Scrape Remote-Jobanzeigen von We Work Remotely in wenigen Minuten mit – einem KI-gestützten Web-Scraper, der Seiteninhalte versteht und Stellenanzeigen in strukturierte Zeilen verwandelt. Du klickst auf AI Suggest Columns, dann auf Scrape, und Thunderbits KI ordnet Titel, Unternehmen, Standorte, Tags, Daten und URLs so, dass du sie direkt exportieren kannst. Wenn du mehr Details brauchst, nutzt du zusätzlich Subpage Scraping: Dabei wird jede Jobseite geöffnet und dein Datensatz um vollständige Beschreibungen und Bewerbungslinks ergänzt.
🧑💻 Was ist der We Work Remotely Scraper
Der We Work Remotely Scraper ist ein KI-Web-Scraper, mit dem du über die Thunderbit Chrome Extension Stellenanzeigen und Jobdetails von extrahieren kannst. Statt Code zu schreiben oder anfällige Selektoren zu bauen, öffnest du einfach die gewünschte Seite (z. B. das Remote-Jobs-Verzeichnis), klickst auf AI Suggest Columns und anschließend auf Scrape. So entsteht eine saubere Tabelle, die du herunterladen oder an deine Tools weitergeben kannst.
Mit Thunderbit kannst du außerdem:
- Pagination und lange Listen zuverlässig verarbeiten
- per Subpage Scraping jede Stellenanzeige öffnen und vollständige Beschreibungen, Anforderungen sowie Bewerbungs-URLs erfassen
- kostenlos nach Excel, Google Sheets, Airtable oder Notion exportieren (inkl. Free-Export-Optionen)
🗂️ Was kannst du mit We Work Remotely scrapen
We Work Remotely ist eine beliebte Anlaufstelle für Remote-Rollen in Engineering, Product, Design, Marketing, Customer Support und mehr. Mit Thunderbits KI-Web-Scraper (https://thunderbit.com/) baust du dir daraus eine strukturierte Job-Datenbank – für Sourcing, Analysen, Alerts und Reporting.
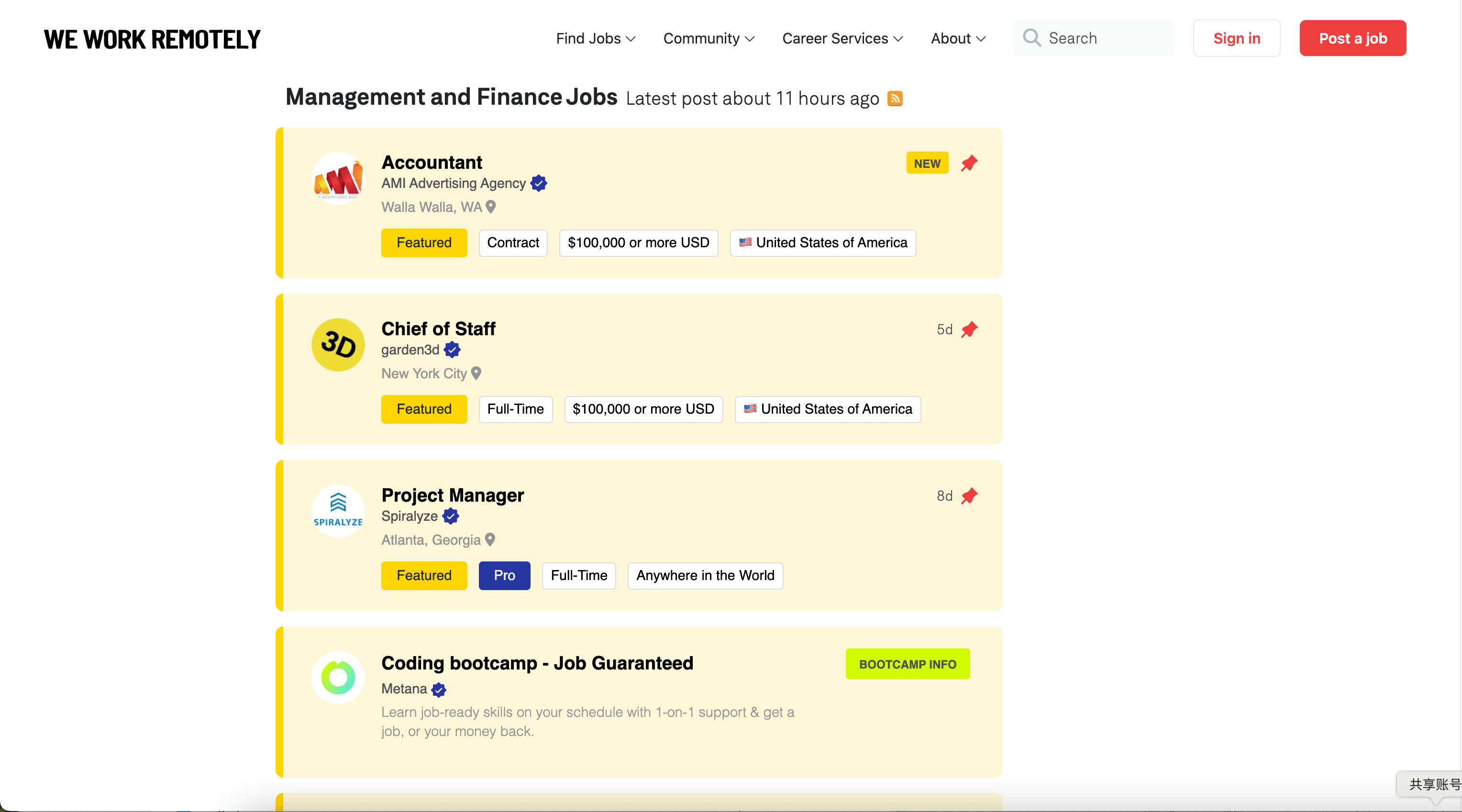
Alle Remote Jobs von We Work Remotely scrapen
In diesem Szenario scrapest du das zentrale Verzeichnis: . Ideal, wenn du möglichst viele Kategorien und Unternehmen abdecken willst – und anschließend optional jede Zeile über die Detailseite anreicherst.
Schritte:
- Lade die herunter und registriere ein Konto.
- Öffne die Zielseite, z. B.: https://weworkremotely.com/remote-jobs
- Klicke auf AI Suggest Columns – Thunderbit schlägt passende Spaltennamen vor.
- Klicke auf Scrape, um den Scraper auszuführen, Daten zu sammeln und die Datei herunterzuladen.
Spaltennamen
| Spalte | Beschreibung |
|---|---|
| 🧾 Jobtitel | Die Rollenbezeichnung in der Liste (z. B. „Senior Backend Engineer“). |
| 🏢 Unternehmen | Der Firmenname, der zur Anzeige gehört. |
| 📍 Standort / Region | Standort-Hinweise wie „Worldwide“, „nur USA“ oder regionale Einschränkungen. |
| 🏷️ Tags / Kategorie | Labels wie Programming, Design, Marketing oder andere Tags aus der Liste. |
| 🗓️ Veröffentlichungsdatum | Datum (oder relative Angabe), wann der Job gepostet wurde – sofern verfügbar. |
| 🔗 Job-URL | Link zur Detailseite (praktisch für Subpage Scraping). |
| 🖼️ Unternehmenslogo-URL | Link zum Logo-Bild, falls in der Liste vorhanden. |
| 🧩 Kurzbeschreibung | Kurzer Teaser/Preview-Text, der in der Übersicht angezeigt wird. |
Tipp: Nach dem Scrape der Übersicht kannst du mit Scrape Subpages jede Job-URL besuchen und Felder wie vollständige Beschreibung, Anforderungen, Gehalt (falls vorhanden) und den Bewerbungslink ergänzen.
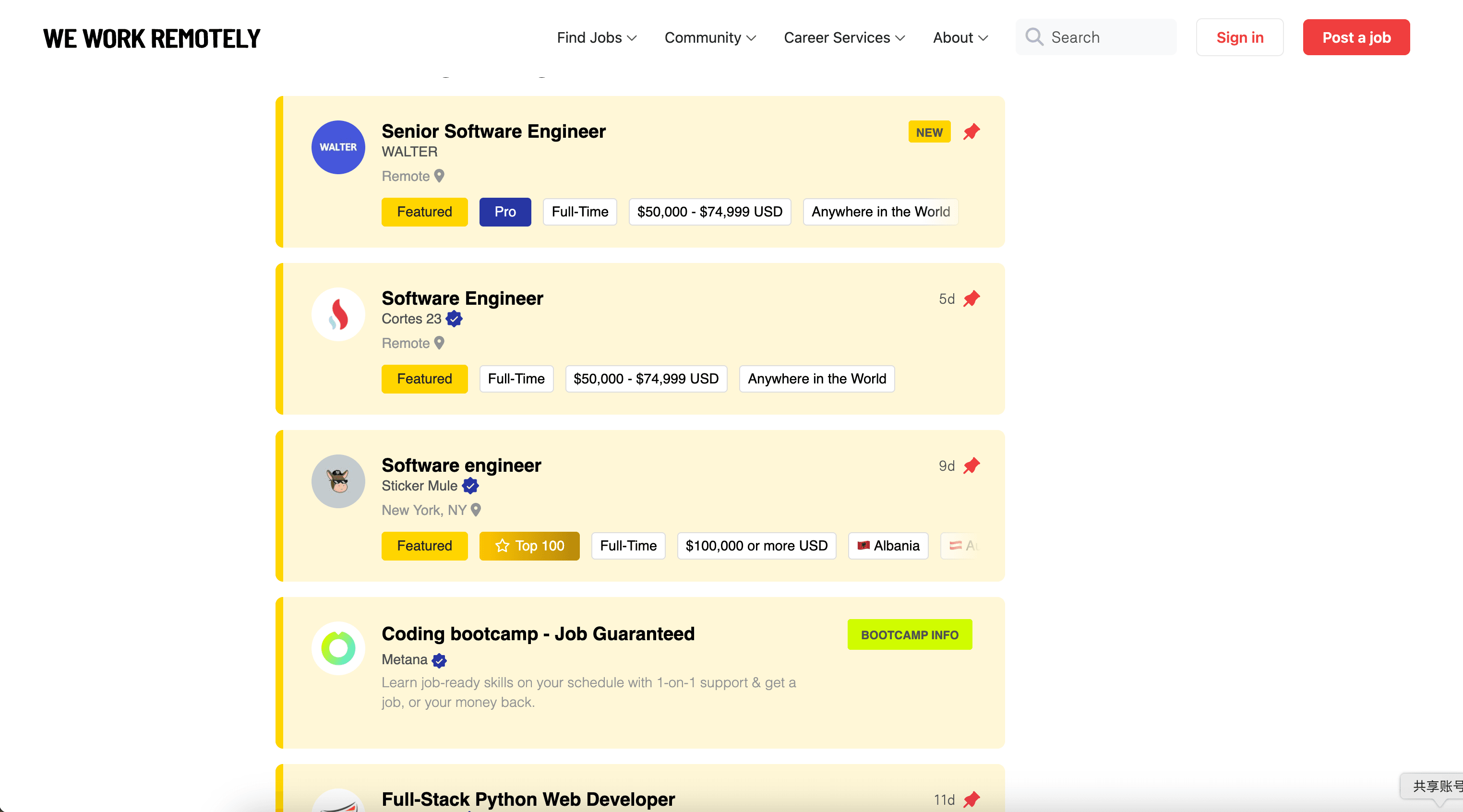
Remote Programming Jobs von We Work Remotely scrapen
Dieses Szenario zielt auf eine konkrete Kategorie: . Das ist ideal, wenn du nur Engineering-Rollen brauchst und dir späteres Filtern sparen willst.
Schritte:
- Lade die herunter und registriere ein Konto.
- Öffne die Zielseite, z. B.: https://weworkremotely.com/categories/remote-programming-jobs
- Klicke auf AI Suggest Columns – Thunderbit empfiehlt Spaltennamen.
- Klicke auf Scrape, um den Scraper zu starten, Daten zu erhalten und die Datei herunterzuladen.
Spaltennamen
| Spalte | Beschreibung |
|---|---|
| 💻 Jobtitel | Der Titel der Programmierrolle, wie er auf der Kategorieseite angezeigt wird. |
| 🏢 Unternehmen | Das einstellende Unternehmen. |
| 🌎 Standort / Zeitzone | Anforderungen wie Land, Region oder Zeitzonen-Overlap. |
| 🧠 Tech / Tags | Tags, die Stack, Seniorität oder Jobtyp markieren – sofern angezeigt. |
| 🗓️ Veröffentlichungsdatum | Datum oder relative Zeitangabe der Veröffentlichung. |
| 🔗 Job-URL | Link zur Detailseite, um per Subpage Scraping anzureichern. |
| 🧾 Kategorie | Kategoriename (hilfreich, wenn du mehrere Kategorien zusammenführst). |
| 📝 Notizen (KI) | Optional: per Field AI Prompt die Rolle zusammenfassen oder klassifizieren (z. B. Backend/Frontend/Full-stack). |
🎯 Warum das We Work Remotely Tool nutzen
Wenn du We Work Remotely scrapest, machst du aus einem schnelllebigen Jobboard einen Datensatz, den du durchsuchen, filtern und in Prozesse überführen kannst.
Typische Gründe, warum Teams We Work Remotely scrapen:
- Recruiting & Talent Sourcing: Pipeline mit Remote-hirenden Unternehmen aufbauen, neue Postings verfolgen und Rollen nach Region, Stack oder Seniorität priorisieren.
- Sales & Partnerschaften: Schnell wachsende Remote-first-Unternehmen identifizieren und Leads mit Hiring-Signalen anreichern (Hiring = Budget und Dringlichkeit).
- Marktforschung: Hiring-Trends nach Kategorie (Programming vs. Design), Standort-Einschränkungen und Rollenhäufigkeit über die Zeit beobachten.
- Jobsuchende & Career Coaches: Persönlichen Job-Tracker in Google Sheets oder Notion erstellen, Duplikate entfernen und neue Posts im Blick behalten.
- Ecommerce- und Ops-Teams mit Bedarf an Tech-Talent: Laufende Liste relevanter Engineering-Rollen für die eigene Nische pflegen.
Der Vorteil von Thunderbit: Es ist für Business-Workflows gebaut. Der KI-Web-Scraper (https://thunderbit.com/) strukturiert die Daten automatisch, und Subpage Scraping reichert jede Zeile an – ohne dass du komplexe Crawler bauen musst.
Wenn du mehr Hintergrund zu modernen Scraping-Workflows suchst, helfen diese Guides:
🧩 So nutzt du die We Work Remotely Chrome Extension
- Thunderbit Chrome Extension installieren: Hol sie dir im und erstelle dein Konto bei .
- Zu einer We Work Remotely-Seite navigieren: Öffne entweder die Seite oder die Kategorie .
- KI-Scraper aktivieren: Klicke auf AI Suggest Columns, um Spaltennamen, Datentypen und optionale Field AI Prompts zu erzeugen. Du kannst Spalten umbenennen oder neue hinzufügen, z. B. „Seniority“ oder „Comp Range (if listed)“.
- Scrapen und anreichern: Klicke auf Scrape, um Zeilen zu sammeln. Nutze danach Scrape Subpages, um jede Job-URL zu öffnen und vollständige Beschreibungen, Bewerbungslinks und weitere Details zu extrahieren.
Pro-Workflow: Exportiere nach Google Sheets für Zusammenarbeit – oder nach Airtable/Notion, wenn du eine leichte ATS-ähnliche Datenbank willst. Exporte sind kostenlos.
💳 Preise für We Work Remotely
Thunderbit nutzt ein einfaches Credit-System:
- 1 Credit = 1 Ausgabezeile (eine Jobanzeige-Zeile in deiner Ergebnistabelle).
- Das KI-gestützte Scraping ist enthalten, und Datenexport ist kostenlos (CSV/JSON, Excel, Google Sheets, Airtable, Notion).
Was du kostenlos testen kannst:
- Free-Tier: 6 Seiten pro Monat scrapen.
- Free-Trial: 10 Seiten kostenlos scrapen – ideal, um Listing + Subpage-Anreicherung auf We Work Remotely zu testen.
Typische Kosten pro Run (Beispiel):
- Wenn du 5 Listing-Seiten scrapest und insgesamt 80 Jobzeilen erhältst, sind das 80 Credits.
- Wenn du diese 80 Jobs anschließend per Subpage Scraping anreicherst und pro Job eine angereicherte Zeile ausgibst, zählen in der Regel weiterhin die ausgegebenen Zeilen. Plane deine Credits daher nach der Anzahl der Jobzeilen, die du am Ende in deiner Tabelle haben möchtest.
Bezahlpläne (monatlich und jährlich) skalieren mit deinem Volumen. Die Jahresoption ist meist am günstigsten, wenn du regelmäßig scrapest. Details findest du unter .
| Stufe | Preis (monatlich) | Preis (jährlich) | Jahresgesamtpreis | Credits (monatlich) | Credits (jährlich) |
|---|---|---|---|---|---|
| Free | Free | Free | Free | 6 Seiten | N/A |
| Starter | $15 | $9 | $108 | 500 | 5,000 |
| Pro 1 | $38 | $16.5 | $199 | 3,000 | 30,000 |
| Pro 2 | $75 | $33.8 | $398 | 6,000 | 60,000 |
| Pro 3 | $125 | $68.4 | $796 | 10,000 | 120,000 |
| Pro 4 | $249 | $137.5 | $1,592 | 20,000 | 240,000 |
❓ FAQ
-
Was ist der KI-gestützte We Work Remotely Scraper?
Der KI-gestützte We Work Remotely Scraper ist ein Workflow in Thunderbit, der Jobanzeigen und Jobdetails von We Work Remotely extrahiert und in eine strukturierte Tabelle umwandelt. Du kannst Übersichtsseiten scrapen und anschließend jede Zeile durch das Besuchen der Detailseiten per Subpage Scraping anreichern. -
Was ist Thunderbit?
ist eine KI-Web-Scraper Chrome Extension, mit der du strukturierte Daten aus Websites, PDFs und Bildern ohne Programmierung extrahieren kannst. Sie richtet sich an Business-User, die schnell starten, zuverlässig extrahieren und unkompliziert in Tools wie Google Sheets, Airtable und Notion exportieren möchten. -
Brauche ich Programmierkenntnisse, um We Work Remotely zu scrapen?
Nein. Du klickst auf AI Suggest Columns, und Thunderbits KI schlägt anhand der Seite passende Felder vor. Du kannst die Spalten in normaler Sprache anpassen und dann auf Scrape klicken. -
Kann Thunderbit auch Jobbeschreibungen und Bewerbungslinks scrapen?
Ja. Nach dem Scrape der Übersichtsseite kannst du mit Subpage Scraping jede Detailseite öffnen und Felder wie vollständige Beschreibung, Aufgaben, Anforderungen und die Bewerbungs-URL extrahieren. Das ist besonders hilfreich, wenn in der Liste nur Titel und Unternehmen stehen. -
Wie funktioniert Pagination auf We Work Remotely-Seiten?
Thunderbit unterstützt Pagination-Scraping sowohl für klickbasierte Seitennavigation als auch für lange Scroll-Listen – je nachdem, wie die Website aufgebaut ist. Wenn das Jobverzeichnis über mehrere Seiten geht, kannst du mehrere Seiten in einem Run scrapen und alles in einer Tabelle ausgeben. -
Welche Daten kann ich exportieren und wohin?
Du kannst als CSV/JSON exportieren, für Excel herunterladen oder direkt an Google Sheets, Airtable oder Notion senden. Der Export ist kostenlos – ideal für einen gemeinsamen Job-Tracker oder eine durchsuchbare Datenbank. -
Was ist der Unterschied zwischen Cloud Scraping und Browser Scraping bei Jobboards?
Cloud Scraping ist meist schneller und kann viele Seiten stapelweise verarbeiten – praktisch für öffentliche Joblisten. Browser Scraping läuft in deiner Chrome-Session und ist besser, wenn eine Seite Login benötigt oder Inhalte abhängig von deiner lokalen Session lädt. -
Wie viele Jobs kann ich mit dem Free-Plan scrapen?
Der Free-Plan wird nach Seiten gemessen, nicht nach Jobs: Du kannst 6 Seiten pro Monat scrapen. Wenn pro Seite viele Jobzeilen enthalten sind, bekommst du trotzdem einen brauchbaren Datensatz. Zusätzlich kannst du mit dem Free-Trial 10 Seiten scrapen, um deinen Workflow zu testen. -
Ist es okay, We Work Remotely für Recruiting oder Research zu scrapen?
Das Scrapen öffentlicher Webseiten ist für Research und Business Intelligence verbreitet. Du solltest jedoch immer geltende Gesetze beachten, Privatsphäre respektieren und die Nutzungsbedingungen der Website prüfen. Für produktive Workflows empfiehlt sich eine angemessene Scrape-Frequenz und ein verantwortungsvoller Umgang mit den Daten.
📚 Mehr erfahren
- Extension holen:
- Produkt & Use Cases:
- Weitere Tutorials:
- Praktische Guides:
Bereit, mit dem KI-Web-Scraper (https://thunderbit.com/) einen sauberen Remote-Jobs-Datensatz aus We Work Remotely aufzubauen? Installiere Thunderbit, öffne die gewünschte Jobseite, klicke auf AI Suggest Columns und anschließend auf Scrape.