
Los rastreadores web son los héroes anónimos de internet. Cada vez que buscas una nueva receta, consultas los últimos precios de tus zapatillas favoritas o comparas hoteles para tus próximas vacaciones, es muy probable que un rastreador web ya haya pasado por ahí, reuniendo y organizando en silencio la información que ves. De hecho, se estima que aproximadamente la mitad de todo el tráfico de internet ya lo generan bots y rastreadores, no personas; encuestas recientes del sector sitúan la cuota de bots entre el 49 y el 51 %. Así es: mientras duermes, estos exploradores digitales recorren la web sin descanso, asegurándose de que la información del mundo esté a solo un clic de distancia.
Pero, ¿qué son exactamente los rastreadores web? ¿Por qué son tan importantes para las empresas, los investigadores y cualquiera que dependa de datos actualizados? ¿Y cómo herramientas modernas como Thunderbit han hecho que el rastreo web sea accesible para todo el mundo, no solo para programadores o gigantes tecnológicos? Como alguien que lleva años desarrollando herramientas de automatización e IA, he visto de primera mano cómo los rastreadores web pasaron de ser misteriosas “arañas” a convertirse en herramientas imprescindibles del día a día para los negocios. Vamos a adentrarnos y a desmitificar el mundo de los rastreadores web: qué son, cómo funcionan y por qué serán la base de un acceso más inteligente a los datos en 2026.
Los rastreadores web son los exploradores de datos de internet
Extrae datos de cualquier sitio web usando IA Get Started Free
Entonces, ¿qué son realmente los rastreadores web? En esencia, los rastreadores web (también conocidos como spiders o bots) son programas automatizados que navegan por internet de forma sistemática, visitando una página web tras otra y recopilando información a medida que avanzan. Piensa en ellos como los becarios de investigación más incansables del mundo: no duermen, no se quejan y pueden visitar millones de páginas en un solo día.
Un rastreador web empieza con una lista de direcciones web (llamadas “semillas”), visita cada una y luego sigue los enlaces que encuentra para descubrir nuevas páginas. Mientras explora, copia contenido, indexa datos y construye un mapa del paisaje web, que cambia constantemente (Cloudflare). Así es como motores de búsqueda como Google saben qué hay ahí fuera, y cómo los sitios de comparación de precios o las herramientas de investigación de mercado mantienen sus datos actualizados.
Dicho de forma simple: los rastreadores web son los exploradores que hacen que internet sea buscable, comparable y útil.
Las muchas caras de los rastreadores web: tipos y funciones principales
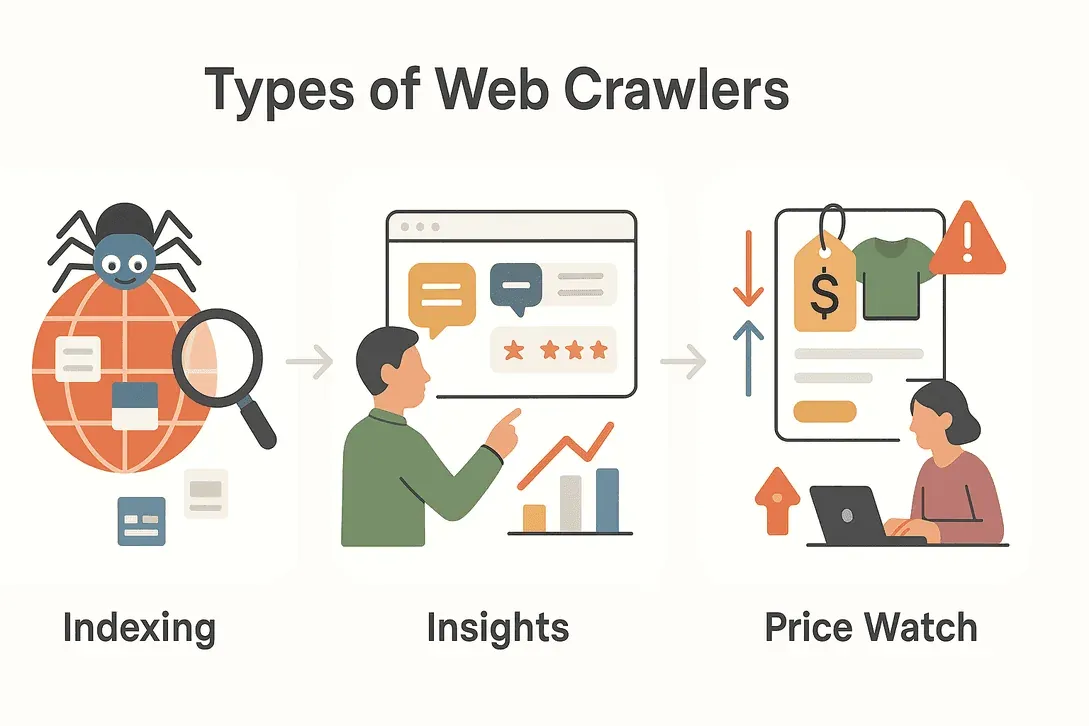 No todos los rastreadores web cumplen la misma función. Según su misión, hay varios tipos, cada uno con su especialidad. Aquí tienes un repaso rápido de los principales:
No todos los rastreadores web cumplen la misma función. Según su misión, hay varios tipos, cada uno con su especialidad. Aquí tienes un repaso rápido de los principales:
| Tipo | Función principal | Caso de uso típico |
|---|---|---|
| Rastreadores de motores de búsqueda | Indexan la web para los resultados de búsqueda | Googlebot, Bingbot indexando sitios nuevos |
| Rastreadores de minería de datos | Reúnen grandes conjuntos de datos para análisis | Investigación de mercado, estudios académicos |
| Rastreadores de seguimiento de precios | Controlan precios y disponibilidad de productos | Comparación de precios en e-commerce, precios dinámicos |
| Rastreadores de agregación de contenido | Recopilan artículos, noticias o publicaciones para agregarlos | Portales de noticias, curación de contenido |
| Rastreadores de generación de leads | Extraen información de contacto y datos empresariales | Prospección comercial, directorios B2B |
Veamos algunas de estas categorías con más detalle:
Rastreadores de motores de búsqueda
Cuando escribes una pregunta en Google, estás confiando en el trabajo de los rastreadores de motores de búsqueda. Estos bots recorren la web las 24 horas del día, los 7 días de la semana, descubriendo páginas nuevas, actualizando las antiguas e indexando contenido para que aparezca en los resultados de búsqueda. Sin rastreadores, los motores de búsqueda irían a ciegas: no tendrían forma de saber qué es nuevo, qué ha cambiado ni qué existe siquiera (TechTarget).
Rastreadores de minería de datos e investigación de mercado
Las empresas y los investigadores usan rastreadores para reunir enormes volúmenes de datos con fines de análisis. ¿Quieres saber cuántas veces se menciona la marca de un competidor en internet? ¿O seguir el sentimiento en torno al lanzamiento de un nuevo producto? Los rastreadores de minería de datos pueden explorar foros, reseñas, redes sociales y más, convirtiendo la web caótica en información estructurada (DataHut).
Rastreadores de seguimiento de precios y productos
En el vertiginoso mundo del comercio electrónico, los precios y los detalles de los productos cambian constantemente. Los rastreadores de seguimiento de precios vigilan a la competencia y avisan a las empresas de bajadas de precio, cambios de stock o lanzamientos de nuevos productos. Esto permite estrategias de precios dinámicos y ayuda a las compañías a seguir siendo competitivas (AIMultiple).
Por qué los rastreadores web son esenciales para el acceso moderno a los datos
Seamos sinceros: internet es demasiado grande para que los humanos podamos seguirle el ritmo de forma manual. Ya hay más de 1.400 millones de sitios web —y siguen creciendo—, con alrededor de un millón de nuevos sitios añadidos cada día. Los rastreadores web permiten:
- Escalar la recopilación de datos: visitar millones de páginas en horas, no en meses.
- Mantenerse al día: supervisar continuamente cambios, contenido nuevo o noticias de última hora.
- Acceder a información dinámica y en tiempo real: responder a cambios del mercado, variaciones de precios o temas de tendencia en el momento en que ocurren.
- Tomar decisiones basadas en datos: impulsar desde motores de búsqueda hasta investigación de mercado, gestión de riesgos y modelado financiero (DEV Community).
En un mundo donde los datos son la columna vertebral de la estrategia digital de negocio, los rastreadores web son los motores que mantienen ese flujo de datos.
Casos de uso comunes de los rastreadores web en distintos sectores
Los rastreadores web no son solo cosa de gigantes tecnológicos o motores de búsqueda. Así es como distintas industrias los aprovechan:
| Sector | Caso de uso | Beneficio |
|---|---|---|
| Ventas | Generación de leads | Crear listas de prospectos segmentadas a partir de directorios |
| E-commerce | Seguimiento de precios | Vigilar precios, stock y cambios de productos de la competencia |
| Marketing | Agregación de contenido | Curar noticias, artículos y menciones en redes sociales |
| Bienes raíces | Agregación de anuncios inmobiliarios | Unificar anuncios de múltiples fuentes |
| Viajes | Comparación de tarifas y hoteles | Supervisar precios, disponibilidad y políticas |
| Finanzas | Supervisión de riesgos | Seguir noticias, informes y sentimiento para inversiones |
Ejemplo del mundo real:
Una agencia inmobiliaria usa rastreadores para extraer detalles de propiedades, fotos y servicios desde varios portales, ofreciendo a sus clientes una visión unificada y actualizada del mercado (DataHut).
Un equipo de e-commerce configura rastreadores para supervisar los SKU y los precios de la competencia, ajustando su propia estrategia en tiempo real (AIMultiple).
Cómo funcionan los rastreadores web: resumen paso a paso
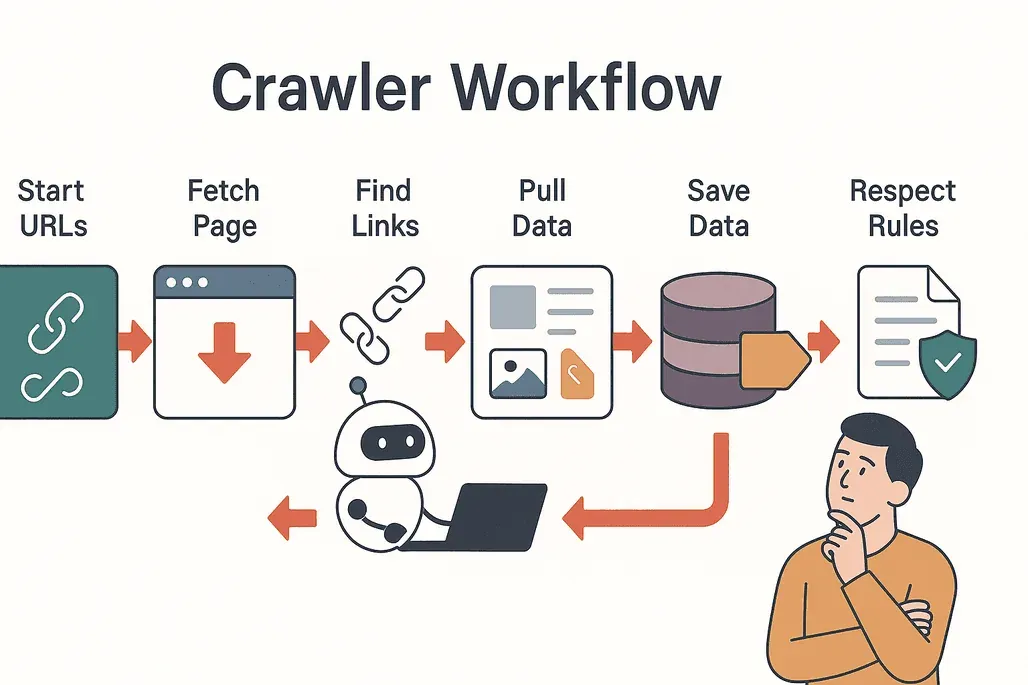 Vamos a desmitificar el proceso. Así funciona un rastreador web típico:
Vamos a desmitificar el proceso. Así funciona un rastreador web típico:
- Empieza con semillas: el rastreador comienza con una lista de URL iniciales.
- Visita y descarga: accede a cada página y descarga el contenido.
- Extrae enlaces: el rastreador encuentra todos los enlaces de la página.
- Sigue los enlaces: añade a su cola los enlaces nuevos que aún no ha visitado.
- Extrae datos: la información relevante (texto, imágenes, precios, etc.) se copia y se estructura.
- Guarda los resultados: los datos se almacenan en una base de datos o se exportan para su análisis.
- Respeta las normas: el rastreador revisa el archivo
robots.txtde cada sitio para ver qué está permitido y evitar las zonas restringidas (Cloudflare).
Buenas prácticas:
- Rastrea con cortesía (no sobrecargues los servidores).
- Respeta la privacidad y los límites legales.
- Evita el contenido duplicado y las solicitudes innecesarias.
Desafíos y consideraciones al usar rastreadores web
El rastreo web no es un camino de rosas. Estos son algunos obstáculos comunes:
- Carga del servidor: demasiadas solicitudes pueden ralentizar o incluso tumbar un sitio web.
- Contenido duplicado: los rastreadores pueden volver a visitar las mismas páginas o quedarse atascados en bucles.
- Privacidad y legalidad: no todos los datos son de libre uso; revisa siempre los términos del servicio y las leyes de privacidad.
- Barreras técnicas: algunos sitios usan CAPTCHAs, contenido dinámico o medidas anti-bot para bloquear rastreadores (DEV Community).
Consejos para tener éxito:
- Usa ritmos de rastreo respetuosos.
- Vigila los cambios en la estructura del sitio web.
- Mantente al día con las normativas de privacidad de datos.
Thunderbit: haciendo accesibles los rastreadores web para todo el mundo
Aquí es donde la cosa se pone interesante. Tradicionalmente, configurar un rastreador web significaba escribir código, ajustar parámetros y pasar horas solucionando errores. Pero con Thunderbit, hemos cambiado las reglas del juego.
Thunderbit es una extensión de Chrome de raspador web con IA diseñada para usuarios de negocios, sin necesidad de programar. Esto es lo que la hace destacar:
- Instrucciones en lenguaje natural: solo describe qué datos quieres (“Extrae todos los nombres y precios de productos de esta página”) y la IA de Thunderbit hace el resto.
- Sugerencias de campos impulsadas por IA: haz clic en “AI Suggest Fields” y Thunderbit leerá la página para recomendar las mejores columnas que extraer.
- Raspado de subpáginas: ¿Necesitas más detalles? Thunderbit puede visitar cada subpágina (como fichas de producto o perfiles de LinkedIn) y enriquecer automáticamente tu conjunto de datos.
- Plantillas instantáneas: para sitios populares (Amazon, Zillow, Shopify, etc.), usa plantillas ya preparadas para extraer datos con un solo clic.
- Exportación fácil: envía tus datos directamente a Excel, Google Sheets, Airtable o Notion, sin pasos extra.
- Exportación gratuita de datos: descarga tus resultados en CSV o JSON, completamente gratis.
Thunderbit cuenta con la confianza de más de 100.000 usuarios en todo el mundo, desde equipos de ventas hasta operadores de e-commerce y profesionales inmobiliarios.
Prueba gratis Thunderbit AI Web Scraper
Thunderbit frente a los rastreadores web tradicionales
Veamos cómo se compara Thunderbit con el enfoque de la vieja escuela:
| Función | Thunderbit | Rastreadores tradicionales |
|---|---|---|
| Tiempo de configuración | 2 clics (la IA se encarga de la configuración) | Horas/días (configuración manual, código) |
| Conocimientos técnicos necesarios | Ninguno (instrucciones en inglés sencillo) | Altos (programación, selectores, scripts) |
| Flexibilidad | Funciona en cualquier sitio y se adapta a los cambios | Se rompe con los cambios de diseño |
| Raspado de subpáginas | Integrado, sin configuración adicional | Requiere scripts manuales |
| Opciones de exportación | Excel, Sheets, Airtable, Notion, CSV, JSON | Normalmente solo CSV/JSON |
| Mantenimiento | La IA se adapta automáticamente | Correcciones manuales frecuentes |
Con Thunderbit, no necesitas ser desarrollador ni pasar horas ajustando configuraciones. Solo apunta, haz clic y deja que la IA haga el trabajo pesado (Thunderbit Blog).
Cómo empezar a usar rastreadores web con Thunderbit
¿Listo para probarlo? Así puedes empezar con Thunderbit en cuestión de minutos:
- Instala la extensión de Chrome de Thunderbit.
- Abre el sitio web que quieres rastrear.
- Haz clic en el icono de Thunderbit y pulsa “AI Suggest Fields”. La IA recomendará columnas según el contenido de la página.
- Ajusta los campos si hace falta y luego haz clic en “Scrape”. Thunderbit extraerá los datos, incluso de subpáginas si lo eliges.
- Exporta tus resultados a Excel, Google Sheets, Airtable, Notion o descárgalos como CSV/JSON.
Qué es el data scraping y cómo hacerlo en 2025 Get Started Free
Y eso es todo: sin scripts, sin programación, sin dolores de cabeza. Tanto si estás siguiendo precios, creando una lista de leads o agregando noticias, Thunderbit convierte la mayoría de las tareas cotidianas de rastreo web en algo que una persona sin conocimientos de desarrollo puede terminar en una sola tarde.
Conclusión: los rastreadores web son la clave para un acceso más inteligente a los datos
Los rastreadores web son los motores invisibles que impulsan nuestro mundo digital, haciendo que la información sea accesible, buscable y accionable para todos. Desde motores de búsqueda hasta equipos de ventas, pasando por e-commerce e inmobiliaria, los rastreadores se han convertido en herramientas esenciales para cualquiera que necesite datos fiables y actualizados.
Y gracias a herramientas modernas impulsadas por IA como Thunderbit, no necesitas ser programador para aprovechar su potencial. Con solo unos clics, cualquiera puede convertir la web en un recurso estructurado y accionable, impulsando decisiones más inteligentes y nuevas oportunidades.
¿Tienes curiosidad por ver qué pueden hacer los rastreadores web por tu negocio? Descarga Thunderbit y empieza hoy mismo a explorar los datos ocultos de la web. Para más consejos y análisis en profundidad, visita el blog de Thunderbit.
Prueba AI Web Scraper Get Started Free
Preguntas frecuentes
1. ¿Qué es exactamente un rastreador web?
Un rastreador web es un programa automatizado (a veces llamado spider o bot) que navega por internet de forma sistemática, visitando páginas web, siguiendo enlaces y recopilando información para indexarla o analizarla.
2. ¿En qué se diferencian los rastreadores web de los raspadores web?
Los rastreadores web están diseñados para descubrir y mapear grandes partes de la web, a menudo siguiendo enlaces de una página a otra. Los raspadores web, en cambio, se centran en extraer datos concretos de páginas específicas. Muchas herramientas modernas, como Thunderbit, combinan ambas funciones.
3. ¿Por qué son importantes los rastreadores web para las empresas?
Los rastreadores web permiten a las empresas acceder a información actualizada a gran escala, ya sea para supervisar precios de la competencia, agregar contenido o crear listas de leads. Apoyan la toma de decisiones en tiempo real y ayudan a las compañías a seguir siendo competitivas.
4. ¿Es legal usar rastreadores web?
El rastreo web suele ser legal cuando se hace de forma responsable y de acuerdo con los términos del servicio y las políticas de privacidad de un sitio web. Revisa siempre el archivo robots.txt del sitio y respeta las normativas de privacidad de datos.
5. ¿Cómo hace Thunderbit que el rastreo web sea más fácil?
Thunderbit usa IA para automatizar la configuración, la selección de campos y la extracción de datos. Con instrucciones en lenguaje natural y plantillas instantáneas, cualquiera puede rastrear y extraer datos de sitios web, sin necesidad de programar ni de tener conocimientos técnicos. Los datos se pueden exportar directamente a Excel, Google Sheets, Airtable o Notion para usarlos al instante.
Saber más




