
« On peut avoir des données sans information, mais on ne peut pas avoir d’information sans données. » —
D’après des chiffres récents, Internet héberge plus de de sites web, et près de 2 millions de nouveaux contenus y apparaissent chaque jour. Autant dire un vrai « 바다 » de données, rempli d’insights capables d’aider à prendre de meilleures décisions. Le hic, c’est qu’environ de ces données sont non structurées : avant de pouvoir les exploiter, il faut donc les « remettre en forme ». C’est exactement là que les outils d’extraction web deviennent incontournables pour toute personne qui veut vraiment profiter des données en ligne.
Si tu débutes dans l’extraction web, des notions comme les ou le peuvent vite donner l’impression d’un mur technique. Mais aujourd’hui, avec l’IA, on passe beaucoup plus facilement ce cap. Les outils modernes, boostés à l’IA, permettent de démarrer sans bagage technique avancé : la collecte et le traitement deviennent rapides, accessibles, et surtout… sans avoir à coder.
Les meilleurs outils et logiciels d’extraction web
- : un Extracteur Web IA facile à prendre en main, avec des résultats vraiment solides
- : pour le monitoring en temps réel et l’extraction en masse
- : pour l’automatisation no-code avec plein d’intégrations d’apps
- : pour une extraction visuelle plus « pro »
- : un no-code puissant, pensé pour limiter le blocage IP et la détection de bots
- : une API avancée d’extraction de données par IA + graphes de connaissances
Essayez l’extraction web avec l’IA
Essayez ! Vous pouvez cliquer, explorer et lancer le workflow tout en regardant.
Comment fonctionne l’extraction web ?
L’extraction web, c’est le fait de récupérer des données depuis des sites. Tu donnes des instructions à un outil, et lui va collecter le texte, les images (ou tout autre élément dont tu as besoin), puis organiser tout ça dans un tableau à partir d’une page web. C’est pratique pour mille choses : suivre des prix sur des sites e-commerce, rassembler des données pour une étude, ou tout simplement remplir un bon fichier Excel ou Google Sheets sans y passer la nuit.
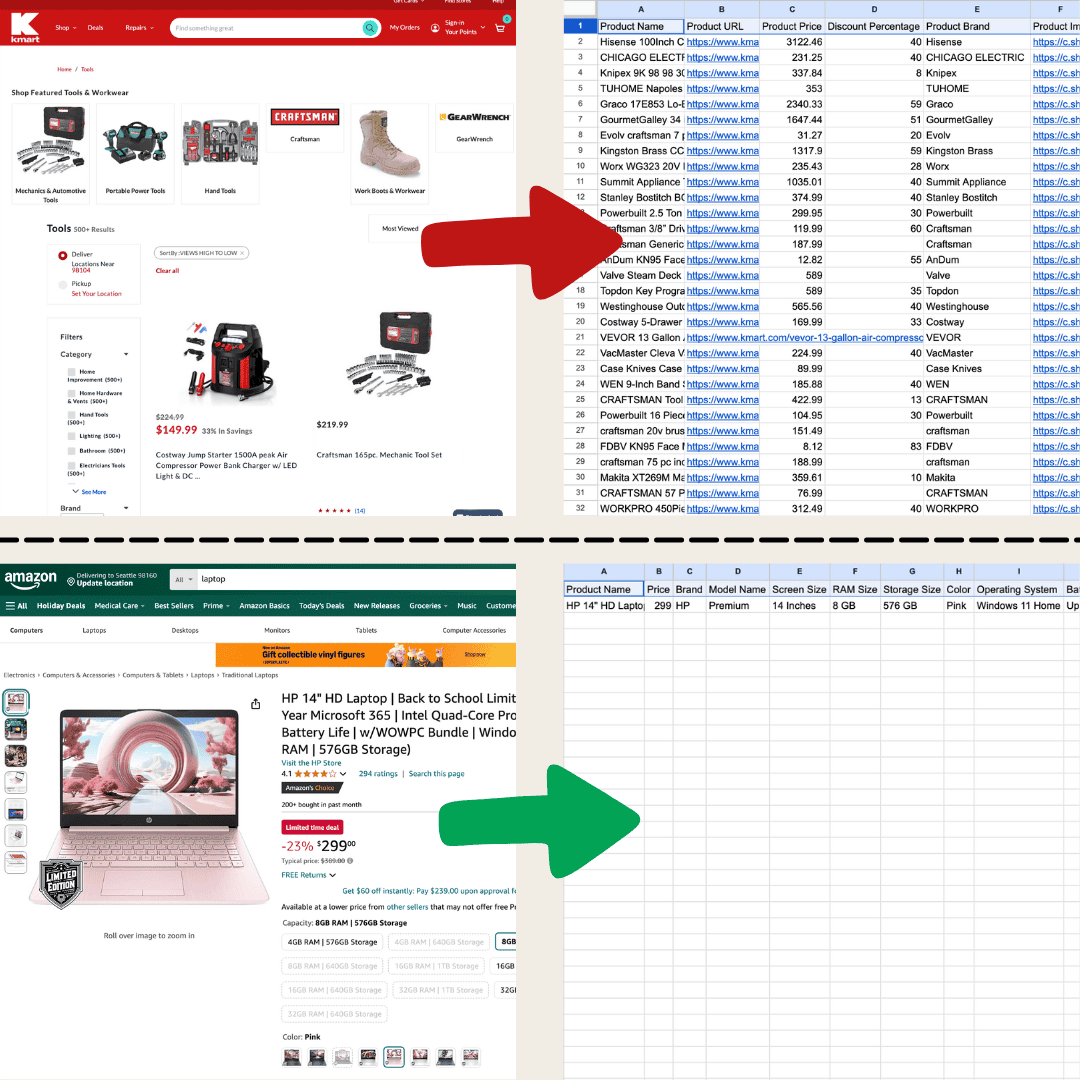 J’ai fait ça avec Thunderbit grâce à l’Extracteur Web IA.
J’ai fait ça avec Thunderbit grâce à l’Extracteur Web IA.
Il existe plusieurs façons de faire. La plus simple, c’est le copier-coller manuel… mais dès que le volume augmente, ça devient vite « 헬게이트 ». En pratique, la plupart des gens choisissent l’une de ces trois méthodes : les extracteurs web « classiques », les Extracteurs Web IA, ou du code sur mesure.
Les extracteurs web traditionnels marchent en définissant des règles très précises selon la structure de la page. Par exemple, tu leur demandes de récupérer les noms de produits ou les prix à partir de certaines balises HTML. Ils sont super efficaces sur des sites qui bougent peu, mais au moindre changement de mise en page, tu risques de devoir tout ajuster (et ça, c’est rarement fun).
 Apprendre à utiliser un extracteur traditionnel prend du temps, et la configuration demande souvent des dizaines de clics.
Apprendre à utiliser un extracteur traditionnel prend du temps, et la configuration demande souvent des dizaines de clics.
Les Extracteurs Web IA, en pratique, c’est plutôt : ChatGPT « lit » la page (voire le site) et extrait ce dont tu as besoin. Ils peuvent gérer l’extraction, la traduction et la synthèse en même temps. Grâce au traitement du langage naturel, ils analysent et comprennent la structure du site, ce qui les rend plus « 탄탄 » face aux changements. Si un site réorganise légèrement ses sections, un Extracteur Web IA peut souvent s’adapter sans que tu aies à tout reconfigurer. C’est donc un excellent choix pour les sites qui évoluent souvent ou dont la structure est complexe.
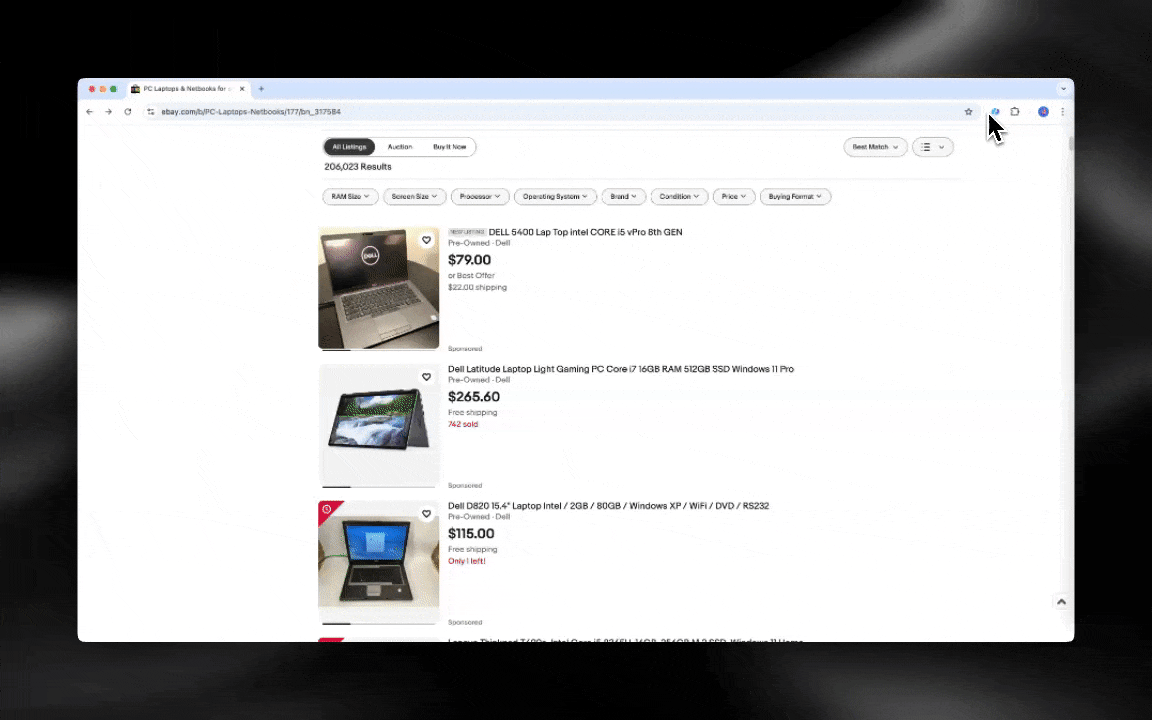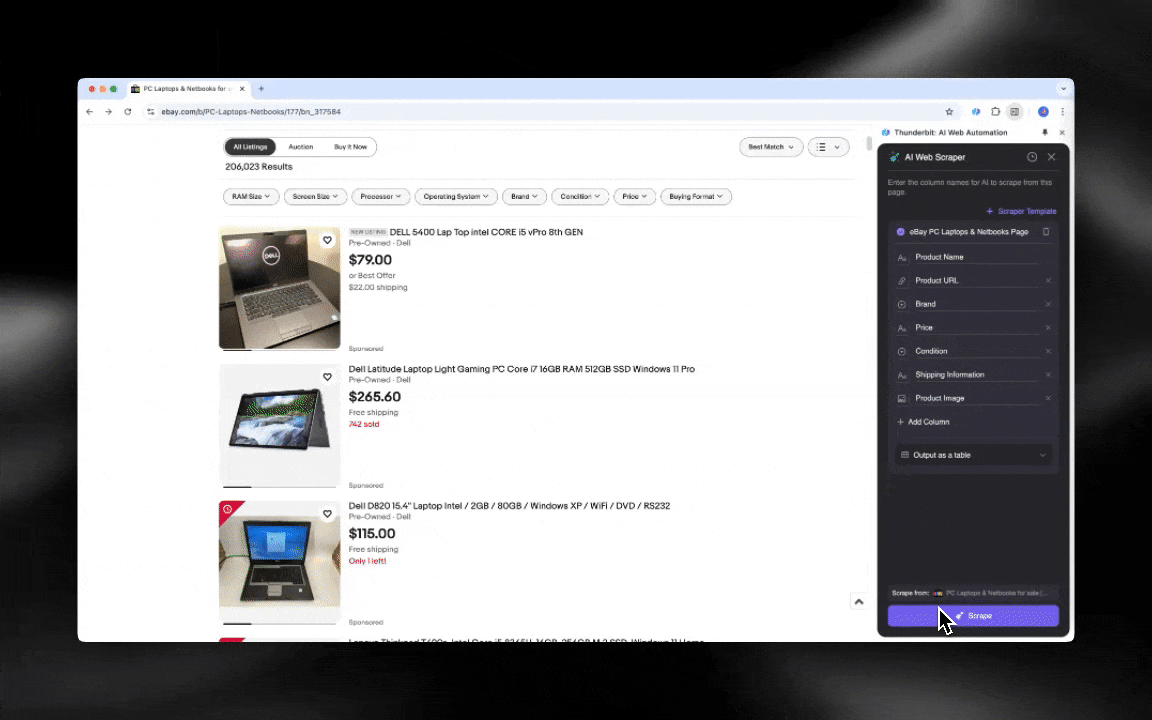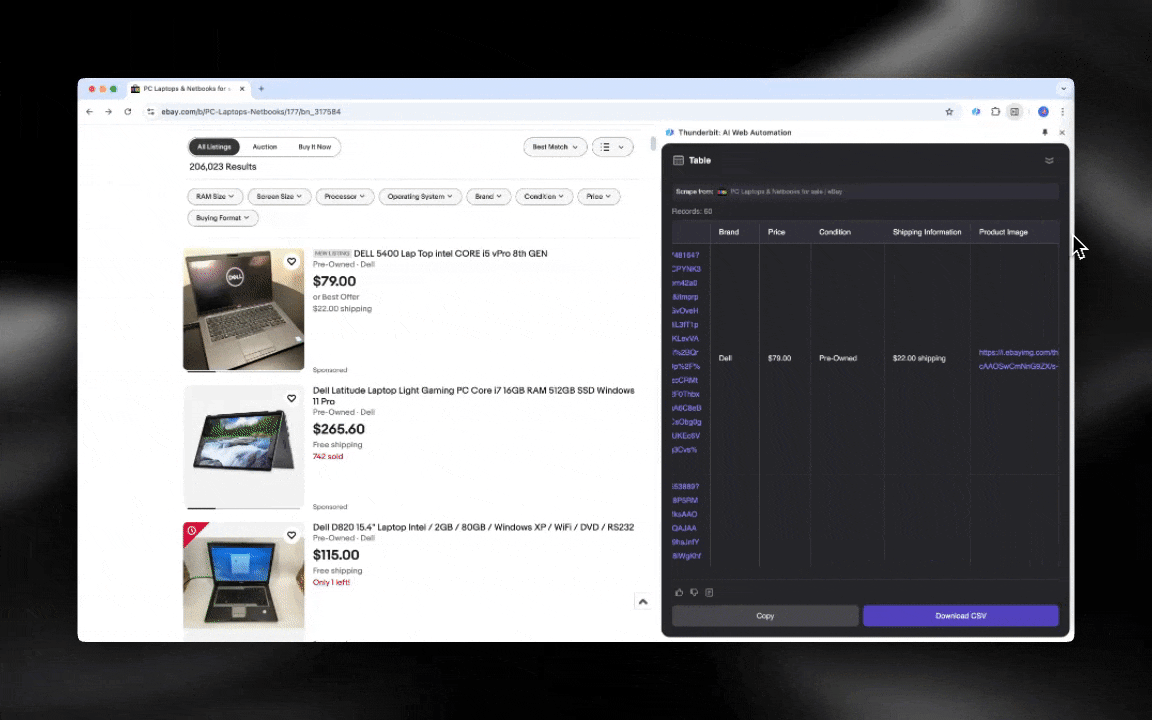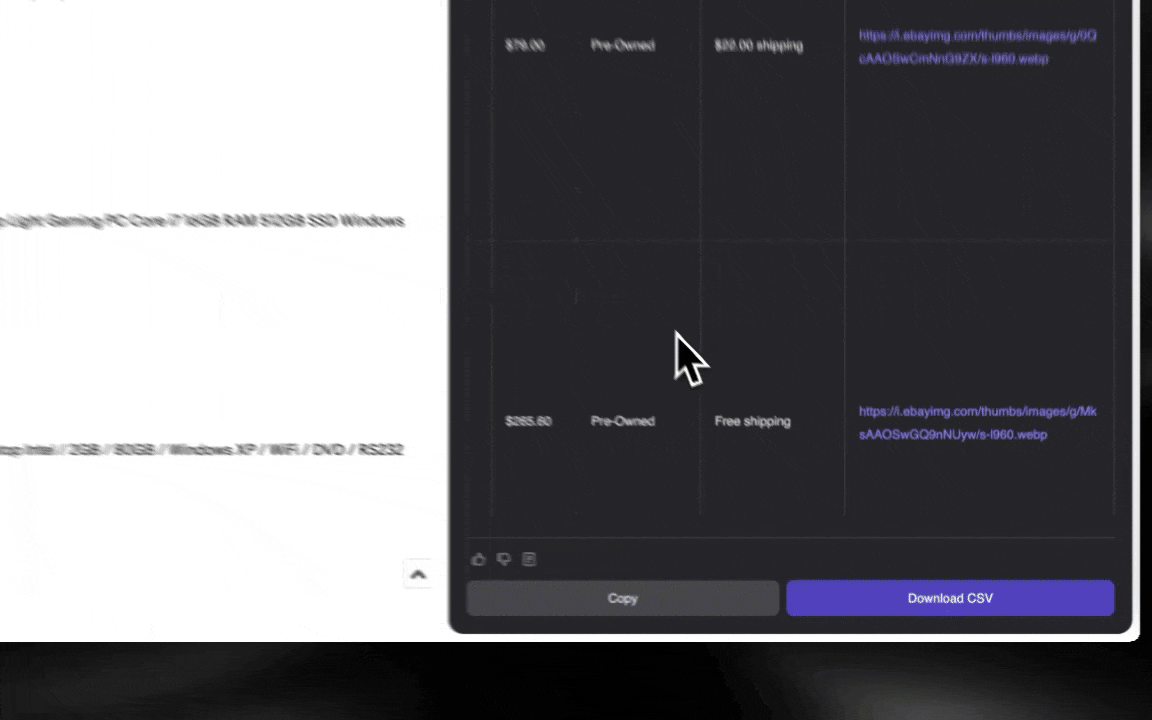 Un Extracteur Web IA est facile à prendre en main et permet d’obtenir des données détaillées en quelques clics.
Un Extracteur Web IA est facile à prendre en main et permet d’obtenir des données détaillées en quelques clics.
Lequel choisir ? Ça dépend. Si tu es à l’aise avec le code ou si tu dois collecter d’énormes volumes sur un site très populaire, les extracteurs traditionnels peuvent être redoutablement efficaces. En revanche, si tu débutes ou si tu veux un outil qui encaisse bien les mises à jour des sites, les Extracteurs Web IA sont généralement le meilleur choix. Le tableau ci-dessous résume les cas d’usage.
| Scénario | Meilleur choix |
|---|---|
| Extraction légère sur des pages comme des annuaires, des sites e-commerce, ou tout site présentant une liste | Extracteur Web IA |
| La page contient moins de 200 lignes de données, et créer un extracteur avec un outil traditionnel prend trop de temps | Extracteur Web IA |
| Les données à extraire doivent respecter un format précis pour être importées ailleurs (ex. : contacts à importer dans HubSpot) | Extracteur Web IA |
| Sites très utilisés à grande échelle, par exemple des dizaines de milliers de pages produits Amazon ou des annonces immobilières Zillow | Extracteur Web traditionnel |
Les meilleurs outils et logiciels d’extraction web en un coup d’œil
| Outil | Tarifs | Fonctionnalités clés | Avantages | Inconvénients |
|---|---|---|---|---|
| Thunderbit | Dès 9 $/mois, offre gratuite disponible | Extracteur Web IA, détection et mise en forme automatiques, plusieurs formats, export en un clic, interface simple. | Sans code, assistance IA, intégrations (Google Sheets, etc.) | L’extraction à grande échelle peut être plus lente, certaines fonctions avancées coûtent plus cher |
| Browse AI | Dès 48,75 $/mois, offre gratuite disponible | Interface no-code, monitoring en temps réel, extraction en masse, intégration de workflows. | Facile à utiliser, intégrations Google Sheets & Zapier | Les pages complexes demandent plus de réglages, l’extraction en masse peut provoquer des timeouts |
| Bardeen AI | Dès 60 $/mois, offre gratuite disponible | Automatisation no-code, intégration avec 130+ apps, MagicBox transforme des tâches en workflows. | Très nombreuses intégrations, évolutif pour les entreprises | Courbe d’apprentissage marquée, mise en place parfois longue |
| Web Scraper | Gratuit en local, 50 $/mois pour le cloud | Création visuelle de tâches, support des sites dynamiques (AJAX/JavaScript), extraction cloud. | Très efficace sur les sites dynamiques | Nécessite des connaissances techniques pour une configuration optimale |
| Octoparse | À partir de 119 $/mois, offre gratuite disponible | Extraction no-code, détection automatique des éléments, cloud avec tâches planifiées, bibliothèque de modèles. | Puissant sur les sites dynamiques, gère mieux les restrictions | Les sites complexes demandent un temps d’apprentissage |
| Diffbot | Dès 299 $/mois | API d’extraction, API sans règles, NLP pour texte non structuré, vaste graphe de connaissances. | Extraction IA solide, intégration API poussée, extraction à grande échelle | Courbe d’apprentissage pour les non-techniciens, temps de mise en place |
Le meilleur Extracteur Web à l’ère de l’IA
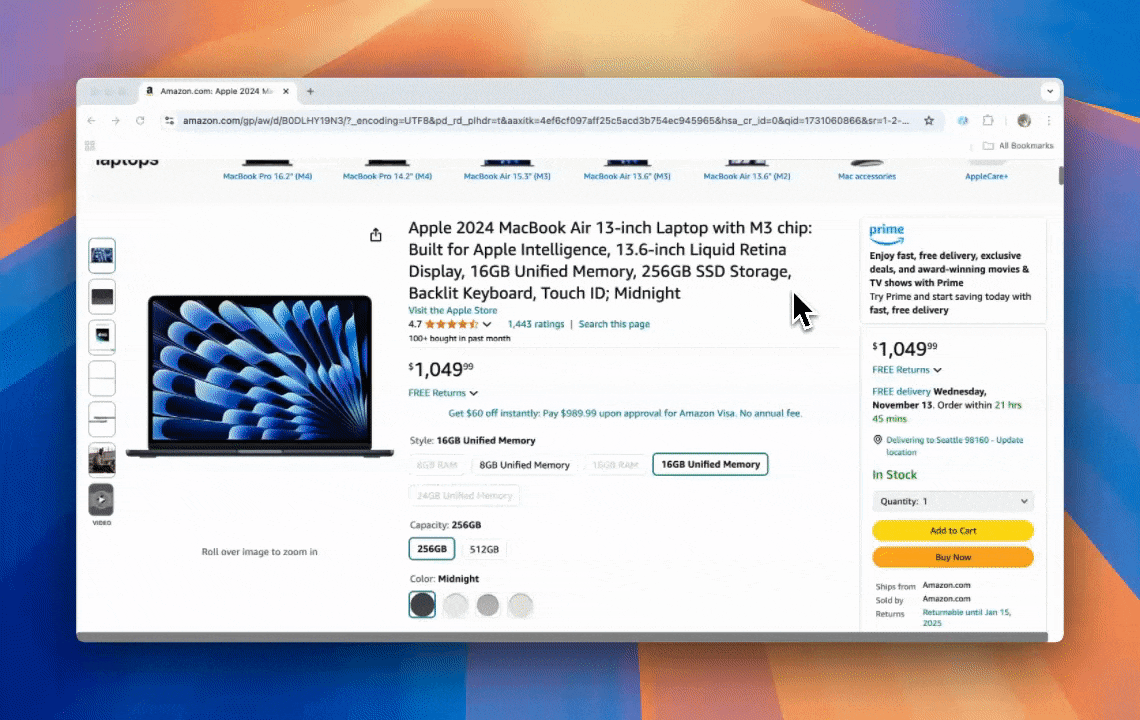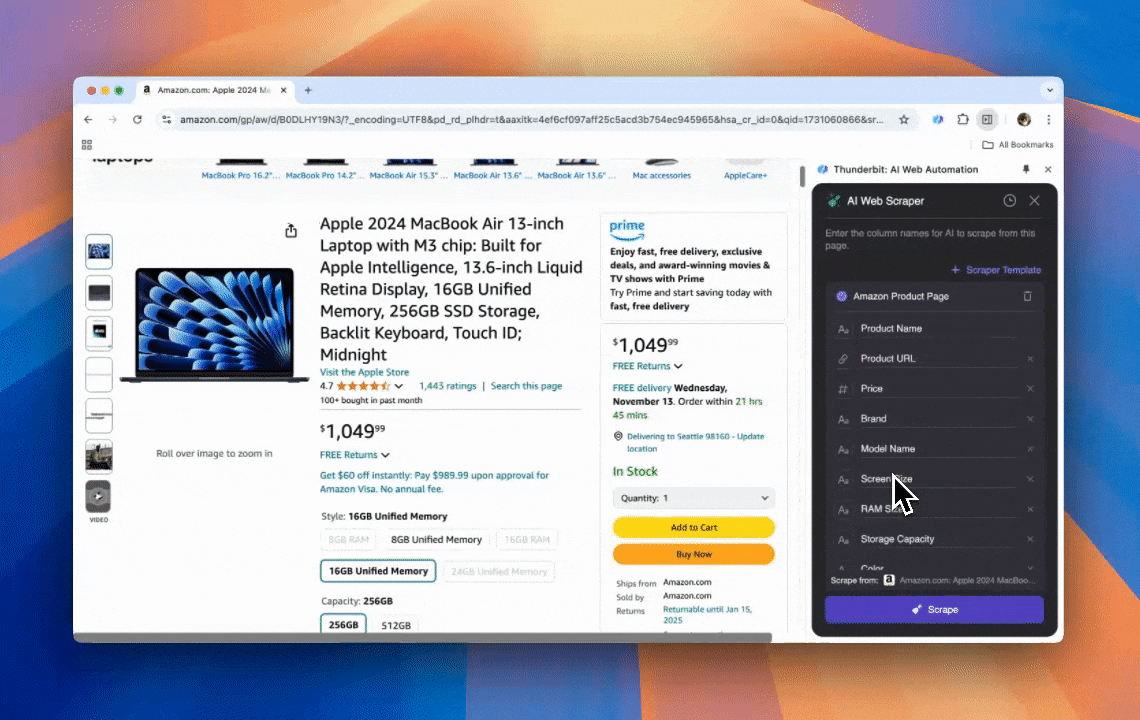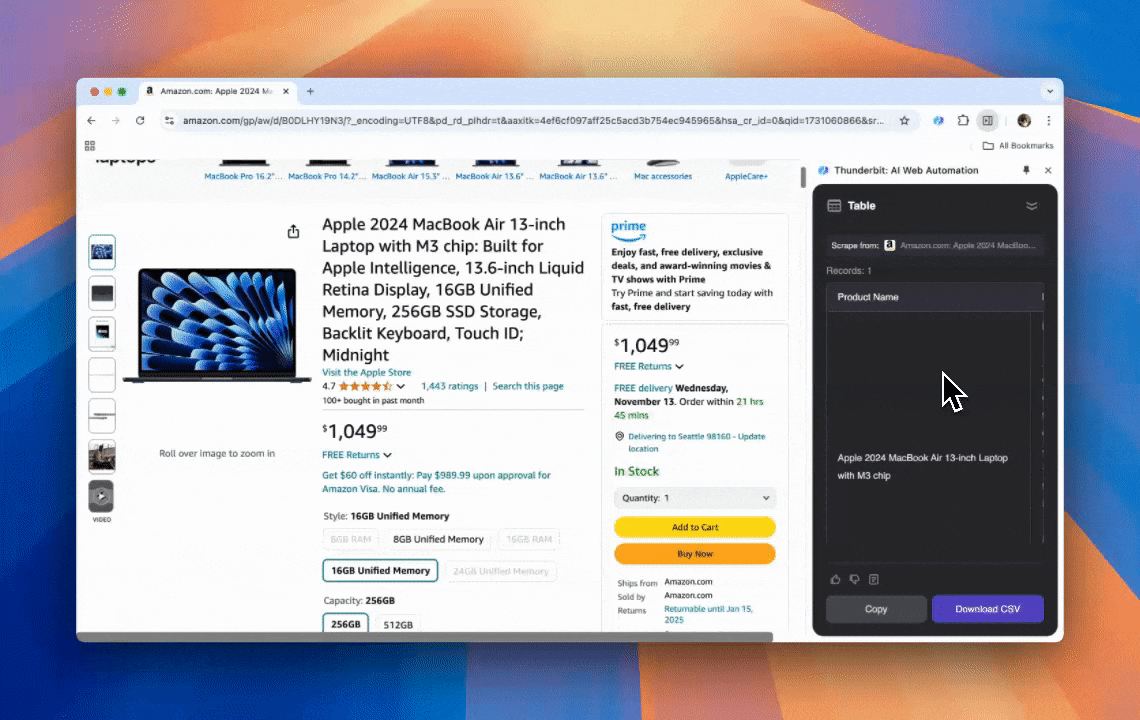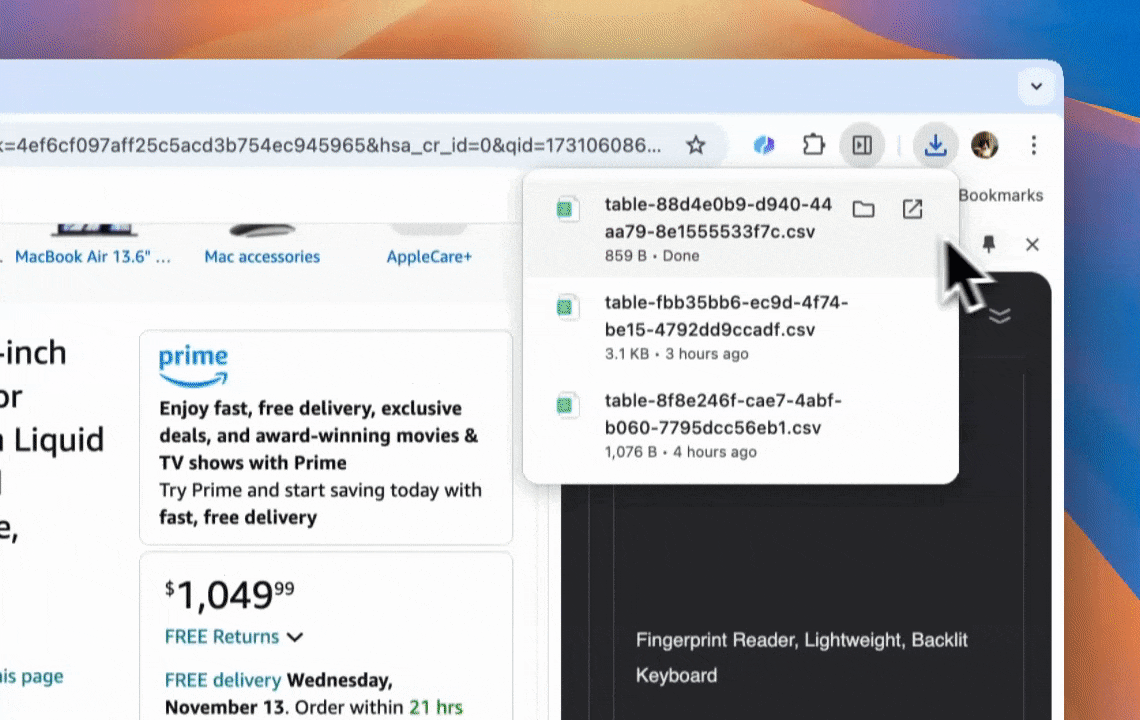
Thunderbit est un outil d’automatisation web par IA, à la fois puissant et « 손쉽게 » utilisable, qui permet d’extraire et d’organiser des données sans savoir coder. Grâce à son , l’ de Thunderbit rend l’extraction beaucoup plus simple : tu récupères rapidement des données web sans devoir manipuler à la main les éléments de la page, ni créer un extracteur différent à chaque variation de mise en page.
Fonctionnalités clés
- Flexibilité pilotée par l’IA : l’Extracteur Web IA de Thunderbit détecte et met en forme automatiquement les données, sans sélecteurs CSS.
- L’expérience d’extraction la plus simple : clique sur « AI suggest column », puis sur « Scrape » sur la page à extraire. 끝.
- Prise en charge de plusieurs formats de données : Thunderbit peut extraire des URL, des images et afficher les données capturées sous différents formats.
- Traitement automatisé des données : l’IA peut reformater à la volée (résumer, catégoriser, traduire) selon le format attendu.
- Export facile : export en un clic vers Google Sheets, Airtable ou Notion pour simplifier la gestion.
- Interface intuitive : accessible quel que soit ton niveau.
Tarifs
Thunderbit propose des formules par paliers, à partir de 9 $/mois pour 5 000 crédits, jusqu’à 199 $ pour 240 000 crédits. Avec l’abonnement annuel, tu reçois tous les crédits en une seule fois.
Avantages :
- Une IA solide qui simplifie l’extraction et le traitement.
- Sans code, accessible à tous.
- Idéal pour l’extraction légère (annuaires, e-commerce, etc.).
- Excellentes intégrations pour exporter directement vers des apps populaires.
Inconvénients :
- L’extraction à grande échelle peut demander un peu de temps pour garantir la précision.
- Certaines fonctionnalités avancées nécessitent un abonnement payant.
Envie d’en savoir plus ? Commencez par , ou découvrez avec Thunderbit.
Meilleur Extracteur Web pour la surveillance de données et l’extraction en masse
Browse AI
Browse AI est un outil no-code robuste, pensé pour extraire et surveiller des données sans écrire une ligne de code. Il intègre quelques fonctions d’IA, mais on n’est pas au niveau d’un véritable Extracteur Web IA. Cela dit, pour démarrer, c’est plutôt « 괜찮아 » et la prise en main est clairement facilitée.
Fonctionnalités clés
- Interface no-code : création de workflows personnalisés en quelques clics.
- Surveillance en temps réel : des bots suivent les changements d’une page et renvoient les mises à jour.
- Extraction en masse : jusqu’à 50 000 entrées de données en une seule exécution.
- Intégration de workflows : possibilité de chaîner plusieurs bots pour des traitements plus complexes.
Tarifs
À partir de 48,75 $/mois, incluant 2 000 crédits. Une offre gratuite est disponible avec 50 crédits par mois pour tester les fonctions de base.
Avantages :
- Intégrations avec Google Sheets et Zapier.
- Bots préconfigurés pour les tâches d’extraction courantes.
Inconvénients :
- Les pages complexes peuvent nécessiter des réglages supplémentaires.
- La vitesse en extraction de masse varie et peut parfois entraîner des timeouts.
Meilleur Extracteur Web pour l’intégration aux workflows
Bardeen AI
Bardeen AI est un outil d’automatisation no-code conçu pour rendre les workflows plus fluides en connectant différentes applications. Il utilise l’IA pour créer des automatisations sur mesure, mais il n’a pas l’adaptabilité d’un outil d’extraction IA « complet » (genre extracteur web ia).
Fonctionnalités clés
- Automatisation no-code : mise en place de workflows en quelques clics.
- MagicBox : tu décris la tâche en langage naturel, Bardeen AI la transforme en workflow.
- Nombreuses intégrations : plus de 130 apps, dont Google Sheets, Slack et LinkedIn.
Tarifs
À partir de 60 $/mois, avec 1 500 crédits (environ 1 500 lignes de données). Une offre gratuite propose 100 crédits par mois pour tester les fonctions de base.
Avantages :
- Très large choix d’intégrations pour répondre à des besoins variés.
- Flexible et évolutif, quelle que soit la taille de l’entreprise.
Inconvénients :
- Les nouveaux utilisateurs peuvent avoir besoin de temps pour maîtriser la plateforme.
- La configuration initiale peut être chronophage.
Meilleur Extracteur Web visuel pour utilisateurs expérimentés
Web Scraper
Oui, tu as bien lu : l’outil s’appelle « Web Scraper ». Web Scraper est une extension populaire pour Chrome et Firefox qui permet d’extraire des données sans coder, via une approche visuelle pour créer des tâches d’extraction. Par contre, il est probable que tu doives passer quelques jours à regarder et suivre les tutoriels ci-dessus pour vraiment être à l’aise. Si tu veux une approche plus simple et plus « 머리 안 아픈 » au quotidien, un Extracteur Web IA sera souvent plus confortable.
Fonctionnalités clés
- Création visuelle : configuration des tâches en cliquant sur les éléments de la page.
- Support des sites dynamiques : gestion d’AJAX et de JavaScript.
- Extraction cloud : planification de tâches via Web Scraper Cloud pour des extractions périodiques.
Tarifs
Gratuit en local ; les offres payantes démarrent à 50 $/mois pour les fonctionnalités cloud.
Avantages :
- Très efficace sur les sites dynamiques.
- Gratuit en local.
Inconvénients :
- Des connaissances techniques sont nécessaires pour une configuration optimale.
- Les changements demandent des tests parfois complexes.
Meilleur Extracteur Web pour éviter le blocage IP et la détection de bots
Octoparse
Octoparse est un logiciel polyvalent, plutôt orienté utilisateurs plus techniques, pour collecter et surveiller des données web spécifiques sans coder — idéal quand les volumes deviennent sérieux. Octoparse ne dépend pas du navigateur de l’utilisateur : il s’appuie sur des serveurs cloud pour l’extraction. Du coup, il peut proposer différentes méthodes pour contourner le blocage IP et certaines protections anti-bot.
Fonctionnalités clés
- Fonctionnement no-code : création de tâches d’extraction sans écrire de code, accessible à différents niveaux techniques.
- Détection intelligente : identification automatique des données de la page et des éléments extractibles, ce qui accélère la configuration.
- Extraction cloud : extraction 24/7 avec planification, pour une récupération flexible.
- Grande bibliothèque de modèles : des centaines de modèles prêts à l’emploi pour extraire rapidement des sites populaires sans configuration complexe.
Tarifs
Les offres Octoparse commencent à 119 $/mois, incluant 100 tâches. Une offre gratuite avec 10 tâches par mois est également disponible pour tester les fonctions de base.
Avantages :
- Fonctionnalités puissantes pour l’extraction de sites dynamiques, avec une bonne adaptabilité.
- Solutions utiles face aux restrictions d’extraction et aux contenus dynamiques.
Inconvénients :
- Les structures de sites complexes peuvent demander plus de temps de configuration.
- Les nouveaux utilisateurs peuvent avoir besoin de temps pour apprendre les bonnes pratiques.
Meilleur Extracteur Web pour une API avancée d’extraction de données par IA
Diffbot
Diffbot est un outil avancé d’extraction de données web qui utilise l’IA pour transformer du contenu non structuré en données structurées. Grâce à des API puissantes et à un graphe de connaissances, Diffbot aide à extraire, analyser et gérer des informations issues du web — utile dans de nombreux secteurs et cas d’usage.
Fonctionnalités clés
- API d’extraction de données : Diffbot propose une API « sans règles » : tu fournis simplement une URL, et l’extraction se fait automatiquement, sans définir des règles spécifiques pour chaque site.
- API de traitement du langage naturel : extraction d’entités, de relations et de sentiments à partir de texte non structuré, pour aider à construire des graphes de connaissances.
- Graphe de connaissances : l’un des plus grands graphes de connaissances, reliant un grand volume d’entités (personnes, organisations, etc.).
Tarifs
Les offres Diffbot commencent à 299 $/mois, incluant 250 000 crédits (soit environ 250 000 extractions de pages via API).
Avantages :
- Excellentes capacités d’extraction « sans règles », très adaptables.
- Nombreuses options d’intégration via API, faciles à connecter à des systèmes existants.
- Adapté à l’extraction à grande échelle, pour des usages entreprise.
Inconvénients :
- La prise en main peut demander un temps d’apprentissage pour les non-techniciens.
- Il faut écrire un programme pour appeler l’API et l’utiliser.
À quoi servent les extracteurs ?
Si tu débutes, voici quelques cas d’usage classiques pour te lancer. Beaucoup de gens utilisent des extracteurs pour récupérer des listes de produits Amazon, collecter des données immobilières sur Zillow, ou rassembler des infos d’entreprises depuis Google Maps. Mais ce n’est que le début : avec l’ de Thunderbit, tu peux collecter des données depuis presque n’importe quel site, automatiser des tâches et gagner du temps au quotidien. Recherche, suivi de prix, création de bases de données… l’extraction web ouvre une tonne de possibilités pour transformer les données d’Internet en quelque chose de vraiment actionnable.
FAQ
-
L’extraction web est-elle légale ?
L’extraction web est généralement légale, mais elle doit respecter les conditions d’utilisation des sites et la nature des données consultées. Vérifie toujours les politiques applicables et reste dans le cadre légal.
-
Faut-il savoir programmer pour utiliser des outils d’extraction web ?
La plupart des outils présentés ici ne demandent pas de compétences en programmation. En revanche, des outils comme Octoparse et Web Scraper sont plus efficaces si l’utilisateur comprend les structures web et adopte une logique « technique ».
-
Existe-t-il des outils d’extraction web gratuits ?
Oui. Des outils gratuits comme BeautifulSoup, Scrapy et Web Scraper existent, et certains services proposent aussi des formules gratuites limitées.
-
Quelles sont les difficultés fréquentes en extraction web ?
Les défis les plus courants : contenu dynamique, CAPTCHAs, blocage IP et structures HTML complexes. Des outils et techniques avancés permettent de gérer efficacement ces contraintes.
Pour aller plus loin :
-
Utilisez l’IA pour travailler sans effort.