Xiaohongshu-Scraper

Vertrauenswürdig für Profis in führenden Unternehmen











Xiaohongshu-Daten in zwei Klicks erschließen
Mühelose Datenerfassung in zwei Klicks
Genervt von kompliziertem Code und endlosem Setup, nur um Xiaohongshu-Daten zu erfassen? Mit Thunderbit kannst du wichtige Datenfelder wie note_id, author_id, author_nickname, note_title, note_content und like_count extrahieren, ohne auch nur eine Zeile Code zu schreiben. Zeig einfach auf die benötigten Daten, und Thunderbit erkennt die Felder automatisch und extrahiert sie per Klick.
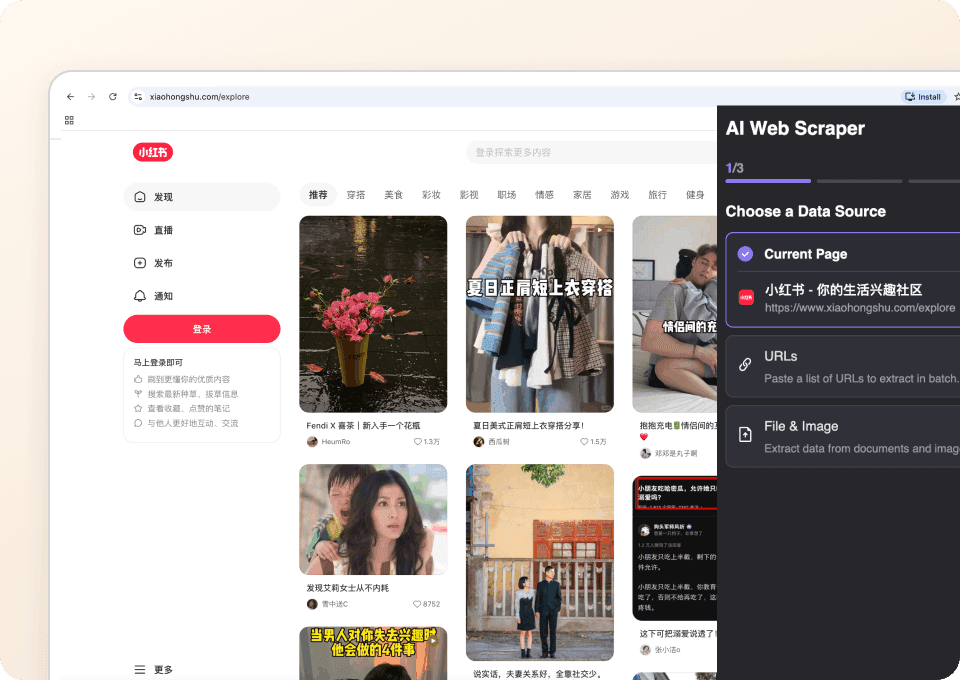
Die ganze Geschichte automatisch erhalten
Xiaohongshu-Listing-Seiten geben dir nur einen ersten Eindruck. Mit Thunderbit kannst du automatisch jede Notiz-Unterseite besuchen, um detaillierte Informationen direkt zu extrahieren. Entdecke verborgene Einblicke und erhalte das vollständige Bild, indem du jedes relevante Detail scrapen lässt – alles als neue Spalten in deinem gewählten Zielsystem hinzugefügt.
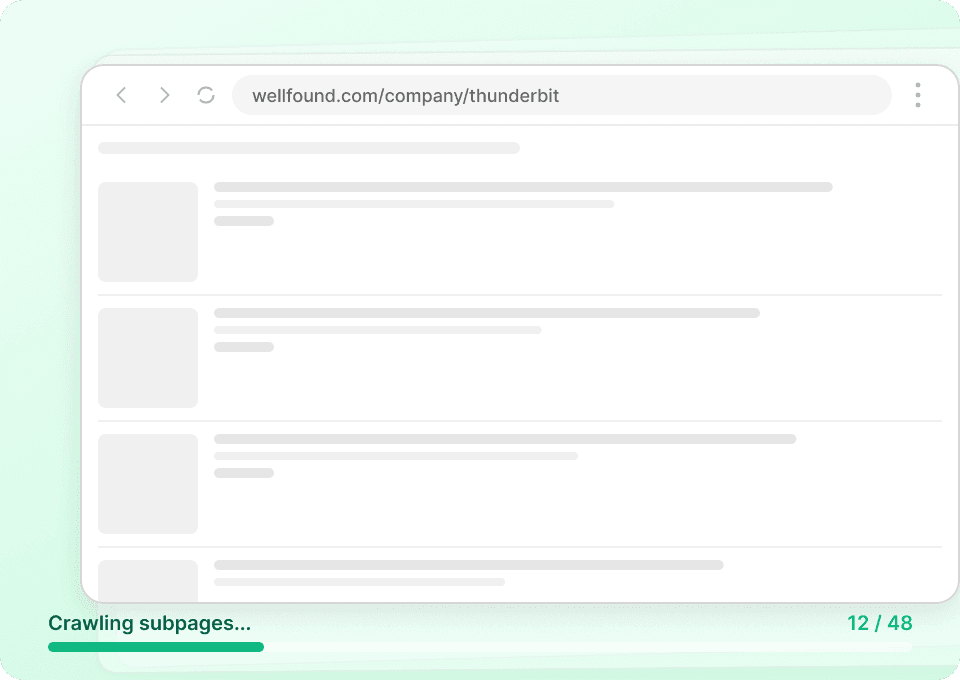
Dein Xiaohongshu-Datenmonitoring automatisieren
Xiaohongshu-Daten ändern sich ständig. Jeden Tag manuell zu scrapen ist mühsam. Mit Thunderbits geplantem Scraping richtest du wiederkehrende Aufgaben ein, die Daten wie like_count automatisch im Hintergrund extrahieren. Erhalte frische Einblicke direkt in Google Sheets, Notion oder Airtable – ganz ohne Aufwand.
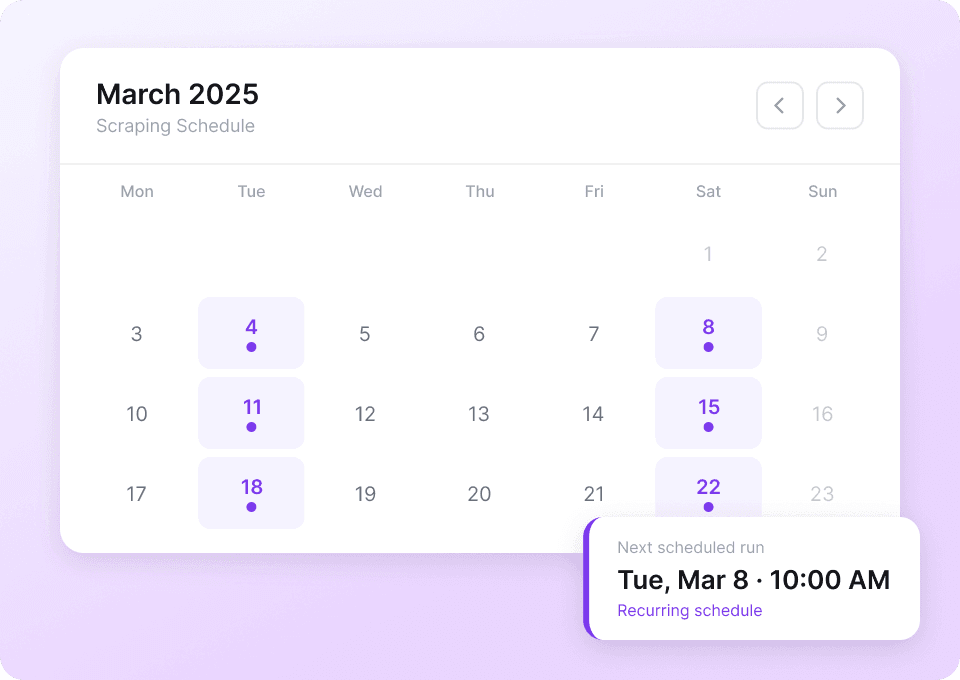
Schwer, Xiaohongshu effektiv zu scrapen?
Sieh dir an, warum Thunderbit der intelligentere Weg ist, Xiaohongshu-Daten zu extrahieren.
Traditional Scrapers
The old way of doing thingsThunderbit AI
The smarter approachVerlass dich nicht nur auf unser Wort
Sieh dir an, was unsere Nutzer über Thunderbit sagen.





Häufig gestellte Fragen
Ähnlich Anwendungsfälle
Entdecke weitere Anwendungsfälle von Thunderbits Web-Scraper.
PeopleWhiz-Scraper
Der Thunderbit PeopleWhiz-Scraper ermöglicht es dir, mit KI-gestützten Feldvorschlägen Daten aus PeopleWhiz-Suchergebnissen und Profilen zu extrahieren. Erfasse Namen, Kontaktdaten, Standorte und mehr für Recherche, Marketing oder Lead-Generierung. Verwandle PeopleWhiz-Daten schnell und effizient in strukturierte Datensätze.
Mehr erfahren ->
TripAdvisor Unternehmenslisten-Scraper
Mit dem Thunderbit TripAdvisor Business Listings Scraper können Sie Daten aus den Geschäftseinträgen, dem Ressourcenbereich und dem Eigentümerforum von TripAdvisor extrahieren. Dank KI-gestützter Feldvorschläge sammeln Sie im Handumdrehen Ressourcennamen, URLs, Beschreibungen, Forenthemen, Autoren und Beiträge – ideal für Recherche, Marketing oder Analyse.
Mehr erfahren ->
ReverseAustralia Scraper
Mit dem Thunderbit ReverseAustralia Scraper können Sie Daten von Beschwerde- und Kommentarseiten auf ReverseAustralia extrahieren. Dank KI-gestützter Feldvorschläge erfassen Sie schnell Telefonnummern, Beschreibungen von Beschwerden, Kommentartexte, Nutzernamen und vieles mehr – ideal für Analysen oder Recherchen. Perfekt für Marketer, Forschende und Unternehmen, die strukturierte Feedbackdaten benötigen.
Mehr erfahren ->
Herold-Scraper
Mit dem Thunderbit Herold-Scraper können Sie Daten aus den Geschäfts- und Personensuchergebnissen von Herold in nur zwei Klicks extrahieren. Dank KI-gestützter Feldvorschläge erfassen Sie gezielt Firmennamen, Adressen, Telefonnummern, E-Mail-Adressen und mehr – perfekt für Leadgenerierung, Recherche oder Marketing. Ideal für Vertriebsteams, Marketer und Forschende, die strukturierte Herold-Daten benötigen.
Mehr erfahren ->
iBegin Scraper
Mit dem Thunderbit iBegin-Scraper können Sie Suchergebnisse und detaillierte Unternehmensinformationen von der iBegin-Website extrahieren. Dank KI-gestützter Feldvorschläge erfassen Sie schnell Firmennamen, Kontaktdaten, Adressen, Bewertungen und vieles mehr – ideal für Leadgenerierung, Recherche oder Marketinganalysen.
Mehr erfahren ->
United Airlines Scraper
Mit einem Klick die Flugdaten von United Airlines erfassen – etwa Flugnummer, Ankunftszeit und Abflughafen. Den Rest übernimmt Thunderbit AI.
Mehr erfahren ->Bereit, deine Datenextraktion zu beschleunigen?
Schließe dich über 100.000 Profis an, die Thunderbit bereits nutzen, um ihre Web-Scraping-Workflows zu automatisieren.
Die kostenlose Testversion bietet unbegrenzte Credits für 8 Webseiten.