Einfacher Reddit Scraper











Reddit-Daten in zwei Klicks freischalten
Reddit-Daten in zwei Klicks extrahieren
Genervt von komplizierten Scrapern, die Programmierkenntnisse verlangen? Mit Thunderbit extrahieren Sie Reddit-Daten — Beitragstitel, Texte, Autoren, Subreddits und Upvotes — in nur zwei Klicks. Zeigen Sie einfach auf die gewünschten Daten, und Thunderbit erkennt die Felder sofort und zieht sie heraus. Kein Code, keine CSS-Selektoren, kein Stress.
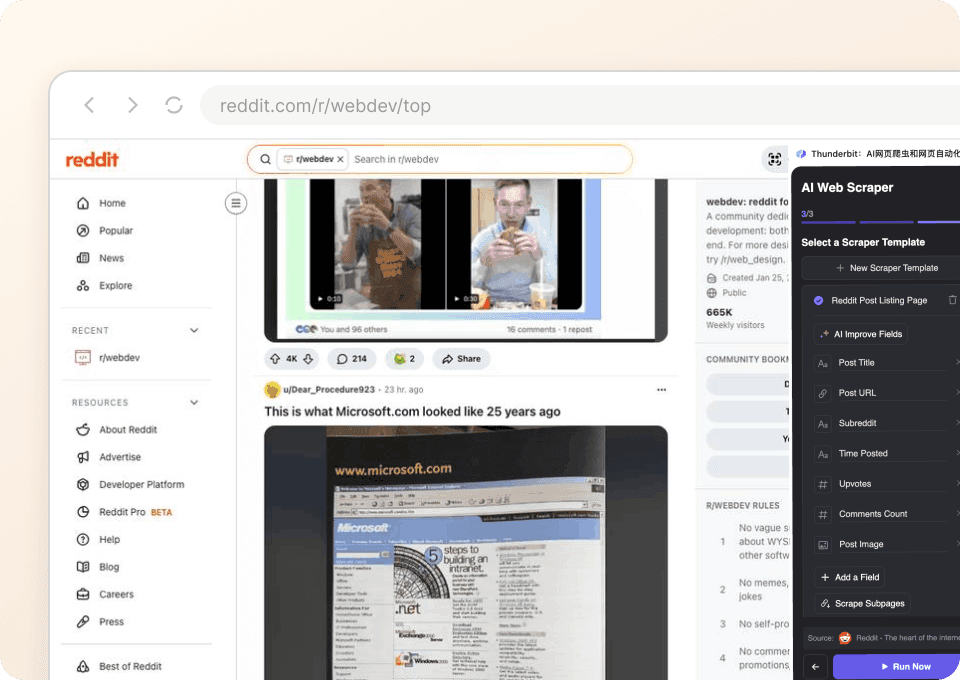
Passt sich an Layout-Änderungen bei Reddit an
Das Layout von Reddit ändert sich häufig, und die meisten Scraper scheitern daran. Thunderbit nutzt semantische KI, um Seiteninhalte nach Bedeutung zu verstehen — nicht über feste Selektoren. Wenn Reddit sein Design aktualisiert, passt sich Thunderbit automatisch an und sorgt dafür, dass Ihre Beitragsdaten, Autoreninfos und Subreddit-Details ohne Unterbrechung weiterlaufen.
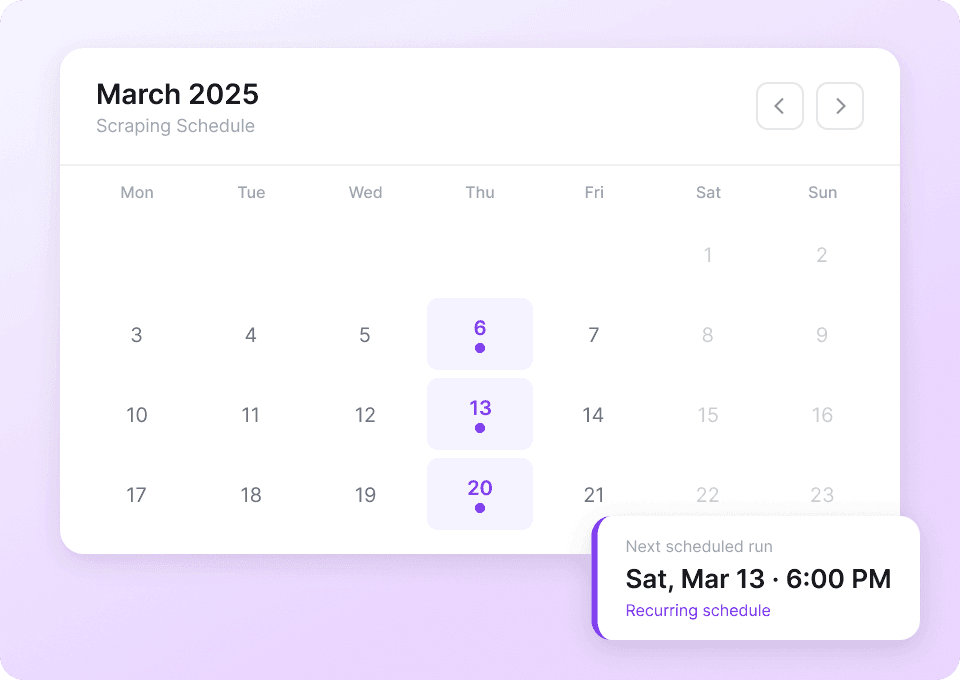
Reddit-Datenerfassung automatisieren
Reddit-Daten ändern sich ständig — neue Posts, neue Upvotes, neue Kommentare. Mit Thunderbit können Sie wiederkehrende Erfassungsaufgaben planen, sodass Ihre neuesten Beitragstitel, Upvotes und Thread-Daten automatisch direkt in Google Sheets, Notion oder Airtable landen. Einmal eingerichtet, bleiben Ihre Daten immer aktuell.
Genug von Reddit-Scraping-Problemen?
Sehen Sie, warum Thunderbit der einfachste Weg ist, Redfin-Daten zu extrahieren.
Klassische Scraper
Die alte VorgehensweiseThunderbit
Der intelligentere AnsatzVerlass dich nicht nur auf unser Wort
Lies, was unsere Nutzer über Thunderbit sagen.






Häufig gestellte Fragen
Ähnlich Anwendungsfälle
Entdecke weitere Anwendungsfälle von Thunderbits Web Scraper.

Rakuten Travel Scraper
Mit dem Thunderbit Rakuten Travel Web-Scraper können Sie Daten aus Hotelangeboten und Detailseiten von Rakuten Travel extrahieren. Dank KI-gestützter Feldvorschläge erfassen Sie schnell Hotelnamen, Preise, Bewertungen, Zimmertypen und Ausstattungen – ideal für Recherchen oder Reiseplanung. Perfekt für Reisebüros, Analysten und Unternehmen, die strukturierte Reisedaten benötigen.
Mehr erfahren ->
Amarillas.com Scraper
Mit dem Thunderbit Amarillas.com-Scraper können Sie strukturierte Daten von Amarillas.com extrahieren, darunter Einträge von Motels und Restaurants. Dank KI-gestützter Feldvorschläge sammeln Sie im Handumdrehen Firmennamen, Standorte, Kontaktnummern, Bewertungen und Rezensionen – ideal für Recherche, Marketing oder Lead-Generierung.
Mehr erfahren ->
UNIQLO Web-Scraper
Erfassen Sie Uniqlo-Produktnamen, Preise, Farben und Größen mit Thunderbits KI-gestützter Chrome-Erweiterung in nur 2 Klicks. Exportieren Sie die Daten direkt nach Google Sheets, Excel oder Notion und halten Sie Ihre Produktrecherche jederzeit auf dem neuesten Stand.
Mehr erfahren ->
Herold-Scraper
Mit dem Thunderbit Herold-Scraper können Sie Daten aus den Geschäfts- und Personensuchergebnissen von Herold in nur zwei Klicks extrahieren. Dank KI-gestützter Feldvorschläge erfassen Sie gezielt Firmennamen, Adressen, Telefonnummern, E-Mail-Adressen und mehr – perfekt für Leadgenerierung, Recherche oder Marketing. Ideal für Vertriebsteams, Marketer und Forschende, die strukturierte Herold-Daten benötigen.
Mehr erfahren ->
BestPrice GR Web-Scraper
Mit dem KI-gestützten BestPrice GR Web-Scraper von Thunderbit können Sie Produktlisten, Preise und detaillierte Informationen von BestPrice.gr in wenigen Klicks extrahieren. Ideal für Vertriebs-, Marketing- und E-Commerce-Teams, die schnell und effizient strukturierte Daten benötigen.
Mehr erfahren ->
HKTVmall Web-Scraper
Produktnamen, Preise, Bewertungen und mehr aus HKTVmall-Angeboten in nur 2 Klicks extrahieren — ganz ohne Programmierung. Exportieren Sie die Daten direkt nach Excel, Google Sheets oder Notion und verwandeln Sie HKTVmall-Daten in umsetzbare Erkenntnisse.
Mehr erfahren ->Bereit, deine Datenextraktion auf das nächste Level zu bringen?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Die kostenlose Testversion bietet unbegrenzte Credits für 8 Webseiten.



