
Kaikki puhuvat dataohjautuvasta päätöksenteosta, mutta harva pysähtyy miettimään, kuinka aikaa vievää ja työlästä datan kerääminen oikeasti on. Jos olet joskus yrittänyt koota tietoa käsin, tiedät, että se on hidasta hommaa. Olen nähnyt monen yrityksen kompastuvan dataohjautuvan strategian käynnistämisessä juuri tehottoman tiedonkeruun takia. Jos olet samassa tilanteessa, tästä artikkelista löydät tuoreita ratkaisuja.
💡 Tässä artikkelissa sukellamme datan kaappauksen maailmaan ja siihen, miten se kehittyy teknologian mukana. Käymme läpi vanhojen menetelmien heikkoudet, nostamme esiin tekoälypohjaisen datan kaappauksen hyödyt ja annamme käytännön vinkkejä oikeaan käyttöön.
Mitä on datan kaappaus?
Datan kaappaus eli web scraping tarkoittaa jäsennellyn tiedon poimimista verkkosivuilta työkaluilla, usein taulukkomuodossa. Se on erittäin tehokas tapa kerätä paljon tietoa nopeasti. Esimerkiksi voit hakea julkista dataa Google Mapsista liidien hankintaan, kerätä verkkokauppojen tuotetietoja Amazonista jälleenmyyntiä tai markkina-analyysiä varten tai poimia asiakasarvosteluja Yelpistä asiakasymmärryksen tueksi.
Teknologinen murros datan kaappauksessa
Aiemmin tiedonkeruu vaikutti siltä, että vain tekniikka-ihmiset pystyivät hoitamaan sen (tai siihen liittyi valtavasti manuaalista kopiointia ja liittämistä). Nyt eletään vuotta 2025, ja tekoäly on tullut mukaan peliin. Datan kaappaus ei ole enää vain ohjelmoijien tai yksinkertaisen automaation aluetta.
Perinteiset menetelmät eivät enää riitä
Nykyaikaiset verkkosivut tuovat mukanaan myös enemmän haasteita: dynaamista sisältölatausta (esimerkiksi React- ja Vue-kehysten avulla), multimodaalisen datan yleistymistä (teksti, video, kuvat) sekä epästandardeja tietorakenteita (sivulla voi olla useita eri mallipohjia). Tuoreet tutkimukset nostavat esiin kolme suurta ongelmaa perinteisissä web scraping -menetelmissä:
-
Ylläpitokustannusten musta aukko
Perinteiset web scraperit vaativat jatkuvaa käsin tehtävää ylläpitoa (noin 3–5 tuntia kuukaudessa per verkkosivu). Kun sivusto päivittyy tai sen frontend-kehys muuttuu, 60 % XPath-valitsimista rikkoutuu. Tekoälytyökalut voivat kielimallien ja koodiosaamisen avulla mukautua automaattisesti 90 %:iin rakenteellisista muutoksista, mikä voi leikata ylläpitokustannuksia 60–80 %. Reactilla tai Vuella rakennetuilta moderneilta sivustoilta tekoäly pystyy pitämään datan kaappauksen vakaana semanttisen ymmärryksen avulla, vaikka luokkanimet vaihtuisivat. -
Rajoittunut datan kattavuus
Perinteiset menetelmät poimivat vain jäsenneltyä dataa ja ohittavat arvokasta tietoa, kuten:- kuvien sisällä olevan tiedon
- artikkeleihin kätkeytyvän tekstin
- rakenteettoman datan ilman HTML-tageja
-
Laadunhallinnan ongelmat
Perinteiset menetelmät eivät pärjää dynaamisen sisällön kanssa, mikä johtaa puutteelliseen tai virheelliseen dataan:- sivunvaihdollisessa sisällössä (esimerkiksi verkkokaupan tuoteluettelot) perinteiset scraperit poimivat vain 30–50 % ensimmäisen näkymän sisällöstä
- loputtomasti rullaavilla sivuilla (esimerkiksi somevirrat) katoaa yli 60 % olennaisesta datasta
- rakenteettoman datan yhteensovittamisessa virheprosentti on korkea (esimerkiksi listat menevät ristiin)
Tässä kohtaa kuvaan astuvat Thunderbitin kaltaiset tekoälypohjaiset työkalut. Kerron niiden eduista tarkemmin alla.
Tekoälypohjaisen datan kaappauksen nousu
Kaappaa dataa miltä tahansa verkkosivulta tekoälyn avulla Get Started Free
Vuoteen 2025 mennessä tekoäly, erityisesti suuret kielimallit (LLM), on osoittanut vahvat kykynsä. Nämä mallit ymmärtävät ja tuottavat luonnollista kieltä, ratkaisevat monimutkaisia analyysitehtäviä ja tarjoavat tehokkaampia tapoja työskennellä. Moni datan kaappauksen työkalu hyödyntää nykyään LLM:iä ohittaakseen perinteisten menetelmien rajoitukset. Kun olen testannut viime kuukausina 13 datan kaappauksen työkalua, suosittelen Thunderbit AI Web Scraperia.
Miksi Thunderbit erottuu joukosta:
-
Uudenlainen käyttötapa: Käyttäjä voi kirjoittaa yksinkertaisen luonnollisen kielen komennon, ja järjestelmä luo kaappaussuunnitelman automaattisesti. Tämä voi vähentää asetusten määrittelyaikaa 87 % verrattuna perinteisiin työkaluihin.
-
Paikallisen kaappauksen merkittävät edut: Selainlaajennuksena Thunderbit tarjoaa:
- välittömän datan kaappauksen
- dynaamisten ja loputtomasti rullaavien sivujen kaappauksen
- kirjautumista vaativien sivujen kaappauksen
-
Vahva multimodaalisen datan käsittely: Thunderbit pystyy käsittelemään monenlaisia datatyyppejä, kuten:
- tekstin poimimisen artikkeleista
- taloustietotaulukoiden poimimisen PDF-tiedostoista
- datan tunnistamisen useista kuvista ja niiden muuntamisen taulukoksi
- videoiden tekstitysten kaappaamisen ja niiden tiivistämisen
Thunderbitin avulla voit hoitaa monenlaiset tiedonkeruutilanteet helposti. Katsotaan seuraavaksi, miten Thunderbitia käytetään.
Miten dataa kaapataan tekoälyn avulla
Seuraa näitä neljää vaihetta hyödyntääksesi Thunderbitin tehokkaita AI-web scraping -ominaisuuksia:
-
Asenna selainlaajennus Siirry Thunderbitin sivustolle ja lataa Thunderbit-laajennus Chrome Web Storesta. Kun asennus on valmis, kiinnitä laajennus selaimesi työkalupalkkiin.
-
Rekisteröidy ja saat ilmaiset krediitit Luo tili laajennuksen kautta saadaksesi kokeilukrediittejä. Niillä voit testata ydintoimintoja, kuten AI-web scrapingia, lomakkeiden automaattitäyttöä ja älykästä tiivistämistä. Kannattaa ensin kokeilla työkalua ilmaiseksi playground-ympäristössä ennen krediittien käyttöä, jotta näet sen tehon käytännössä.
-
Käynnistä älykäs kaappaus Avaa Thunderbitin sivupalkista sopiva malli. Valitse haluamasi data ja tietotyyppi luonnollisen kielen kuvauksilla, määritä tarvittaessa tarkat poimintamuodot tai säädä muita asetuksia. Paina sitten kaappauspainiketta ja aloita datan keruu.
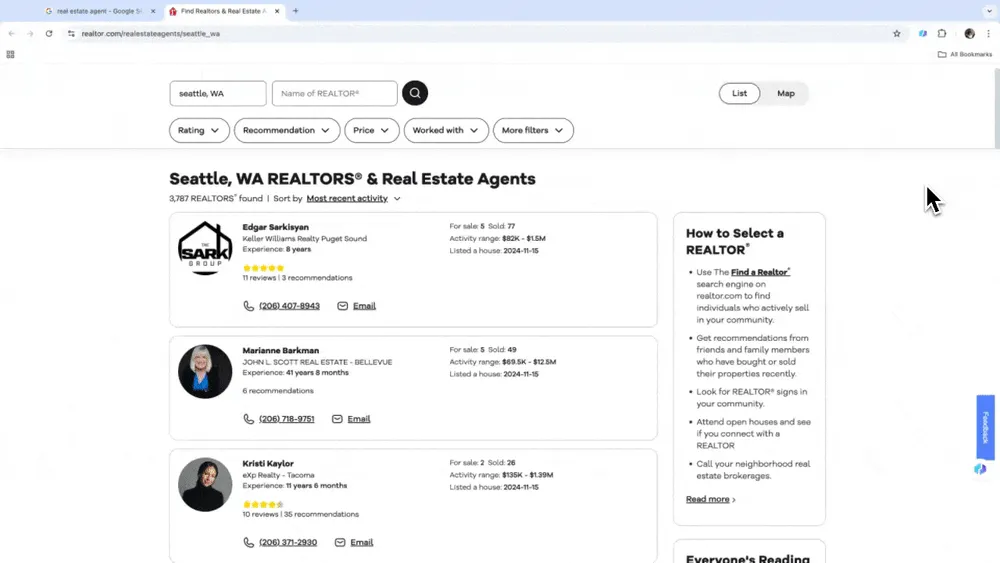
Edistyneet kaappausominaisuudet (Pro-taso)
Kun tilaat Thunderbitin Pro-tason (tai aloitat ilmaisen kokeilun), saat käyttöösi nämä ominaisuudet:
-
Multimodaalinen datankäsittely Tukee monimutkaisia tilanteita, kuten PDF-dokumenttien analysointia (talousraportit / käyttöohjeet), kuvista poimittavaa dataa (hintalaput / tekniset tiedot) ja videoiden tekstitysten kaappaamista. Järjestelmä standardoi rakenteettoman datan automaattisesti.
-
Syvällinen alasivujen kaappaus Voit halutessasi avata kaikki sivun alaslinkit (esimerkiksi tuotesivut/asiakasarvostelusivut), tunnistaa niistä älykkäästi liittyvän tiedon ja yhdistää sen automaattisesti päätaulukkoon. Erinomainen verkkokauppojen tuotekatalogeihin, asuntokohdelistoihin ja muuhun vastaavaan.
-
Valmiit mallipohjat Käytä heti optimoituja kaappausmalleja yli 30 alustalle, kuten TikTokiin, Amazoniin ja Zillow’hun. Mallit mukautuvat automaattisesti sivurakenteen muutoksiin. Uudet käyttäjät säästävät keskimäärin 83 % asetusaikaa.
-
Massakaappaus Suorita useita kaappaustehtäviä yhtä aikaa ja tuo URL-listoja eräajoa varten.
-
Älykäs sivutus Tunnistaa ja kaappaa automaattisesti sivutetun sisällön, mukaan lukien "lataa lisää" -painikkeet ja sivunavigoinnin, sekä tukee loputtomasti rullaavia sivuja. Testeissä on onnistuttu kaappaamaan kokonaan yli 200 sivua verkkokauppojen tuoteluetteloita.
Thunderbitin käytännön opas
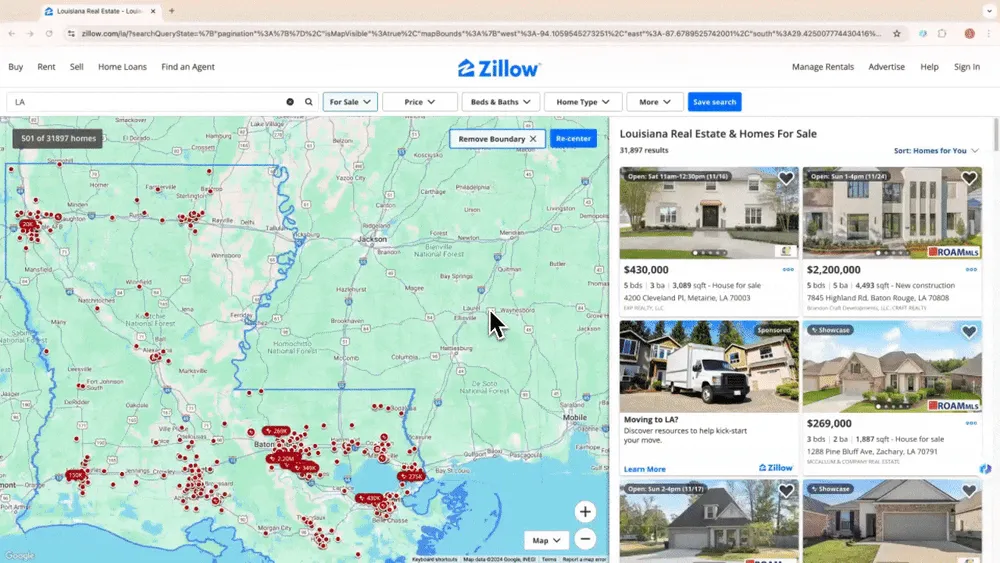
Skenaario 1: Kiinteistödatan kerääminen
Jos olet kiinteistönvälittäjä ja haluat kerätä kohdetietoja Zillownista tai sijoittaja, joka etsii tuottoisia mahdollisuuksia, luotettava web scraper voi olla paras apurisi. Thunderbitin AI web scraperin avulla voit helposti poimia tärkeät kiinteistötiedot Zillownista ja pysyä ajan tasalla sekä kilpailukykyisenä. Katso opastusvideo siitä, miten Zillow’ta kaapataan Thunderbitilla.
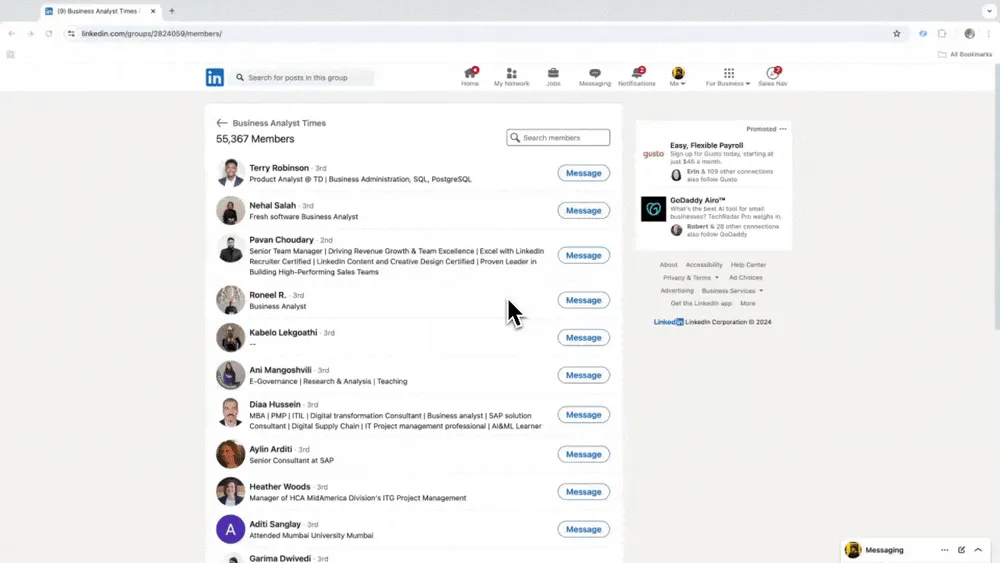
Skenaario 2: Rekrytointi ja liidien etsintä
Jos työskentelet HR:ssä ja etsit osaajia tai olet myyjä, joka hakee uusia liidejä, luotettava web scraper voi olla tehokas apuri. Thunderbitin avulla voit poimia hyödyllisiä yhteystieto- ja yritystietoja julkisilta verkkosivuilta, hakemistoista ja profiilisivuilta, mikä auttaa tehostamaan osaajahakua ja liidien hallintaa. Kun olet käyttänyt sitä, huomaat, että aikaa vievä manuaalinen hakeminen ja kopiointi-liittäminen jäävät historiaan. Valmiiseen työnkulkuun pääset aloittamalla Website Contact Scraperilla.
Skenaario 3: Markkina-analyysi ja asiakassegmentointi
Jos olet yrityksen omistaja ja keräät sijaintipohjaista dataa markkina-analyysiä varten, tai myyntityöntekijä, joka etsii paikallisia yritysliidejä, luotettava web scraper voi muuttaa pelin. Thunderbitin avulla voit helposti poimia keskeisiä tietoja Google Mapsista, mikä auttaa tekemään parempia päätöksiä ja kohdentamaan viestintääsi tehokkaammin.
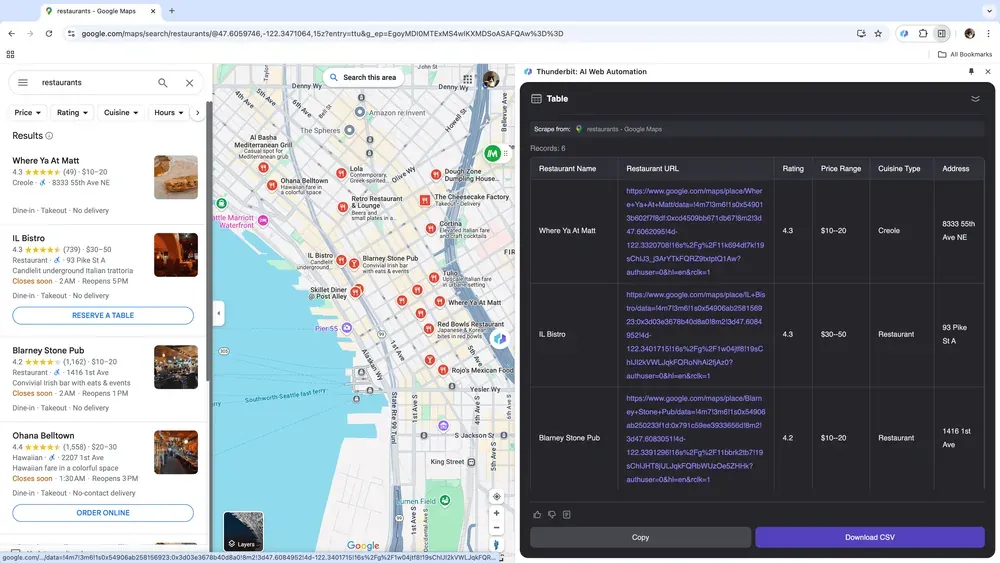
Skenaario 4: Verkkokaupan data-analyysi
Jos olet verkkokauppias ja haluat ymmärtää kilpailijoita, tai yrittäjä, joka seuraa markkinatrendejä, Thunderbit on juuri oikea työkalu! Se voi kerätä helposti monenlaisia tuotetietoja Amazonista, mukaan lukien yksityiskohtaiset kuvaukset, hinnat ja käyttäjäarvostelut.
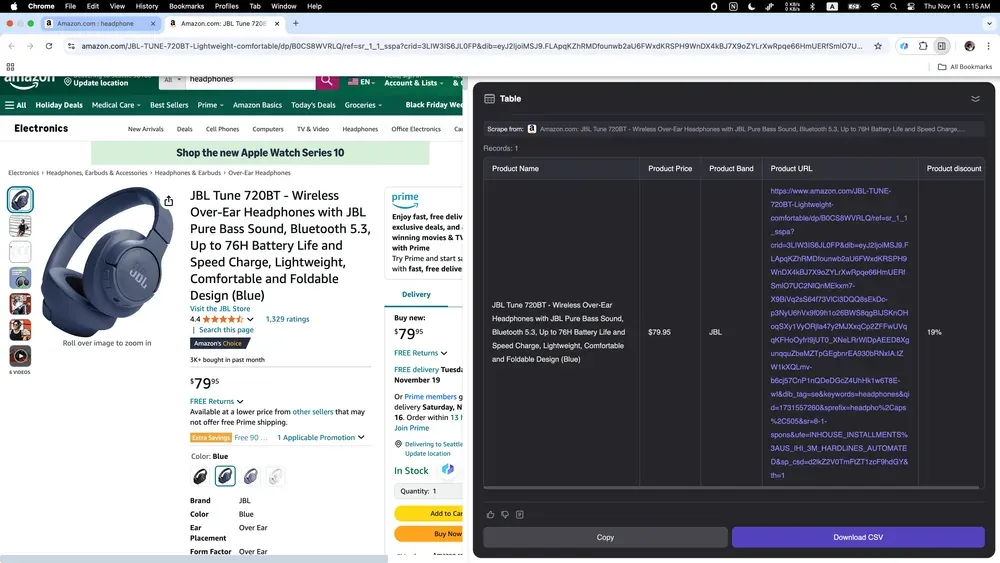
Thunderbit AI web scraper määrittelee uudelleen sen, miten liiketoiminnan käyttäjät keräävät dataa: se tekee siitä nopeampaa, yksinkertaisempaa ja tehokkaampaa kuin koskaan. Etsitpä sitten asuntokohteita, potentiaalisia asiakkaita tai verkkokaupan trendejä, AI web scraper voi säästää lukemattomia tunteja ja vaivaa. Ota tekoälyn voima käyttöön web scrapingissa ja huomaa tuottavuutesi loikkaavan uudelle tasolle. Valmis aloittamaan? Kokeile Thunderbitia ja ota ensimmäinen askel kohti älykkäämpää web scrapingia.
Kokeile Thunderbit AI Web Scraperia
Ainutlaatuiset vinkit datan puhdistamiseen
Perinteisillä scrapereilla varsinainen työ alkaa vasta datan kaappauksen jälkeen – eli datan puhdistamisesta. Thunderbitin tekoäly voi hoitaa datan puhdistusta jo kaappauksen aikana LLM:n avulla, mikä vähentää puhdistustyötä 83 % seuraavien innovatiivisten ominaisuuksien ansiosta:
Vinkki 1: Älykäs kenttien yhteensovitus
Kun käsittelet useista lähteistä tulevaa heterogeenista dataa (esimerkiksi LinkedInin ja Zillownin yhtäaikaista kaappausta), Thunderbitin tekoäly muodostaa automaattisesti semanttiset vastaavuudet:
- tunnistaa automaattisesti kenttien vastaavuudet eri tietolähteiden välillä (esim. "price" ↔ "售价" ↔ "Price")
- yhdistää älykkäästi samankaltaiset kentät (esim. "area" ja "square feet")
- standardoi dataa eri alustoilla (esim. LinkedInin "current position" ja Zillownin "property status" voidaan yhtenäistää tagitiedoksi)
Vinkki 2: Kontekstin ymmärtävä täydentäminen
Suurten kielimallien kontekstin ymmärtämisen ansiosta Thunderbit saavuttaa alan huipputason 99 %:n tietojen täyttöasteen:
- Osoitteen täydentäminen: täyttää automaattisesti kaupungin ja osavaltion postinumeron perusteella (esim. syöte 10001 → New York City, NY)
- Urapolun päättely: ennustaa mahdollisia työkokemuksia LinkedInin koulutustaustan perusteella
Vinkki 3: Datan optimointi
- Monikielinen käännös (tukee reaaliaikaista käännöstä 12 kielellä, mukaan lukien englanti, kiina ja japani)
- Älykäs tiivistäminen (muuntaa 500 sanan tuotekuvauksen kolmeksi tärkeimmäksi myyntiväittämäksi)
- Yksikköjen yhtenäistäminen (muuntaa automaattisesti neliöjalat ↔ neliömetrit, Fahrenheit ↔ Celsius)
- Muotojen standardointi (päivämäärät muotoon YYYY-MM-DD, valuutta muotoon USD)
Vinkki 4: Laadun varmistus
- Älykäs virheenkorjaus: korjaa automaattisesti muotovirheet (esim. puhelinnumero +01 138-1234-5678 → +113812345678)
- Looginen validointi: varmistaa, että "year built" on aikaisempi kuin "last renovation time"
Vinkki 5: AI-tunnisteet
Luo automaattisesti älykkäitä tunnisteita luonnollisen kielen käsittelyn avulla:
- tunnelma-analyysin tunnisteet (merkitsee asiakasarviot automaattisesti positiivisiksi/negatiivisiksi/neutraaleiksi)
- liiketoiminta-arvon tunnisteet (merkitsee automaattisesti "high-potential clients" / "properties to follow up on")
- toimialaluokituksen tunnisteet (merkitsee LinkedIn-profiilit automaattisesti tunnisteilla "tech|finance|healthcare")
Datan kaappauksen varjopuoli
Vaikka datan kaappaus tarjoaa valtavasti arvoa, on tärkeää tunnistaa myös sen haasteet. Lainsäädäntö nousee eturiviin – GDPR:n ja CCPA:n kaltaiset säädökset asettavat tiukat vaatimukset tiedonkeruulle, mikä edellyttää huolellista yksityisyyslakien noudattamista. Verkkosivustot käyttävät usein kehittyneitä suojauksia, kuten Cloudflarea, tunnistamaan ja estämään kaappausyrityksiä IP-rajoitusten avulla.
Datan kaappauksen tulevaisuus tekoälyn aikakaudella
Tekoälyn kehitys muuttaa web scrapingin intuitiiviseksi yritysratkaisuksi. Kuvittele, että syötät vain domainin (esim. zillow.com) ja pyynnön (esim. "kaappaa kaikki New York Cityn asuntoilmoitukset"), ja tekoäly muodostaa automaattisesti kaikki olennaiset tietopisteet – kohdetiedoista hintatrendeihin – ilman manuaalista konfigurointia. Nämä älykkäät järjestelmät integroivat kaapatun datan sujuvasti yrityksen työnkulkuihin, syöttäen LinkedIn-liidit automaattisesti CRM-järjestelmiin tai siirtäen verkkokaupan mittarit analytiikkataulukoihin. Edistynyt mallintunnistus mahdollistaa ennakoivan kaappauksen, joka valvoo ennakolta varastomuutoksia tai nousevia markkinatrendejä. Tärkeää on myös, että tekoäly hoitaa vaatimustenmukaisuuden dynaamisesti ja mukauttaa kaappausparametreja reaaliajassa muuttuvien säädösten mukaan säilyttäen samalla läpinäkyvät auditointijäljet.
Tekoälyyn perustuva murros ei ainoastaan demokratisoi pääsyä kriittiseen liiketoimintatietoon, vaan muuttaa perusteellisesti sitä, miten organisaatiot työskentelevät verkkodatan kanssa. Kun nämä teknologiat kypsyvät, aikaisin liikkeellä olevat ja Thunderbitin kaltaisia AI-pohjaisia kaappausratkaisuja käyttävät toimijat saavat ratkaisevan kilpailuedun dataohjautuvassa päätöksenteossa.
UKK
-
Mikä Thunderbit on? Thunderbit on suurten kielimallien (LLM) pohjalta rakennettu älykäs selainlaajennus, joka on suunniteltu nykyaikaisiin tiedonkeruutarpeisiin. Se tarjoaa paitsi AI-web scraping -ominaisuudet myös multimodaalisen datankäsittelyn, joten se tukee kattavaa tiedon poimintaa dynaamisilta verkkosivuilta, PDF-dokumenteista, kuvista ja videoista. Paikallisena selainratkaisuna se pystyy käsittelemään suoraan kirjautumista vaativia sivuja (kuten LinkedIn) ja mukautumaan automaattisesti modernien frontend-kehysten muutoksiin.
-
Miten Thunderbitin AI web scraper toimii? Thunderbitin AI web scraper käyttää tekoälyä jäsennellyn tiedon poimimiseen verkkosivuilta. Käyttäjä voi klikata "AI Suggest Columns" -toimintoa, jolloin tekoäly ehdottaa, miten nykyinen sivusto kannattaa kaapata, ja sitten klikata "Scrape" kerätäkseen tiedot. Se pystyy käsittelemään dataa miltä tahansa verkkosivulta, PDF:stä tai kuvasta vain kahdella klikkauksella.
-
Mitä eroa on listakaappauksella ja alasivukaappauksella? Listakaappaus on optimoitu sivutetuille tilanteille (esimerkiksi verkkokaupan tuotelistoille). Se tunnistaa automaattisesti sivutuslogiikan ja kaappaa tuhansia tietueita. Alasivukaappaus käyttää puurakenteista keruutilaa (esimerkiksi Zillown kohdelistaus → yksityiskohtaiset sivut → pohjaratkaisut), ja se muodostaa automaattisesti pää- ja alataulujen väliset suhteet semanttisen yhteyden avulla.
-
Voivatko ei-ohjelmoijat käyttää Thunderbitia? Thunderbitissä on luonnolliseen kieleen perustuva käyttötapa: käyttäjä kuvaa vain tarpeensa, kuten "name, email, phone", ja järjestelmä luo kaappaussuunnitelman automaattisesti. Testidatamme mukaan 85 % käyttäjistä saa ensimmäisen datankeruunsa valmiiksi 10 minuutissa ilman mitään verkkokoodauksen osaamista.
-
Minkä tyyppistä dataa Thunderbit käsittelee? Thunderbit tukee monien tietotyyppien älykästä tunnistusta:
- jäsennelty data: taulukot, listat (esim. Amazonin tuotespesifikaatiot)
- rakenteeton data: arvosteluteksti, PDF-dokumentit (automaattinen tunnistus)
- multimodaalinen data: hintalaput kuvissa, videoiden tekstitysten poiminta
- dynaaminen data: loputtomasti rullaava sisältö, viiveellä latautuvat kuvat
- liittyvä data: sivujen välinen suhdekartoitus (esim. LinkedIn-yhteydet → yritystiedot)
-
Miten Thunderbitin käytön voi aloittaa? Lue lisää meidän kaappausominaisuuksistamme tai tutustu mallikirjastoomme ja aloita heti.
Lisätietoja:
- The Best Web Scraping Tools & Software in 2025
- How to Scrape Any Website Using AI
- How to set up Thunderbit
Kokeile AI Web Scraperia Get Started Free




