

Surveiller plus de 200 sources d'actualité pour débusquer les articles qui montent : à la main, c'est un poste à plein temps. Avec un extracteur classique, c'est pire — il rendait l'âme à chaque refonte de mise en page.
Le basculement est venu avec les extracteurs d'articles dopés à l'IA. Un clic, des données propres, et plus le moindre sélecteur CSS à entretenir. L'écart de confort saute aux yeux.
Si vous êtes journaliste, expert SEO ou chercheur et que vous devez extraire des articles à grande échelle, ce comparatif vous épargnera une longue série de tâtonnements. J'ai mis à l'épreuve des extracteurs no-code classiques et des solutions à base d'IA — voici ce qui tient vraiment la distance.
Extraire n’importe quel site web grâce à l’IA Get Started Free
En bref
| Avantages | Inconvénients | Idéal pour | |
|---|---|---|---|
| Extracteur d’articles IA | - Peut extraire plusieurs sites avec une grande précision - Supprime automatiquement le bruit - S’adapte aux changements de structure web - Gère le chargement de contenu dynamique - Faible coût de nettoyage des données | - Coût de calcul plus élevé - Temps de traitement plus long - Certaines pages peuvent nécessiter une intervention manuelle - Risque de déclencher des mécanismes anti-extraction | - Extraction de sites à contenu complexe ou dynamique (par ex. portails d’actualité, réseaux sociaux) - Collecte de données à grande échelle |
| Extracteur d’articles no-code traditionnel | - Exécution rapide - Coût plus faible - Faible consommation de ressources serveur et locales - Forte maîtrise | - Maintenance fréquente en raison des changements de structure web - Impossible d’extraire plusieurs sites en même temps - Incapable de gérer le contenu dynamique - Coût élevé de nettoyage des données | - Extraction rapide à grande échelle de pages web statiques simples - Ressources informatiques limitées, contraintes budgétaires |
Qu'est-ce qu'un extracteur d'articles ? Pourquoi l'extracteur d'articles IA change-t-il la donne ?
Un extracteur d'articles est un type d'extracteur Web capable de repérer et de récupérer des informations — titres, auteurs, dates de publication, contenu, mots-clés, images, vidéos — sur des sites d'actualité, puis de les ranger dans des formats structurés comme JSON, CSV ou Excel.
Les extracteurs d'articles no-code classiques s'appuient sur des sélecteurs CSS pour aller chercher le contenu selon la structure HTML d'une page. Une approche qui montre vite ses limites :
- Aucune universalité : chaque site impose ses propres sélecteurs CSS, et le moindre changement de structure les met hors-jeu, d'où des mises à jour incessantes.
- Le contenu dynamique reste hors de portée : beaucoup de sites chargent leur contenu via AJAX ou JavaScript, ce que les sélecteurs CSS ne savent pas extraire directement.
- Un traitement des données minimal : les sélecteurs CSS ne ramènent que des fragments HTML bruts, sans nettoyage, mise en forme, analyse sémantique ni analyse de sentiment.
 Place à l'extracteur d'articles IA.
Place à l'extracteur d'articles IA.
-
Cette technologie s'appuie sur les LLM pour comprendre les pages web, ce qui ouvre la voie à :
- Une reconnaissance intelligente : identification des titres, auteurs, résumés et contenu principal.
- Une suppression automatique du bruit : le moteur fait le tri entre contenu principal, navigation, publicités et articles associés, au bénéfice de la qualité des données et de l'efficacité de l'extraction.
- Une adaptation aux évolutions du web : même quand la structure ou le style d'un site bouge, l'IA continue d'extraire grâce à la compréhension sémantique et aux indices visuels.
- Une généralisation d'un site à l'autre : contrairement aux extracteurs classiques, les extracteurs IA s'appliquent à des sites variés sans réglage manuel.
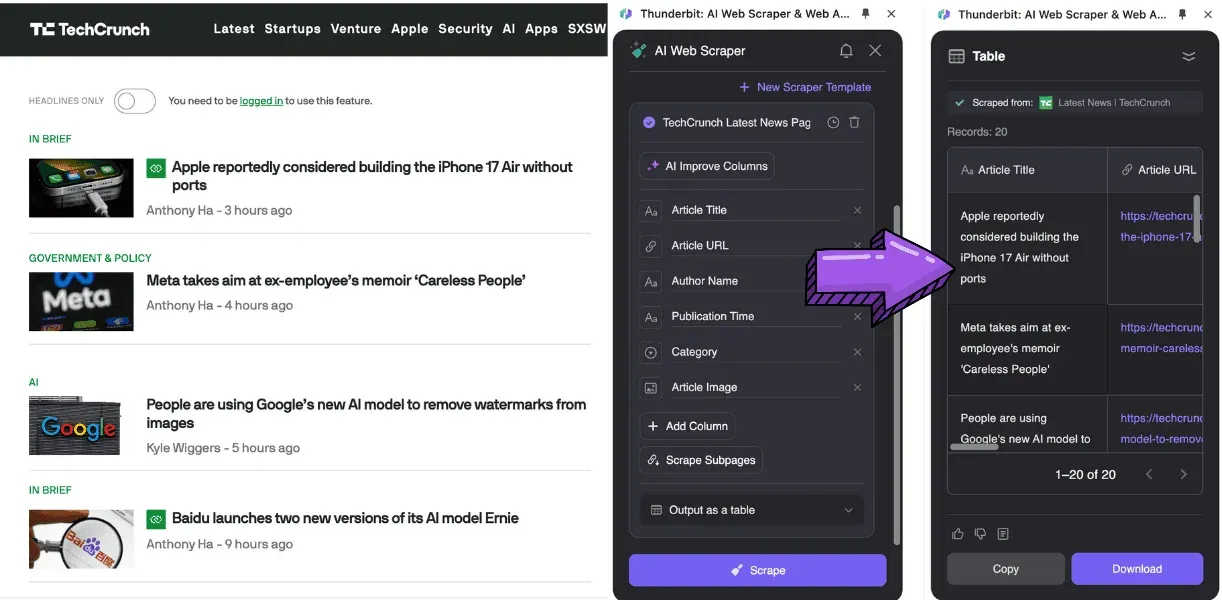
- Une intégration avec le NLP et le deep learning : pour mener à bien des tâches comme la traduction, le résumé et l'analyse de sentiment.
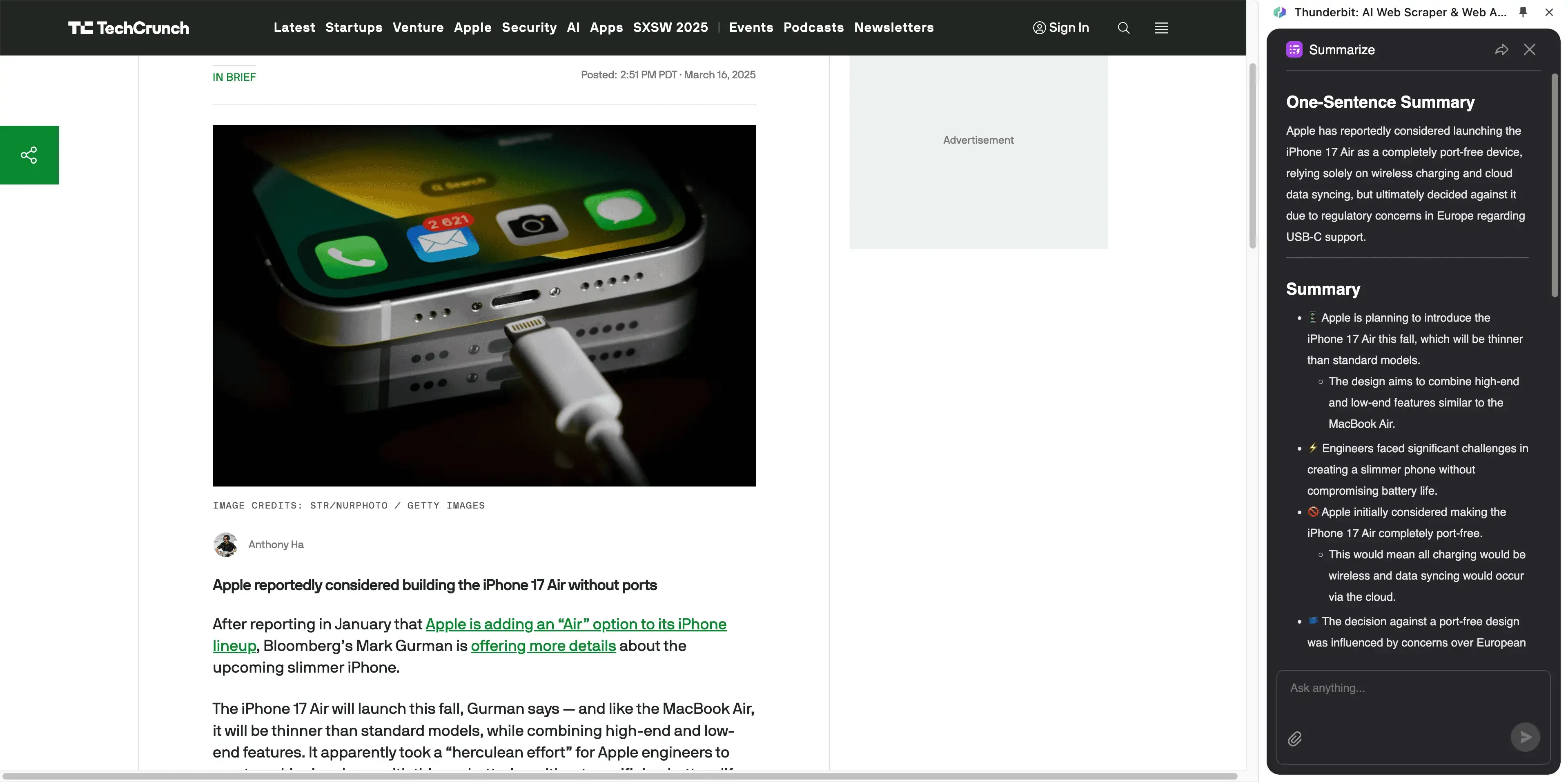
Qu'est-ce qui distingue le meilleur extracteur d'articles en 2026 ?
Un bon extracteur d'articles trouve le juste équilibre entre performance, coût, simplicité d'usage, souplesse et capacité à grandir. Voici les critères qui départagent les meilleurs extracteurs d'articles en 2026 :

- Simplicité d'usage : une interface intuitive, sans code.
- Précision d'extraction : un repérage fin des informations utiles, sans publicités ni éléments de navigation.
- Adaptabilité aux évolutions du web : un ajustement automatique aux changements de structure ou de style, sans maintenance à répétition.
- Polyvalence entre sites : un fonctionnement sur des structures web variées.
- Gestion du contenu dynamique : la prise en charge du chargement dynamique via JavaScript ou AJAX.
- Gestion des médias : la reconnaissance des images, vidéos et fichiers audio.
- Contournement de l'anti-extraction : rotation d'IP, résolution de CAPTCHA et proxys pour franchir les barrières anti-extraction.
- Consommation de ressources maîtrisée : sans appétit excessif en mémoire ni en puissance de calcul.
Les meilleurs extracteurs d'articles et de news en un coup d'œil
| Outils | Fonctionnalités clés | Idéal pour | Tarifs |
|---|---|---|---|
| Thunderbit | extracteur propulsé par l’IA ; modèles prêts à l’emploi ; prise en charge de l’extraction de PDF, d’images et de documents ; capacités avancées de traitement des données | Utilisateurs sans profil technique ayant besoin d’extraire plusieurs sites de niche | Essai gratuit de 7 jours, à partir de 9 $/mois (forfait annuel) |
| WebScraper.io | Extension de navigateur ; prise en charge du contenu dynamique ; sans intégration de proxy | Utilisateurs ne traitant pas de pages web complexes ni de fonctionnalités avancées | Essai gratuit de 7 jours, à partir de 40 $/mois (forfait annuel) |
| Browse.ai | Extracteur et outil de surveillance no-code ; robots préconstruits ; navigateur virtuel ; plusieurs méthodes de pagination ; intégration puissante | Entreprises ayant besoin d’extraire des sites complexes à grande échelle | 19 $/mois (forfait annuel) |
| Octoparse | Extracteur no-code basé sur les sélecteurs CSS ; détection automatique et génération du workflow d’extraction ; modèles d’extracteur d’articles prêts à l’emploi ; navigateur virtuel ; mécanismes anti-anti-extraction | Entreprises ayant besoin d’extraire des sites complexes | À partir de 99 $/mois (forfait annuel) |
| Bardeen | Capacités complètes d’automatisation web ; modèles prêts à l’emploi ; extracteur no-code ; intégration fluide avec l’espace de travail | Équipes GTM intégrant l’extraction d’articles dans des workflows existants | Essai gratuit de 7 jours, à partir de 99 $/mois (forfait annuel) |
| PandaExtract | Interface conviviale ; détection et étiquetage automatiques | Utilisateurs ayant besoin d’une extraction rapide en un clic, sans configuration complexe | 49 $ à vie |
L'extracteur d'articles IA le plus puissant pour les usages professionnels
- Avantages :
- Mobilise l'IA via le langage naturel pour reconnaître et analyser les informations web, sans aucun sélecteur CSS
- Analyse de données assistée par l'IA : conversion de format, synthèse, classification, traduction et balisage
- Modèles d'articles prêts à l'emploi pour extraire en un clic les listes d'articles et leur contenu
- Tarification accessible, au rapport qualité-prix très convaincant
- Inconvénients :
- Disponible pour l'instant uniquement sous forme d'extension Chrome
- Peu taillé pour l'extraction de données à très grande échelle
- Plus lent sur l'extraction multipage, mais l'exécution en arrière-plan permet d'accélérer les résultats
Essayer l’extracteur d’articles IA Thunderbit
Un extracteur d'articles dopé à l'IA pour les entreprises
Browse.ai
- Avantages :
- Extracteur et outil de surveillance d'articles no-code
- Fonctionnement via navigateur virtuel pour éviter de réveiller les mécanismes anti-extraction
- Une foule de robots d'extraction d'articles préconstruits pour aspirer en un clic Google News, Medium, Hacker News et bien d'autres
- Intégration poussée avec des plateformes comme Zapier et Make pour relier les outils
- Inconvénients :
- L'extraction approfondie réclame deux robots, ce qui alourdit le processus
- Les sélecteurs CSS manquent de précision sur les sites de niche
- Tarif élevé, mieux adapté à l'extraction continue à grande échelle
Un extracteur no-code pour l'extraction de données à petite échelle
PandaExtract
- Avantages :
- Repère automatiquement les listes d'articles et leurs détails grâce à une interface conviviale
- Sait extraire listes, fiches détaillées, e-mails et images — parfait pour de la donnée structurée à petite échelle
- Paiement unique pour une utilisation à vie
- Inconvénients :
- Disponible uniquement en extension de navigateur, sans exécution dans le cloud
- La version gratuite se limite au copier-coller, sans export vers CSV, JSON, etc.
Un extracteur d'articles prêt à l'emploi pour les organisations
Octoparse
- Avantages :
- Extracteur d'articles no-code à détection automatique, qui reconnaît la structure web et génère le workflow d'extraction
- Un large catalogue de modèles d'extracteurs d'articles prêts à l'emploi
- Navigateur virtuel avec rotation d'IP, résolution de CAPTCHA et proxys pour franchir les barrières anti-extraction
- Inconvénients :
- La détection automatique reste tributaire de la logique des sélecteurs CSS, avec une précision moyenne
- Les fonctions avancées exigent du temps d'apprentissage et un certain bagage technique
- Coût élevé pour l'extraction à grande échelle
L'automatisation la plus complète pour les équipes GTM
Bardeen
- Avantages :
- Extracteur d'articles no-code qui s'appuie sur un LLM pour une automatisation en un clic
- Se connecte à plus de 100 applications, dont Google Sheets, Slack et Zoom
- Outils d'automatisation web musclés pour l'analyse IA en aval de l'extraction
- Idéal pour glisser l'extraction de données dans des workflows déjà en place
- Inconvénients :
- Très dépendant des playbooks préconstruits ; les workflows sur mesure demandent essais et ajustements
- Malgré le no-code, comprendre et paramétrer des automatisations complexes peut donner du fil à retordre aux profils non techniques
- La configuration de l'extraction des sous-pages est ardue
- Très onéreux
Un extracteur d'articles léger pour une extraction instantanée
Webscraper.io
- Avantages :
- Extracteur no-code avec interface point-and-click
- Prend en charge le chargement de contenu dynamique
- Fonctionnement dans le cloud
- Intégration avec Dropbox, Google Sheets et Amazon
- Inconvénients :
- Aucun modèle prêt à l'emploi : il faut bâtir un sitemap personnalisé
- Une courbe d'apprentissage pour qui ne maîtrise pas les sélecteurs CSS
- Configuration épineuse pour la pagination et l'extraction des sous-pages
- La version cloud est coûteuse
Des solutions plus avancées pour les ingénieurs
Pour les profils techniques, il existe des API d'extraction d'articles. Ces solutions offrent :
- De la souplesse : des appels API directs pour une extraction sur mesure, avec rendu dynamique et rotation d'IP
- De la scalabilité : une intégration dans des pipelines de données personnalisés, pour des besoins d'entreprise à haute fréquence et à grand volume
- Une maintenance allégée : plus besoin de gérer ses pools de proxys ni ses stratégies anti-extraction, ce qui réduit la charge opérationnelle
Les solutions API en un coup d'œil
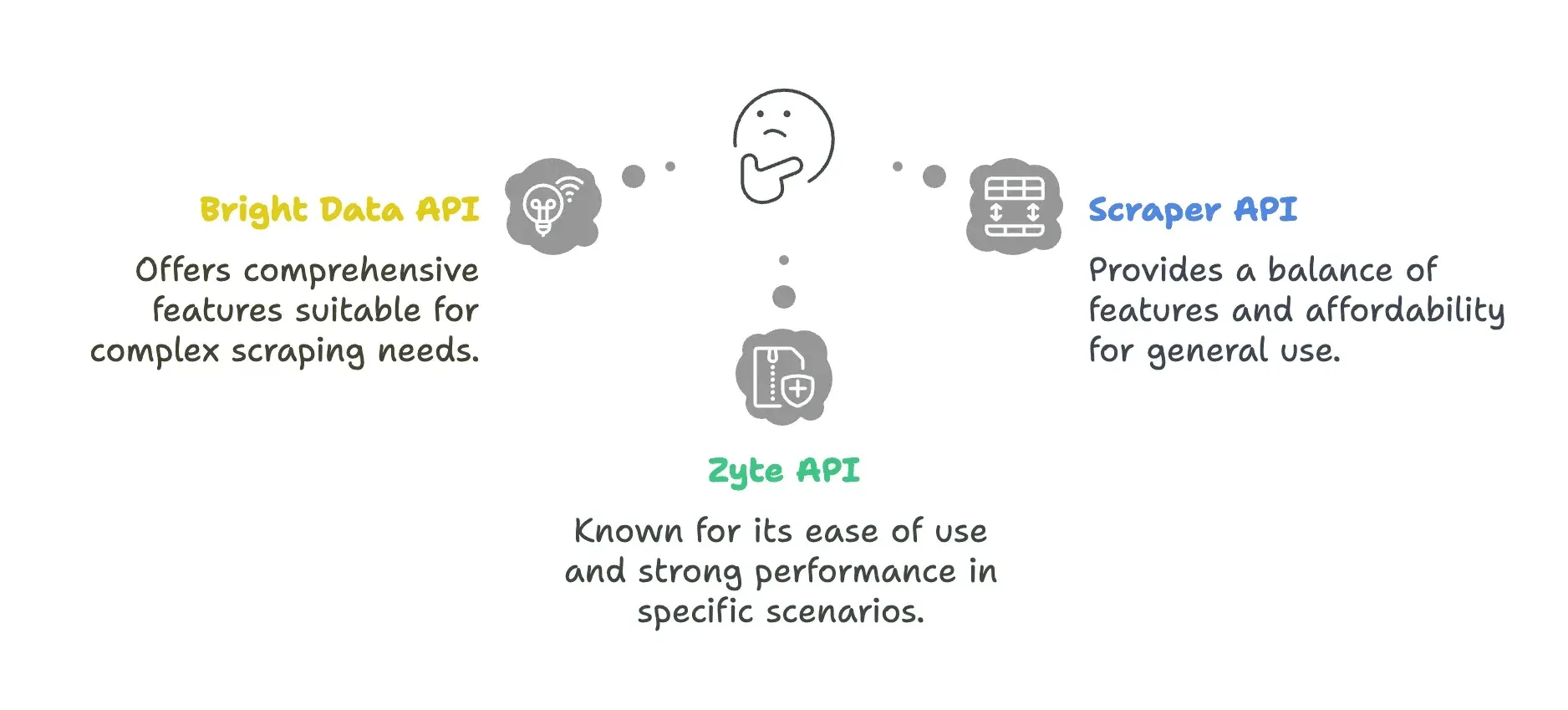
| API | Avantages | Inconvénients |
|---|---|---|
| Bright Data API | - Réseau de proxys très étendu (plus de 72 M d’IP dans 195 pays) - Géociblage avancé jusqu’au niveau de la ville ou du code postal - Proxy Manager robuste pour la rotation d’IP | - Temps de réponse plus lents (22,08 s en moyenne) - Tarifs élevés, peu adaptés aux petites équipes - Courbe d’apprentissage plus forte pour la configuration |
| ScraperAPI | - Entrée de gamme à 49 $ - Fonction Autoparse pour l’extraction automatique des données - Lecteur d’interface web pour les tests | - Facture souvent les requêtes bloquées - Capacités limitées de rendu JavaScript - Les coûts peuvent grimper avec les paramètres premium |
| Zyte API | - Capacités d’analyse par IA - Ne facture pas les requêtes échouées | - Coût initial plus élevé (environ 450 $/mois) - Les crédits ne sont pas reportés d’un mois à l’autre |
- API d'extraction Web Bright Data
- Avantages :
- Couvre 195 pays avec plus de 72 M d'IP résidentielles, gère la rotation automatique des IP et la simulation de géolocalisation — taillé pour les sites aux barrières anti-extraction sévères (par ex. Amazon et Instagram)
- Prend en charge le chargement dynamique de contenu JavaScript et la capture de snapshots de page
- Inconvénients :
- Coût élevé (facturation à la requête et à la bande passante), peu rentable pour les petits projets
- Avantages :
- Scraper API
- Avantages :
- 40 M de proxys à l'échelle mondiale, bascule automatique entre IP de centre de données et IP résidentielles, contournement de la vérification Cloudflare, résolution de CAPTCHA via des services tiers (par ex. 2Captcha)
- Points de terminaison structurés et extracteurs asynchrones pour une extraction plus rapide
- Inconvénients :
- Coût supplémentaire pour le rendu des pages dynamiques, prise en charge limitée des sites AJAX complexes
- Avantages :
- Zyte API
- Avantages :
- Extraction automatique de données web propulsée par l'IA, sans avoir à développer et entretenir des règles d'extraction pour chaque site
- Tarification flexible, à l'usage
- Inconvénients :
- Les fonctions avancées (gestion de session, navigateur scriptable, etc.) demandent un temps d'apprentissage
- Avantages :
Comment choisir votre extracteur d'articles et de news ?
Pour arrêter votre choix, partez de trois repères : vos besoins métier, votre niveau technique et votre budget.

- Si vous devez extraire plusieurs sites de niche sans construire un extracteur pour chaque page, et que le budget suit, Thunderbit s'impose. Il se passe des sélecteurs CSS au profit d'une analyse des structures web par l'IA, ce qui autorise aussi une analyse IA en aval. Pour l'IA de Thunderbit, tous les sites se valent, et les articles sont capturés dans leur intégralité, sans bavure.
- Pour aspirer des news et des articles sur de grands sites comme le Wall Street Journal ou Google News, visez un extracteur à l'anti-extraction solide, doté de modèles prêts à l'emploi, à l'image de Browse.ai ou d'Octoparse. Cela dit, la meilleure piste reste une extension Chrome comme Thunderbit : le processus imite la navigation et le copier-coller d'un humain, ce qui permet de composer avec les sessions connectées sans configuration alambiquée.
- Pour de l'extraction continue à grande échelle, les outils dotés de planification, comme Octoparse, prennent l'avantage.
- Pour un usage en équipe et une intégration sans accroc dans des workflows existants, Bardeen tire son épingle du jeu, avec une vaste panoplie d'automatisation web au-delà de la seule extraction d'articles.
- Si vous voulez un extracteur léger pour de petites extractions sans y passer la journée à apprendre, optez pour un outil point-and-click comme PandaExtract.
- Si vous avez un profil technique ou que vous bâtissez un extracteur d'articles d'entreprise, regardez du côté des API ou de votre propre extracteur, en complément de ces extracteurs no-code.
Conclusion
Ce tour d'horizon a posé le concept et les usages métier des extracteurs d'articles et de news. Les extracteurs classiques reposent sur des sélecteurs CSS, ce qui suppose une certaine connaissance du HTML et du CSS, surtout pour les opérations avancées. La nouvelle génération d'extracteurs d'articles propulsés par l'IA mise entièrement sur la compréhension sémantique et la reconnaissance visuelle, et devance les extracteurs classiques sur l'adaptation aux changements de structure, la généralisation d'un site à l'autre, la gestion du contenu dynamique, ainsi que le nettoyage et l'analyse des données en aval.
L'article a aussi passé en revue six extracteurs d'articles et de news utiles, sans oublier des outils API pour les développeurs, en comparant leurs forces et leurs faiblesses, les volumes de données auxquels ils conviennent, leurs fonctions web et leurs publics cibles. Au moment de vous lancer dans l'extraction d'articles et de news, retenez la solution qui épouse vos besoins métier tout en gardant performance et coût en équilibre.
FAQ
1. Qu'est-ce qu'un extracteur d'articles IA et comment fonctionne-t-il ?
- Il s'appuie sur l'IA pour analyser et extraire le contenu des pages web, sans le moindre sélecteur CSS.
- Il repère avec une grande précision titres, auteurs, dates de publication et contenu principal.
- Il évacue automatiquement publicités, menus de navigation et autres éléments parasites.
- Il s'ajuste aux changements de structure web et fonctionne sur des sites variés.
2. Quels sont les atouts d'un extracteur d'articles propulsé par l'IA face aux extracteurs classiques ?
- Il extrait le contenu de plusieurs sites avec un seul et même outil.
- Il gère le contenu dynamique, y compris les pages chargées en JavaScript et AJAX.
- Il réclame bien moins de configuration manuelle et de maintenance que les extracteurs basés sur le CSS.
- Il ajoute des fonctions complémentaires comme la synthèse, la traduction et l'analyse de sentiment.
3. Puis-je utiliser Thunderbit pour l'extraction d'articles IA sans savoir coder ?
- Oui, Thunderbit a été pensé pour les profils non techniques, avec une interface simple et sans code.
- Il s'appuie sur l'IA pour détecter et extraire automatiquement le contenu des articles.
- Il propose des modèles prêts à l'emploi pour une extraction rapide et efficace.
- Il permet d'exporter les données vers différents formats : CSV, JSON, Google Sheets.
En savoir plus :
- Qu'est-ce que le web scraping
- Comment utiliser l'IA pour le web scraping
- Web scraping moderne : plongée approfondie dans les outils propulsés par l'IA
- Scraping de news : outils, cas d'usage et défis
Essayer l’Extracteur Web IA Get Started Free




