Pixiv-Scraper
Vertraut von Profis bei führenden Unternehmen











Pixiv-Daten-Scraping leicht gemacht
Extrahiere Pixiv-Daten wie Überschriften, Autoren und Abschnittsdetails ohne manuelles Copy-Paste.
Pixiv-Daten in großem Umfang scrapen
Pixiv-Daten manuell Seite für Seite zu sammeln, wird schnell langsam – besonders wenn du Dutzende oder Hunderte von Überschriften, Artikelzusammenfassungen, Autoren, Veröffentlichungsdaten, Nachrichtenquellen und Abschnitten brauchst. Thunderbit lässt dich eine Liste von URLs in einem Durchgang scrapen, sodass du ohne Zeitverlust durch wiederholte Arbeit von wenigen Seiten zu einem großen Satz an Pixiv-Datensätzen wechseln kannst.

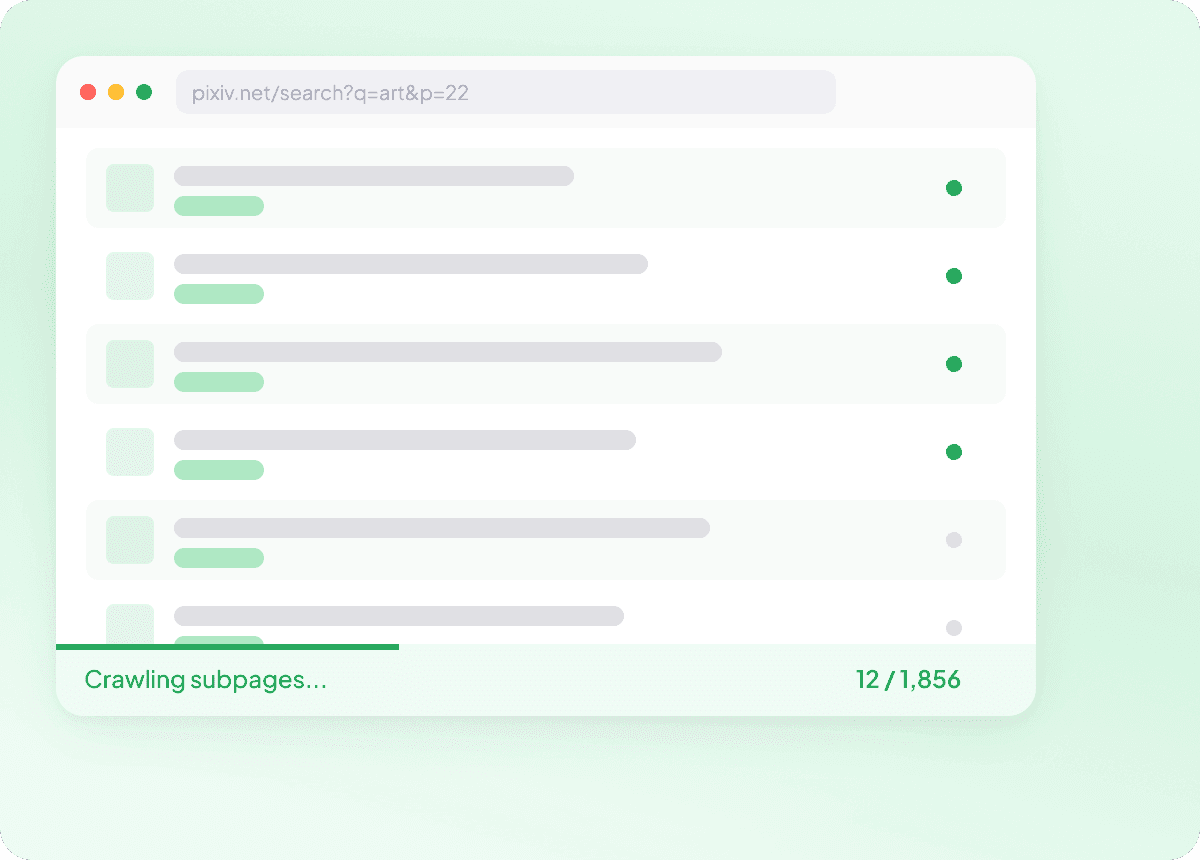
Alle Details von Pixiv-Unterseiten erfassen
Listenseiten auf Pixiv zeigen oft nur die Grundlagen, während die eigentlichen Details in jeder Artikel- oder Beitrags-Unterseite stecken. Thunderbit besucht jede verlinkte Unterseite und holt das vollständige Bild zurück, sodass du reichere Daten wie Artikelzusammenfassung, Autor, Veröffentlichungsdatum, Nachrichtenquelle und Abschnitt in einer sauberen Struktur erhältst.
Pixiv-Daten automatisch aktuell halten
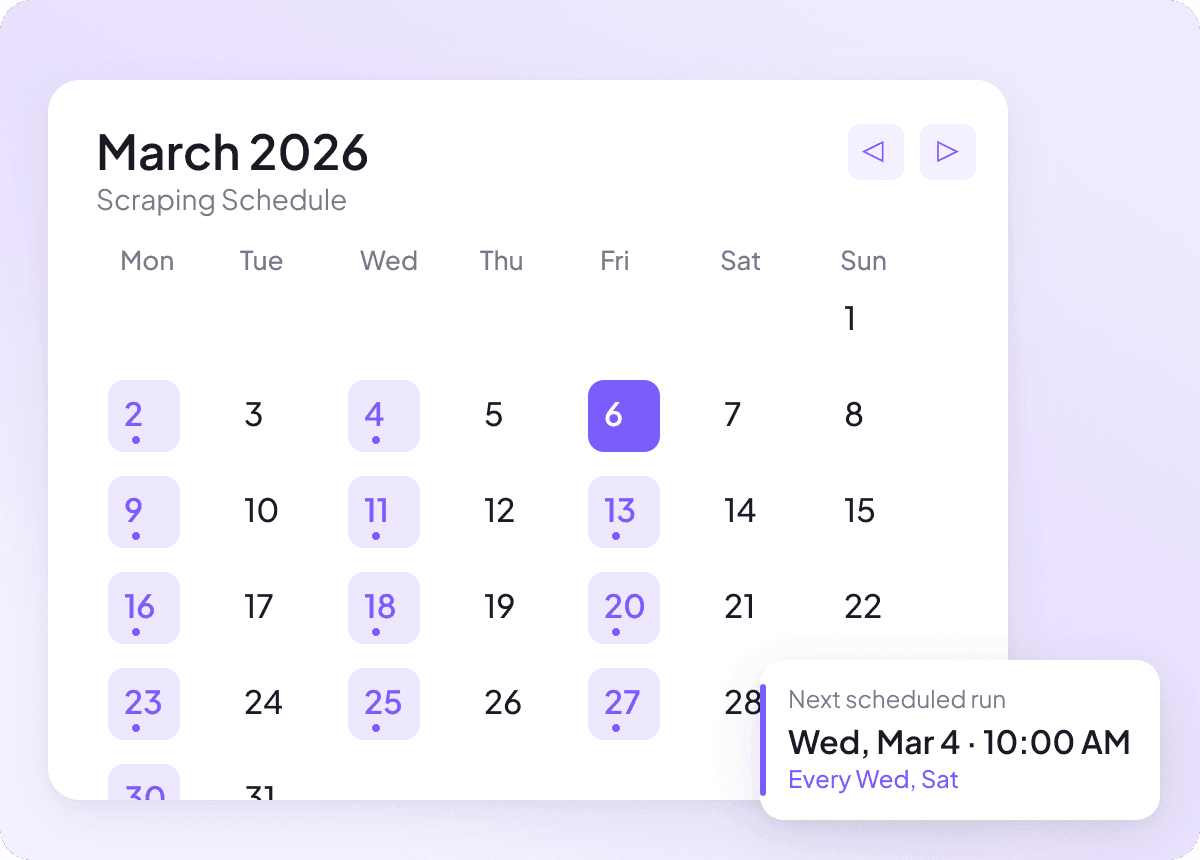
Pixiv-Inhalte können sich täglich ändern, und manuell Schritt zu halten bedeutet, dieselben Seiten immer wieder zu prüfen. Mit geplantem Scraping läuft Thunderbit automatisch und liefert regelmäßig frische Pixiv-Daten in deine Tabelle, damit dein Tracking von Überschrift, Autor und Abschnitt immer auf dem neuesten Stand bleibt, ohne dass du einen Finger rührst.
Warum unterscheidet sich Thunderbit von herkömmlichen Pixiv-Scrapern?
Ein einfacherer Weg, Pixiv ohne fragile Selektoren oder Nacharbeit zu scrapen.
Herkömmliche Scraper
Der alte WegThunderbit KI
Der intelligentere AnsatzVerlass dich nicht nur auf unser Wort
Lies, was unsere Nutzer über Thunderbit sagen.





Häufig gestellte Fragen
Ähnlich Anwendungsfälle
Entdecke weitere Anwendungsfälle von Thunderbits Web Scraper.
On the Beach Web-Scraper
Mit dem Thunderbit On the Beach Scraper können Sie Urlaubs- und Hotelangebote, Preise, Bewertungen und vieles mehr von On the Beach in nur zwei Klicks extrahieren. Dank KI-gestützter Feldvorschläge sammeln und strukturieren Sie Reisedaten im Handumdrehen – ideal für Analyse, Vergleich oder Reiseplanung. Perfekt für Reiseprofis, Analysten und Urlaubsplaner.
Mehr erfahren ->
Herold-Scraper
Mit dem Thunderbit Herold-Scraper können Sie Daten aus den Geschäfts- und Personensuchergebnissen von Herold in nur zwei Klicks extrahieren. Dank KI-gestützter Feldvorschläge erfassen Sie gezielt Firmennamen, Adressen, Telefonnummern, E-Mail-Adressen und mehr – perfekt für Leadgenerierung, Recherche oder Marketing. Ideal für Vertriebsteams, Marketer und Forschende, die strukturierte Herold-Daten benötigen.
Mehr erfahren ->
People-Search-Scraper
Mit dem Thunderbit People-Search-Scraper können Sie strukturierte Daten aus People-Search-Profilen und Seiten zur Rückwärtssuche von Telefonnummern extrahieren. Dank KI-gestützter Feldvorschläge erfassen Sie blitzschnell Namen, Orte, Telefonnummern, E-Mail-Adressen und mehr – ideal für Recherche, Marketing oder Lead-Generierung. Perfekt für Marketer, Analysten und Unternehmen, die öffentliche Kontaktdaten und Informationen benötigen.
Mehr erfahren ->
UNIQLO Web-Scraper
Erfasse Produktdaten von Uniqlo wie Namen, Preise und verfügbare Größen mit nur 2 Klicks – dank der Chrome-Erweiterung von Thunderbit.
Mehr erfahren ->
Tieba-Scraper
Mit dem Thunderbit Tieba Web-Scraper können Sie gezielt Daten aus Baidu Tieba erfassen – darunter aktuelle Trendthemen und Forenkategorien. Dank KI-gestützter Feldvorschläge sammeln Sie im Handumdrehen Themen, Links, Beitragszahlen und Nutzeraktivitäten – perfekt für Recherche, Marketing oder Content-Erstellung. Ideal, um Social-Media-Trends und Diskussionen auf Tieba zu analysieren.
Mehr erfahren ->
UpCity Scraper
Mit dem Thunderbit UpCity-Scraper können Sie Daten aus den Agentur-Listings und Anbieterbewertungen von UpCity extrahieren. Dank KI-gestützter Feldvorschläge erfassen Sie im Handumdrehen Agenturnamen, Standorte, Bewertungen, Kontaktdaten und ausführliche Rezensionen – ideal für Analysen oder Recherchen. Perfekt für Marketer, Forscher und Unternehmer, die strukturierte UpCity-Daten benötigen.
Mehr erfahren ->Bereit, deine Datenextraktion zu beschleunigen?
Schließe dich über 100.000 Profis an, die Thunderbit bereits nutzen, um ihre Web-Scraping-Workflows zu automatisieren.
Die kostenlose Testphase bietet unbegrenzte Credits für 8 Webseiten.