Tu CRM solo vale lo que valen los datos que le metes. Y seamos claros: los datos más jugosos suelen estar en sitios web públicos, no en esas bases de datos de terceros carísimas que te venden “la solución” y luego vienen desactualizadas.
Los extractor web convierten ese caos de info online en hojas de cálculo bien limpias. Los buenos lo hacen en minutos y sin que tengas que ponerte a programar.
He usado estas herramientas en proyectos reales: montar listas de leads, seguir precios de la competencia, sacar catálogos de productos. Aquí van 12 que de verdad aguantaron el tirón, ordenadas según lo bien que rindieron en tareas de negocio de la vida real.
Por qué los extractores web son imprescindibles para las empresas
Hablemos sin rodeos: la web es la base de datos más grande del mundo (y también la más caótica). Y en 2026, las empresas que saben transformar ese desorden en insights son las que se ponen por delante. Según , las compañías guiadas por datos son un 5% más productivas y un 6% más rentables que sus pares. No es “un plus”: es ventaja competitiva de verdad.
Las herramientas de extracción web (a veces llamadas extractor de páginas web o soluciones de extracción de páginas web) son ese ingrediente secreto que muchos pasan por alto. Permiten a los equipos de ventas extraer datos de directorios públicos, redes sociales y webs corporativas para crear listas de prospectos súper segmentadas; adiós a comprar listados viejos o a rezar para que el becario no se canse a mitad del “copiar y pegar” (). Los equipos de marketing y ecommerce usan extractor web para vigilar precios de la competencia, controlar niveles de stock y comparar productos en tiempo real; John Lewis, por ejemplo, atribuye al web scraping un aumento del 4% en ventas solo por afinar la estrategia de precios ().
Pero no todo va de métricas. Los extractor web ahorran una barbaridad de tiempo (un usuario dijo haber ahorrado “cientos de horas” automatizando la recopilación de datos) y bajan los errores humanos (). Los equipos de operaciones ya montan scrapers para recopilar datos de forma continua, algo que antes habría tomado semanas incluso con un equipo de prácticas: recuperan horas que antes se iban en tareas repetitivas de copiar y pegar (). Y con extractores impulsados por IA, incluso gente no técnica puede convertir sitios web en datos estructurados listos para analizar ().
¿La idea clave? Si en 2026 no estás usando un extractor web, probablemente estás dejando insights (y dinero) encima de la mesa.
Cómo elegimos los 12 mejores extractores web
Con tantas herramientas de extracción web, ¿cómo eliges la que te conviene? Revisé un montón de opciones, pero solo 12 entraron en esta lista. Esto fue lo que más pesó:
- Facilidad de uso: ¿Puede arrancar rápido alguien no técnico sin escribir código? Priorizo herramientas no-code o low-code con interfaces intuitivas ().
- Capacidades de IA: Herramientas de nueva generación que usan IA para simplificar la extracción: detectar campos automáticamente, navegar por el sitio o dejarte describir lo que necesitas en lenguaje natural ().
- Automatización y programación: Los mejores extractor web funcionan en modo piloto automático. Elegí herramientas que permiten programar extracciones recurrentes o monitorizar sitios web ().
- Exportación e integraciones: ¿Puedes exportar fácil a Excel, Google Sheets, Airtable o Notion? Puntos extra si encaja bien en tus flujos de trabajo ().
- Escalabilidad y fiabilidad: Da igual si extraes una página o miles: estas herramientas tienen que aguantar. También miré reseñas de usuarios sobre estabilidad.
- Casos de uso orientados a negocio: Me centré en herramientas populares entre equipos de ventas, marketing, ecommerce y operaciones, no solo entre devs.
Algunas son novedades con IA; otras son clásicos del sector. Todas están pensadas para ayudarte a convertir la web en tu propia base de datos de negocio, sin dramas.
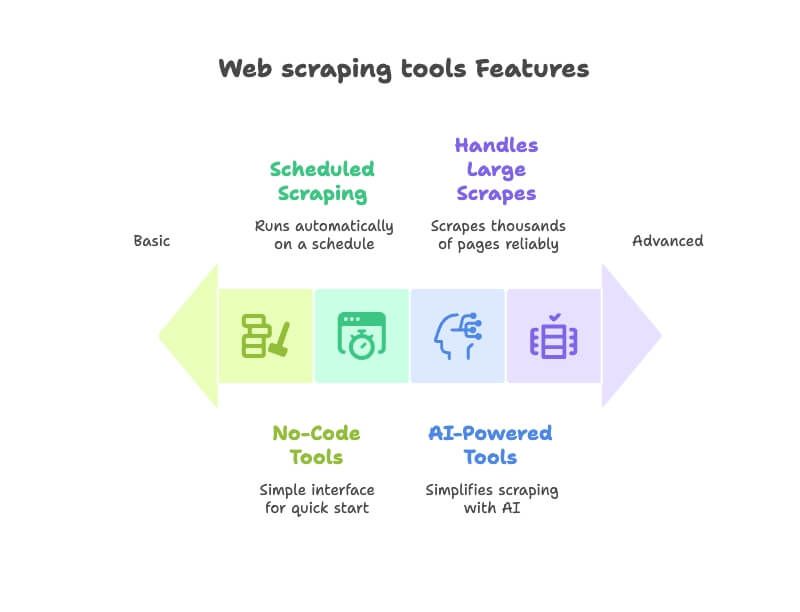
Comparativa rápida: herramientas de extracción web de un vistazo
Aquí tienes un resumen de las 12 herramientas que veremos, para compararlas en un momento:
| Herramienta | Automatización con IA | Facilidad de uso | Mejor caso de uso |
|---|---|---|---|
| Thunderbit | Sí: la IA sugiere campos y gestiona páginas automáticamente | Muy fácil (extensión de Chrome, sin código) | Extracción rápida de leads, precios, etc. para usuarios no técnicos que quieren resultados en minutos. |
| Octoparse | Limitada (basada en plantillas, sin IA) | Fácil para la mayoría (interfaz visual de arrastrar y soltar) | Flujos de extracción personalizados (con login, paginación) para analistas que quieren control sin programar. |
| Browse AI | Parcial: “robots” de apuntar y hacer clic | Fácil (no-code, en la nube) | Monitorización automatizada de datos (precios, listados, etc.) con programación, alertas e integraciones. |
| WebScraper.io | No (configuración manual) | Media (extensión con configuración de sitemaps) | Extracción visual en sitios multinivel para usuarios dispuestos a configurar pasos. |
| ScraperAPI | N/A (servicio API; gestiona proxies vía API) | Requiere programación (integración por API) | Extracción a gran escala para equipos técnicos: proxies y CAPTCHAs resueltos para scrapes masivos. |
| Data Miner | No | Muy fácil (extensión con plantillas de un clic) | Extracciones puntuales desde páginas (sobre todo tablas o listas) directamente a CSV/Excel. |
| Simplescraper | No (algunas funciones asistidas por IA) | Fácil (constructor de “recetas” con clics) | Extracción no-code con integraciones: ideal para enviar datos a Google Sheets, Airtable o API. |
| Instant Data Scraper | Sí: detecta tablas automáticamente | Muy fácil (clic y listo, sin configuración) | Extracción instantánea y gratuita de tablas/listas HTML para cualquiera (perfecto para capturas rápidas). |
| ScrapeStorm | Sí: la IA identifica elementos de la página | Fácil (interfaz visual; app multiplataforma) | Proyectos complejos o a gran escala sin programar, incluyendo rastreos programados. |
| Apify | Algo: “actors” preconstruidos disponibles | Media (interfaz web; código opcional) | Extracción y automatización escalables en la nube con scripts listos o personalizados. |
| ParseHub | No (sin scripts, pero configuración manual) | Fácil para lo básico (editor visual; app de escritorio) | Extracción de sitios dinámicos o complejos (contenido AJAX) con interfaz no-code. |
| OutWit Hub | No | Fácil (aplicación de escritorio con GUI) | Extracción sencilla sin conexión y archivado de contenido para proyectos pequeños. |
La mayoría ofrece plan gratuito o prueba y suscripciones por niveles. Aquí el foco está en capacidades y casos de uso, no en el precio.
Thunderbit: el extractor web con IA para todo el mundo

Arranquemos con Thunderbit: sí, es “mi criatura”, pero déjame contarte por qué importa. El sector está pasando de “móntate tu scraper” a “dile a la IA lo que necesitas”. Thunderbit es la primera herramienta que he visto (y ayudado a construir) que se siente de verdad como un asistente de datos con IA, no como otro “crawler” más.
Con , te olvidas de XPath, selectores CSS o expresiones regulares. Solo describes en lenguaje natural lo que quieres —por ejemplo, “saca el título, el autor y la fecha de esta página”— y la IA se encarga del resto (). Pulsas “AI Suggest Fields” y Thunderbit analiza la página, propone columnas y además gestiona subpáginas y paginación automáticamente ().
Y ojo, no es solo “capturar” datos. Thunderbit puede limpiar, transformar, categorizar e incluso traducir campos mientras extrae. ¿Quieres normalizar teléfonos, resumir descripciones o traducir nombres de producto? Le metes una instrucción rápida y la IA lo hace. Al terminar, exportas directo a Excel, Google Sheets, Airtable o Notion ().
Lo que más diferencia a Thunderbit es el cero configuración y cero curva de aprendizaje. Es una extensión de Chrome, así que en segundos estás dentro. Sin plugins raros, sin ajustes eternos, sin jerga técnica. Por eso se ha vuelto favorita de equipos de ventas, marketing y operaciones que necesitan resultados ya (). El plan gratuito te deja probar el flujo completo, y los planes de pago suelen ser razonables (para muchos equipos, “menos que el presupuesto mensual de café”).
Si quieres sentir cómo es la extracción web con IA, y pruébala. Igual tus días de copiar y pegar tienen fecha de caducidad.
Octoparse: extractor web visual para flujos personalizados
Octoparse es un clásico del scraping visual. Es una app de escritorio con una interfaz de apuntar y hacer clic: tú interactúas con la web, marcas los datos y Octoparse monta el flujo por detrás (). Permite gestionar inicios de sesión, configurar paginación e incluso automatizar envíos de formularios, todo sin escribir una línea de código.
Uno de sus puntos fuertes es su biblioteca de más de 500 plantillas para sitios populares (Amazon, Twitter, LinkedIn, etc.), así que muchas veces es cargar plantilla y empezar a extraer (). Para webs más peleonas, puedes pasar a modo manual y configurar cada paso de forma visual. Soporta contenido que aparece tras clics o scroll, y puede usar proxies y resolver CAPTCHAs en trabajos más duros. También tiene opción en la nube para programar y ejecutar extracciones a escala.
¿Lo menos bonito? Tiene su curva de aprendizaje, sobre todo cuando te metes en escenarios avanzados. Aun así, para no programadores y analistas que quieren un flujo de extracción a medida sin código, Octoparse es una opción muy sólida ().
Browse AI: extracción automatizada con robots preconfigurados
Browse AI va al grano: “entrenas” un robot señalando y haciendo clic en los datos que quieres, y aprende a extraerlos en páginas similares (). Es no-code y funciona en la nube, así que te olvidas de scripts y servidores.
Lo que más destaca en Browse AI es la automatización y la monitorización. Puedes programar robots para que corran cada X tiempo y recibir alertas cuando cambien los datos (por ejemplo, si un competidor baja el precio o aparece una nueva oferta de empleo). También tienen una biblioteca de robots ya hechos para tareas típicas, así que muchas veces arrancas con algo listo y lo ajustas ().
Se integra con miles de apps vía Zapier y Make, y exporta a Google Sheets o mediante API/webhooks (). Es ideal para monitorización continua y recopilación recurrente, sobre todo si quieres alertas e integraciones sin tocar nada.
WebScraper.io: extractor de páginas web desde el navegador

WebScraper.io (muchas veces llamado simplemente “Web Scraper”) es una extensión de navegador que te deja crear “sitemaps”: planes visuales de cómo navegar por un sitio y qué elementos extraer (). Defines selectores para los datos y los enlaces a seguir (por ejemplo, “haz clic en siguiente para paginar” o “visita cada ficha de producto para detalles”).
Tiene su curva, pero no programas: seleccionas elementos y defines acciones de extracción. Soporta navegación multinivel, paginación e incluso scroll infinito (aunque esos pasos los tienes que indicar tú). Es flexible y corre en el navegador, así que puedes extraer sitios con login iniciando sesión tú mismo.
WebScraper.io va genial para analistas “ciudadanos” que entienden la estructura de las páginas y quieren una herramienta gratuita y flexible. Es un caballo de batalla si no te importa montar tus propios sitemaps.
ScraperAPI: extractor web basado en API para desarrolladores y equipos
No todos los equipos quieren una interfaz de clics; a veces necesitas una solución backend para mandar datos web directo a tus apps o bases de datos. ScraperAPI es un extractor web API-first: le pasas una URL y te devuelve el HTML bruto o los datos extraídos, encargándose de lo pesado (proxies, rotación geográfica de IP, navegadores headless y CAPTCHAs) ().
ScraperAPI mantiene un pool de más de 40 millones de proxies en más de 50 países y procesa 36.000 millones de solicitudes al mes (). Es ideal para extracción automatizada a gran escala donde la fiabilidad y evitar bloqueos es lo número uno. Necesitas saber programar, pero si estás montando pipelines de datos o integrando scraping en tu producto, es una opción top.
Data Miner: extensión de Chrome para extraer datos rápido

Data Miner es una extensión de Chrome pensada para gente de negocio e investigadores que necesitan datos rápido. Ofrece una experiencia de apuntar y hacer clic y una biblioteca de “recetas” prehechas para patrones típicos como tablas, listas o sitios concretos ().
Instalas la extensión, entras a la página objetivo y haces clic en el icono de Data Miner. Eliges una receta o creas la tuya seleccionando elementos. Va de lujo para tareas puntuales o necesidades rápidas: por ejemplo, un comercial sacando leads de un directorio online o alguien de ecommerce copiando precios de la competencia.
Es simple, vive en el navegador y encaja perfecto para extracción interactiva bajo demanda.
Simplescraper: extractor web no-code para resultados inmediatos

Simplescraper hace honor a su nombre. Es una extensión de Chrome no-code (y también app web) que te deja seleccionar datos visualmente para crear una “receta” de extracción (). Puedes seguir enlaces para extraer subpáginas, gestionar paginación e incluso convertir tu extracción en un endpoint de API con un clic.
Donde realmente brilla es en las integraciones: puedes mandar datos directo a Google Sheets, Airtable o herramientas como Zapier (). También ofrece scraping en la nube y programación para trabajos recurrentes, además de “AI Enhance” para limpiar o analizar datos con GPT.
Si buscas resultados rápidos e integraciones sin lío, Simplescraper es como una navaja suiza del scraping ligero.
Instant Data Scraper: extracción rápida para tablas y listas
A veces solo quieres los datos ya, sin configurar nada. Ahí entra Instant Data Scraper (IDS). Es una extensión gratuita de Chrome conocida por su extracción en un clic de datos tabulares (). La activas y detecta automáticamente tablas o listas. Incluso gestiona paginación y scroll infinito avanzando por todas las páginas.
IDS es 100% gratis: sin registro, sin código, sin esperas. Perfecta para necesidades urgentes o casuales: un comercial sacando una lista rápida de leads o un estudiante extrayendo tablas de Wikipedia. Si detecta tus datos, los tienes en segundos.
ScrapeStorm: extractor web en la nube con ayuda de IA
ScrapeStorm es una herramienta de web scraping con IA que mezcla interfaz visual con algoritmos potentes (). Metes una URL y su IA identifica automáticamente campos de datos: listas, tablas, botones de siguiente página y más.
Funciona en Windows, Mac y Linux y ofrece scraping tanto en escritorio como en la nube. Puedes programar tareas, correr varios trabajos en paralelo y exportar a Excel, CSV, JSON o incluso subir a una base de datos (). Es popular en ecommerce e investigación de mercado, y también puede extraer datos de imágenes o PDFs con IA.
Si necesitas un asistente inteligente para proyectos complejos o a gran escala, vale la pena tenerlo en el radar.
Apify: marketplace de extractores y plataforma de automatización

Apify no es solo un scraper: es una plataforma de scraping y automatización. Ejecutas “actors”, que son scripts para scraping o automatización del navegador. Lo mejor es su marketplace de actors ya listos para tareas comunes (). ¿Necesitas extraer todas las reseñas de un ecommerce? Lo más probable es que ya haya un actor hecho.
Para desarrolladores, permite escribir scrapers en Node.js o Python y desplegarlos en la nube. Es escalable, automatizable e integrable por API. Encaja mejor con usuarios avanzados y organizaciones que tratan los datos web como un activo estratégico: scraping continuo a gran escala o integración en pipelines de datos.
ParseHub: extractor visual para sitios complejos

ParseHub es una app de escritorio (con opciones en la nube) conocida por manejar sitios dinámicos y complejos. Navegas por el sitio en una interfaz tipo navegador, haces clic en los datos y ParseHub construye el extractor (). Soporta lógica condicional, extracción anidada, contenido AJAX y más.
Suele ser la opción cuando otras herramientas se quedan cortas con un sitio. La usan investigadores, analistas y pequeñas empresas para webs “difíciles”. Tiene curva de aprendizaje, pero si tienes un sitio complejo y no quieres programar, es una alternativa muy potente.
OutWit Hub: extractor de escritorio para archivado de contenido

OutWit Hub es más “old school”, pero es una aplicación de escritorio muy apañada para capturar distintos tipos de contenido (enlaces, imágenes, correos, etc.) y organizarlo (). Funciona como un navegador mezclado con hoja de cálculo: entras a una página y puede extraer tablas, listas, imágenes y más.
Es especialmente útil para archivado de contenido o investigación: por ejemplo, sacar todos los posts de un foro o bajar una colección de archivos. Al ser de escritorio, corre en local y mantienes tus datos más privados. Ideal para tareas pequeñas o medianas donde quieres una interfaz directa y control.
¿Qué extractor web es mejor para ti?
Doce herramientas, mil escenarios. ¿Con cuál te quedas? Aquí va mi chuleta rápida:
-
Para principiantes totales o tareas puntuales rápidas:
Prueba Instant Data Scraper para tablas y listas básicas (gratis e inmediato). Data Miner también es muy amigable y trae más plantillas si sueles extraer páginas parecidas.
-
Para usuarios no técnicos que necesitan extracción recurrente o integraciones:
Thunderbit ofrece el flujo más sencillo gracias a su enfoque con IA: perfecto para equipos de negocio que quieren resultados rápidos y frecuentes. Browse AI es ideal para monitorización continua y alertas. Simplescraper encaja si quieres que los datos fluyan a Google Sheets o a una app interna mediante API.
-
Para sitios complejos o flujos personalizados sin programar:
Elige un extractor visual como Octoparse o ParseHub. Octoparse es fácil y trae muchas plantillas. ParseHub maneja sitios dinámicos muy complejos y te da control fino. WebScraper.io también es excelente si no te importa configurar tus propios sitemaps.
-
Para desarrolladores o data engineers que necesitan escala:
ScraperAPI está hecho para integrar scraping en tu software o correr proyectos grandes. Apify es perfecto si necesitas una plataforma escalable con marketplace de scripts listos o personalizados.
-
Para extracción de contenido o uso sin conexión:
OutWit Hub es una buena elección para recopilar y archivar contenido de forma sistemática, sobre todo si prefieres una herramienta de escritorio por privacidad o control.
En la práctica, muchos equipos usan varias herramientas según el curro. Puedes arrancar con Instant Data Scraper para algo simple, pasar a Thunderbit u Octoparse para un proyecto más completo, y tirar de ScraperAPI o Apify cuando toque industrializar el proceso. La buena noticia: casi todas tienen plan gratuito o prueba, así que puedes ir probando sin casarte.
Conclusión: el futuro de la extracción web para equipos de negocio
Las herramientas de extracción web han pegado un salto enorme. En 2026 ya son totalmente mainstream. ¿La gran tendencia? El web scraping cada vez es más fácil, más automatizado y más integrado en el trabajo del día a día (). Con scrapers impulsados por IA, incluso sitios dinámicos y complejos se pueden domar sin habilidades especializadas. Como dijo un data engineer: “Cuando llegaron las herramientas de web scraping con IA, pude completar tareas mucho más rápido y a mayor escala... con IA, la [limpieza de datos] ya viene incluida en mi flujo de trabajo”.
Otro cambio fuerte es que se están difuminando las fronteras entre extracción, monitorización y automatización. Herramientas como Browse AI y Thunderbit no solo extraen datos: los mantienen al día e incluso pueden ejecutar acciones (como rellenar formularios o disparar alertas). El crecimiento es real: una plataforma importante vio cómo sus usuarios activos mensuales subían más de un 140% en un año (). Empresas de todos los tamaños están entendiendo que acceder a datos públicos de la web (de forma ética y legal) es clave para competir.
Para equipos de negocio, el mensaje es empoderamiento. Ya no tienes que esperar semanas a un desarrollador ni decidir “a ojo”. Las herramientas de esta lista ponen el poder de los datos web en tus manos, con interfaces y funciones pensadas para casos reales en ventas, marketing, operaciones y más. Y por cómo avanza el sector, veremos interfaces aún más amigables, IA más lista e integraciones más profundas con plataformas de BI y analítica.
Eso sí: respeta los términos de servicio y las reglas de robots.txt, y asegúrate de cumplir las leyes de privacidad. El scraping ético es clave para que esto sea sostenible.
Así que, tanto si empiezas con una extensión gratuita como si despliegas una flota de scraping a nivel enterprise, nunca ha sido mejor momento para convertir la información de la web en decisiones accionables. La revolución de los extractores web ya está aquí: elige una herramienta, pruébala y desbloquea el valor que está a simple vista. Tu futuro basado en datos está a un clic.
Preguntas frecuentes
1. ¿Qué es un extractor web y por qué es importante para las empresas?
Un extractor web es una herramienta que recopila automáticamente datos estructurados desde sitios web. Es importante porque permite convertir información online desordenada en insights accionables: mejora la productividad, impulsa la rentabilidad y elimina la recopilación manual.
2. ¿Quién puede usar extractores web? ¿Necesito conocimientos técnicos?
En muchos extractores modernos no necesitas conocimientos técnicos. Herramientas como Thunderbit, Browse AI e Instant Data Scraper están pensadas para usuarios no técnicos, con interfaces intuitivas, automatización con IA y flujos no-code.
3. ¿Cómo se benefician ventas, marketing y operaciones de los extractores web?
Ventas puede crear listas de leads desde directorios online; marketing puede vigilar precios de la competencia; operaciones puede automatizar procesos de recopilación de datos. Estas herramientas ahorran tiempo, reducen errores y aportan insights frescos y fiables para decisiones estratégicas.
4. ¿En qué debo fijarme al elegir una herramienta de extracción web?
Busca facilidad de uso, capacidades de IA, automatización/programación, integraciones con herramientas como Google Sheets o Airtable, escalabilidad y que encaje con tu caso de uso (leads, monitorización de precios, archivado de contenido, etc.).
5. ¿Hay extractores web gratuitos o de bajo coste?
Sí. Muchos ofrecen planes gratuitos o precios accesibles. Instant Data Scraper es totalmente gratis para necesidades básicas, y herramientas como Thunderbit, Simplescraper y Data Miner tienen planes gratuitos generosos con opciones de upgrade.
¿Quieres aprender más sobre extracción web, scraping con IA o cómo convertir sitios web en la próxima ventaja competitiva de tu equipo? Visita el para más guías, consejos e historias reales desde la primera línea de la automatización de datos.