout malentendu : cloner, ce n’est pas voler ou plagier. Dans la majorité des cas, c’est parfaitement légitime—veille concurrentielle, prototypage rapide, ou archivage pour la conformité. Le but, c’est d’aller plus vite et d’avoir des insights en s’appuyant sur ce qui marche déjà, pas de réinventer la roue ou de franchir la ligne rouge.
Pourquoi cloner un site web ? Les usages qui cartonnent en entreprise
Tu serais étonné du nombre d’équipes qui utilisent le clonage de sites au quotidien. Voilà quelques exemples concrets :
| Cas d’usage | Description & Bénéfices métier |
|---|---|
| Veille tarifaire concurrentielle | Extraire les pages produits des concurrents pour suivre les prix et les stocks. Permet d’ajuster ses tarifs en temps réel—un distributeur britannique a constaté une hausse de 4% de ses ventes. |
| Génération de leads & enrichissement CRM | Cloner des annuaires ou des pages LinkedIn pour collecter des prospects. L’automatisation peut faire gagner jusqu’à 80% de temps. |
| Réutilisation de contenu | Dupliquer des FAQ, articles de blog ou avis clients pour en extraire des insights ou les reformuler pour votre audience. |
| Prototypage & design rapide | Cloner le front-end de sites existants pour accélérer le lancement de nouveaux projets—prototyper en quelques jours au lieu de semaines. |
| Sauvegarde & archivage | Créer des copies complètes de sites pour la conformité ou la conservation d’historique. |
Et ce n’est qu’un début. Les chercheurs peuvent cloner des pages de réseaux sociaux pour analyser des tendances, les experts SEO dupliquer la structure de sites pour des audits hors ligne, et près de 2 700 sites de comparaison de prix s’appuient sur la collecte automatisée de données web. Le vrai plus, c’est la vitesse et la profondeur d’analyse—au lieu de tout faire à la main, tu récupères toutes les données en un clin d’œil.
Les galères du clonage de site web : bien plus qu’un simple copier-coller
Si cloner un site, c’était juste « Copier > Coller », tout le monde le ferait. Mais ceux qui ont déjà essayé savent que c’est loin d’être aussi simple.
Pourquoi le copier-coller ne suffit pas
- Contenu dynamique : Beaucoup de sites chargent leurs données via JavaScript, donc un simple « Enregistrer la page » te laisse avec une coquille vide—pas d’images, pas de données dynamiques (voir cette expérience).
- APIs et scripts : Certaines infos arrivent après le chargement de la page, via des APIs. Copier le HTML ne suffit pas.
- Pages protégées par login : Si les données sont derrière une connexion, il faut un outil qui gère les sessions authentifiées.
- Anti-scraping : Certains sites utilisent des CAPTCHAs, des limites de requêtes ou détectent les robots pour bloquer l’automatisation.
- Questions juridiques et éthiques : Ce n’est pas parce qu’on peut copier qu’on doit le faire. Respecter le droit d’auteur et les conditions d’utilisation, c’est la base.
Bref, cloner un site web, c’est jongler entre défis techniques et limites légales. Il ne s’agit pas juste de récupérer les données, mais de le faire proprement—et de façon responsable.
Comparatif des solutions de clonage de site : du bricolage à l’IA
Parlons outils. Il y a plusieurs façons de cloner un site web, chacune avec ses avantages et ses limites :
| Méthode | Facilité d’utilisation | Précision | Contenu dynamique | Options d’export | Conformité légale | Maintenance |
|---|---|---|---|---|---|---|
| Copie/téléchargement manuel | Moyenne | Faible | Mauvaise | HTML/CSS/JS | Dépend de l’utilisateur | Élevée (fragile) |
| Web Scraping traditionnel | Faible | Élevée* | Bonne* | CSV/Excel/JSON | Dépend de l’utilisateur | Élevée (fragile) |
| Outils IA (Thunderbit) | Très élevée | Élevée | Excellente | Excel/Sheets/Notion | Conviviale | Faible |
*Si tu maîtrises la config.
Copie/téléchargement manuel
Des outils comme HTTrack ou la fonction « Enregistrer la page » du navigateur peuvent suffire pour des sites statiques simples, mais c’est galère et inefficace sur les sites dynamiques. Tu te retrouves souvent avec des images manquantes, des styles cassés, et un dossier de fichiers inutilisable.
Web Scraping traditionnel
Ça inclut l’écriture de scripts (Python, BeautifulSoup, etc.) ou l’utilisation de scrapers visuels où tu sélectionnes les éléments à extraire. C’est puissant, mais il faut des compétences techniques ou beaucoup de réglages. Et si le site change, il faut tout refaire.
Outils IA (Thunderbit)
C’est là que ça devient fun. Thunderbit utilise l’IA pour « comprendre » la page, sans que tu aies à tout configurer. Clique sur « Suggérer les champs IA », laisse l’outil détecter automatiquement les données, et c’est parti. Il gère le contenu dynamique, la navigation multi-pages, et exporte direct vers Excel, Google Sheets, Airtable ou Notion. Le tout, sans une ligne de code.
Pour un comparatif détaillé des extensions Chrome d’extracteur web, mate cet article.
Tutoriel : cloner un site web pas à pas avec Thunderbit
Comment extraire n'importe quel site web avec l'IA Get Started Free
Prêt à te lancer ? Voilà comment je clone n’importe quel site avec Thunderbit, étape par étape.
Étape 1 : Installer et configurer Thunderbit
Va sur le site Thunderbit et crée-toi un compte gratuit. Installe ensuite l’extension Chrome Thunderbit AI Web Scraper. L’installation est aussi simple que pour n’importe quelle extension—quelques clics et c’est bon.
Une fois installée, l’icône Thunderbit s’affiche dans la barre d’outils Chrome. Clique dessus, connecte-toi, et lance ton premier projet. Petit tip : épingle l’icône pour l’avoir toujours sous la main. Si le site à cloner demande une connexion, connecte-toi d’abord—Thunderbit fonctionne avec ta session en cours.
Essayez Thunderbit AI Web Scraper gratuitement
Étape 2 : Utiliser l’IA pour détecter et structurer les données
Va sur le site à cloner (par exemple, une page produit concurrente). Ouvre le panneau latéral Thunderbit et démarre un nouveau projet. C’est là que la magie opère : clique sur « Suggérer les colonnes IA » (ou « Suggérer les champs IA »), et l’IA de Thunderbit analyse la page pour te proposer automatiquement des champs de données—nom du produit, prix, URL de l’image, note, etc.
Tu peux ajuster, ajouter ou supprimer des colonnes selon tes besoins. Besoin d’un champ en plus, genre « Disponibilité » ou « Référence » ? Ajoute-le, et l’IA va essayer de le remplir. Pas besoin de connaître le HTML—l’IA gère tout.
Étape 3 : Extraire et exporter les données du site
Une fois tes colonnes prêtes, clique sur « Extraire » (ou « Démarrer »). Thunderbit va collecter toutes les données pour les champs sélectionnés, ligne par ligne. Si la page contient plusieurs éléments (genre une liste de produits), il les récupère tous.
Et pour la pagination ou le scroll infini ? Thunderbit gère la plupart des cas tout seul—s’il y a un bouton « Suivant » ou un chargement au scroll, il continue. Pour les cas plus tordus, tu peux scroller manuellement ou ajuster les paramètres, mais pour la majorité des sites pros, ça roule.
À la fin, tes données s’affichent dans un tableau bien propre. L’export est instantané : envoie-les vers Excel, Google Sheets, Airtable ou Notion. Fini les galères de CSV—tes données sont prêtes à l’emploi.
Pour plus de détails, checke le guide Thunderbit sur l’extraction de sites avec l’IA.
Aller plus loin : extraction des sous-pages pour un clonage complet
Extraction de sous-pages avec Thunderbit Get Started Free
C’est là que Thunderbit fait la différence : l’extraction de sous-pages. Beaucoup de sites n’affichent qu’un résumé sur la page principale (nom, prix), mais les infos importantes—descriptions, caractéristiques, avis—sont planquées sur des pages secondaires.
L’extraction de sous-pages de Thunderbit permet d’aller chercher tout ça. Active cette option, et l’IA va suivre les liens depuis la page principale vers chaque fiche détaillée, récupérer les infos en plus, puis tout fusionner dans ta base principale. Par exemple, pour cloner une catégorie « vestes d’hiver » d’un site e-commerce, Thunderbit peut ouvrir chaque fiche produit et extraire les matériaux, la dispo, les avis clients, etc.—tu obtiens une copie complète et structurée de toute la gamme.
Un vrai gain de temps pour les pros. Que tu construises une base de leads, archives une base de connaissances ou analyses un catalogue complet, l’extraction de sous-pages te garantit de ne rien louper.
Pour voir ça en action, mate Thunderbit sur l’extraction de sous-pages.
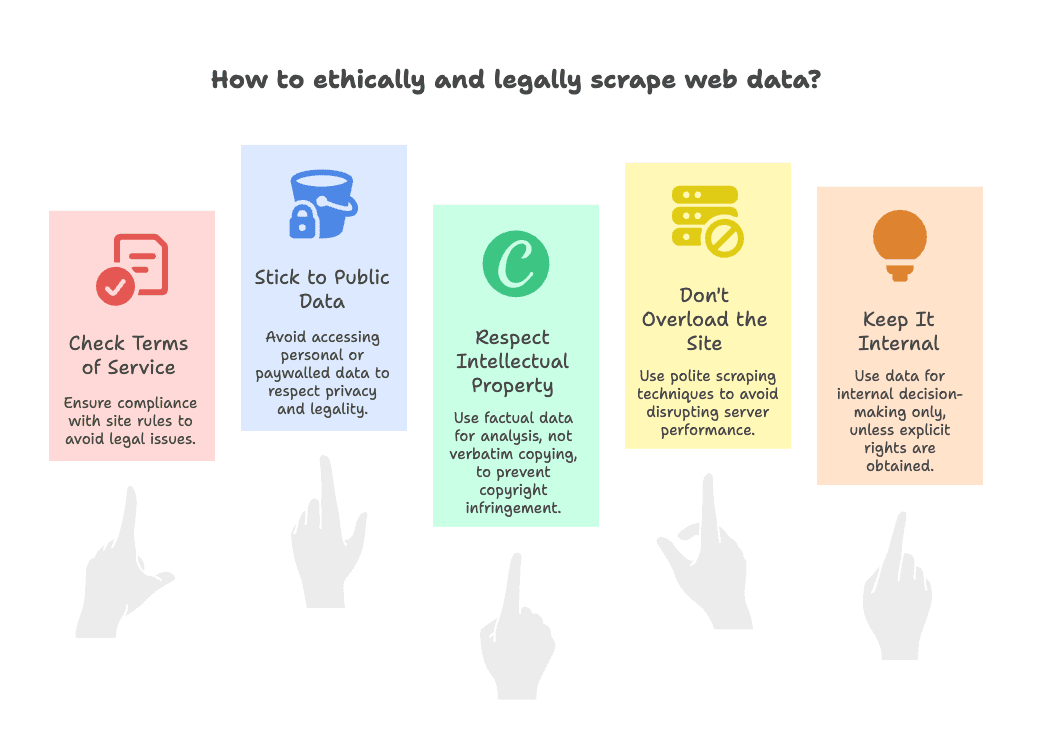
Respecter la loi : cloner un site web sans souci
On attaque le sujet qui fâche : Est-ce légal de cloner un site web ?
La réponse courte : en général oui, si tu respectes quelques règles de base. Voici ma checklist pour rester dans les clous :
- Vérifie les conditions d’utilisation : Certains sites interdisent clairement l’extraction de données. Dans ce cas, fais gaffe—utilise les données en interne, pas pour les republier (plus d’infos sur le risque juridique).
- Reste sur les données publiques : N’extrais que ce qui est visible sans connexion. Évite les données perso, emails ou contenus derrière un paywall (voir les recommandations légales).
- Respecte la propriété intellectuelle : Les données factuelles (prix, noms de produits) sont généralement OK. Copier du contenu créatif (articles, images) peut poser souci—utilise-les pour l’analyse, pas pour créer un site clone (plus sur la PI).
- N’abuse pas des serveurs : Sois « poli »—n’inonde pas le site de requêtes. Thunderbit limite déjà le rythme, mais reste toujours respectueux (infos sur robots.txt).
- Usage interne uniquement : Sauf autorisation explicite, limite-toi à l’utilisation interne des données clonées.
Thunderbit facilite la conformité en permettant d’exporter direct vers des plateformes sécurisées comme Google Sheets ou Airtable, pour un partage maîtrisé en interne. Pour plus de conseils juridiques, checke ce guide complet.
Astuces avancées : exploiter tout le potentiel de Thunderbit pour le clonage
Une fois les bases maîtrisées, voici quelques tips pour aller plus loin :
- Sites dynamiques et interactifs : Pour les contenus qui s’affichent après une action (genre « Voir tous les avis »), fais l’action manuellement, puis lance Thunderbit. L’IA prendra ce qui est affiché. Pour le scroll infini, fais défiler par étapes ou utilise la pagination intégrée (plus d’astuces ici).
- Prompts IA personnalisés : Guide l’IA en nommant précisément tes colonnes—par exemple « Auteur (texte après Par :) » ou « Résumé des avantages ». Thunderbit comprend le contexte, donc des noms clairs servent d’instructions (voir des exemples).
- Transformation des données par IA : Utilise la fonction de résumé IA de Thunderbit ou connecte-toi à ChatGPT pour analyser, catégoriser ou traduire les données à la volée (idées d’intégration).
- Programmation d’extractions régulières : Planifie des extractions automatiques pour surveiller l’évolution des prix ou des offres d’emploi (infos sur le cloud scraping).
- Extraction en masse via liste d’URLs : Donne à Thunderbit une liste d’URLs, il les traite tout seul—parfait si tu as déjà collecté des liens ailleurs.
- Modèles pour les sites populaires : Utilise les modèles instantanés de Thunderbit pour des sites comme Amazon ou Zillow, puis adapte-les à tes besoins (détails sur les modèles).
- Gestion des cas complexes : Si tu tombes sur des CAPTCHAs ou des structures bizarres, tente l’extraction en deux temps ou ajuste tes colonnes. L’IA de Thunderbit est solide, mais un petit check rapide ne fait jamais de mal.
Pour des workflows encore plus poussés, explore l’API et les intégrations Thunderbit.
Cloner n'importe quel site avec Thunderbit IA
Conclusion & points clés : cloner un site web sans prise de tête
Cloner un site web, ce n’est plus réservé aux devs—c’est une technique à la portée de toutes les équipes commerciales, marketing ou opérationnelles. À retenir :
- Valeur métier : Le clonage de site, c’est un vrai retour sur investissement—pour devancer la concurrence, gagner du temps ou prendre de meilleures décisions (chiffres du secteur).
- Défis & solutions : Les sites modernes sont complexes, mais des outils comme Thunderbit rendent le clonage précis, rapide et accessible à tous.
- L’avantage Thunderbit : Avec des fonctions comme « Suggérer les colonnes IA » et l’extraction de sous-pages, Thunderbit transforme des heures de boulot manuel en quelques clics.
- Respect de la loi : Cloner de façon responsable—reste sur les données publiques, respecte la propriété intellectuelle, et utilise les données pour l’analyse ou la prise de décision interne.
- Aller plus loin : Grâce aux astuces avancées et aux intégrations, Thunderbit gère même les sites et workflows les plus costauds.
La prochaine fois que tu tombes sur une page produit concurrente, un annuaire de prospects ou une base de connaissances à analyser—sache que tu as les outils pour cloner les données de ce site en toute confiance. Utilise-les intelligemment, et que tes projets data cartonnent !
Essayez Thunderbit AI Web Scraper maintenant Get Started Free
FAQ
1. Est-ce légal de cloner un site web à des fins pros ?
En général, oui—si tu restes sur les données publiques, respectes la propriété intellectuelle et utilises les données en interne. Vérifie toujours les conditions d’utilisation du site et évite d’extraire des données perso ou protégées sans autorisation. Pour en savoir plus, checke ce guide juridique.
2. Quelle différence entre cloner un site et l’extraire (scraping) ?
Cloner, c’est généralement copier le contenu, la structure ou le design d’un site, alors que l’extraction (scraping) vise à récupérer des données précises. Avec des outils comme Thunderbit, la frontière est mince—tu peux extraire et structurer les données pour « cloner » ce qui t’intéresse.
3. Thunderbit gère-t-il le contenu dynamique et les sous-pages ?
Oui ! L’IA de Thunderbit est faite pour gérer le contenu dynamique (chargé en JavaScript) et peut suivre les liens pour extraire les sous-pages, en fusionnant tout dans un seul jeu de données. C’est l’une des méthodes les plus simples pour obtenir une copie complète d’un site.
4. Comment exporter les données clonées vers Excel ou Google Sheets ?
Après extraction avec Thunderbit, tu peux exporter tes données direct vers Excel, Google Sheets, Airtable ou Notion en quelques clics. Pas besoin de bidouiller—tes données sont prêtes à être analysées ou partagées.
5. Des astuces pour cloner des sites complexes ?
Utilise des prompts IA personnalisés pour extraire pile les champs que tu veux, programme des extractions régulières pour une veille continue, et exploite les fonctions d’extraction en masse ou les modèles Thunderbit pour gagner du temps. Pour les sites interactifs, fais les actions manuellement avant d’extraire, et vérifie toujours la qualité de tes données.




