News-Scraper

Vertrauenswürdig für Profis in führenden Unternehmen











News-Daten schneller erfasst
Ziehe saubere News-Daten aus Artikeln, Listen und Quellen — ohne mühsame Handarbeit.
Erhalte die vollständigen Artikeldetails
News-Listingseiten liefern meist nur einen Teaser. Thunderbit besucht jede Artikelseite und holt das komplette Bild zurück, einschließlich Überschrift, Artikelzusammenfassung, Autor, Veröffentlichungsdatum, News-Quelle und Abschnitt. So kommst du mit weniger Schritten von einer einfachen Story-Liste zu einem vollständigen Datensatz.
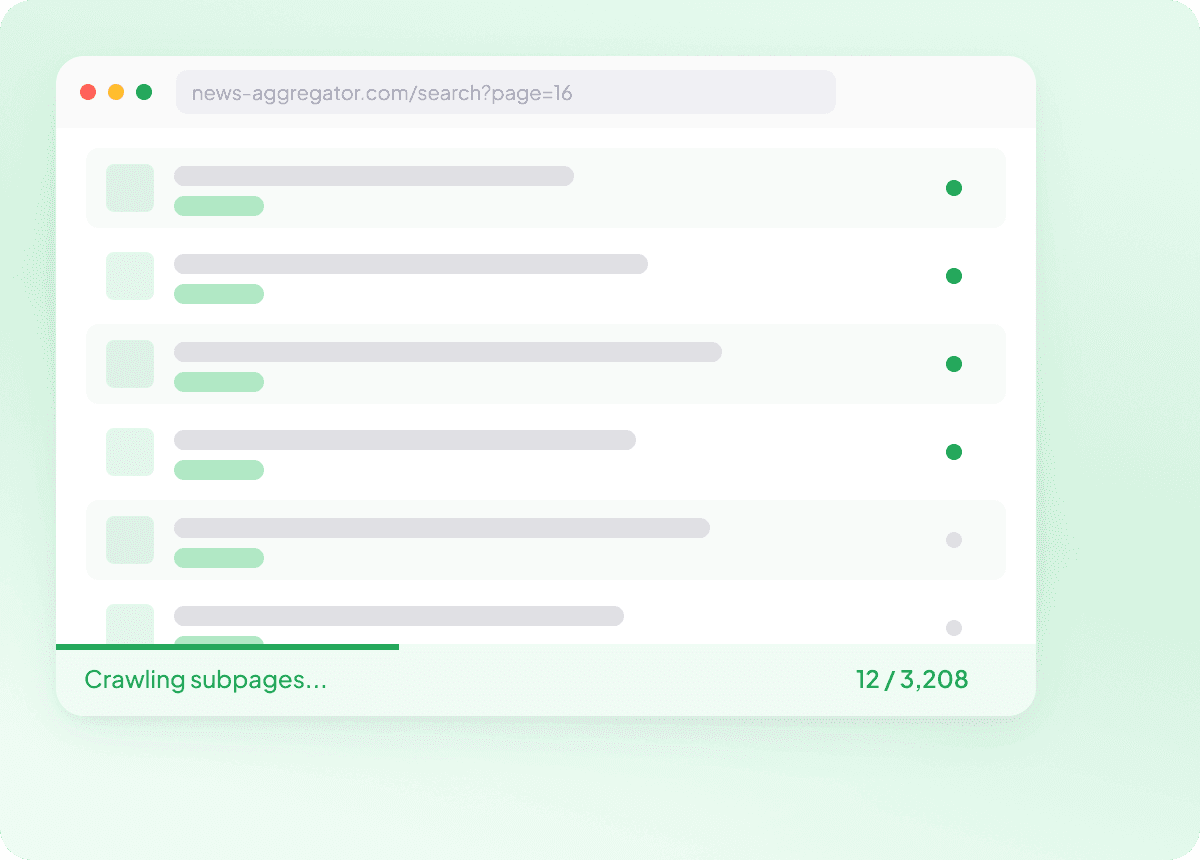
News-URL-Listen in großen Mengen scrapen
News Seite für Seite zu scrapen wird schnell langsam. Mit Thunderbit kannst du ihm eine Liste von Artikel-URLs geben und Hunderte von Seiten auf einmal in einem Durchlauf scrapen, sodass jede Story mit den benötigten Feldern erfasst wird. Das ist ein praktischer Weg, große News-Datensätze zu sammeln, ohne dieselbe Arbeit immer wieder zu wiederholen.

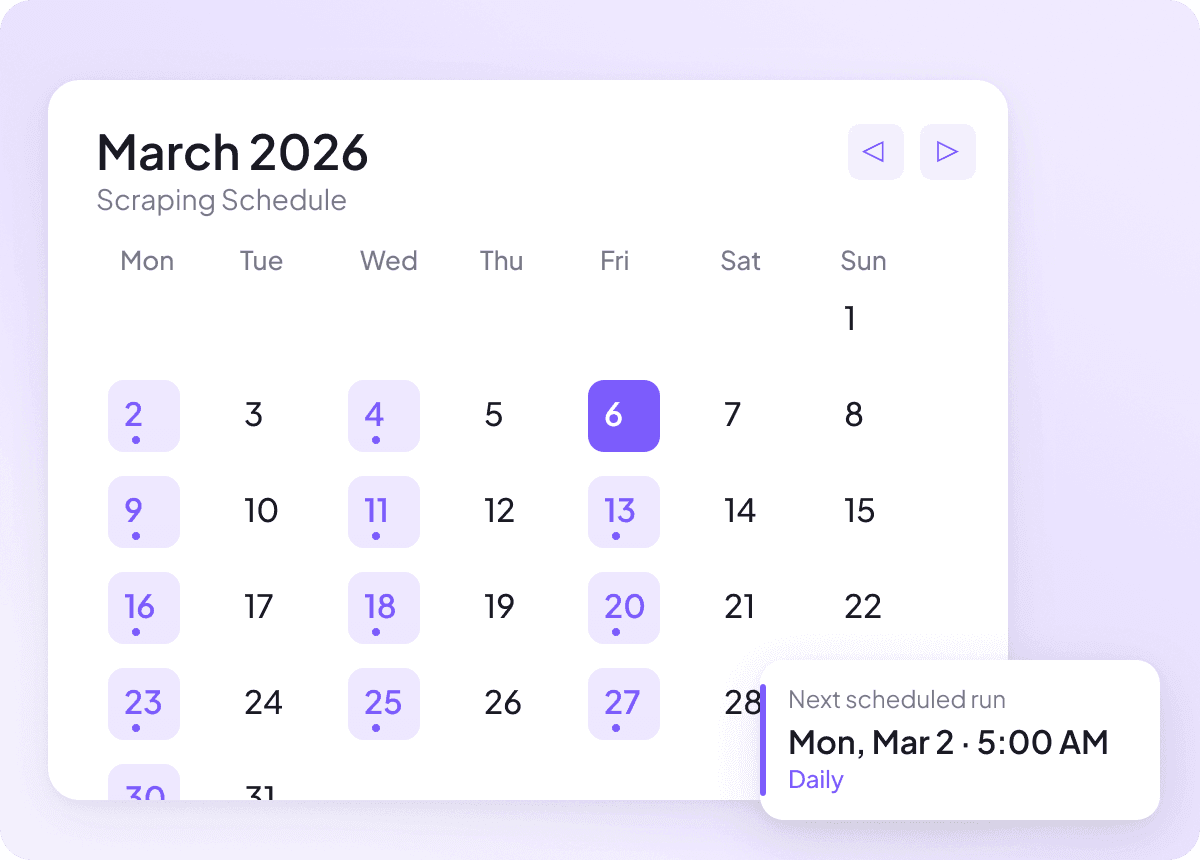
News-Daten aktuell halten
News ändert sich täglich, und veraltete Daten sind nutzlos. Richte geplantes Scraping ein, damit Thunderbit im Autopilot läuft und deine Tabelle mit frischen Überschriften, Zusammenfassungen, Autoren, Veröffentlichungsdaten, News-Quellen und Abschnitten aktualisiert. So erhältst du regelmäßige Updates, ohne den Termin selbst im Blick behalten zu müssen.
Warum unterscheidet sich Thunderbit von traditionellen News-Scrapern?
Ein schnellerer Weg, chaotische News-Daten ohne ständige Ausfälle zu sammeln.
Traditionelle Scraper
Die alte VorgehensweiseThunderbit KI
Der intelligentere AnsatzVerlass dich nicht nur auf unser Wort
Sieh dir an, was unsere Nutzer über Thunderbit sagen.





Häufig gestellte Fragen
Ähnlich Anwendungsfälle
Entdecke weitere Anwendungsfälle von Thunderbits Web-Scraper.

HKTVmall Web-Scraper
Mit nur wenigen Klicks Produktnamen, Preise und sogar Kundenbewertungen aus HKTVmall-Listings erfassen – ganz ohne komplizierte Einrichtung.
Mehr erfahren ->Substack-Scraper
Hole dir Abonnentenzahlen, Artikeltitel und Beschreibungen von Substack-Publikationen in eine saubere Tabelle – ganz ohne Code, die KI übernimmt die Strukturierung.
Mehr erfahren ->
TripAdvisor Unternehmenslisten-Scraper
Mit dem Thunderbit TripAdvisor Business Listings Scraper können Sie Daten aus den Geschäftseinträgen, dem Ressourcenbereich und dem Eigentümerforum von TripAdvisor extrahieren. Dank KI-gestützter Feldvorschläge sammeln Sie im Handumdrehen Ressourcennamen, URLs, Beschreibungen, Forenthemen, Autoren und Beiträge – ideal für Recherche, Marketing oder Analyse.
Mehr erfahren ->
Trustpilot-Scraper
Verwandle Trustpilot-Seiten in eine saubere Tabelle mit Bewertungen, Ratings und Namen der Rezensenten. Wir lesen jede Seite für dich, sodass kein Code und kein Copy-Paste nötig ist.
Mehr erfahren ->
Tieba-Scraper
Mit dem Thunderbit Tieba Web-Scraper können Sie gezielt Daten aus Baidu Tieba erfassen – darunter aktuelle Trendthemen und Forenkategorien. Dank KI-gestützter Feldvorschläge sammeln Sie im Handumdrehen Themen, Links, Beitragszahlen und Nutzeraktivitäten – perfekt für Recherche, Marketing oder Content-Erstellung. Ideal, um Social-Media-Trends und Diskussionen auf Tieba zu analysieren.
Mehr erfahren ->Tradera Web-Scraper
Mit dem Thunderbit Tradera Web-Scraper können Sie mühelos Daten aus Tradera-Angeboten und Produktseiten extrahieren. Dank KI-gestützter Feldvorschläge erfassen Sie Produktnamen, Preise, Kategorien, Bilder und Beschreibungen – ideal für Analysen oder die Bestandsverwaltung. Perfekt für Online-Händler, Sammler und Forscher, die strukturierte Tradera-Daten benötigen.
Mehr erfahren ->Bereit, deine Datenextraktion zu beschleunigen?
Schließe dich über 100.000 Profis an, die Thunderbit bereits nutzen, um ihre Web-Scraping-Workflows zu automatisieren.
Die kostenlose Testversion bietet unbegrenzte Credits für 8 Webseiten.