IDCrawl Web-Scraper
Vertraut von Profis bei führenden Unternehmen











Idcrawl-Daten, die nutzbar bleiben
Nutze idcrawl, um mit Thunderbit schneller, sauberer und in großem Umfang Daten zu extrahieren.
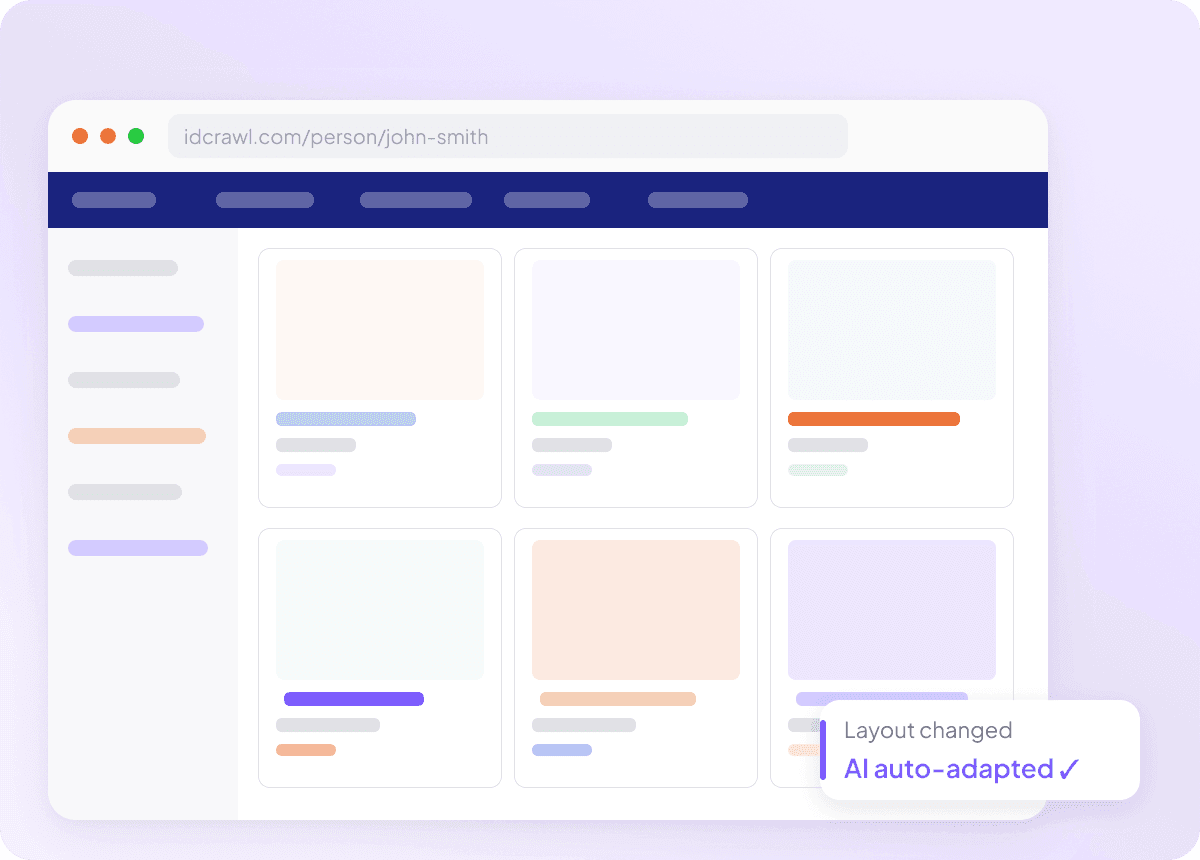
Passt sich an, wenn sich Idcrawl ändert
Scraper, die nach jedem Website-Update kaputtgehen, sind nutzlos — besonders, wenn du von idcrawl vollständige Namen, Berufsbezeichnungen, Firmennamen, E-Mail-Adressen, Telefonnummern und LinkedIn-Profile ziehen willst. Thunderbit liest Seiten nach Bedeutung statt nach festen Selektoren und kann sich deshalb anpassen, wenn sich das Layout verschiebt. So verbringst du weniger Zeit mit dem Reparieren von Scrapern und mehr Zeit mit den Daten, die du brauchst.
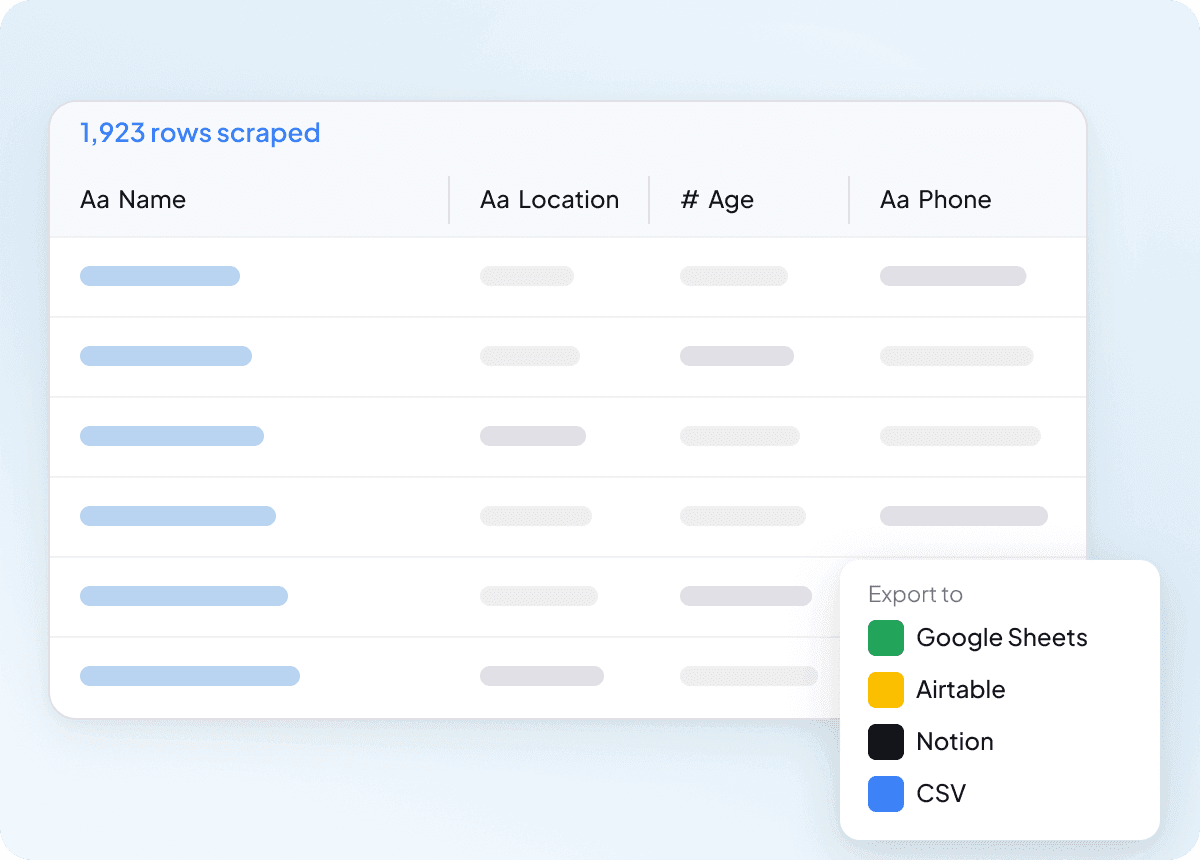
Saubere Daten von Anfang an
Rohdaten sind nur der Anfang der eigentlichen Arbeit, und idcrawl-Ergebnisse müssen oft erst bereinigt werden, bevor sie wirklich nützlich sind. Thunderbit strukturiert und formatiert die Daten schon während der Extraktion, sodass das, was du exportierst, bereits sauber und einsatzbereit ist. Das bedeutet weniger Sortieren, weniger Nacharbeit und eine reibungslosere Übergabe an dein Team.
Idcrawl in einem Rutsch im Bulk scrapen
Eine idcrawl-Seite nach der anderen zu scrapen skaliert nicht, wenn du eine lange Kontaktliste brauchst. Thunderbit kann Hunderte von Seiten in einem Durchlauf im Bulk scrapen, sodass du eine Liste von URLs einlesen und darüber hinweg vollständige Namen, Berufsbezeichnungen, Firmennamen, E-Mail-Adressen, Telefonnummern und LinkedIn-Profile extrahieren kannst. So wird aus einer großen Liste deutlich einfacher nutzbare Daten.

Warum unterscheidet sich Thunderbit von herkömmlichen idcrawl-Scrapern?
Eine einfachere Möglichkeit, idcrawl-Daten ohne ständige Korrekturen zu extrahieren.
Herkömmliche Scraper
Die alte VorgehensweiseThunderbit KI
Der intelligentere AnsatzVerlass dich nicht nur auf unser Wort
Lies, was unsere Nutzer über Thunderbit sagen.







Häufig gestellte Fragen
Ähnlich Anwendungsfälle
Entdecke weitere Anwendungsfälle von Thunderbits Web Scraper.

Tieba-Scraper
Mit dem Thunderbit Tieba Web-Scraper können Sie gezielt Daten aus Baidu Tieba erfassen – darunter aktuelle Trendthemen und Forenkategorien. Dank KI-gestützter Feldvorschläge sammeln Sie im Handumdrehen Themen, Links, Beitragszahlen und Nutzeraktivitäten – perfekt für Recherche, Marketing oder Content-Erstellung. Ideal, um Social-Media-Trends und Diskussionen auf Tieba zu analysieren.
Mehr erfahren ->Substack-Scraper
Hole dir Abonnentenzahlen, Artikeltitel und Beschreibungen von Substack-Publikationen in eine saubere Tabelle – ganz ohne Code, die KI übernimmt die Strukturierung.
Mehr erfahren ->Tradera Web-Scraper
Mit dem Thunderbit Tradera Web-Scraper können Sie mühelos Daten aus Tradera-Angeboten und Produktseiten extrahieren. Dank KI-gestützter Feldvorschläge erfassen Sie Produktnamen, Preise, Kategorien, Bilder und Beschreibungen – ideal für Analysen oder die Bestandsverwaltung. Perfekt für Online-Händler, Sammler und Forscher, die strukturierte Tradera-Daten benötigen.
Mehr erfahren ->
People-Search-Scraper
Mit dem Thunderbit People-Search-Scraper können Sie strukturierte Daten aus People-Search-Profilen und Seiten zur Rückwärtssuche von Telefonnummern extrahieren. Dank KI-gestützter Feldvorschläge erfassen Sie blitzschnell Namen, Orte, Telefonnummern, E-Mail-Adressen und mehr – ideal für Recherche, Marketing oder Lead-Generierung. Perfekt für Marketer, Analysten und Unternehmen, die öffentliche Kontaktdaten und Informationen benötigen.
Mehr erfahren ->On the Beach Web-Scraper
Mit dem Thunderbit On the Beach Scraper können Sie Urlaubs- und Hotelangebote, Preise, Bewertungen und vieles mehr von On the Beach in nur zwei Klicks extrahieren. Dank KI-gestützter Feldvorschläge sammeln und strukturieren Sie Reisedaten im Handumdrehen – ideal für Analyse, Vergleich oder Reiseplanung. Perfekt für Reiseprofis, Analysten und Urlaubsplaner.
Mehr erfahren ->DialIndia Scraper
Mit dem Thunderbit DialIndia-Scraper können Sie Daten aus Geschäftsprofilen und Reiseverzeichnissen von DialIndia extrahieren – unterstützt durch KI-basierte Feldvorschläge. Sammeln Sie Firmennamen, Kontaktdaten, Standorte und Beschreibungen für Recherche, Marketing oder Lead-Generierung in wenigen Klicks.
Mehr erfahren ->Bereit, deine Datenextraktion zu beschleunigen?
Schließe dich über 100.000 Profis an, die Thunderbit bereits nutzen, um ihre Web-Scraping-Workflows zu automatisieren.
Die kostenlose Testphase bietet unbegrenzte Credits für 8 Webseiten.