La web está llena de información, pero convertir ese desorden en datos útiles para tu negocio es el verdadero desafío—y también una oportunidad enorme. Después de años creando herramientas SaaS y de automatización, he visto cómo el mundo pasó de tomar decisiones por corazonadas a depender de los datos para todo. Ya no es solo cosa de las grandes tecnológicas; hasta los equipos más pequeños buscan extraer datos de sitios web para potenciar ventas, marketing, precios y desarrollo de productos. Pero a medida que la web se vuelve más compleja y cambia constantemente, conseguir datos limpios, legales y valiosos se vuelve cada vez más complicado.
Vamos al grano: te voy a contar por qué la extracción de datos web es tan importante hoy, los principales obstáculos que te vas a encontrar y las mejores prácticas (incluyendo lo que hemos aprendido en Thunderbit) para hacerlo bien—de forma legal, eficiente y a gran escala. Si te enfrentas a contenido desordenado, te preocupa el RGPD o simplemente quieres dejar de copiar y pegar en hojas de cálculo, esta guía es para ti.
Por Qué Extraer Datos de Sitios Web es Clave para los Negocios Modernos
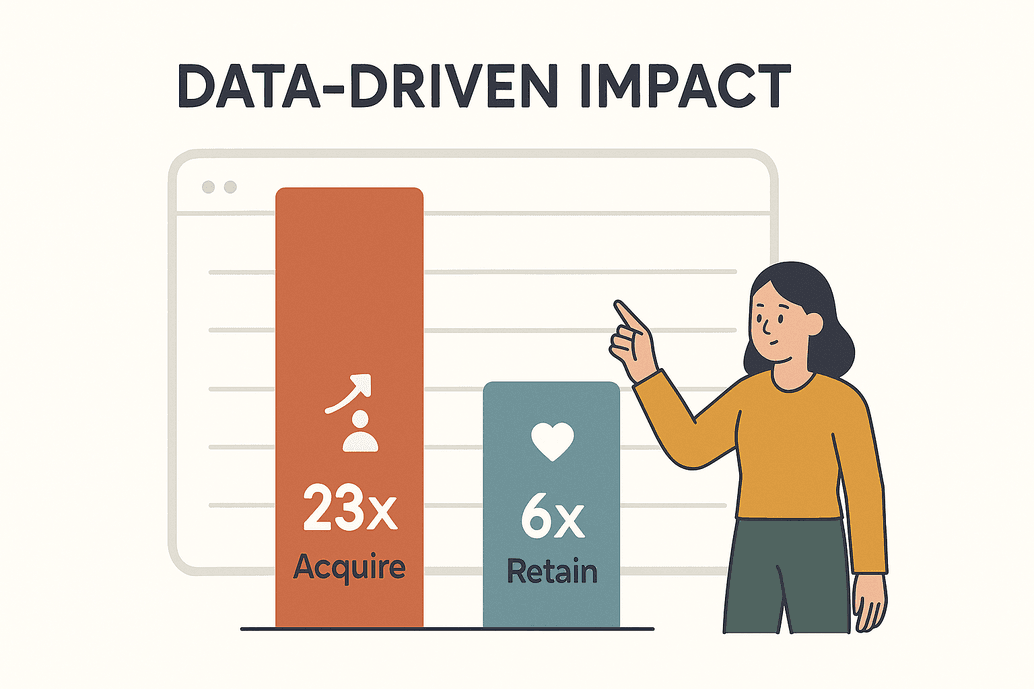 Los datos no son solo una tendencia: son el motor de la competitividad en los negocios. Según una , las empresas que se apoyan en los datos tienen 23 veces más probabilidades de captar clientes y 6 veces más de retenerlos. No es solo impresionante—es cuestión de sobrevivir. Para 2025, las empresas extraerán miles de millones de páginas web cada día para alimentar analíticas, modelos de IA y decisiones en tiempo real ().
Los datos no son solo una tendencia: son el motor de la competitividad en los negocios. Según una , las empresas que se apoyan en los datos tienen 23 veces más probabilidades de captar clientes y 6 veces más de retenerlos. No es solo impresionante—es cuestión de sobrevivir. Para 2025, las empresas extraerán miles de millones de páginas web cada día para alimentar analíticas, modelos de IA y decisiones en tiempo real ().
¿Y esto cómo se ve en la vida real? Aquí tienes algunos ejemplos que veo todas las semanas:
| Aplicación Empresarial | Descripción y Beneficios | Ejemplo/Estadística |
|---|---|---|
| Monitoreo de Precios | Vigila precios, stock y promociones de la competencia en tiempo real; ajusta tu estrategia para mantenerte por delante. | Más del 80% de los principales comercios online extraen precios de la competencia a diario (kanhasoft.com). |
| Generación de Leads | Extrae datos de directorios, redes sociales o sitios de reseñas para conseguir nuevos contactos. | La extracción automatizada llena los CRMs mucho más rápido que la investigación manual. |
| Análisis de Tendencias de Mercado | Agrupa reseñas, foros y noticias para detectar tendencias o cambios de opinión antes que nadie. | El 26% de la extracción se centra en redes sociales para detectar tendencias (blog.apify.com). |
| Agregación de Contenidos | Recopila noticias, listados de productos o eventos de varios sitios para facilitar el acceso. | Los equipos de medios curan feeds para sus audiencias. |
| Datos de Producto e Investigación | Reúne detalles de productos, reseñas o datos de investigación para análisis y desarrollo. | El 67% de los asesores de inversión usan datos alternativos de la web (scrap.io). |
| Datos para Entrenar IA | Extrae grandes volúmenes de texto, imágenes o registros para entrenar modelos de IA. | Cerca del 70% de los grandes modelos de IA dependen de datos extraídos de la web (kanhasoft.com). |
Si no estás extrayendo datos de la web, no solo vas por detrás—es como si no existieras en tu sector. He visto equipos de e-commerce triplicar su ROI en seis meses solo por automatizar la extracción de precios de la competencia (). En resumen: los datos web son un activo estratégico, y saber extraerlos bien es ahora imprescindible.
Principales Retos al Extraer Datos de Cualquier Sitio Web
Por supuesto, no todo es tan fácil como exportar a CSV. La web es un entorno caótico y extraer datos tiene sus retos:
- Datos No Estructurados: Cerca del 80% de los datos online no están estructurados—escondidos en HTML desordenado, repartidos en varias páginas o detrás de elementos interactivos. Convertir eso en una tabla limpia no es nada sencillo ().
- Cambios en los Sitios: Las webs cambian su diseño todo el tiempo. He visto 웹 스크래퍼 romperse 15 veces en un mes solo porque el sitio objetivo cambió su estructura ().
- Volumen y Escalabilidad: Las empresas necesitan extraer datos de cientos o miles de páginas—muchas veces de forma programada. El copiar y pegar manual no da para tanto.
- Defensas Anti-Scraping: CAPTCHAs, límites de velocidad, muros de inicio de sesión… Los sitios cada vez son más hábiles bloqueando bots. Más de un tercio del tráfico web ya son bots (), y la tecnología anti-bots avanza rápido.
- Errores Manuales: El copiar y pegar humano es lento y propenso a errores. Un selector mal puesto y extraes datos equivocados—o ninguno.
Los métodos tradicionales no escalan. Por eso cada vez más equipos apuestan por soluciones inteligentes y automatizadas (y por eso confío tanto en las herramientas con IA).
Buenas Prácticas Legales, de Cumplimiento y Seguridad en la Extracción de Datos Web
Vamos a dejarlo claro: que puedas extraer datos de una web no significa que debas hacerlo—al menos sin pensar en lo legal y lo ético. Esto es lo que toda empresa debe tener en cuenta:
- Datos Públicos vs. Privados: Extraer información pública suele ser legal en muchos países. Pero lo que está tras un login es territorio prohibido. Saltarse autenticaciones no está permitido ().
- Términos de Servicio: Revisa siempre los Términos de Servicio del sitio. Si prohíben el scraping, te arriesgas a demandas o bloqueos. Ante la duda, pide permiso o usa APIs oficiales.
- Leyes de Privacidad (RGPD, CCPA): Si recoges datos personales, necesitas una base legal (como interés legítimo), debes minimizar lo que recopilas y estar preparado para eliminar datos si te lo piden. No cumplir puede salir caro ().
- Respeta robots.txt: No es legalmente obligatorio, pero es buena práctica. Sigue las reglas de crawl-delay y no sobrecargues los servidores.
- Seguridad de los Datos: Trata los datos extraídos como información sensible. Guárdalos de forma segura, limita el acceso y límpialos antes de usarlos.
Lista de Verificación de Cumplimiento:
| Consideración | Mejor Práctica |
|---|---|
| Acceso Legal | Extrae solo datos públicos; nunca saltes inicios de sesión (xbyte.io). |
| Términos de Servicio | Revisa y respeta los ToS del sitio; usa APIs si el scraping está prohibido. |
| Datos Personales | Evítalos si puedes; si es necesario, minimiza y cumple RGPD/CCPA. |
| robots.txt y Crawl Delays | Respeta las reglas del sitio; limita la frecuencia de peticiones. |
| Seguridad de los Datos | Encripta, restringe el acceso y elimina cuando ya no sean necesarios. |
Cómo la IA Mejora la Extracción de Datos Web
Aquí es donde la cosa se pone buena. La IA ha revolucionado la extracción de datos web. En vez de pelearte con selectores o scripts frágiles, ahora puedes usar herramientas inteligentes que “leen” la página y detectan qué extraer—muchas veces con solo un par de clics.
¿Qué significa esto en la práctica?
- Configuración Mínima: 웹 스크래퍼 con IA como detectan automáticamente los campos. Solo haz clic en “Sugerir Campos con IA” y la herramienta te propone las columnas adecuadas—sin código ni pruebas eternas.
- Adaptabilidad: Los 웹 스크래퍼 con IA reconocen patrones, no solo estructuras fijas. Si el sitio cambia, la IA suele adaptarse sola. Menos mantenimiento y menos sustos de madrugada.
- Precisión: La IA filtra el ruido, elimina duplicados y limpia los datos mientras los extrae. Algunos equipos reportan precisiones de hasta el 99,5% con extractores basados en IA ().
- Contenido Dinámico: Los 웹 스크래퍼 con IA pueden manejar sitios con JavaScript, scroll infinito e incluso extraer texto de imágenes o PDFs.
- Procesamiento en Tiempo Real: ¿Necesitas traducir, categorizar o resumir datos mientras los extraes? La IA lo hace en una sola pasada.
 He visto equipos ahorrar entre un 30 y 40% de su tiempo en extracción de datos solo por pasarse a herramientas con IA (). No es solo productividad—es una ventaja competitiva.
He visto equipos ahorrar entre un 30 y 40% de su tiempo en extracción de datos solo por pasarse a herramientas con IA (). No es solo productividad—es una ventaja competitiva.
Thunderbit está pensado para que la extracción sea fácil, precisa y accesible, incluso para quienes nunca han programado. (Y sí, mi madre puede usarlo. Aunque todavía se pelea con Netflix.)
Thunderbit AI Web Scraper: Funciones Clave para Empresas
Déjame presumir un poco de lo que hemos creado en Thunderbit (¡me lo he ganado!). Thunderbit está hecho para usuarios de negocio—ventas, operaciones, marketing, inmobiliarias—que buscan resultados, no complicaciones. Esto es lo que lo hace especial:
- Sugerencia de Campos con IA: Haz clic y la IA de Thunderbit analiza la página, sugiere columnas y configura el 웹 스크래퍼 por ti. Olvídate de los selectores.
- Extracción en 2 Clics: Una vez definidos los campos, solo pulsa “Extraer” y obtén una tabla limpia—sin código ni configuraciones.
- Extracción en Subpáginas: ¿Necesitas más detalles? Thunderbit puede visitar automáticamente cada subpágina (como fichas de producto o perfiles) y enriquecer tu tabla con información extra.
- Plantillas Predefinidas: Para sitios populares (Amazon, Zillow, Instagram, Shopify, etc.), solo elige una plantilla y listo—sin configuraciones.
- Exporta a Cualquier Lugar: Exportación gratuita a Excel, Google Sheets, Airtable, Notion o CSV. Sin costes ocultos.
- Extracción Programada: Automatiza extracciones recurrentes—solo describe el intervalo (“cada lunes a las 8am”) y Thunderbit se encarga.
- Extracción en la Nube o en el Navegador: Usa los servidores de Thunderbit para velocidad, o tu propio navegador para sitios que requieren login.
- Soporte Multilingüe: Extrae datos en 34 idiomas, incluyendo español, inglés, chino y más.
Automatiza y Escala: Programación e Integraciones para la Extracción de Datos
El scraping manual ya es cosa del pasado. El verdadero valor está en automatizar e integrar la extracción de datos en tus flujos de trabajo:
- Extracción Programada: Configura Thunderbit para ejecutar extracciones diarias, semanales o cuando lo necesites. Ideal para monitoreo de precios, generación de leads o agregación de noticias.
- Integración Directa: Exporta los datos extraídos directamente a Google Sheets, Excel, Airtable o Notion. Olvídate de descargar y volver a subir archivos.
- Integración con CRM y Analítica: Envía los datos a tu CRM o herramientas BI para dashboards en tiempo real, alertas o campañas automáticas.
Ejemplo: Flujo Automatizado de Monitoreo de Precios
- Configura Thunderbit en la página de producto de un competidor.
- Usa “Sugerir Campos con IA” para capturar nombre, precio y URL del producto.
- Programa la extracción cada mañana a las 7am.
- Exporta los resultados a Google Sheets, enlazado a un dashboard.
- El responsable de precios revisa los cambios y ajusta la estrategia antes que la competencia.
Con la automatización, no solo eres más rápido—siempre tienes datos frescos y listos.
Buenas Prácticas para Manejar Datos No Estructurados al Extraer de la Web
Seamos sinceros: la mayoría de los datos web no son limpios ni ordenados. Son desestructurados, inconsistentes y a veces caóticos. Así puedes ponerlos en forma:
- Define la Estructura Antes: Usa sugerencias de campos con IA o plantillas para imponer orden—decide columnas y tipos de datos antes de extraer.
- Prompts de IA por Campo: Thunderbit permite añadir instrucciones personalizadas para cada campo. ¿Quieres categorizar productos, formatear teléfonos o traducir descripciones? Solo indícalo a la IA.
- Aprovecha el PLN: Para reseñas, comentarios o artículos, usa funciones de PLN integradas para resumir, analizar sentimiento o extraer palabras clave.
- Normaliza los Datos: Limpia formatos (fechas, precios, teléfonos) durante la extracción, no después. La consistencia es clave.
- Elimina Duplicados y Valida: Quita duplicados y revisa muestras para asegurar precisión. Si algo no cuadra, ajusta los prompts o la configuración.
Prompts de IA por Campo: Personaliza la Extracción para Mejores Resultados
Esta es una de mis funciones favoritas. Con prompts de IA a nivel de campo puedes:
- Etiquetar y Categorizar: “Clasifica este producto como Electrónica, Muebles o Ropa según su descripción.”
- Forzar Formatos: “Devuelve la fecha en formato AAAA-MM-DD.” “Extrae solo el precio numérico.”
- Traducir al Instante: “Traduce la descripción del producto al español.”
- Limpiar Ruido: “Extrae la biografía del usuario, ignorando enlaces de ‘Leer más’ o anuncios.”
- Combinar Campos: “Une las líneas de dirección en un solo campo.”
Es como tener un analista junior integrado en tu 웹 스크래퍼—y nunca se queja por el café.
Cómo Garantizar la Calidad y Consistencia de los Datos Extraídos
Una buena extracción no termina al pulsar “Exportar”. Así mantienes tus datos limpios y fiables:
- Validaciones: Usa comprobaciones de rango, campos obligatorios y claves únicas para detectar errores.
- Auditoría de Muestras: Revisa manualmente una muestra de los datos extraídos frente al sitio original—especialmente tras la configuración o si el sitio cambia.
- Gestión de Errores: Registra extracciones fallidas y configura alertas para anomalías (como una caída repentina en el número de filas).
- Limpieza Continua: Usa hojas de cálculo o scripts para eliminar espacios, corregir codificaciones y normalizar textos.
- Consistencia de Esquema: Mantén nombres de campos y formatos estables en el tiempo. Documenta cambios para que tu equipo no tenga dudas.
La confianza en tus datos lo es todo. Un poco de esfuerzo al principio evita muchos problemas después.
Comparativa de Herramientas: Qué Buscar al Elegir una Solución
No todos los 웹 스크래퍼 son iguales. Ten en cuenta lo siguiente:
| Herramienta | Ventajas | Consideraciones |
|---|---|---|
| Thunderbit | La más fácil para usuarios no técnicos; detección de campos con IA; extracción en subpáginas; plantillas predefinidas; exportación gratuita; planes asequibles (Thunderbit Blog). | No está pensada para proyectos enormes o muy técnicos; usa un sistema de créditos. |
| Browse AI | Sin código, ideal para monitoreo de cambios; integración con Google Sheets; extracción masiva. | Planes iniciales más caros; la configuración puede llevar tiempo. |
| Octoparse | Potente, maneja sitios dinámicos; funciones avanzadas para usuarios técnicos. | Curva de aprendizaje pronunciada; precios más altos. |
| Web Scraper (webscraper.io) | Gratis para proyectos pequeños; configuración visual; gran comunidad. | La configuración manual puede ser confusa; asistencia de IA limitada. |
| Diffbot | Potenciado por IA, analiza páginas no estructuradas vía API; ideal para desarrolladores. | Caro, basado en API, no apto para usuarios no técnicos. |
Mi consejo: Si eres usuario de negocio y buscas resultados rápidos y precisos, es una gran opción. Para usuarios avanzados o desarrolladores, Octoparse o Diffbot pueden valer la pena si asumes la complejidad. Prueba siempre la versión gratuita antes de decidirte.
Conclusión: Pon en Práctica las Mejores Estrategias de Extracción de Datos Web
Extraer datos de sitios web ya no es un “extra”—es imprescindible para cualquier empresa que quiera ser competitiva. Quédate con esto:
- Valor: Los datos web impulsan decisiones más inteligentes y rápidas. No los dejes pasar.
- Supera los Retos: Usa herramientas con IA para manejar datos no estructurados, grandes volúmenes y cambios en los sitios.
- Cumple la Ley: Respeta la privacidad, las normas de los sitios y la seguridad de los datos.
- Automatiza: Programa e integra la extracción en tu día a día.
- Calidad Ante Todo: Valida, limpia y monitoriza tus datos para mantener la confianza.
¿Listo para ver lo fácil que puede ser? y pruébala en tu próximo proyecto de datos. Y si quieres profundizar, visita el para más guías, consejos y ejemplos reales.
¡Feliz extracción—y que tus datos siempre sean estructurados, legales y listos para usar!
Preguntas Frecuentes
1. ¿Es legal extraer datos de cualquier sitio web?
En general, extraer datos públicos es legal en muchos países, pero debes evitar saltarte inicios de sesión o medidas de seguridad. Revisa siempre los términos de servicio y cumple con leyes de privacidad como RGPD y CCPA ().
2. ¿Cómo mejora la IA el proceso de extracción de datos web?
Herramientas con IA como detectan campos automáticamente, se adaptan a cambios en el diseño, limpian y formatean datos, y pueden manejar contenido dinámico o traducciones—todo con mínima configuración y alta precisión ().
3. ¿Cuáles son las mejores prácticas para manejar datos no estructurados?
Define la estructura de tus datos desde el principio, usa prompts de IA por campo para guiar la extracción, normaliza formatos durante el proceso y valida los resultados. Herramientas como Thunderbit facilitan categorizar, formatear y etiquetar datos al instante.
4. ¿Cómo puedo automatizar y escalar la extracción de datos web?
Utiliza funciones de programación para ejecutar extracciones periódicas e integra los resultados directamente en Google Sheets, Airtable o tu CRM. La automatización mantiene tus datos actualizados y reduce el trabajo manual.
5. ¿Cómo garantizo la calidad y consistencia de los datos extraídos?
Implementa validaciones, audita muestras regularmente, gestiona errores y mantén tu esquema de datos estable. La mejora continua y la monitorización son clave para datos fiables.
¿Quieres ver estas buenas prácticas en acción? y descubre lo fácil, legal y escalable que puede ser la extracción de datos web.
Más información