Les données en ligne explosent — et la pression pour suivre le rythme aussi. Je l’ai vu de près : les équipes commerciales et opérationnelles passent souvent plus de temps à dompter des tableurs et à faire du copier-coller depuis des sites web qu’à prendre de vraies décisions. D’après Salesforce, les commerciaux consacrent désormais , et Asana indique que . Résultat : un paquet d’heures cramées en collecte manuelle — des heures qui pourraient plutôt servir à closer des deals ou à lancer des campagnes.
Bonne nouvelle : le web scraping avec ruby s’est vraiment démocratisé, et tu n’as pas besoin d’être dev pour en profiter. Ruby est depuis longtemps un choix “go-to” pour automatiser l’extraction de données web. Mais en le combinant avec des solutions modernes comme un extracteur web ia tel que , tu obtiens le meilleur des deux mondes : la souplesse pour les codeurs, et la simplicité d’un extracteur web sans code pour tout le monde. Que tu sois marketeur, responsable e-commerce, ou juste à bout du copier-coller à répétition, ce guide te montre comment maîtriser le web scraping avec Ruby et l’IA — sans écrire de code.
Qu’est-ce que le web scraping avec Ruby ? La porte d’entrée vers des données automatisées
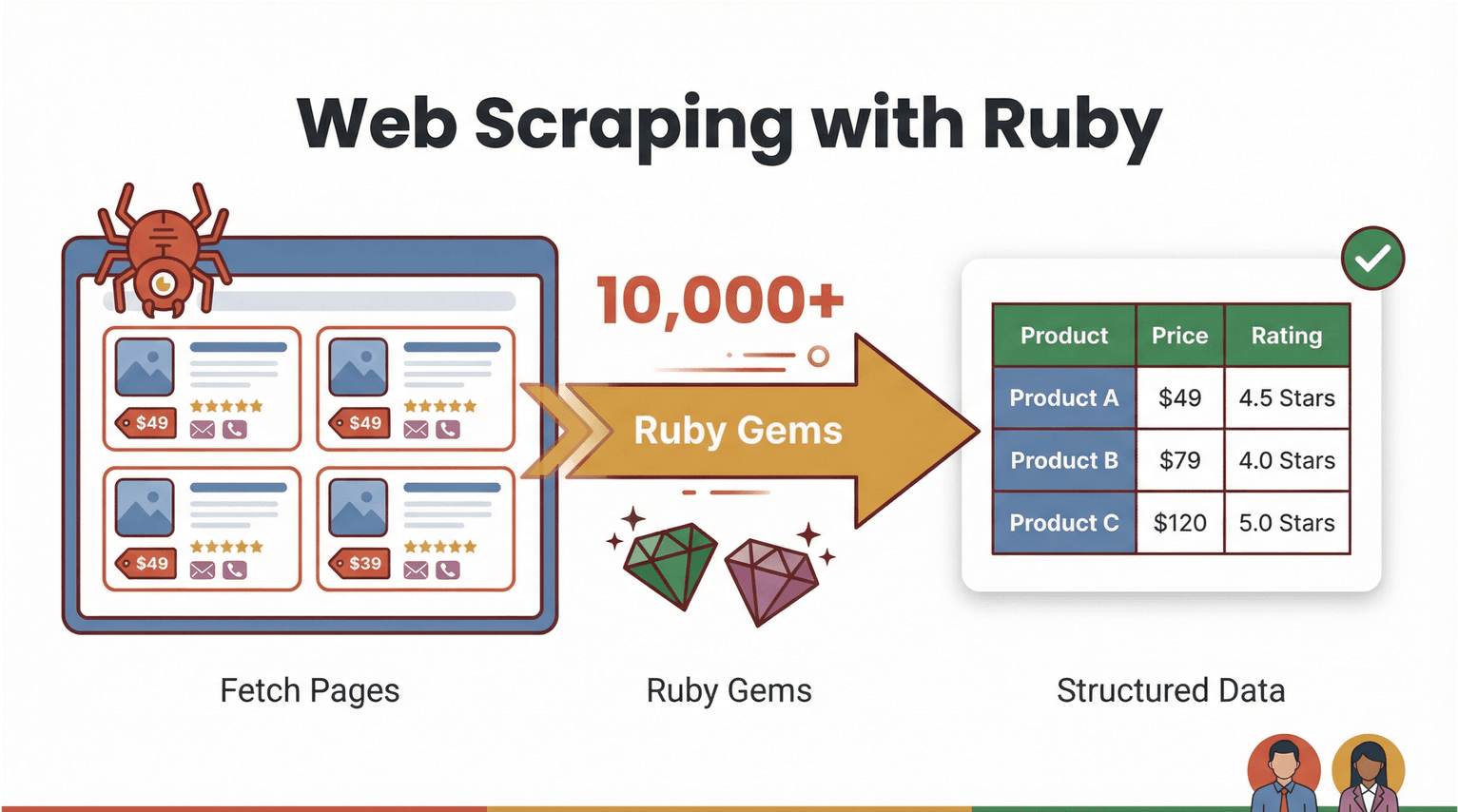
On repart des bases. Le web scraping consiste à utiliser un logiciel pour récupérer des pages web et en extraire des infos précises — par exemple des prix, des coordonnées ou des avis — afin de les transformer en données structurées (CSV, Excel, etc.). Avec Ruby, le web scraping est à la fois costaud et accessible. Le langage est connu pour sa syntaxe lisible et son gros écosystème de “gems” (bibliothèques) qui rendent l’automatisation beaucoup plus simple ().
À quoi ressemble concrètement le “web scraping avec ruby” ? Imagine que tu veuilles récupérer tous les noms de produits et leurs prix sur un site e-commerce. Avec Ruby, tu peux écrire un script qui :
- Télécharge la page web (avec une bibliothèque comme )
- Analyse le HTML pour repérer les données souhaitées (avec )
- Exporte le tout vers un tableur ou une base de données
Mais voilà le vrai game changer : tu n’as pas toujours besoin d’écrire du code. Des solutions d’extracteur web sans code basées IA, comme , peuvent maintenant faire le gros du taf — lire la page, détecter les champs, et sortir des tableaux propres en quelques clics. Ruby reste un excellent “ciment d’automatisation” pour des workflows sur mesure, mais les extracteur web ia ouvrent clairement la voie aux équipes métier.
Pourquoi le web scraping avec Ruby est important pour les équipes métier

Soyons francs : personne n’a envie de passer sa journée à faire du copier-coller. La demande d’extraction automatisée de données web explose — et ce n’est pas pour rien. Voilà comment le web scraping avec Ruby (et les outils IA) change la donne côté ops :
- Génération de leads : récupère direct des coordonnées depuis des annuaires ou LinkedIn pour alimenter ton pipeline.
- Suivi des prix concurrents : surveille les variations de prix sur des centaines de références e-commerce — terminé les checks manuels.
- Création de catalogues produits : regroupe descriptions, caractéristiques et images pour ta boutique ou marketplace.
- Études de marché : collecte avis, notes ou articles pour analyser les tendances.
Le ROI saute aux yeux : les équipes qui automatisent la collecte de données web gagnent des heures chaque semaine, réduisent les erreurs et obtiennent des données plus fraîches et plus fiables. Dans l’industrie, par exemple, , alors même que le volume de données a doublé en seulement deux ans. L’opportunité d’automatisation est énorme.
Voici un résumé rapide de la valeur apportée par Ruby et les outils IA :
| Cas d’usage | Point de douleur en manuel | Bénéfice de l’automatisation | Résultat typique |
|---|---|---|---|
| Génération de leads | Copier les emails un par un | Extraire des milliers en quelques minutes | 10x plus de leads, moins de tâches ingrates |
| Suivi des prix | Vérifications quotidiennes | Collecte planifiée et automatisée | Veille tarifaire en temps réel |
| Création de catalogue | Saisie manuelle | Extraction en masse + mise en forme | Lancements plus rapides, moins d’erreurs |
| Études de marché | Lire les avis à la main | Collecte et analyse à grande échelle | Insights plus profonds et plus récents |
Et ce n’est pas qu’une question de vitesse : l’automatisation réduit les erreurs et rend les données plus cohérentes — un point crucial quand .
Explorer les solutions : scripts Ruby vs outils Extracteur Web IA
Alors, est-ce qu’il vaut mieux coder son propre script Ruby ou passer par un extracteur web ia en mode extracteur web sans code ? On découpe ça proprement.
Scripts Ruby : contrôle total, maintenance plus lourde
L’écosystème Ruby est blindé de gems pour tous les besoins :
- : la référence pour analyser HTML et XML.
- : pour récupérer des pages web et des API.
- : pratique quand il faut gérer cookies, formulaires et navigation.
- / : pour piloter un vrai navigateur (top pour les sites très JavaScript).
Avec des scripts Ruby, tu gagnes en flexibilité : logique personnalisée, nettoyage des données, intégration à tes systèmes. En échange, tu prends la maintenance : si le site change de structure, ton script peut casser. Et si tu n’es pas à l’aise avec le code, il y a forcément une courbe d’apprentissage.
Extracteurs Web IA & outils sans code : rapides, simples et adaptatifs
Les solutions d’extracteur web sans code modernes comme changent complètement l’approche. Au lieu d’écrire du code, tu :
- Ouvres l’extension Chrome
- Cliques sur « AI Suggest Fields » pour laisser l’IA détecter quoi extraire
- Lances « Scrape » puis exportes tes données
L’IA de Thunderbit s’adapte aux changements de mise en page, gère les sous-pages (comme les fiches produit) et exporte directement vers Excel, Google Sheets, Airtable ou Notion. C’est parfait pour les équipes métier qui veulent des résultats sans prise de tête.
Comparatif rapide :
| Approche | Avantages | Inconvénients | Idéal pour |
|---|---|---|---|
| Scripts Ruby | Contrôle total, logique sur mesure, flexible | Apprentissage plus long, maintenance | Développeurs, utilisateurs avancés |
| Extracteur Web IA | Sans code, mise en place rapide, s’adapte | Moins de granularité, certaines limites | Équipes métier, ops |
La tendance est claire : à mesure que les sites deviennent plus complexes (et plus “défensifs”), les extracteur web ia deviennent le choix naturel pour la plupart des usages métier.
Bien démarrer : configurer votre environnement Ruby pour le web scraping
Si tu veux tester l’approche “script Ruby”, on commence par préparer l’environnement. Bonne nouvelle : Ruby s’installe facilement sur Windows, macOS et Linux.
Étape 1 : installer Ruby
- Windows : télécharge et suis l’assistant. Pense à inclure MSYS2 pour compiler les extensions natives (nécessaire pour des gems comme Nokogiri).
- macOS/Linux : utilise pour gérer les versions. Dans le Terminal :
1brew install rbenv ruby-build
2rbenv install 4.0.1
3rbenv global 4.0.1(Consulte la pour la dernière version stable.)
Étape 2 : installer Bundler et les gems essentielles
Bundler sert à gérer les dépendances :
1gem install bundlerCrée un Gemfile pour ton projet :
1source 'https://rubygems.org'
2gem 'nokogiri'
3gem 'httparty'Puis exécute :
1bundle installTon environnement est ainsi clean et prêt pour l’extraction.
Étape 3 : vérifier l’installation
Teste dans IRB (le shell interactif Ruby) :
1require 'nokogiri'
2require 'httparty'
3puts Nokogiri::VERSIONSi un numéro de version s’affiche, c’est carré.
Pas à pas : créer votre premier Extracteur Web Ruby
Voyons un exemple concret : extraire des données produits depuis , un site fait exprès pour s’entraîner au scraping.
Voici un script Ruby simple pour récupérer titres, prix et disponibilité :
1require "net/http"
2require "uri"
3require "nokogiri"
4require "csv"
5BASE_URL = "https://books.toscrape.com/"
6def fetch_html(url)
7 uri = URI.parse(url)
8 res = Net::HTTP.get_response(uri)
9 raise "HTTP #\{res.code\} for #\{url\}" unless res.is_a?(Net::HTTPSuccess)
10 res.body
11end
12def scrape_list_page(list_url)
13 html = fetch_html(list_url)
14 doc = Nokogiri::HTML(html)
15 products = doc.css("article.product_pod").map do |pod|
16 title = pod.css("h3 a").first["title"]
17 price = pod.css(".price_color").text.strip
18 stock = pod.css(".availability").text.strip.gsub(/\s+/, " ")
19 { title: title, price: price, stock: stock }
20 end
21 next_rel = doc.css("li.next a").first&.[]("href")
22 next_url = next_rel ? URI.join(list_url, next_rel).to_s : nil
23 [products, next_url]
24end
25rows = []
26url = "#\{BASE_URL\}catalogue/page-1.html"
27while url
28 products, url = scrape_list_page(url)
29 rows.concat(products)
30end
31CSV.open("books.csv", "w", write_headers: true, headers: %w[title price stock]) do |csv|
32 rows.each { |r| csv << [r[:title], r[:price], r[:stock]] }
33end
34puts "Wrote #\{rows.length\} rows to books.csv"Ce script récupère chaque page, analyse le HTML, extrait les données et les écrit dans un fichier CSV. Tu peux ouvrir books.csv dans Excel ou Google Sheets.
Pièges fréquents :
- Si des erreurs indiquent des gems manquantes, vérifie ton Gemfile puis relance
bundle install. - Pour les sites qui chargent les données via JavaScript, il faudra un outil d’automatisation de navigateur comme Selenium ou Watir.
Booster le scraping Ruby avec Thunderbit : l’Extracteur Web IA en action
Voyons maintenant comment peut te faire passer au niveau supérieur — sans code.
Thunderbit est une qui permet d’extraire des données structurées depuis n’importe quel site en deux clics. Comment ça marche :
- Ouvre l’extension Thunderbit sur la page à extraire.
- Clique sur « AI Suggest Fields ». L’IA analyse la page et propose les meilleures colonnes (ex. « Product Name », « Price », « Stock »).
- Clique sur « Scrape ». Thunderbit collecte les données, gère la pagination et peut même suivre des sous-pages si tu as besoin de détails.
- Exporte tes données directement vers Excel, Google Sheets, Airtable ou Notion.
Ce qui fait la différence avec Thunderbit, c’est sa capacité à gérer des pages complexes et dynamiques — sans sélecteurs fragiles ni code. Et si tu veux mixer les approches, tu peux extraire avec Thunderbit puis traiter/enrichir ensuite via un script Ruby.
Astuce pro : la fonction d’extraction des sous-pages de Thunderbit est en or pour l’e-commerce et l’immobilier. Tu extrais une liste de liens produits, puis tu laisses Thunderbit visiter chaque fiche pour récupérer caractéristiques, images ou avis — et enrichir automatiquement ton dataset.
Exemple concret : extraire des données produits et prix e-commerce avec Ruby et Thunderbit
On met tout ensemble avec un workflow concret, pensé pour les équipes e-commerce.
Scénario : tu veux surveiller les prix et détails produits de concurrents sur des centaines de SKU.
Étape 1 : utiliser Thunderbit pour extraire la liste principale de produits
- Ouvre la page de listing produits du concurrent.
- Lance Thunderbit, clique sur « AI Suggest Fields » (ex. Product Name, Price, URL).
- Clique sur « Scrape » et exporte en CSV.
Étape 2 : enrichir les données via l’extraction des sous-pages
- Dans Thunderbit, utilise « Scrape Subpages » pour visiter chaque fiche produit et extraire des champs supplémentaires (description, stock, images, etc.).
- Exporte le tableau enrichi.
Étape 3 : traiter ou analyser avec Ruby
- Utilise un script Ruby pour nettoyer, transformer ou analyser davantage. Par exemple :
- Convertir les prix dans une devise standard
- Filtrer les produits en rupture
- Générer des statistiques de synthèse
Exemple de snippet Ruby pour ne garder que les produits en stock :
1require 'csv'
2rows = CSV.read('products.csv', headers: true)
3in_stock = rows.select { |row| row['stock'].include?('In stock') }
4CSV.open('in_stock_products.csv', 'w', write_headers: true, headers: rows.headers) do |csv|
5 in_stock.each { |row| csv << row }
6endRésultat :
Tu passes de pages web brutes à un tableau propre et exploitable — prêt pour l’analyse tarifaire, la planification des stocks ou des campagnes marketing. Et tout ça sans écrire une seule ligne de code de scraping.
Sans code, aucun souci : automatiser l’extraction de données web pour tous
Ce que j’aime particulièrement avec Thunderbit, c’est qu’il redonne la main aux utilisateurs non techniques. Pas besoin de connaître Ruby, HTML ou CSS : tu ouvres l’extension, tu laisses l’IA bosser, puis tu exportes.
Courbe d’apprentissage : avec des scripts Ruby, il faut apprendre les bases de la programmation et la structure du web. Avec Thunderbit, la prise en main se fait en minutes, pas en jours.
Intégrations : Thunderbit exporte directement vers les outils déjà utilisés par les équipes : Excel, Google Sheets, Airtable, Notion. Tu peux même planifier des extractions récurrentes pour un suivi continu.
Retours terrain : j’ai vu des équipes marketing, sales ops et e-commerce automatiser la création de listes de prospects, le suivi des prix, et bien plus — sans solliciter l’IT.
Bonnes pratiques : combiner Ruby et Extracteur Web IA pour une automatisation scalable
Pour construire un workflow solide et qui tient la route dans le temps, voilà mes recommandations :
- Gérer les changements de site : les extracteur web ia comme Thunderbit s’adaptent automatiquement, mais avec des scripts Ruby, prévois de mettre à jour les sélecteurs quand le site bouge.
- Planifier les extractions : utilise la planification de Thunderbit pour des collectes régulières. Côté Ruby, configure un cron ou un planificateur de tâches.
- Traitement par lots : pour de gros volumes, découpe en lots afin d’éviter les blocages ou la surcharge.
- Mise en forme des données : nettoie et valide avant analyse — les exports Thunderbit sont structurés, mais des scripts Ruby sur mesure peuvent nécessiter des contrôles supplémentaires.
- Conformité : n’extrais que des données publiques, respecte
robots.txtet tiens compte des lois sur la vie privée (notamment dans l’UE — ). - Plans de secours : si un site devient trop complexe ou bloque l’extraction, privilégie les API officielles ou d’autres sources.
Quand utiliser quoi ?
- Utilise des scripts Ruby si tu as besoin d’un contrôle total, de logique personnalisée ou d’intégrations internes.
- Utilise Thunderbit si tu cherches la rapidité, la simplicité et l’adaptabilité — surtout pour des tâches métier ponctuelles ou récurrentes.
- Combine les deux pour des workflows avancés : Thunderbit pour l’extraction, Ruby pour l’enrichissement, la QA ou l’intégration.
Conclusion & points clés
Le web scraping avec ruby a toujours été un superpouvoir pour automatiser la collecte de données — mais avec des extracteur web ia comme Thunderbit, cette puissance devient accessible à tous. Que tu sois développeur en quête de flexibilité ou utilisateur métier qui veut des résultats, tu peux automatiser l’extraction, économiser des heures de travail manuel et décider plus vite, avec de meilleures données.
À retenir :
- Ruby est un excellent outil pour le web scraping et l’automatisation, notamment grâce à Nokogiri et HTTParty.
- Les extracteur web ia comme Thunderbit rendent l’extraction accessible aux non-codeurs, avec « AI Suggest Fields » et l’extraction de sous-pages.
- Associer Ruby et Thunderbit offre le meilleur des deux mondes : extraction rapide sans code + automatisation et analyse sur mesure.
- Automatiser la collecte de données web est un levier majeur pour les équipes sales, marketing et e-commerce : moins d’effort manuel, plus de précision, et de nouveaux insights.
Prêt à te lancer ? , teste un script Ruby simple et mesure le temps gagné. Et pour aller plus loin, consulte le : guides, astuces et exemples concrets.
FAQ
1. Dois-je savoir coder pour utiliser Thunderbit pour le web scraping ?
Non. Thunderbit est pensé pour les utilisateurs non techniques. Ouvre l’extension, clique sur « AI Suggest Fields » et laisse l’IA faire le reste. Tu peux exporter vers Excel, Google Sheets, Airtable ou Notion — sans écrire de code.
2. Quels sont les principaux avantages de Ruby pour le web scraping ?
Ruby propose des bibliothèques puissantes comme Nokogiri et HTTParty pour créer des workflows d’extraction flexibles et personnalisés. C’est idéal pour les développeurs qui veulent un contrôle total, une logique sur mesure et des intégrations avec d’autres systèmes.
3. Comment fonctionne la fonctionnalité « AI Suggest Fields » de Thunderbit ?
L’IA de Thunderbit analyse la page web, identifie les champs les plus pertinents (noms de produits, prix, emails, etc.) et propose un tableau structuré. Tu peux ajuster les colonnes avant de lancer l’extraction.
4. Puis-je combiner Thunderbit et des scripts Ruby pour des workflows avancés ?
Oui. Beaucoup d’équipes utilisent Thunderbit pour extraire des données (notamment sur des sites complexes ou dynamiques), puis les traitent ou les analysent avec Ruby. Cette approche hybride est parfaite pour du reporting sur mesure ou l’enrichissement de données.
5. Le web scraping est-il légal et sûr pour un usage professionnel ?
Le web scraping est légal si tu collectes des données publiques et respectes les conditions d’utilisation des sites ainsi que les lois sur la confidentialité. Vérifie toujours robots.txt et évite d’extraire des données personnelles sans consentement — en particulier pour les utilisateurs de l’UE soumis au RGPD.
Envie de voir comment le web scraping peut transformer ta façon de travailler ? Essaie l’offre gratuite de Thunderbit ou teste un script Ruby dès aujourd’hui. Et si tu bloques, le et la regorgent de tutoriels et de conseils pour maîtriser l’automatisation des données web — sans code.
En savoir plus