Si vous évaluez des outils de web scraping en 2026, vous ne cherchez sans doute pas une leçon de philosophie. Vous voulez une shortlist fiable, un moyen rapide de distinguer les outils faits pour les équipes métier des stacks lourdes côté ingénierie, et assez d'éléments concrets pour ne pas vous tromper d'achat. C'est exactement le rôle de cette page.
Réponse rapide
Si seule la logique de choix vous intéresse, retenez ceci :
- Optez pour un extracteur web doté d'IA si votre objectif est de passer du site au tableur le plus vite possible, avec une configuration minimale.
- Optez pour un scraper sans code si vous avez besoin de plus de contrôle sur les tâches, de planification ou d'exécutions cloud, sans écrire la moindre ligne de code.
- Optez pour une plateforme API si votre équipe a besoin de rendu, de rotation de proxy, de contournement anti-bot ou d'intégration dans un produit interne.
- Optez pour une bibliothèque open source si vous voulez un contrôle total et que vous pouvez assumer la maintenance, les sélecteurs, l'infrastructure et les pannes.
L'article conserve ses 20 outils, mais la logique de recommandation est volontairement simple : partez de l'outil le plus léger capable de gérer votre flux de travail de manière fiable, et ne descendez dans la pile que lorsque la maintenance, le blocage ou l'échelle vous y poussent.
Tableau comparatif express : les meilleurs outils de web scraping en 2026
Les prix et les modèles ci-dessous ont été vérifiés sur les pages officielles produit ou tarifs le 8 mai 2026. Quand un éditeur facture à l'usage ou par devis personnalisé, je décris le modèle plutôt que de prétendre à un prix affiché universel.
| Outil | Type | Idéal pour | Pourquoi il reste dans la liste 2026 | Modèle de tarification (vérifié en mai 2026) |
|---|---|---|---|---|
| Thunderbit | Extracteur web IA | Ventes, opérations, e-commerce, immobilier | Le chemin le plus rapide pour les non-développeurs : suggestion de champs par IA, sous-pages, exports, flux navigateur + cloud | Formule gratuite, offres payantes, tarification entreprise sur mesure |
| Browse AI | Extracteur web IA | Profils métier qui surveillent des sites web | Robots sans code puissants, surveillance et sorties type tableur ou API | Formule gratuite, offres payantes, offre premium gérée |
| Bardeen | Automatisation IA + scraping | Revenue ops et flux navigateur | Pertinent quand le scraping n'est qu'une étape d'un flux d'automatisation plus large | Formule gratuite et offres payantes |
| Diffbot | Plateforme d'extraction IA | Grands comptes et équipes data | Le meilleur choix quand vous voulez de l'extraction IA combinée à des flux de données structurées à grande échelle | Tarification entreprise |
| Instant Data Scraper | Extracteur navigateur léger | Utilisateurs occasionnels et extraction rapide de tableaux | L'un des moyens les plus simples pour récupérer en CSV une liste ou un tableau visible | Gratuit |
| Octoparse | Scraper sans code | Analystes et équipes ops aux tâches récurrentes plus lourdes | Générateur visuel mature avec extraction cloud, anti-blocage et modèles | Formule gratuite, offres payantes à partir de 69 USD/mois, offre entreprise sur mesure |
| ParseHub | Scraper low-code | Analystes qui veulent logique et contrôle desktop | Logique de projet flexible et navigation imbriquée, mais courbe d'apprentissage plus raide que les outils IA récents | Formule gratuite et offres payantes |
| Web Scraper | Scraper sans code | Débutants et tâches cloud légères | Bon point d'entrée si vous aimez le scraping par sitemap et la configuration d'abord dans le navigateur | Extension gratuite, offres cloud payantes |
| Data Miner | Scraper navigateur | Chercheurs et équipes growth | Toujours utile pour une extraction rapide par recettes directement dans le navigateur | Formule gratuite et offres payantes |
| Apify | Plateforme API + Actors | Équipes techniques et opérateurs hybrides | Excellent écosystème d'Actors couplé à un runtime personnalisé quand les extensions navigateur ne suffisent plus | Formule gratuite, offre starter à partir de 29 USD/mois plus usage, paliers supérieurs payants |
| ScrapingBee | API de scraping | Développeurs qui visent des sites lourds en JavaScript | Bon choix quand vous voulez rendu et gestion des proxies sans bâtir vous-même la couche navigateur | Essai gratuit et offres payantes |
| ScraperAPI | API de scraping | Développeurs qui montent en charge vite | API simple, crédits d'essai, produits structurés et infrastructure facile à déléguer | Essai de 7 jours avec 5 000 crédits, offres payantes à partir de 49 USD/mois |
| Bright Data | API entreprise + plateforme de proxies | Programmes à fort volume et très sensibles à la conformité | La stack de collecte de données la plus large quand déblocage, proxies et acquisition gérée priment sur la simplicité | Tarification à l'usage et selon les produits |
| Oxylabs | API entreprise + plateforme de proxies | Équipes qui achètent le scraping comme infrastructure | Très solide pour la collecte à grande échelle, notamment sur prix, SEO et études de marché | API Web Scraper à partir de 49 USD/mois ; tarification des proxies variable |
| Zyte | API + pile anti-bot | Développeurs et équipes data | Bon choix si vous voulez une extraction orientée API avec navigateur, rotation et évitement de détection robustes | Essai avec 5 USD de crédit gratuit, engagements basés sur l'usage |
| Selenium | Automatisation navigateur open source | Automatisation type QA et flux interactifs complexes | Toujours utile quand la fidélité d'interaction utilisateur compte plus que le débit | Gratuit et open source |
| BeautifulSoup4 | Parseur open source | Débutants et analyse légère | Idéal comme parseur dans une stack simple, pas comme plateforme complète | Gratuit et open source |
| Scrapy | Framework de crawl open source | Crawlers personnalisés en production | Le meilleur compromis entre puissance et maturité quand vous gérez le pipeline vous-même | Gratuit et open source |
| Puppeteer | Automatisation navigateur open source | Scraping orienté Node et scripting navigateur | Excellent si votre équipe maîtrise déjà l'écosystème Chrome/Node | Gratuit et open source |
| Playwright | Automatisation navigateur open source | Automatisation moderne multi-navigateurs | Souvent le choix le plus propre pour l'automatisation moderne, avec une ergonomie développeur remarquable | Gratuit et open source |
Comment j'ai évalué ces outils
J'ai retenu quatre critères :
- Temps avant le premier scraping réussi Si un profil non technique n'obtient pas vite des données utiles, c'est un vrai problème.
- Charge de maintenance Une configuration rapide ne vaut rien si le flux casse au moindre changement de site.
- Plafond d'échelle Certains outils sont parfaits pour 50 pages par semaine, catastrophiques pour 5 millions de requêtes par mois.
- Adéquation au flux de travail Le meilleur outil pour une équipe revenue ops est rarement le meilleur pour une équipe data platform.
Le résultat n'est pas un classement universel. C'est une grille d'aide à la décision : d'abord la bonne catégorie d'outil, ensuite le bon produit à l'intérieur.
De quel type d'outil de web scraping avez-vous réellement besoin ?
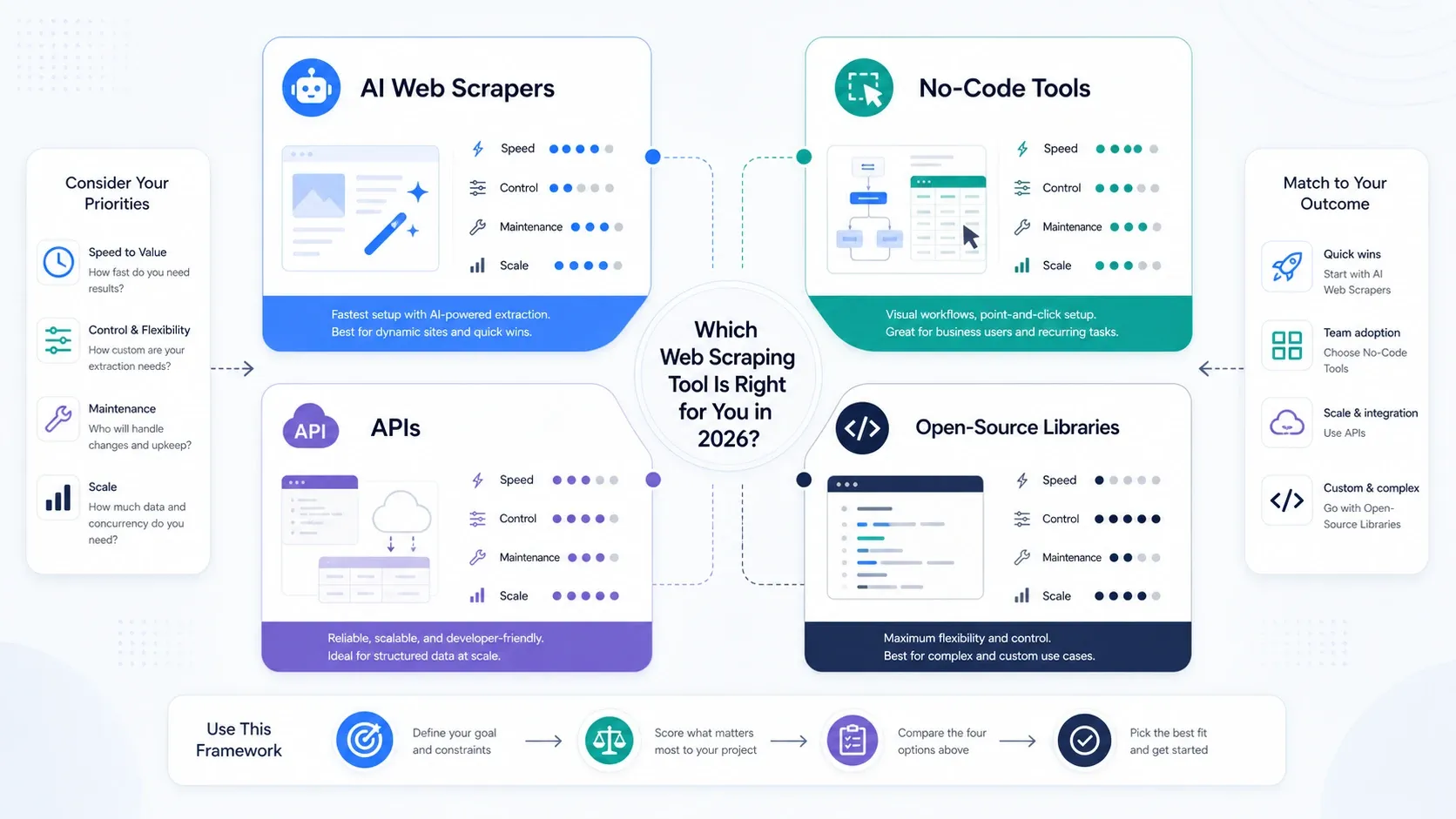
- Choisissez les extracteurs web IA si votre objectif principal est la vitesse opérationnelle.
- Choisissez les outils sans code si vous avez besoin de pagination, de planification et de contrôle reproductible des tâches.
- Choisissez les API et plateformes de scraping si rendu, rotation et capacité de déblocage deviennent votre principal goulot d'étranglement.
- Choisissez les bibliothèques open source si votre équipe valorise le contrôle plus que la commodité et peut maintenir la stack en interne.
Si votre équipe hésite entre ops et ingénierie pour le scraping, commencez par un outil IA ou sans code. Vous apprendrez ce qui compte beaucoup plus vite en lançant de vrais jobs qu'en sur-architecturant la stack dès le départ.
Les meilleurs extracteurs web IA pour les équipes métier
Voici les outils que je regarderais en premier si votre objectif est d'obtenir des données prêtes pour un tableur avec un minimum de configuration.
1. Thunderbit
Thunderbit est l'option la plus simple de cette liste si votre équipe veut extraire des données structurées sans apprendre les sélecteurs, le scripting navigateur ou l'infrastructure de scraping. Le flux repose sur la suggestion de champs par IA, l'enrichissement des sous-pages et l'export direct vers les outils où les profils métier travaillent déjà.
- Idéal pour : équipes ventes, ops, e-commerce, immobilier et autres équipes très dépendantes du navigateur.
- Pourquoi il se démarque : il réduit le temps de configuration mieux que tout autre outil de la liste pour les non-développeurs.
- Point de vigilance : si vous avez besoin d'une logique de crawler très personnalisée ou d'un contrôle d'ingénierie poussé, vous finirez par descendre dans la pile.
- Modèle de tarification : formule gratuite, offres payantes en self-service et tarification entreprise.
Vous voulez voir le flux réel le plus rapide avant de comparer d'autres outils ? Ce tutoriel est le meilleur point de départ :
2. Browse AI
Browse AI reste un très bon choix pour les profils métier qui veulent une configuration en point-and-click couplée à une surveillance récurrente. Son modèle de robot devient particulièrement utile quand scraping et détection de changements pèsent autant l'un que l'autre.
- Idéal pour : surveiller des pages tarifaires, des pages concurrentes et extraire de manière répétable des listes.
- Pourquoi il se démarque : onboarding soigné, robots prêts à l'emploi, chemin clair entre site web et tableur ou sortie type API.
- Point de vigilance : les tâches complexes et à fort volume peuvent devenir coûteuses ou pénibles à gérer plus vite qu'avec une stack API-first.
- Modèle de tarification : formule gratuite, offres payantes, offre premium gérée.
3. Bardeen
Bardeen brille surtout quand le scraping n'est qu'une action parmi d'autres dans un flux d'automatisation navigateur plus large. Si vous déplacez des données vers le CRM, vers des tableurs ou vers des flux de prospection, son angle automatisation pèse davantage que la profondeur brute d'extraction.
- Idéal pour : revenue ops, flux de prospects et automatisation de tâches natives au navigateur.
- Pourquoi il se démarque : une histoire d'automatisation plus solide que celle des outils d'extraction purs.
- Point de vigilance : moins adapté quand le scraping lui-même est complexe et critique.
- Modèle de tarification : formule gratuite et offres payantes.
4. Diffbot
Diffbot s'adresse aux équipes qui ont besoin d'extraction IA à l'échelle entreprise, pas à celles qui cherchent l'option la moins chère ou la plus simple. L'outil prend tout son sens quand la qualité des données structurées et l'ingestion à grande échelle priment sur le contrôle manuel.
- Idéal pour : équipes data en grand compte, intelligence de contenu et programmes d'extraction massifs.
- Pourquoi il se démarque : extraction par vision par ordinateur et orientation forte vers les sorties structurées.
- Point de vigilance : surdimensionné pour les petites équipes et peu pratique sur un cas léger.
- Modèle de tarification : offres entreprise et vente sur devis.
5. Instant Data Scraper
Instant Data Scraper conserve sa place : il existe une foule de situations où on a juste besoin du tableau, de l'annuaire ou de la liste visibles, tout de suite. Ce n'est pas une plateforme, mais c'est souvent suffisant.
- Idéal pour : extraction ponctuelle, listes de prospects rapides, répertoires simples et tableaux visibles.
- Pourquoi il se démarque : presque aucune friction sur les bonnes pages.
- Point de vigilance : automatisation limitée, profondeur limitée, peu adapté aux flux avancés.
- Modèle de tarification : gratuit.
Les meilleurs outils de web scraping sans code pour les tâches répétables
Dès que la tâche dépasse le scraping occasionnel, les générateurs visuels et l'exécution cloud prennent toute leur importance.
6. Octoparse
Octoparse reste l'une des plateformes sans code les plus solides quand vous avez besoin d'exécutions cloud, d'une bonne couverture de modèles et d'une gestion de tâches plus poussée qu'une extension navigateur.
- Idéal pour : analystes, équipes pricing et opérateurs qui font tourner des jobs de collecte récurrents.
- Pourquoi il se démarque : générateur de tâches mature, extraction cloud, fonctionnalités anti-blocage et large écosystème de modèles.
- Point de vigilance : plus puissant que les outils navigateur IA-first — donc plus de configuration aussi.
- Modèle de tarification : formule gratuite, offres payantes à partir de 69 USD/mois, offre entreprise sur mesure.
7. ParseHub
ParseHub reste pertinent pour les utilisateurs qui veulent plus de contrôle qu'un scraper IA, sans pour autant écrire de code. Il récompense la patience, pas la vitesse.
- Idéal pour : analystes et opérateurs techniquement curieux capables d'absorber une courbe d'apprentissage plus raide.
- Pourquoi il se démarque : logique de navigation flexible et meilleur contrôle que les outils navigateur légers.
- Point de vigilance : l'expérience produit paraît plus lourde que celle des entrants récents, surtout pour des équipes métier qui avancent vite.
- Modèle de tarification : formule gratuite et offres payantes.
8. Web Scraper
Web Scraper reste un point d'entrée raisonnable si vous aimez le modèle sitemap et voulez un outil qui démarre dans le navigateur, avec une planification cloud à activer plus tard.
- Idéal pour : débutants, projets personnels et petits jobs répétables.
- Pourquoi il se démarque : flux sitemap accessible et adoption facile d'abord dans le navigateur.
- Point de vigilance : il devient limitant dès qu'il faut une logique d'extraction plus adaptative.
- Modèle de tarification : extension navigateur gratuite et offres cloud payantes.
9. Data Miner
Data Miner doit se voir comme un utilitaire d'extraction rapide plutôt que comme une plateforme complète. Il mérite sa place : le travail par recettes est très utile pour de nombreuses tâches de recherche et de prospection.
- Idéal pour : chercheurs, équipes growth et export rapide depuis le navigateur.
- Pourquoi il se démarque : modèle par recettes, faible friction et export simple depuis le navigateur.
- Point de vigilance : ce n'est pas un outil pensé pour le scraping à l'échelle d'une vraie plateforme.
- Modèle de tarification : formule gratuite et offres payantes.
Les meilleures plateformes API quand échelle et blocage deviennent le vrai problème
C'est le niveau où les équipes d'ingénierie cessent de se demander « comment extraire cette page ? » pour se demander « comment rendre cela fiable à grande échelle ? ».
10. Apify
Apify est la plateforme la plus flexible du groupe : une place de marché de scrapers réutilisables doublée d'un environnement d'exécution pour votre propre code. Mieux que la plupart de ses concurrents, elle fait le pont entre découverte sans code et exécution développeur.
- Idéal pour : équipes hybrides, scraping piloté par les développeurs et flux d'automatisation réutilisables.
- Pourquoi il se démarque : l'écosystème d'Actors couplé au runtime personnalisé lui donne une portée rare.
- Point de vigilance : dès que vous personnalisez, vous revenez dans l'univers ingénierie et l'avantage de simplicité s'érode.
- Modèle de tarification : formule gratuite, offre starter à partir de 29 USD/mois plus usage, paliers d'usage supérieurs et entreprise.
11. ScrapingBee
ScrapingBee s'impose quand votre besoin réel est : « donnez-moi une page rendue et débrouillez-vous avec l'infrastructure pénible ». Il convient bien aux cibles très lourdes en JavaScript.
- Idéal pour : développeurs qui visent des sites dynamiques sans appétit pour le travail infra.
- Pourquoi il se démarque : API simple autour du rendu, des proxies et de l'automatisation navigateur.
- Point de vigilance : c'est un service d'infrastructure — vous restez responsable du parsing, de la logique de retry et de la qualité en aval.
- Modèle de tarification : essai et offres payantes.
12. ScraperAPI
ScraperAPI reste l'un des moyens les plus simples de déléguer la gestion des proxies et la réussite des requêtes quand vous voulez monter en volume rapidement.
- Idéal pour : développeurs qui doivent passer vite du prototype au volume.
- Pourquoi il se démarque : API directe, crédits d'essai, produits structurés et paliers de montée en charge.
- Point de vigilance : comme tous les produits API-first, il ne supprime pas le besoin de jugement d'ingénierie pour le parsing et la validation des données.
- Modèle de tarification : essai de 7 jours avec 5 000 crédits, offres payantes à partir de 49 USD/mois.
13. Bright Data
Bright Data est l'option lourde quand contournement des blocages, inventaire de proxies et acquisition gérée comptent plus que la simplicité de l'outil. Programme conforme au RGPD pour les équipes européennes, c'est aussi son terrain.
- Idéal pour : programmes grand compte, collecte à grande échelle sensible à la conformité et acquisition de données gérée.
- Pourquoi il se démarque : largeur de l'offre — proxies, scrapers, navigateurs et datasets.
- Point de vigilance : coûteux et facile à suracheter si votre flux principal reste simple.
- Modèle de tarification : tarification à l'usage et selon les produits pour API, proxies et services gérés.
14. Oxylabs
Oxylabs reste un excellent choix pour les équipes qui achètent le scraping comme infrastructure plutôt que comme outil navigateur. Pertinent quand fiabilité et maturité des achats comptent.
- Idéal pour : collecte entreprise, suivi tarifaire, suivi SEO et études de marché.
- Pourquoi il se démarque : infrastructure robuste, profondeur de l'offre proxy et processus d'achat clairement entreprise.
- Point de vigilance : pas idéal si votre équipe veut un flux self-service décontracté.
- Modèle de tarification : API Web Scraper à partir de 49 USD/mois ; autres produits variables selon unité et usage.
15. Zyte
Zyte mérite une considération sérieuse de la part des équipes développeur et data qui veulent anti-détection, actions navigateur, rendu JavaScript et rotation d'IP derrière une seule approche API-first.
- Idéal pour : équipes techniques qui bâtissent des systèmes d'extraction répétables.
- Pourquoi il se démarque : actions navigateur, rendu JavaScript, rotation d'IP et posture anti-bot dans une seule stack.
- Point de vigilance : mieux adapté aux équipes qui assument l'ingénierie qu'aux profils non techniques.
- Modèle de tarification : essai avec 5 USD de crédit gratuit et engagements mensuels basés sur l'usage.
Les meilleures bibliothèques open source pour les développeurs en quête de contrôle total
Si vous voulez maîtriser votre stack de scraping de bout en bout, voici les briques les plus utiles en 2026.
16. Selenium
Selenium reste utile quand vous avez besoin d'une fidélité d'interaction type QA, de flux d'automatisation navigateur historiques ou d'un contrôle très explicite des parcours utilisateur.
- Idéal pour : automatisation lourde en interactions, recouvrement avec la QA et sites où le comportement du navigateur compte plus que le débit de crawl.
- Pourquoi il se démarque : écosystème mature et large support des navigateurs.
- Point de vigilance : plus lourd et plus lent que les outils navigateur récents pour beaucoup de charges de scraping.
- Modèle de tarification : gratuit et open source.
17. BeautifulSoup4

BeautifulSoup n'est pas une plateforme de scraping complète, mais c'est l'un des moyens les plus simples d'analyser du HTML désordonné dans des flux légers.
- Idéal pour : débutants, scripts rapides et tâches où le parseur est au centre.
- Pourquoi il se démarque : API simple et faible charge mentale.
- Point de vigilance : combinez-le avec des outils de requête, de navigateur ou de crawl ; seul, ce n'est qu'un parseur.
- Modèle de tarification : gratuit et open source.
18. Scrapy
Scrapy reste la meilleure réponse quand il vous faut un vrai framework de crawl plutôt qu'une poignée de scripts.
- Idéal pour : crawlers personnalisés en production et pipelines de données gérés en interne.
- Pourquoi il se démarque : haute performance, pipelines, middleware et extensibilité dans la durée.
- Point de vigilance : vraie charge d'ingénierie, et les cibles très lourdes en JavaScript exigent souvent des outils complémentaires.
- Modèle de tarification : gratuit et open source.
19. Puppeteer
Puppeteer reste un choix solide pour les équipes Node qui veulent un contrôle direct sur Chromium et le scripting navigateur.
- Idéal pour : scraping en Node, captures d'écran et tâches d'automatisation navigateur.
- Pourquoi il se démarque : contrôle direct et puissant du comportement de Chromium.
- Point de vigilance : couverture navigateur plus limitée que Playwright et gourmand en ressources à grande échelle.
- Modèle de tarification : gratuit et open source.
20. Playwright
Playwright est ma recommandation par défaut pour l'automatisation navigateur moderne quand votre équipe écrit du code et veut une abstraction plus récente que Selenium.
- Idéal pour : automatisation navigateur moderne, sites lourds en JavaScript et équipes attentives à l'ergonomie développeur.
- Pourquoi il se démarque : modèle multi-navigateurs solide, comportement d'attente fiable et API propres.
- Point de vigilance : vous gardez la charge de l'infrastructure navigateur, de la concurrence, des dérives de sélecteurs et de la validation des données.
- Modèle de tarification : gratuit et open source.
Ma shortlist par type d'équipe
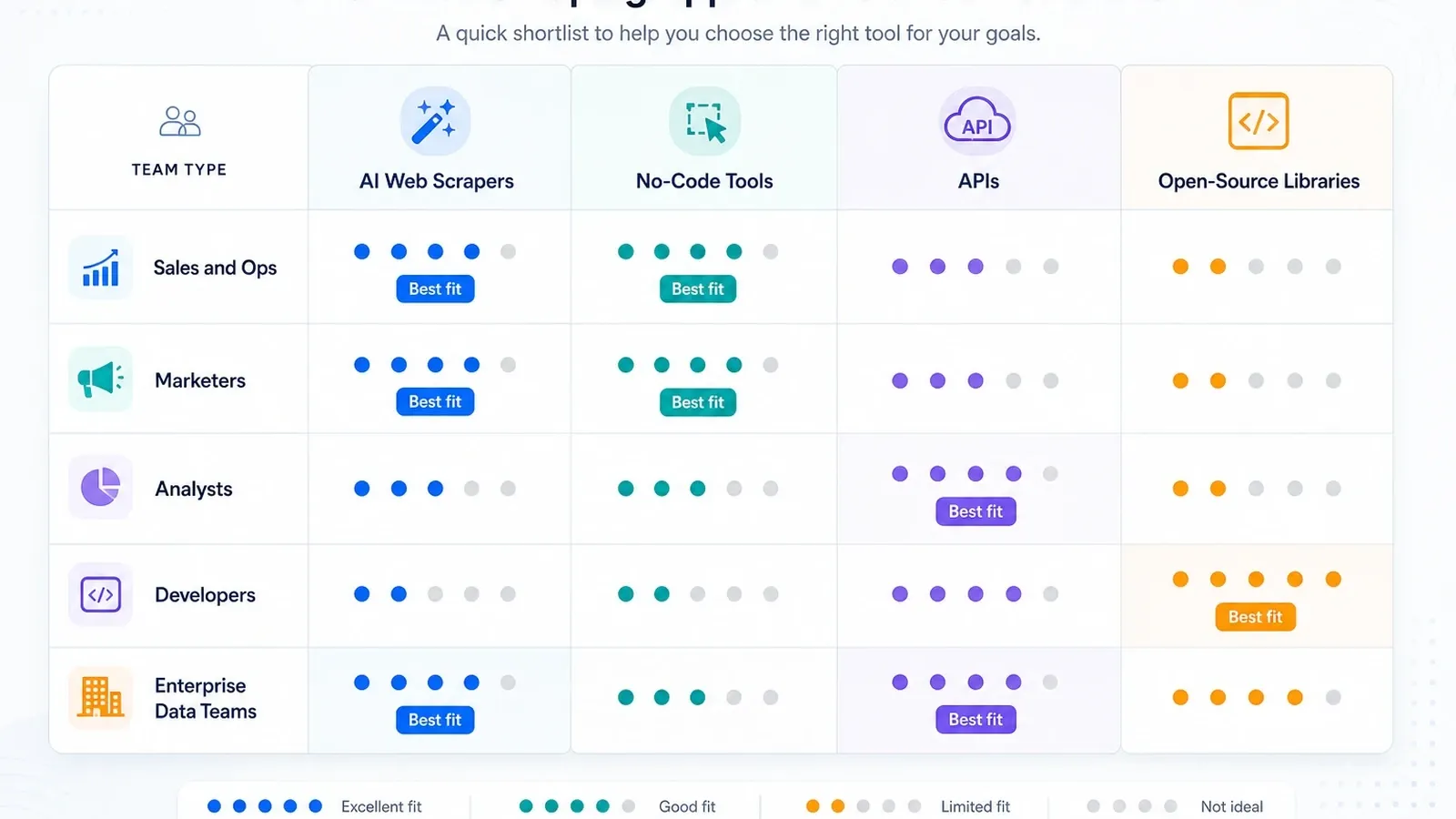
- Équipes ventes et ops : commencez par Thunderbit, puis regardez Browse AI si la surveillance compte plus que l'enrichissement des sous-pages.
- Équipes analystes et recherche : Octoparse d'abord si les tâches récurrentes dépassent ce que les extensions navigateur peuvent absorber sans douleur.
- Équipes GTM très automatisées : Bardeen si le scraping n'est qu'une étape dans un flux plus large.
- Équipes développeurs qui construisent des outils internes : Apify, Zyte, ScraperAPI ou Playwright selon le degré de propriété de la stack que vous souhaitez.
- Programmes data entreprise : Bright Data, Oxylabs, Diffbot et Zyte sont les vraies discussions d'infrastructure.
Quand descendre dans la pile
Appliquez cette règle :
- Restez sur les outils IA jusqu'aux limites de répétabilité ou de cas limites.
- Passez aux outils sans code dès que planification, pagination, anti-blocage ou exécutions cloud comptent plus que la simplicité en un clic.
- Passez aux API quand taux de déblocage, rendu JavaScript et concurrence deviennent les vrais goulots d'étranglement.
- Passez aux bibliothèques open source quand le coût de l'abstraction éditeur dépasse le coût de maîtrise complète de la stack.
La plupart des équipes descendent trop tôt. C'est l'une des erreurs les plus fréquentes que je vois.
Conclusion
Pour la plupart des équipes non techniques, la bonne réponse en 2026 n'est pas « le scraper le plus puissant ». C'est l'outil qui livre des données fiables au flux suivant avec le moins de maintenance possible. C'est pour cela que les outils IA-first continuent de gagner chez les opérateurs, tandis que les API et les stacks open source restent le meilleur choix pour les équipes techniques aux besoins d'échelle clairs.
Si vous voulez le chemin le plus court entre une page et une sortie structurée, commencez par Thunderbit. Si vous savez déjà que votre tâche exige une infrastructure lourde, sautez directement aux couches API et développeur. Ne confondez simplement pas complexité et sophistication.
FAQ
1. Quel est le meilleur outil de web scraping pour les utilisateurs non techniques en 2026 ?
Pour la plupart des profils non techniques, les outils IA-first comme Thunderbit et Browse AI offrent le chemin le plus rapide vers des données utiles : ils allègent le travail sur les sélecteurs, les frictions de configuration et la maintenance.
2. Que choisir si mes sites sont lourds en JavaScript ou bloquent agressivement les requêtes ?
Orientez-vous vers ScrapingBee, ScraperAPI, Zyte, Bright Data, Oxylabs, Playwright ou Selenium selon que vous voulez un service géré ou un contrôle d'ingénierie direct.
3. Les outils sans code sont-ils encore pertinents maintenant que les extracteurs web IA se sont améliorés ?
Oui. Des outils sans code comme Octoparse et ParseHub gardent leur intérêt quand vous avez besoin d'un contrôle explicite sur la logique des tâches, l'exécution cloud et la gestion de jobs répétables.
4. Quels outils conviennent le mieux aux équipes d'ingénierie ?
Apify, Zyte, ScraperAPI, Scrapy, Playwright, Puppeteer et Selenium sont les choix les plus naturels quand les développeurs pilotent le flux de travail.
5. Comment bâtir une shortlist rapidement sans creuser des heures ?
Commencez par choisir le type d'outil, pas l'éditeur. Décidez si vous avez besoin de la simplicité IA, du contrôle sans code, d'une infrastructure API ou de la propriété open source. Ensuite seulement, comparez les produits à l'intérieur de cette couche.
Lectures associées