

Der Reddit Post Web-Scraper ist ein leistungsstarkes Tool, um detaillierte Informationen aus Reddit-Beiträgen zu gewinnen. Mit diesem vorgefertigten Scraper lassen sich Daten wie Beitragstitel, Nutzernamen, Community-Details sowie Interaktionsmetriken wie Kommentar- und Upvote-Anzahl bequem erfassen.
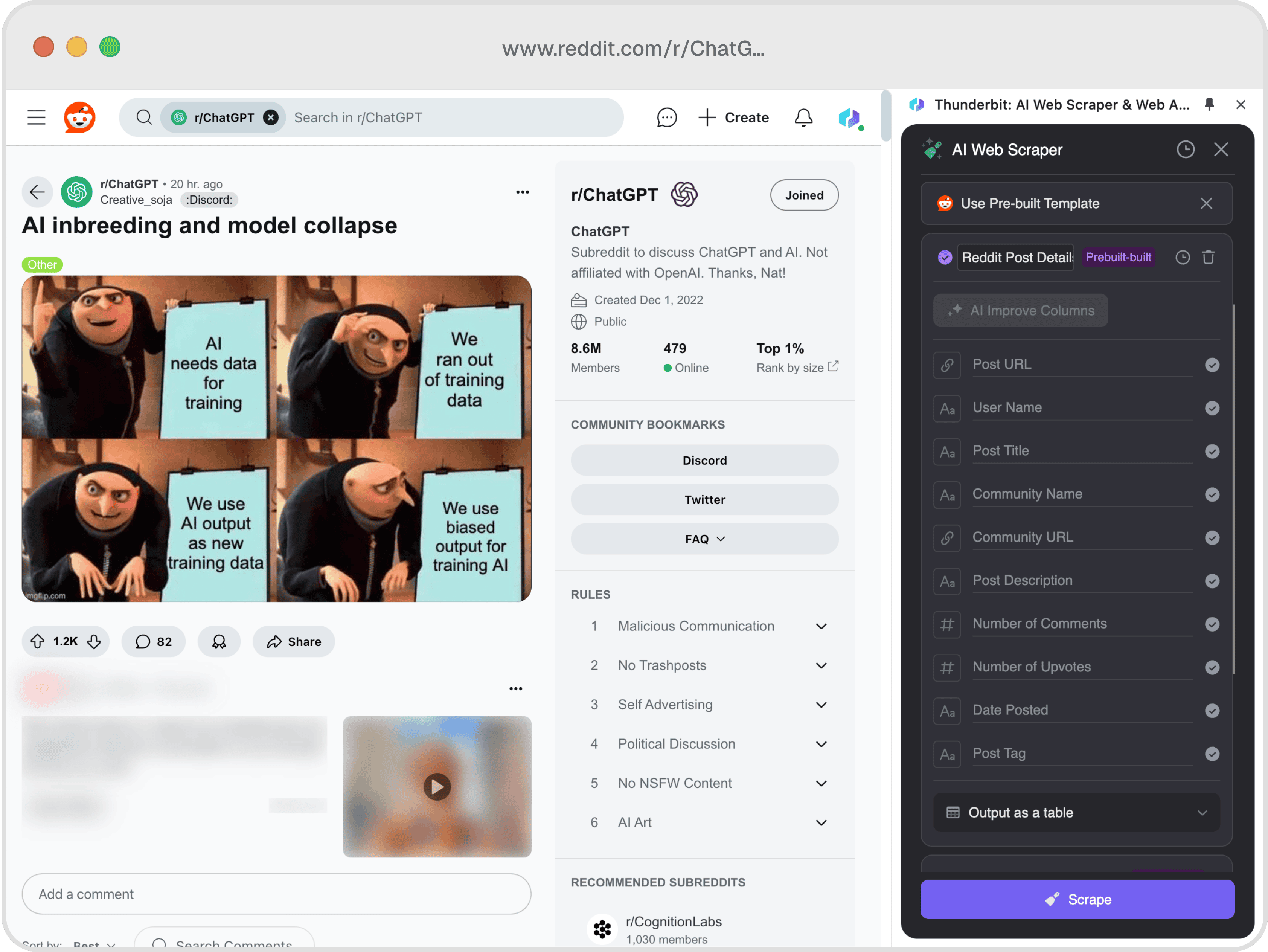
📊 Spaltenübersicht
| Spalte | Beschreibung |
|---|---|
| 🔗 Post-URL | Direkter Link zum Reddit-Beitrag. |
| 👤 Nutzername | Name des Users, der den Beitrag erstellt hat. |
| 📝 Beitragstitel | Titel des Reddit-Posts. |
| 🌐 Community-Name | Name des Subreddits, in dem der Beitrag veröffentlicht wurde. |
| 🔗 Community-URL | URL des Subreddits. |
| 📝 Beitragsbeschreibung | Inhalt oder Beschreibung des Beitrags. |
| 💬 Anzahl der Kommentare | Gesamtzahl der Kommentare zum Beitrag. |
| 👍 Anzahl der Upvotes | Gesamtzahl der Upvotes, die der Beitrag erhalten hat. |
| 📅 Veröffentlichungsdatum | Datum, an dem der Beitrag gepostet wurde. |
| 🏷️ Beitragstags | Zugeordnete Tags zum Beitrag. |
🤔 Warum Reddit-Daten extrahieren?
Das Scrapen von Reddit eröffnet vielfältige Möglichkeiten für Fachleute aus unterschiedlichen Bereichen:
- Marketing-Teams: Trends analysieren, Stimmungen der Nutzer erfassen und neue Themen entdecken, um Marketingstrategien gezielt zu optimieren.
- Forschende: Umfangreiche Datensätze für Studien sammeln, öffentliche Meinungen auswerten und Diskussionen zu Nischenthemen für wissenschaftliche oder branchenspezifische Analysen nutzen.
- Content Creators: Inspiration finden, Zielgruppen besser verstehen und Content-Ideen anhand populärer Diskussionen und Trends entwickeln.
- Produktentwickler: Nutzerfeedback, Probleme und Feature-Wünsche identifizieren, um Produkte oder Services gezielt zu verbessern.
- Social Media Analysten: Subreddit-Aktivitäten überwachen, Marken-Erwähnungen verfolgen, Wettbewerber analysieren oder das Community-Engagement messen.
Mit dem Scrapen von Reddit-Daten können Sie gezielt Informationen extrahieren und analysieren, um fundierte Entscheidungen zu treffen und Ihrer Konkurrenz einen Schritt voraus zu sein. 🚀
🛠️ So nutzen Sie den Reddit Post Web-Scraper
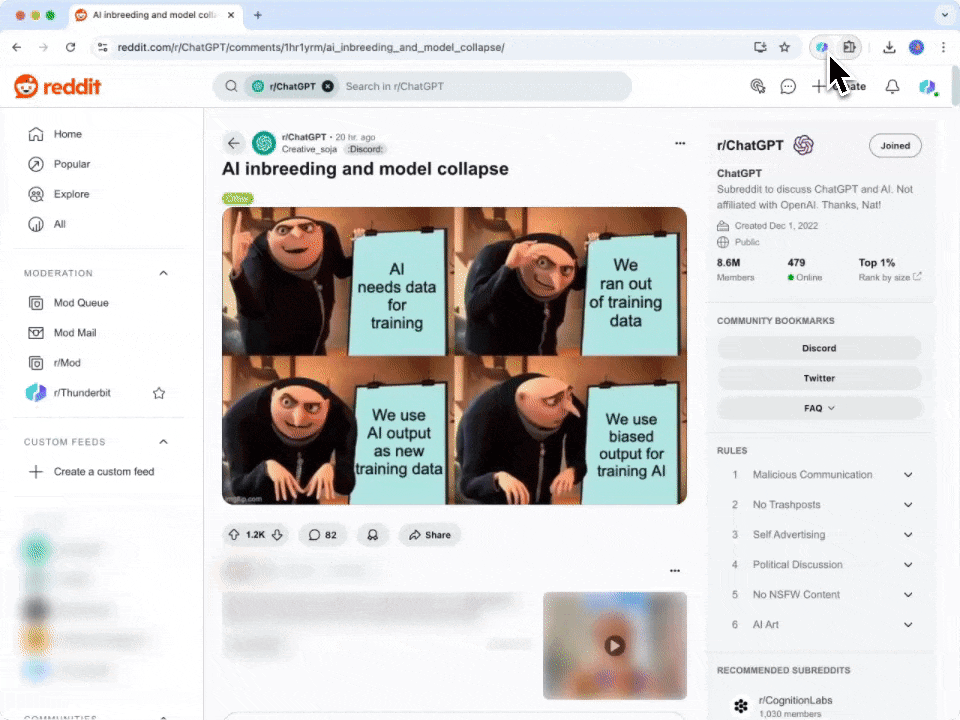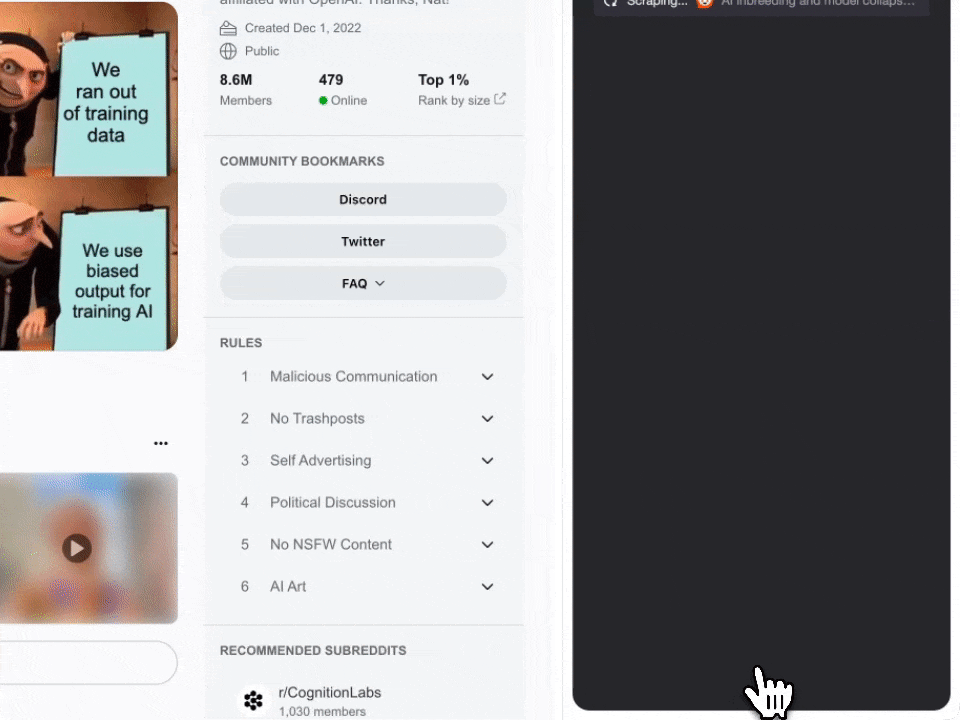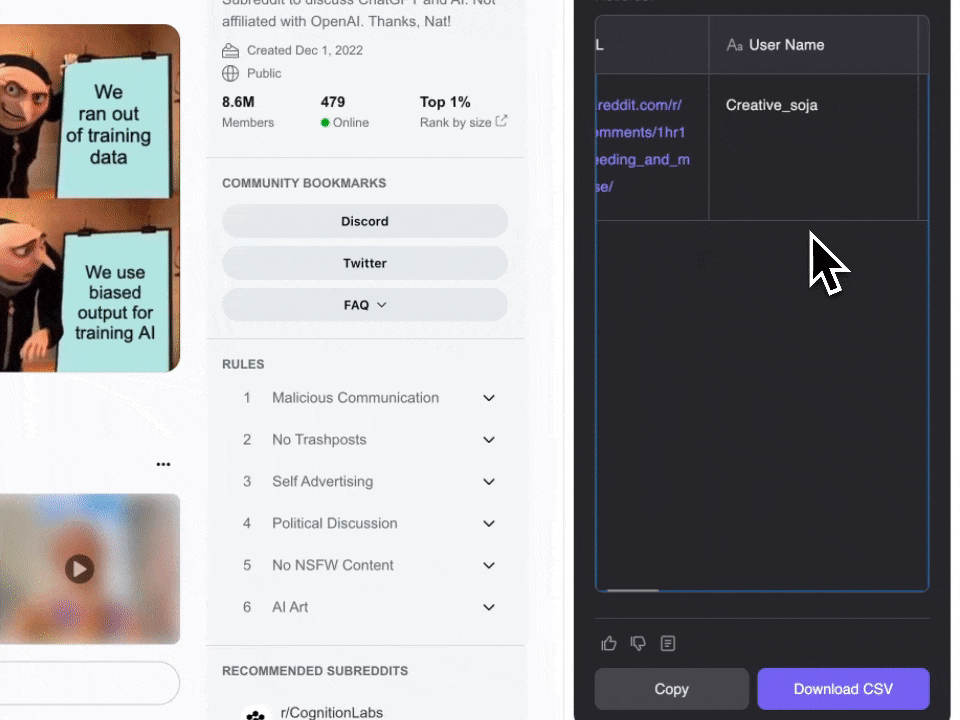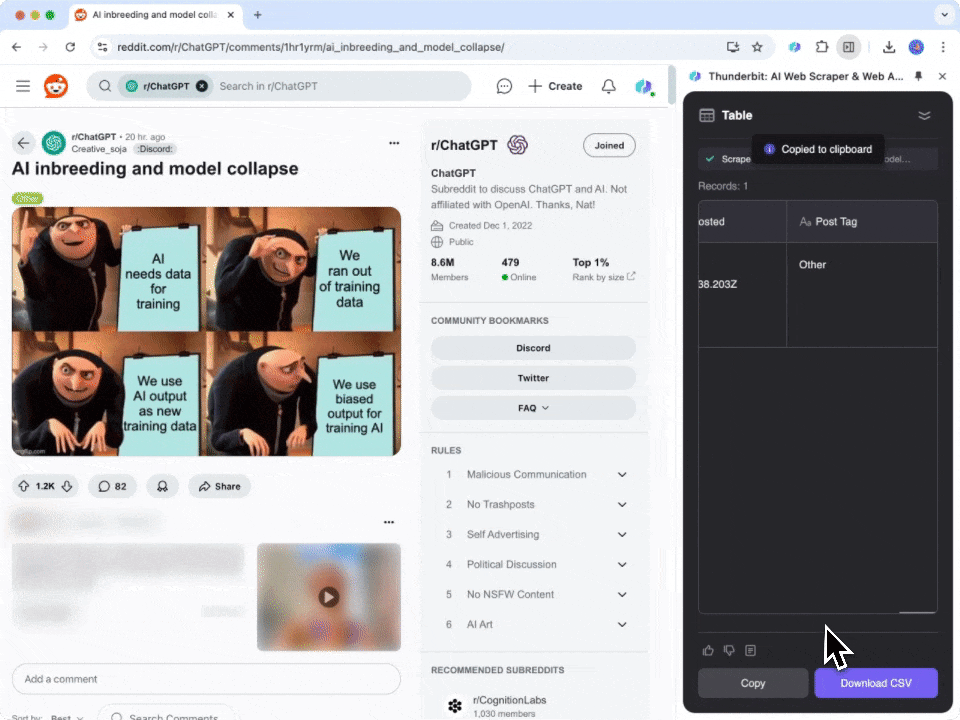
- Download & Installation: Laden Sie zunächst die herunter und registrieren Sie sich.
- Zu Reddit navigieren: Öffnen Sie den gewünschten oder die Subreddit-Seite, die Sie auslesen möchten.
- Scraper aktivieren: Es erscheint ein Popup, das Sie zur Nutzung der vorgefertigten Reddit Post Web-Scraper-Vorlage auffordert. Klicken Sie, um fortzufahren. Diese Funktion ist Teil des kostenpflichtigen Plans, aber Sie können mit einer kostenlosen Testphase starten und alle Features ausprobieren.
💰 Kosten des Reddit Post Web-Scrapers
Der Reddit Post Web-Scraper funktioniert auf Basis eines Credit-Systems: Jeder Durchlauf kostet 1 Credit. Mit der kostenlosen Testphase von Thunderbit können Sie bis zu 10 Seiten gratis auslesen. Ein Credit entspricht einer Ergebniszeile – so behalten Sie die Kosten stets im Blick.
🤖 Reddit mit KI extrahieren
Mit dem können Sie Reddit-Daten mit nur zwei Klicks erfassen. Das KI-gestützte Tool bietet Vorteile wie automatische Datenformatierung und Kategorisierung – ideal, wenn Sie schnell strukturierte Daten benötigen. Im Gegensatz zum vorgefertigten Scraper passt sich der KI-Web-Scraper flexibel an verschiedene Datenstrukturen an und ist besonders benutzerfreundlich.
❓ FAQ
- Was ist ein vorgefertigter Web-Scraper?
Ein vorgefertigter Web-Scraper ist ein sofort einsatzbereites Tool, das gezielt bestimmte Daten von Webseiten extrahiert – ganz ohne individuelle Konfiguration. Damit wird die Datenerfassung deutlich vereinfacht, da Sie ohne technisches Vorwissen oder Programmierkenntnisse direkt starten können. - Was ist Thunderbit?
Thunderbit ist eine Chrome-Erweiterung, mit der Sie Webaufgaben wie Datenerfassung, Formularausfüllung und Inhaltszusammenfassungen mithilfe von KI automatisieren können. Die Anwendung steigert Ihre Produktivität, indem sie wiederkehrende Online-Aufgaben effizient und benutzerfreundlich gestaltet – für Einsteiger und Profis gleichermaßen. - Wie funktioniert der Reddit Post Web-Scraper?
Der Reddit Post Web-Scraper nutzt eine vordefinierte Vorlage, um gezielt Daten aus Reddit-Beiträgen zu extrahieren. Sie navigieren einfach zur gewünschten Reddit-Seite, und der Scraper sammelt die relevanten Informationen automatisch – ganz ohne manuelle Datenerfassung. - Kann ich den Reddit Post Web-Scraper kostenlos nutzen?
Ja, Thunderbit bietet eine kostenlose Testphase, mit der Sie bis zu 10 Seiten gratis auslesen können. So können Sie die Funktionen risikofrei testen. Nach Ablauf der Testphase ist ein Abo erforderlich, um unbegrenzt Daten mit dem vorgefertigten Scraper zu extrahieren. - Welche Daten kann ich mit dem Reddit Post Web-Scraper erfassen?
Sie können verschiedene Datenpunkte wie Beitragstitel, Nutzernamen, Community-Details, Kommentaranzahl, Upvotes und mehr extrahieren. Diese umfassenden Daten eignen sich ideal für Analysen, Recherchen oder Content-Erstellung. - Sind die extrahierten Daten zuverlässig?
Ja, der Scraper ist darauf ausgelegt, die Daten aus Reddit-Beiträgen gemäß der Vorlage präzise zu erfassen. So erhalten Sie konsistente und verlässliche Ergebnisse für Ihre Datenauswertung. - Wie verwalte ich meine Credits bei Thunderbit?
Credits bestimmen, wie viele Daten Sie extrahieren können. Jeder Durchlauf des Reddit Post Web-Scrapers kostet 1 Credit. Ihre Credits verwalten Sie bequem im Thunderbit-Dashboard – dort behalten Sie den Überblick, können Credits nachkaufen und Ihre Scraping-Aufgaben effizient planen. - Kann ich die Datenfelder im Reddit Post Web-Scraper anpassen?
Der vorgefertigte Scraper bietet eine feste Auswahl an Datenfeldern für gängige Anwendungsfälle. Für mehr Flexibilität nutzen Sie den Thunderbit KI-Web-Scraper, mit dem Sie individuelle Extraktionsfelder nach Ihren Anforderungen definieren können.
📚 Mehr erfahren
Weitere Informationen zu Thunderbit und seinen Funktionen finden Sie auf der oder im mit Tutorials und Tipps.