Una búsqueda en GitHub de "tiktok scraper" devuelve . Aproximadamente no ha recibido commits en más de un año, y al menos .
Si alguna vez clonaste un repositorio popular de scraper de TikTok, te pasaste una hora peleando con dependencias y al final no obtuviste ningún resultado, no eres el único. El scraper de TikTok con más estrellas en GitHub, drawrowfly/tiktok-scraper, todavía tiene más de 5.000 estrellas. Sin embargo, su registro de incidencias está lleno de hilos como y , ambos reportando cero salida. En Thunderbit he seguido durante meses el estado de los repositorios de scraping de TikTok, y el patrón es clarísimo: estas herramientas se rompen rápido y la mayoría nunca se arregla. Este artículo es la guía práctica de supervivencia que me habría gustado tener cuando empecé a evaluar estos repositorios. Veremos qué sigue vivo, qué está muerto, qué hacer en su lugar y cómo dejar de perder horas con código que dejó de funcionar antes de que lo encontraras.
Por qué la mayoría de los scrapers de TikTok en GitHub se rompen (y siguen rompiéndose)
TikTok no es un objetivo de scraping típico. Su superficie web cambia todo el tiempo. A diferencia de una página de producto de comercio electrónico estática o un directorio, TikTok rota endpoints, actualiza la huella anti-bot, cambia la forma de renderizar páginas e introduce nuevos requisitos de sesión y tokens, a veces en cuestión de semanas desde el último cambio.
Los mantenedores de código abierto son voluntarios. Cuando TikTok publica una actualización que rompe la ruta de solicitudes del scraper, el repositorio puede quedarse roto durante días, semanas o para siempre. No es una crítica a los mantenedores: es un choque estructural entre una plataforma que cambia a gran velocidad, está muy bien financiada y desarrolladores no remunerados que tienen otro trabajo.
Incluso los mejores repositorios de scraper de TikTok viven en una rueda de arreglar y romper. Si vas a usar uno, necesitas una estrategia para evaluarlo, depurarlo y tener un plan de respaldo.
Defensas anti-bot de TikTok: contra qué estás compitiendo
- Limitación de velocidad. Los de TikTok describen explícitamente cuotas de solicitudes incluso para integraciones aprobadas. Los scrapers no oficiales llegan a esos límites mucho más rápido.
- Bloqueo por cookies y sesión. Repositorios modernos como requieren un
ms_token; repositorios antiguos como muestrantt_webid_v2en sus ejemplos; documentamsToken,ttwid,X-BogusyA_Bogus. TikTok comprueba si tu solicitud parece venir de una sesión de navegación real. - Huella digital del navegador. La explica por qué los sitios comparan encabezados, cookies, firmas TLS y rasgos del navegador expuestos por JavaScript con tráfico de usuarios reales. Su cubre Canvas, WebGL, WebRTC, fuentes y señales de ejecución. El fingerprinting es como si TikTok revisara el DNI de tu navegador: si el navegador, las cookies, el tiempo y la firma de red no cuadran, la solicitud parece falsa incluso antes de devolver contenido.
- Detección de comportamiento. Hilos de sobre scraping de TikTok mencionan con frecuencia que las sesiones nuevas de Playwright activan CAPTCHA. Publicaciones de la comunidad de describen cada vez más una detección basada en el momento de las acciones y la calidad de la interacción, no solo en la reutilización de IP.
- Parámetros de solicitud cifrados o firmados. Evil0ctal documenta
X-BogusyA_Bogus; los antiguos gists de la comunidad giran en torno a la firma de URLs y la generación de tokens. Cada vez más, TikTok espera que las solicitudes lleguen con los mismos "sellos" que llevaría su propio tráfico de navegador o app. - Flujos de CAPTCHA y verificación. La existencia de y de confirma que el CAPTCHA sigue formando parte de la superficie anti-bot.
Por qué los mantenedores de código abierto no alcanzan a ponerse al día
El ciclo siempre es el mismo. Un desarrollador construye un scraper de TikTok. Se vuelve viral en GitHub. TikTok lo parchea. El mantenedor lo arregla o sigue adelante.
Dos repositorios ilustran el patrón a la perfección:
- drawrowfly/tiktok-scraper todavía tiene 5.052 estrellas y 889 forks, pero su . Es el scraper de TikTok con la frase exacta más valorado en GitHub, y se lee como un artefacto histórico: mucha visibilidad, mucha confianza, cero mantenimiento actual.
- davidteather/TikTok-Api muestra . Su muestra mantenimiento real en abril de 2025, julio de 2025, octubre de 2025 y abril de 2026, incluidos arreglos para rastreo de videos de usuarios y nuevos controles de proxy/sesión. Pero incluso este proyecto más sano advierte abiertamente que TikTok bloquea solicitudes y que los usuarios quizá necesiten proxies, Playwright y lógica personalizada de sesión.
El patrón es simple:
- Un repositorio de scraper de TikTok obsoleto probablemente está muerto.
- Un repositorio activo de scraper de TikTok probablemente sigue siendo frágil.
- La única diferencia real es si todavía hay alguien disponible para parchear la rotura este mes.
Lista de verificación de 60 segundos: cómo evaluar cualquier scraper de TikTok en GitHub
Antes de clonar nada, ejecuta esta lista. Toma menos de un minuto y te ahorra horas de frustración.
| Señal | 🟢 Saludable | 🟡 Riesgoso | 🔴 Muerto |
|---|---|---|---|
| Último commit relevante | Hace menos de 3 meses | Hace 3–12 meses | Hace 12+ meses |
| Número de incidencias abiertas | Bajo, las incidencias recientes reciben respuesta | Acumulación creciente con algo de actividad del mantenedor | Muchos informes sin respuesta de "roto/bloqueado/no funciona" |
| Quejas recientes de usuarios | Principalmente preguntas de configuración | Mezcla de configuración + fallos | "cero salida", "403", "¿sigue funcionando?" repetidos |
| Modelo actual de auth/sesión | Flujo de sesión/cookie documentado | Basado en tokens pero documentado | Depende de endpoints web antiguos sin guía actual de autenticación |
| Superficie de instalación | Configuración reproducible y probada | Algunos pasos manuales | Dependencias viejas, sin notas modernas de instalación |
| CI/pruebas | Existen pruebas y están al día | Existen pruebas, pero la cobertura no está clara | No hay pruebas o las acciones están obsoletas |
| Ajuste del alcance de datos | Coincide con tu caso real | Solo cubre parte del caso | Resuelve un problema distinto por completo |
Cómo comprobar cada señal en menos de 60 segundos
- Fecha del último commit: Mira el encabezado del repositorio en GitHub. Si dice "last pushed 2 years ago", ya está, descártalo.
- Incidencias abiertas: Haz clic en la pestaña Issues. Revisa los títulos más recientes. Busca
not working,403,blocked,captchaozero output. - Quejas de usuarios: Si las 5 incidencias abiertas principales son variaciones de "esto ya no funciona", ya tienes tu respuesta.
- Modelo de auth/sesión: Abre el README. Busca orientación actual como
ms_token, configuración de Playwright o notas sobre proxies. Si el README menciona endpoints de 2023, sigue de largo. - Superficie de instalación: Comprueba si hay archivo de dependencias, soporte para Docker o instrucciones claras de configuración. Si el README dice "npm install" y la última versión de Node probada fue 14, espera problemas.
- CI/pruebas: Revisa la pestaña Actions. Si las pruebas fallan o no existen, la rotura es una apuesta.
- Ajuste del alcance de datos: ¿El repositorio describe realmente los tipos de datos que necesitas (perfiles, metadatos de video, comentarios, hashtags)? Muchos solo descargan videos, no extraen datos estructurados.
Señales rojas que significan "aléjate"
- El repositorio está archivado.
- El README dice "no longer maintained".
- El último commit hace referencia a una versión de la API de TikTok de hace más de 2 años.
- Las incidencias están inundadas de reportes de "doesn't work" y el mantenedor no responde desde hace meses.
- El repositorio tiene muchas estrellas, pero pocos forks o pull requests recientes.
Consejo: busca en la pestaña Issues is:issue is:open "not working" o is:issue is:open "403". Si los resultados son abundantes y recientes, probablemente el repositorio esté roto.
Repositorios populares de scrapers de TikTok en GitHub: una revisión honesta del estado actual (2026)
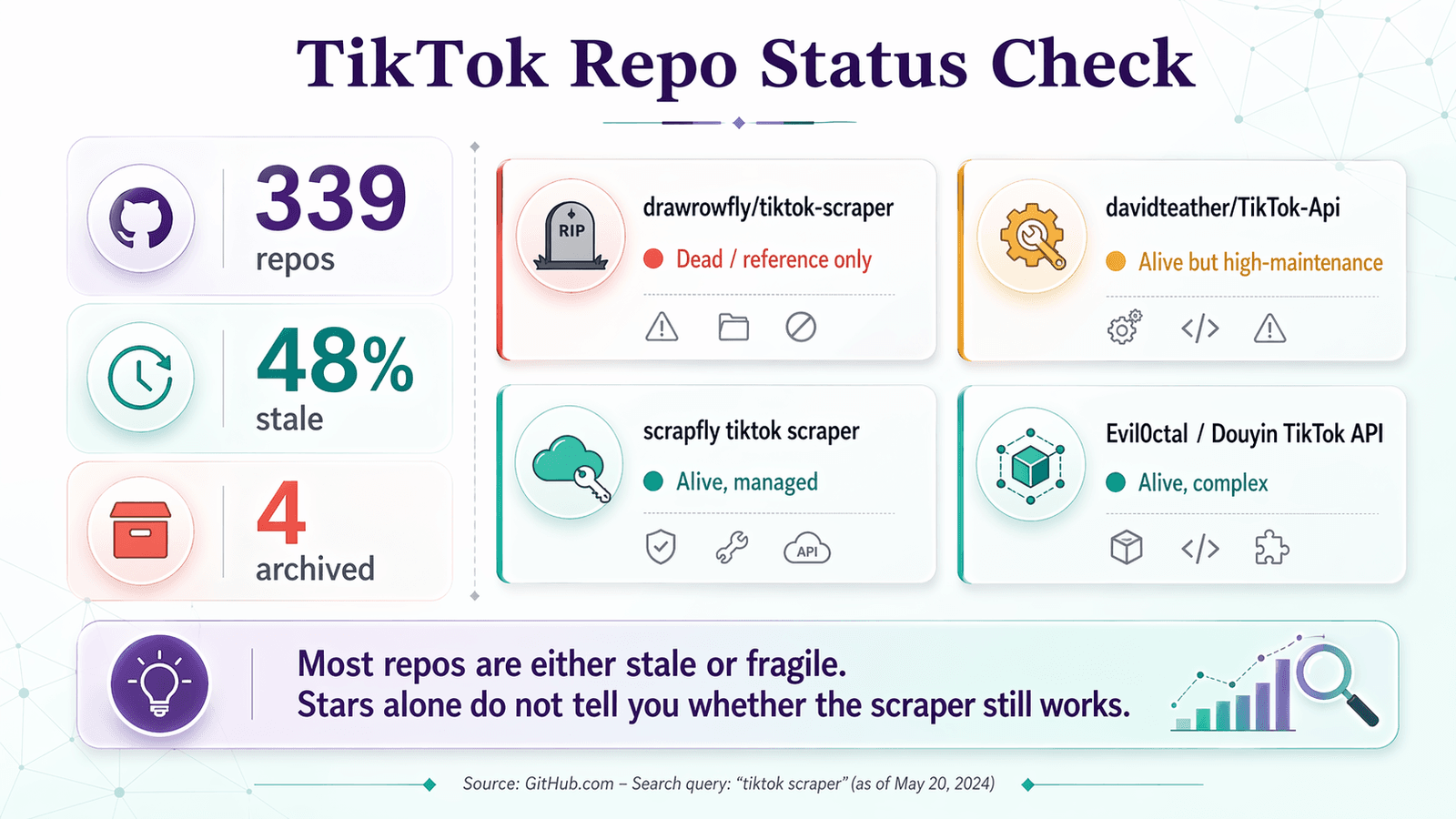
Aquí tienes la lista de verificación de salud del repositorio aplicada a los repositorios que de verdad encontrarás al buscar "tiktok scraper" en GitHub:
| Repositorio | Último commit | Estrellas | Incidencias abiertas | Veredicto | Nota |
|---|---|---|---|---|---|
| drawrowfly/tiktok-scraper | 2023-05-19 | 5,052 | 58 | 🔴 Muerto / solo como referencia | Sigue siendo famoso, pero demasiado obsoleto para uso en producción en 2026 |
| davidteather/TikTok-Api | 2026-04-01 | 6,301 | 134 | 🟡 Vivo pero requiere mucho mantenimiento | La opción OSS más sólida; espera Playwright, tokens y, a menudo, proxies |
| scrapfly/scrapfly-scrapers/tiktok-scraper | 2026-04-21 | 938 (padre) | ~0 (monorepo) | 🟡 Vivo, pero no es OSS puro | Actual y útil, pero requiere una clave de API de ScrapFly |
| Evil0ctal/Douyin_TikTok_Download_API | 2025-10-12 | 17,397 | 135 | 🟡 Vivo, amplio, complejo | Proyecto multicanal y con muchas funciones; más cercano a una plataforma para usuarios avanzados |
| naseif/tiktok-scraper | 2024-07-26 | 107 | 13 | 🟡 Riesgoso | Repositorio pequeño con quejas abiertas sobre información de usuario y flujos de hashtags |
| loewehancara1rmyv/Tiktok-scraper | 2026-01-12 | 4 | 0 | 🔴 Demasiado nuevo para confiar | Repositorio de demostración, no probado por la comunidad |
drawrowfly/tiktok-scraper
Durante años, este scraper/descargador en TypeScript fue la respuesta por defecto a "tiktok scraper github", y gestionaba feeds de usuarios, tendencias, hashtags y música. En 2026, conviene tratarlo como documentación histórica. El , y la cola de incidencias todavía contiene reportes sin resolver de y de 2023–2025. Si estás leyendo este artículo porque clonaste este repositorio y no obtuviste nada, estás en buena compañía.
davidteather/TikTok-Api
El envoltorio de datos de TikTok de código abierto más creíble que sigue vivo en 2026. Está activo, tiene y documenta explícitamente la configuración de Playwright, el uso asíncrono, el manejo de tokens, el soporte de proxies y funciones de recuperación de sesión. Pero no es una herramienta de "clonar y usar". Su propio README dice que EmptyResponseException normalmente significa que TikTok está bloqueando la solicitud, y el muestra problemas repetidos con ms_token, extracción rota de comentarios, KeyError: 'ItemModule' y fallos específicos de endpoints. Veredicto: vivo, útil, solo para desarrolladores y con mucho mantenimiento.
Otros repositorios destacados
- : actual y técnicamente relevante, pero el README exige una
SCRAPFLY_KEY. Es un ejemplo de código para una plataforma de scraping gestionada, no una herramienta gratuita e independiente. - : cubre TikTok y Douyin, documenta lógica de firmas (
X-Bogus,A_Bogus,msToken) y admite comentarios, seguidores, listas de reproducción y más. Es técnicamente exigente y cada vez más está vinculado a referencias de API de pago. El registro de incidencias muestra informes de errores continuos en 2026 sobre enlaces de video y endpoints de información de usuario. Vivo y con muchas funciones, pero complejo. - : más pequeño y con quejas abiertas. Riesgoso para producción.
- : 4 estrellas, 0 incidencias, demasiado nuevo para confiar. El artículo de Medium que lo promocionó no lo hizo de forma crítica.
API oficial de TikTok vs. scrapers de GitHub vs. herramientas no-code: un marco de decisión

La mayoría de los artículos de la competencia o bien ignoran las vías oficiales de acceso de TikTok o saltan directamente de "usa GitHub" a "compra nuestro servicio". Aquí va una comparación neutral de las tres rutas:
| Factor | TikTok Research API | Scrapers de GitHub | Herramientas no-code (p. ej., Thunderbit) |
|---|---|---|---|
| Barrera de acceso | Se requiere solicitud académica/empresarial; ~4 semanas para aprobación | Clonar el repo + configuración | Instalar extensión del navegador |
| Alcance de datos | Solo endpoints aprobados (cuentas, videos, comentarios, tiendas) | Amplio (perfiles, videos, comentarios, hashtags, tiendas) | Datos visibles de la página (perfiles, videos, interacción, hashtags) |
| Carga de mantenimiento | Baja (oficial y estable) | Alta (los repos se rompen cuando TikTok se actualiza) | Ninguna (la IA se adapta a cambios de diseño) |
| Riesgo de bloqueo | Ninguno (autorizado) | Alto | Bajo (basado en navegador, imita a un usuario real) |
| Coste | Gratis (si se aprueba) | Gratis (pero consume mucho tiempo) | Hay plan gratuito; planes de pago desde 15 $/mes |
| Requiere programar | Sí (Python/R) | Sí (Python/Node.js) | No |
| Ideal para | Investigadores, académicos, organizaciones aprobadas | Desarrolladores cómodos con el mantenimiento | Equipos de marketing, ventas, operaciones y personas sin perfil técnico |
Cuándo tiene sentido la TikTok Research API
La de TikTok es la vía oficial más limpia si cumples los requisitos. Los investigadores elegibles en pueden solicitar acceso para estudiar contenido público y datos de cuentas. Las categorías de datos disponibles incluyen cuentas, seguidores/seguidos, videos con me gusta, videos fijados, videos republicados, contenido, comentarios y tiendas. El expone campos como video_description, view_count, like_count, comment_count, share_count y campos a nivel de comentario como text, reply_count y create_time.
La desventaja: la elegibilidad está limitada a instituciones académicas e investigadores independientes o sin fines de lucro en regiones específicas, además de . Si eres un equipo de growth o una agencia que necesita datos operativos rápidos, esta no es tu vía.
TikTok también ofrece una para anuncios y datos de contenido publicitario, útil para investigación de transparencia, pero no para scraping general.
Cuándo sigue teniendo sentido un scraper de GitHub
Los scrapers de GitHub siguen teniendo sentido para desarrolladores que necesitan acceso no oficial a datos públicos más allá del filtro de aprobación de la API oficial y están dispuestos a mantener la pila. Eso incluye casos de uso como extraer cuadrículas visibles de perfiles, hashtags, comentarios, listas de reproducción o metadatos de video en una canalización personalizada donde hacer un fork del repositorio y parchearlo sea aceptable.
La salvedad honesta: esto no es una configuración de una sola vez. Incluso el repositorio más fiable de 2026, , sigue diciéndoles a los usuarios que quizá necesiten Playwright, cookies/tokens, proxies y fábricas personalizadas de página/sesión.
Cuándo tiene sentido una herramienta no-code como Thunderbit
¿No eres desarrollador? ¿O sí lo eres, pero ya estás cansado del ciclo de romper y arreglar? Una herramienta de IA basada en navegador es la forma más rápida de obtener datos estructurados de TikTok.
Creamos como un Raspador Web IA que funciona como extensión de Chrome. En TikTok, lee cualquier página visible (perfil, video, hashtag, resultados de búsqueda), sugiere columnas mediante "AI Suggest Fields" y te permite hacer clic en "Scrape" para extraer datos estructurados. La documenta campos como fecha de publicación, duración del video, me gusta, compartidos, guardados, comentarios, vistas y hashtags. La muestra cómo recopilar miniaturas de publicaciones, URLs, descripciones, usuarios creadores y señales de interacción desde páginas de perfil. La cubre URL del video, nombre de usuario del creador, descripción, hora de publicación, vistas, me gusta, comentarios, compartidos, sonido/audio y URL de la imagen de portada.
El scraping de subpáginas te permite visitar cada página de video desde un listado de perfil y enriquecer la tabla con métricas de interacción, descripciones y hashtags, algo muy útil para marketers que construyen bases de datos de influencers o auditan contenido de la competencia.
Sin mantenimiento, sin pelear con instalaciones, sin configuración anti-bloqueo. La IA se adapta automáticamente a los cambios de diseño. La exportación es gratuita a Google Sheets, Excel, Airtable, Notion, CSV o JSON.
Si has perdido horas con repositorios rotos de GitHub, esta es una alternativa legítima, no un discurso comercial forzado.
Triaje de instalación: cómo arreglar los 5 fallos de configuración más comunes en scrapers de TikTok de GitHub
Los fallos de instalación son el tercer punto de dolor más mencionado en los foros de scraping de TikTok, y ninguna guía importante ayuda de verdad a resolverlos. Esto es lo que suele fallar.
Conflictos de versión de Node.js
Problema: Muchos repos antiguos de scrapers de TikTok, especialmente drawrowfly/tiktok-scraper, se construyeron para Node.js 14–16. Si usas Node 20+, npm install puede fallar en silencio o producir binarios incompatibles.
Solución: Usa nvm (Node Version Manager) para instalar y cambiar a la versión correcta:
1nvm install 16
2nvm use 16
3npm installSi el repositorio no especifica una versión de Node, revisa el campo engines en package.json o la configuración de CI.
Problemas de dependencias en Python y configuración de Playwright
Problema: requiere y Playwright con binarios de navegador específicos. Los usuarios ven errores como "browser not found" o conflictos de dependencias.
Solución: Usa siempre un entorno virtual y luego instala explícitamente los navegadores de Playwright:
1python -m venv .venv
2source .venv/bin/activate # En Windows: .venv\Scripts\activate
3pip install TikTokApi
4python -m playwright installSi playwright install falla, revisa el gestor de paquetes de tu sistema por dependencias faltantes (por ejemplo, libnss3 en Ubuntu).
Errores de permisos en Linux/Ubuntu
Problema: Ejecutar sudo pip install corrompe el entorno de Python del sistema y genera problemas en cascada con las dependencias.
Solución: Nunca uses sudo pip install. Crea siempre primero un entorno virtual:
1python3 -m venv .venv
2source .venv/bin/activate
3pip install -r requirements.txtAsí aíslas las dependencias del scraper de tu Python del sistema.
Problemas de ruta y codificación en Windows
Problema: CMD de Windows tiene problemas de codificación y límites de longitud de rutas que rompen instalaciones de scrapers, especialmente cuando Playwright descarga binarios de navegador en directorios muy anidados.
Solución: Usa WSL (Windows Subsystem for Linux) o Git Bash en lugar de CMD. WSL te da un entorno Linux completo dentro de Windows:
1wsl --install
2# Luego abre una terminal de WSL y sigue los pasos de configuración de LinuxEl atajo con Docker: omitir por completo los problemas de dependencias
Problema: Todo lo anterior.
Solución: Si te sientes cómodo con Docker, containeriza el entorno del scraper. Un Dockerfile básico para un scraper de TikTok basado en Python se ve así:
1FROM python:3.11-slim
2RUN apt-get update && apt-get install -y libnss3 libatk-bridge2.0-0 libdrm2 libxcomposite1 libxdamage1 libxrandr2 libgbm1 libasound2
3RUN pip install TikTokApi playwright && python -m playwright install --with-deps chromium
4WORKDIR /app
5COPY . .
6CMD ["python", "scrape.py"]Esto garantiza un entorno reproducible sin importar el sistema operativo anfitrión. Si el scraper funciona en Docker, cualquier fallo fuera de Docker es un problema del entorno, no del código.
Flujo de solución de problemas:
- ¿El repositorio ejecuta con éxito su propio ejemplo? → Si no, revisa la versión de ejecución.
- ¿La versión de ejecución es correcta? → Comprueba la instalación del navegador/Playwright.
- ¿El navegador está instalado? → Revisa tokens/cookies.
- ¿Los tokens/cookies son válidos? → Comprueba si TikTok está bloqueando la sesión.
- ¿Todo lo anterior falla? → Asume que el repositorio está roto, no que el usuario cometió un error. Cambia de herramienta.
Buenas prácticas anti-baneo para scraping de TikTok (sin pagar por proxies)
Los usuarios de foros se quejan una y otra vez de bloqueos y detección: "te terminan baneando las cuentas, lo que además supone un gasto" y "sin usar Apify o APIs de pago caras". Aquí tienes soluciones prácticas y gratuitas que no requieren una suscripción de proxy de pago.

| Práctica | Dificultad | Coste | Eficacia |
|---|---|---|---|
| Retrasos aleatorios entre solicitudes (jitter de 2–8 s) | Fácil | Gratis | Moderada |
| Rotación de sesión/cookies | Media | Gratis | Moderada |
| Extraer solo páginas públicas sin iniciar sesión | Fácil | Gratis | Moderada |
Respetar robots.txt + encabezados de limitación de velocidad | Fácil | Gratis | Base |
| Aleatorización de huella digital del navegador sin interfaz (Playwright) | Media | Gratis | Alta |
| Usar endpoints de API móvil de TikTok (menor detección) | Difícil | Gratis | Alta |
| Rotación de proxies residenciales | Media | 20–100 $/mes | Alta |
Técnicas gratuitas que sí ayudan
Retrasos aleatorios entre solicitudes. No envíes solicitudes en un bucle cerrado. Añade un jitter aleatorio de 2–8 segundos entre solicitudes. Es lo más fácil que puedes hacer:
1import time, random
2time.sleep(random.uniform(2, 8))Reutilización de sesión y cookies. No crees una sesión totalmente nueva para cada solicitud. Reutiliza cookies y estado de sesión en un lote de solicitudes y luego rota. Por eso los repositorios modernos piden ms_token en lugar de prometer scraping sin estado.
Extraer solo páginas públicas sin iniciar sesión. que no admite rutas autenticadas por usuario y solo funciona con datos visibles al cerrar sesión. El scraping sin sesión tiene un perfil de detección más bajo que las sesiones autenticadas.
Respeta robots.txt. El bloquea por completo a muchos agentes y solo permite un conjunto limitado de rutas públicas para rastreo general. No es una luz verde para hacer scraping agresivo, pero respetarlo reduce la posibilidad de un bloqueo inmediato de IP.
Técnicas intermedias para mayores tasas de éxito
Aleatorización de huella digital del navegador sin interfaz. Si usas Playwright, aleatoriza el tamaño de la ventana, la cadena de user-agent, la zona horaria y la configuración regional en cada sesión. Así tu scraper parece un usuario real diferente cada vez, en vez del mismo bot con una IP nueva.
Usar endpoints de la API móvil de TikTok. Algunos miembros de la comunidad informan tasas de detección más bajas cuando apuntan a endpoints de estilo móvil en lugar del frontend web. Es más difícil de implementar y menos documentado, pero es una técnica real para usuarios avanzados.
Cuándo sí necesitas un proxy (y opciones asequibles)
A escala, las técnicas gratuitas no bastan. La rotación de proxies residenciales es el enfoque estándar para scraping de TikTok a gran volumen. No voy a recomendar aquí un servicio concreto de proxy de pago, pero el consejo general es: evita proxies de centro de datos (TikTok los marca con agresividad) y busca grupos de proxies residenciales o móviles con rotación por solicitud.
Como alternativa, herramientas basadas en navegador como evitan por completo la cuestión de los proxies porque funcionan en tu propia sesión del navegador, imitando a un usuario real. Eso no las hace inmunes a la detección a gran escala, pero para casos de uso típicos de marketing o investigación (docenas o cientos de páginas, no millones) es una vía mucho más sencilla.
¿Qué datos obtienes realmente? Muestras reales de salida de scrapers de TikTok
Los usuarios quieren saber qué datos obtendrán en realidad antes de comprometerse con una herramienta, y la mayoría de las guías se saltan esto por completo. Aquí tienes estructuras de campos representativas basadas en la documentación de origen.
Datos de perfil
| Nombre de usuario | Nombre visible | Seguidores | Siguiendo | Me gusta totales | Bio | Verificado | URL del perfil |
|---|---|---|---|---|---|---|---|
| @examplecreator | Jane Doe | 1,240,000 | 312 | 48,700,000 | "Cocina + comedia 🍳" | ✅ | tiktok.com/@examplecreator |
| @travelwithmark | Mark S. | 890,000 | 150 | 22,100,000 | "Vlogger de viajes 🌍" | ❌ | tiktok.com/@travelwithmark |
| @fitnessmaya | Maya L. | 2,100,000 | 88 | 91,300,000 | "Entrenamiento y bienestar" | ✅ | tiktok.com/@fitnessmaya |
Disponible en: scrapers de GitHub (TikTok-Api, Evil0ctal), Research API, Thunderbit (a partir de páginas de perfil visibles).
Metadatos de video
| URL del video | Descripción | Vistas | Me gusta | Comentarios | Compartidos | Música | Hashtags | Fecha de publicación | Duración |
|---|---|---|---|---|---|---|---|---|---|
| tiktok.com/@ex/video/123 | "El mejor truco para la pasta 🍝" | 4,200,000 | 312,000 | 8,400 | 21,000 | "Italian Vibes – DJ Marco" | #pasta #cocina #truco | 2026-03-15 | 0:42 |
| tiktok.com/@ex/video/456 | "POV: tu gato te juzga" | 9,100,000 | 1,100,000 | 23,000 | 55,000 | "Original Sound" | #gato #pov #gracioso | 2026-04-01 | 0:18 |
| tiktok.com/@ex/video/789 | "La rutina de la mañana que nadie pidió" | 1,800,000 | 98,000 | 3,200 | 7,500 | "Chill Morning – LoFi" | #rutina #mañana | 2026-04-10 | 1:02 |
Disponible en: scrapers de GitHub (TikTok-Api, Evil0ctal), (los campos incluyen video_description, view_count, like_count, comment_count, share_count, music_id, hashtag_names, video_duration), Thunderbit ().
Datos de comentarios
| Autor del comentario | Texto del comentario | Me gusta | Marca de tiempo | Respuestas |
|---|---|---|---|---|
| @user_abc | "Lo probé y realmente funciona 😂" | 1,200 | 2026-03-16T08:12:00Z | 14 |
| @chef_dan | "Añade ajo la próxima vez, confía en mí" | 890 | 2026-03-16T09:45:00Z | 7 |
| @randomfan99 | "Este es el tipo de contenido por el que estoy aquí" | 340 | 2026-03-16T11:30:00Z | 2 |
Disponible en: scrapers de GitHub (TikTok-Api, Evil0ctal), (los campos incluyen text, like_count, reply_count, create_time), Thunderbit (a partir de las secciones visibles de comentarios).
Datos de hashtags y búsqueda
| Hashtag | URL del video principal | Vistas agregadas | En tendencia |
|---|---|---|---|
| #pasta | tiktok.com/@ex/video/123 | 4,200,000 | Sí |
| #cooking | tiktok.com/@chef/video/321 | 11,000,000 | Sí |
| #hack | tiktok.com/@tips/video/654 | 2,900,000 | No |
Disponible en: scrapers de GitHub (varía según el repositorio), Thunderbit ().
Nota: ningún repositorio garantiza todos los campos todo el tiempo. Las estructuras de respuesta de TikTok cambian, y hasta los mantenedores lo advierten. Tómalos como ejemplos representativos, no como garantías.
Cómo extraer datos de TikTok en 2 clics con Thunderbit (paso a paso)
¿Cansado del ciclo de romper y arreglar? Aquí tienes la ruta no-code: la salida para cualquiera que haya probado y fallado con repositorios de GitHub.
- Instala la .
- Ve a la página de TikTok que quieres extraer: un perfil, una página de resultados de búsqueda, una página de hashtag o un video individual.
- Haz clic en "AI Suggest Fields". La IA de Thunderbit lee la página y sugiere columnas: nombre de usuario, seguidores, descripción del video, me gusta, hashtags, etc.
- Ajusta los campos si hace falta y luego haz clic en "Scrape". Los datos se llenan en una tabla estructurada.
- Usa el scraping de subpáginas para enriquecer los datos. Entra en cada video desde un listado de perfil y extrae campos adicionales: descripción completa, detalles de música, número de comentarios, compartidos.
- Exporta a Google Sheets, Excel, Airtable o Notion — totalmente gratis.
Sin mantenimiento, sin pelear con la instalación, sin configuración anti-bloqueo. La IA se adapta automáticamente a los cambios de diseño de TikTok.
Enriquecer datos de TikTok con scraping de subpáginas
Después de extraer una lista de videos de un perfil o de una página de hashtags, haz clic en "Scrape Subpages" para que la IA visite cada página de video y extraiga campos adicionales. Esto es especialmente útil para marketers que construyen bases de datos de influencers o realizan auditorías de contenido de la competencia: obtienes una tabla completa de datos de interacción a nivel de video sin tener que hacer clic manualmente en decenas de páginas.
Exportar y usar tus datos de TikTok
Thunderbit exporta a Google Sheets, Excel, Airtable, Notion, CSV o JSON, todo gratis. Casos de uso comunes:
- Volcar los datos en una hoja de cálculo para analizar la interacción.
- Enviarlos a Airtable para un rastreador de influencers tipo CRM.
- Pasarlos a Notion para colaborar en equipo sobre investigación de contenido.
Para ver con más detalle cómo Thunderbit maneja la extracción de datos web, consulta nuestra o mira tutoriales en el .
Mantenerse legal: términos de servicio de TikTok y cumplimiento del scraping
La postura legal de TikTok es clara. La dice que sus Términos de servicio prohíben scripts automatizados que recopilen información o interactúen con el servicio de formas no autorizadas, y menciona explícitamente eludir restricciones de acceso. Las de TikTok también prohíben intentos engañosos de obtener información mediante scripts automatizados o rastreo web.
Orientación práctica:
- Limítate a los datos disponibles públicamente. No extraigas contenido privado ni protegido por inicio de sesión.
- Respeta los límites de velocidad. No satures los servidores de TikTok.
- Cumple las leyes de privacidad de datos. GDPR y CCPA siguen aplicando si recopilas, almacenas o analizas datos personales.
- Usa la Research API cuando seas elegible. Es la ruta más segura desde el punto de vista del cumplimiento.
- Esto no es asesoramiento legal. Consulta a un profesional para tu situación concreta.
Para profundizar en el panorama legal, consulta nuestra guía sobre las .
Qué hacer cuando tu repositorio de GitHub para scraper de TikTok muere
La versión corta:
- Ejecuta siempre la lista de verificación de 60 segundos del repositorio antes de clonar cualquier scraper de TikTok desde GitHub. La mayoría ya están muertos.
- Entiende tus opciones. La API oficial, los scrapers de GitHub y las herramientas no-code sirven a usuarios y casos de uso distintos.
- Si eliges la ruta de GitHub, reserva tiempo para depurar la instalación y configurar la protección anti-bloqueo. Espera mantenimiento continuo.
- Sabe qué datos vas a obtener realmente antes de comprometerte con una herramienta. Revisa los campos de salida, no solo el número de estrellas.
- Si no eres desarrollador (o estás cansado de repos rotos), prueba una herramienta no-code como — dos clics, datos estructurados, exportación gratis.
Los datos de TikTok que necesitas son accesibles. La pregunta es si quieres pasar tu tiempo manteniendo un scraper o usando realmente los datos. Elige el enfoque que se ajuste a tu nivel y caso de uso, y no dejes que un repositorio muerto de GitHub te haga perder otra tarde.
Preguntas frecuentes
¿Hay scrapers de TikTok en GitHub que sigan funcionando en 2026?
Sí, pero la lista es corta. es la opción de código abierto más creíble con mantenimiento activo a abril de 2026. también sigue vivo, aunque es más complejo. El repositorio con más estrellas, drawrowfly/tiktok-scraper, no se actualiza desde mayo de 2023 y, en la práctica, está muerto. Ejecuta siempre la lista de verificación de salud del repositorio antes de invertir tiempo en cualquiera de ellos.
¿Es legal extraer datos de TikTok?
Los Términos de servicio de TikTok prohíben explícitamente el scraping automatizado. Los datos visibles públicamente ocupan una zona legal gris que varía según la jurisdicción. La vía más segura es la oficial para investigadores elegibles. Si extraes datos públicos, limítate a contenido accesible públicamente, respeta los límites de velocidad y cumple con GDPR/CCPA. Esto no es asesoramiento legal; consulta a un profesional para tu caso.
¿Puedo extraer datos de TikTok sin programar?
Sí. Herramientas de IA basadas en navegador como te permiten extraer datos estructurados de TikTok (perfiles, metadatos de video, hashtags, métricas de interacción) sin escribir código. La TikTok Research API también requiere muy poco código para solicitantes aprobados. Para personas sin perfil técnico, las herramientas no-code son la vía más rápida y fiable.
¿Qué datos puedo obtener de un scraper de TikTok?
Los tipos de datos comunes incluyen información de perfil (nombre de usuario, seguidores, bio, estado de verificación), metadatos de video (descripción, vistas, me gusta, comentarios, compartidos, música, hashtags, duración, fecha de publicación), comentarios (texto, me gusta, marca de tiempo, respuestas) y datos de hashtags/búsqueda (mejores videos, vistas agregadas, estado de tendencia). Los campos exactos dependen de la herramienta y del método; mira la sección de ejemplos de salida más arriba para más detalles.
¿Por qué mi scraper de TikTok sigue siendo bloqueado?
TikTok usa varias capas de defensa anti-bot: limitación de velocidad, bloqueo por cookies/sesión, huella digital del navegador, detección de comportamiento, parámetros de solicitud cifrados y flujos de CAPTCHA. Las causas más comunes de bloqueo incluyen enviar solicitudes demasiado rápido, usar una sesión limpia/nueva en cada solicitud, ejecutar un navegador sin interfaz con huellas por defecto o usar proxies de centros de datos. Consulta la sección de buenas prácticas anti-baneo más arriba para ver soluciones gratuitas y de pago.