
Der Thunderbit KI-gestützte namu.wiki Scraper ist ein spezialisiertes Tool, das entwickelt wurde, um Daten von namu.wiki präzise und mühelos zu extrahieren. Mit der können Nutzer Webseiteninhalte in strukturierte Datensätze umwandeln und Daten mit nur zwei Klicks exportieren.
📚 Was ist der namu.wiki Scraper
Der Scraper ist ein KI-Web-Scraper, der es Nutzern ermöglicht, Daten von der namu.wiki-Website mithilfe künstlicher Intelligenz zu extrahieren. Indem man einfach zur navigiert, können Nutzer auf die Schaltfläche AI Suggest Columns und die Schaltfläche Scrape klicken, um wertvolle Daten effizient zu extrahieren.
🔍 Was kann man mit dem namu.wiki Scraper extrahieren
📄 NamuWiki Needed Pages Listing Page scrapen
Der KI-gestützte namu.wiki Scraper ermöglicht es Nutzern, detaillierte Informationen von der zu extrahieren. Diese Funktion ist ideal, um Einblicke in Seiten zu gewinnen, die Inhaltserstellung oder Aktualisierungen erfordern.
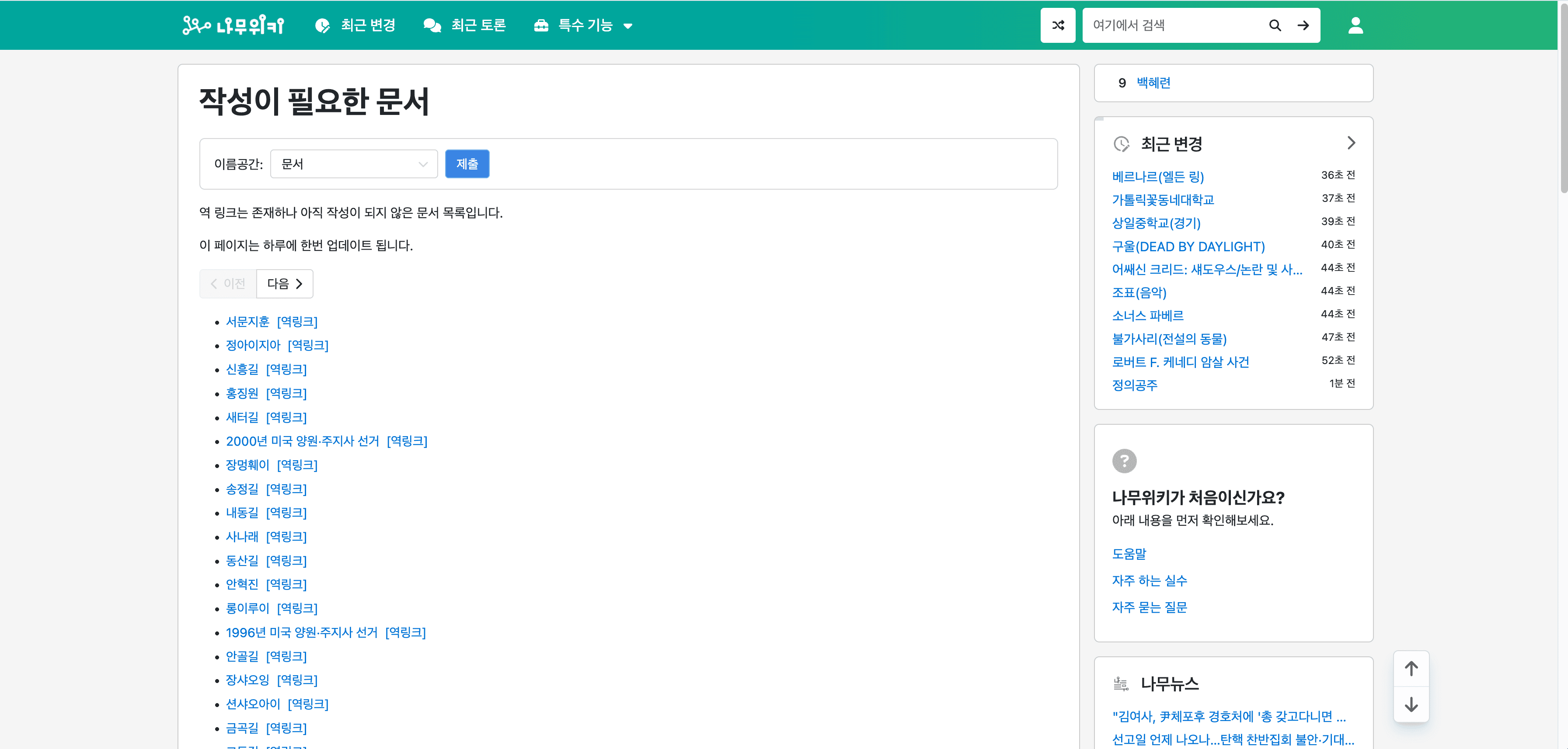
Schritte:
- Laden Sie die herunter und registrieren Sie ein Konto.
- Gehen Sie zur Zielseite, zum Beispiel: .
- Klicken Sie auf AI Suggest Columns, damit die KI die Webseite liest und Spaltennamen empfiehlt.
- Klicken Sie auf Scrape, um den Scraper auszuführen, Daten zu erhalten und die Datei herunterzuladen.
Spaltennamen
| Spalte | Beschreibung |
|---|---|
| 📄 Seitentitel | Der Titel der benötigten Seite. |
| 🔗 Seiten-URL | Der Link zur benötigten Seite. |
| 📅 Zuletzt bearbeitet | Das Datum, an dem die Seite zuletzt bearbeitet wurde. |
| ✍️ Editor | Der Benutzername des letzten Bearbeiters. |
💬 NamuWiki Recent Discussions Page scrapen
Der KI-gestützte namu.wiki Scraper ermöglicht es auch, Informationen von der zu extrahieren. Diese Funktion ist ideal, um laufende Diskussionen und Community-Interaktionen zu überwachen.
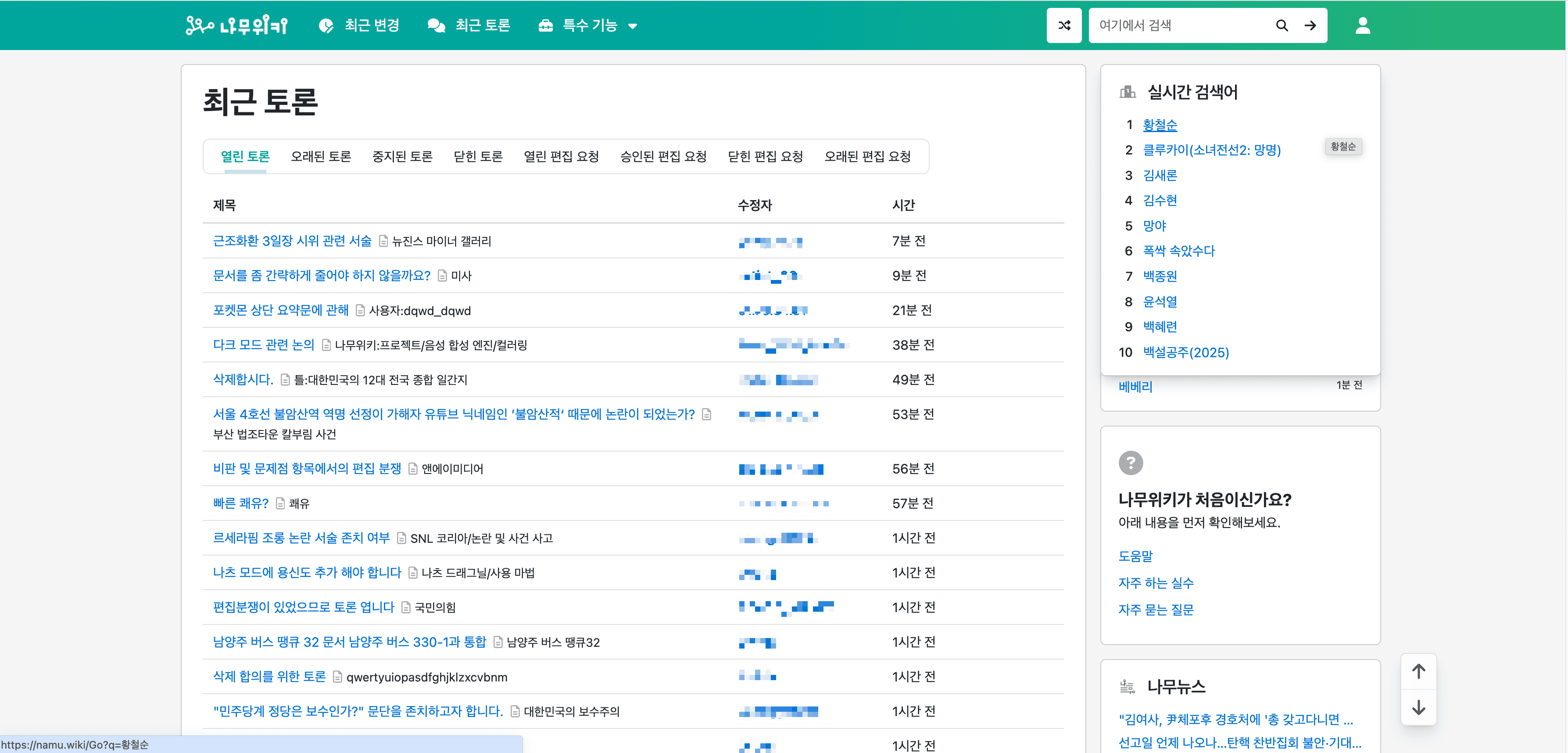
Schritte:
- Laden Sie die herunter und registrieren Sie ein Konto.
- Gehen Sie zur Zielseite, zum Beispiel: .
- Klicken Sie auf AI Suggest Columns, damit die KI die Webseite liest und Spaltennamen empfiehlt.
- Klicken Sie auf Scrape, um den Scraper auszuführen, Daten zu erhalten und die Datei herunterzuladen.
Spaltennamen
| Spalte | Beschreibung |
|---|---|
| 💬 Diskussionsthema | Das Thema der Diskussion. |
| 🔗 Diskussions-URL | Der Link zur Diskussionsseite. |
| 🕒 Letzte Aktivität | Der Zeitstempel der letzten Aktivität in der Diskussion. |
| 👤 Teilnehmer | Der Benutzername des Teilnehmers in der Diskussion. |
🤔 Warum das namu.wiki Tool verwenden
Das Scrapen von namu.wiki kann wertvolle Einblicke für verschiedene Zwecke bieten:
- Forscher: Analysieren von Inhaltslücken und Community-Interaktionen.
- Inhaltsersteller: Identifizieren von benötigten Seiten für die Inhaltserstellung.
- Community-Manager: Überwachen von Diskussionen und Interaktion mit der Community.
- Unternehmen: Extrahieren von strukturierten Daten für Marktforschung und Analyse.
Durch das Extrahieren genauer und gut organisierter Daten können Sie datengetriebene Entscheidungen treffen und neue Möglichkeiten erschließen.
🛠️ Wie man die namu.wiki Chrome-Erweiterung verwendet
- Installieren Sie die Thunderbit Chrome-Erweiterung: Laden Sie die Erweiterung herunter und registrieren Sie Ihr Konto.
- Navigieren Sie zur Needed Pages oder Recent Discussions Page: Gehen Sie zur namu.wiki-Seite, die Sie scrapen möchten.
- Aktivieren Sie den KI-gestützten Scraper: Klicken Sie auf AI Suggest Column, um Spaltennamen zu generieren oder passen Sie die Spalten an Ihre Bedürfnisse an.
💰 Preisgestaltung für den namu.wiki Scraper
Thunderbit arbeitet mit einem kreditbasierten System, wobei 1 Kredit einer gescrapten Zeile entspricht. Das Tool ist kostenlos auszuprobieren, und zusätzliche Pläne bieten Flexibilität für gelegentliche und intensive Nutzer.
Pläne:
| Stufe | Monatlicher Preis | Jährlicher Preis | Jährliche Gesamtkosten | Credits/Monat | Credits/Jahr |
|---|---|---|---|---|---|
| Kostenlos | Kostenlos | Kostenlos | Kostenlos | 6 Seiten | N/A |
| Starter | $15 | $9 | $108 | 500 | 5,000 |
| Pro 1 | $38 | $16.5 | $199 | 3,000 | 30,000 |
| Pro 2 | $75 | $33.8 | $406 | 6,000 | 60,000 |
| Pro 3 | $125 | $68.4 | $821 | 10,000 | 120,000 |
| Pro 4 | $249 | $137.5 | $1,650 | 20,000 | 240,000 |
Kostenlose Funktionen:
- 6 Seiten pro Monat im kostenlosen Plan.
- 10 Seiten kostenlos mit der kostenlosen Testversion, ideal zum Erkunden der Funktionen des Scrapers.
❓ FAQ
-
Was ist der KI-gestützte namu.wiki Scraper?
Der KI-gestützte namu.wiki Scraper ist ein spezialisiertes Werkzeug, das entwickelt wurde, um detaillierte Informationen von namu.wiki's benötigten Seiten und aktuellen Diskussionen zu extrahieren. Es vereinfacht die Datenerfassung durch die Nutzung der Thunderbit Chrome-Erweiterung, sodass Nutzer schnell und einfach strukturierte Daten für Forschung, Inhaltserstellung oder Analyse sammeln können, ohne technische Expertise zu benötigen.
-
Was ist Thunderbit?
Thunderbit ist eine fortschrittliche Chrome-Erweiterung, die Web-Scraping, Datenextraktion und Automatisierungsaufgaben mithilfe künstlicher Intelligenz vereinfacht. Sie ermöglicht es Nutzern, Daten von Websites zu scrapen, Spalten anzupassen, Online-Formulare automatisch auszufüllen und Inhalte zusammenzufassen. Thunderbit richtet sich an Fachleute in den Bereichen Marketing, E-Commerce, Forschung und mehr, indem es mühsame webbasierte Aufgaben schneller, einfacher und genauer macht.
-
Wie viele Seiten kann ich mit der kostenlosen Testversion scrapen?
Mit der kostenlosen Testversion von Thunderbit können Sie bis zu 10 Seiten kostenlos scrapen. Dies ermöglicht es Nutzern, die Fähigkeiten des Tools zu erkunden und zu entscheiden, ob es ihren Datenextraktionsanforderungen entspricht, bevor sie auf einen kostenpflichtigen Plan upgraden.
-
Kann ich die Spalten und Datenfelder anpassen, die gescrapt werden sollen?
Absolut! Thunderbit bietet robuste Anpassungsoptionen, mit denen Sie die genauen Datenfelder angeben können, die Sie extrahieren möchten. Von Seitendetails wie Titeln, URLs und zuletzt bearbeiteten Daten bis hin zu Diskussionsdaten wie Themen, URLs und Teilnehmernamen passt sich der Scraper Ihren Anforderungen an.
-
Wie oft kann ich den Scraper ausführen?
Die Häufigkeit der Ausführung des Scrapers hängt von Ihrem Abonnementplan und der Anzahl der in Ihrem Konto verfügbaren Credits ab. Höherwertige Pläne beinhalten mehr Credits, die größere oder häufigere Datenextraktionen ermöglichen. Nutzer, die kontinuierlichen Zugriff auf das Tool benötigen, können auf einen Premium-Plan upgraden, um eine ununterbrochene Nutzung zu gewährleisten.
-
Was passiert, wenn mir die Credits ausgehen?
Wenn Ihnen die Credits ausgehen, können Sie problemlos zusätzliche Credits nach Bedarf kaufen oder auf einen höherwertigen Abonnementplan upgraden. Dies stellt sicher, dass Sie jederzeit Zugriff auf die Funktionen des Scrapers haben, wann immer Sie sie benötigen.
-
Ist es legal, namu.wiki-Seiten und -Diskussionen zu scrapen?
Das Scrapen öffentlich zugänglicher Daten von namu.wiki ist im Allgemeinen zulässig, solange Sie die geltenden Gesetze einhalten, die Datenschutzrechte respektieren und die Nutzungsbedingungen von namu.wiki nicht verletzen. Es ist wichtig, die Daten verantwortungsbewusst zu verwenden und sicherzustellen, dass alle relevanten Vorschriften eingehalten werden, um potenzielle Probleme zu vermeiden.
-
Welche Arten von Daten kann ich von namu.wiki extrahieren?
Sie können eine Vielzahl von Daten von namu.wiki extrahieren, einschließlich Seitentiteln, URLs, zuletzt bearbeiteten Daten, Diskussionsthemen und Teilnehmernamen. Diese Daten können für Analysen, Inhaltserstellung und Community-Engagement verwendet werden und bieten wertvolle Einblicke in die Inhalte und Interaktionen der Plattform.
-
Wie kann ich sicherstellen, dass die von mir gescrapten Daten genau und aktuell sind?
Der KI-gestützte Scraper von Thunderbit ist darauf ausgelegt, genaue und aktuelle Daten bereitzustellen, indem er kontinuierlich die Struktur und den Inhalt der Website analysiert. Es ist jedoch immer eine gute Praxis, die Daten manuell zu überprüfen und mit anderen Quellen abzugleichen, um deren Genauigkeit und Relevanz sicherzustellen.
📖 Mehr erfahren
Für weitere Informationen über Web-Scraping und wie Sie Thunderbit effektiv nutzen können, besuchen Sie unseren und entdecken Sie Artikel wie und .