Goodreads-Scraper
Vertraut von Profis bei führenden Unternehmen











Goodreads-Daten in Sekunden statt Stunden extrahieren
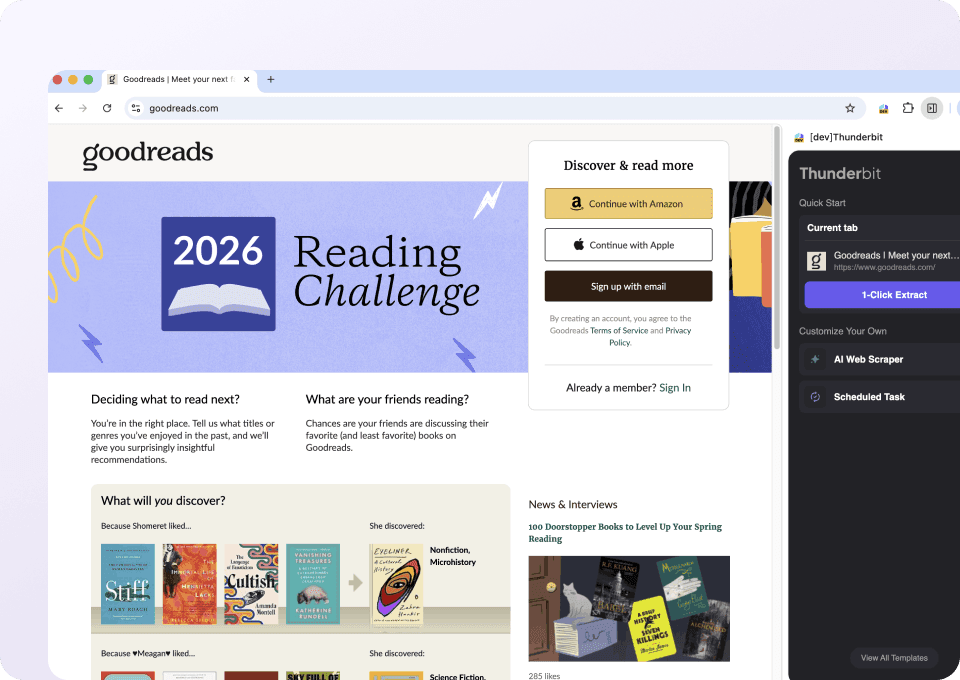
Goodreads-Daten mit zwei Klicks scrapen
Genug davon, Buchtitel, Autorennamen, Bewertungen und Seitenzahlen manuell von Goodreads zu kopieren? Thunderbit ermöglicht dir die Extraktion in nur zwei Klicks. Keine Programmierung und kein kompliziertes Setup nötig. Zeige einfach auf die gewünschten Daten, und unsere KI erkennt die Felder automatisch und extrahiert sie.
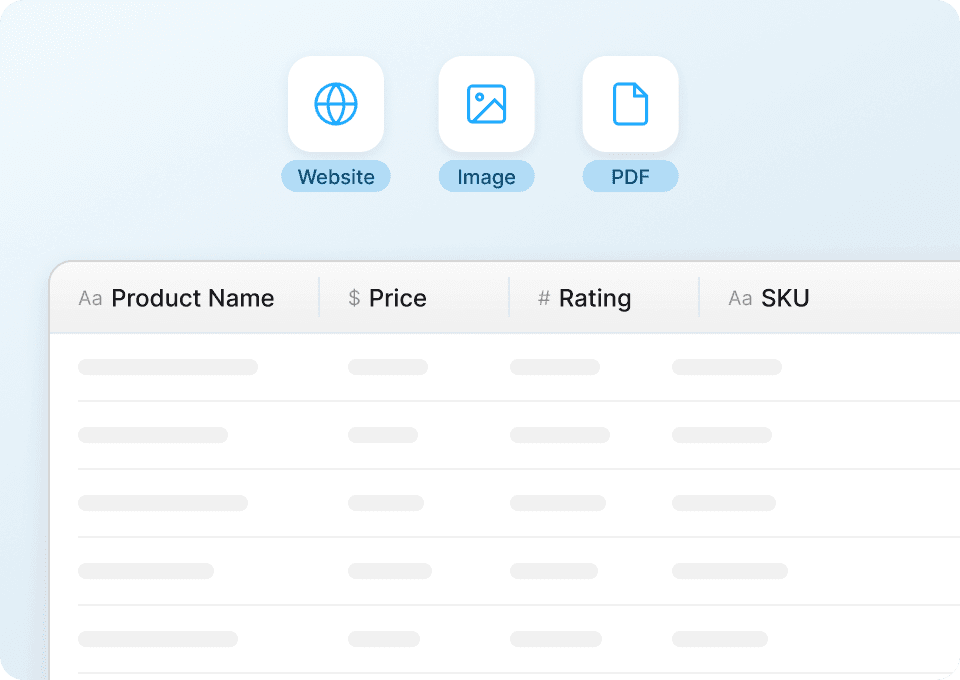
Bereinigte Goodreads-Daten, sofort einsatzbereit
Goodreads-Daten können unübersichtlich sein. Thunderbit bereinigt und strukturiert die Daten automatisch während der Extraktion. Stell dir ein perfekt formatiertes Google Sheet mit Buchtiteln, Autoren, Durchschnittsbewertung, Anzahl der Rezensionen und Seitenzahl vor – alles direkt für deine Analyse bereit, ganz ohne manuelle Nacharbeit.
Hunderte Goodreads-Seiten scrapen
Goodreads manuell Seite für Seite zu scrapen ist mühsam und zeitaufwendig. Thunderbit kann automatisch Hunderte Goodreads-Seiten auf einmal scrapen. Gib einfach eine Liste mit URLs ein, und das Tool extrahiert schnell und effizient Buchdaten, Autoren oder andere Informationen, die du brauchst.

Macht dir das Scraping von Goodreads zu schaffen?
Sieh, wie Thunderbit die Datenextraktion von Goodreads vereinfacht.
Traditionelle Scraper
Die alte VorgehensweiseThunderbit
Der klügere AnsatzVerlass dich nicht nur auf unser Wort
Lies, was unsere Nutzer über Thunderbit sagen.






Häufig gestellte Fragen
Ähnlich Anwendungsfälle
Entdecke weitere Anwendungsfälle von Thunderbits Web Scraper.

HKTVmall Web-Scraper
Mit nur wenigen Klicks Produktnamen, Preise und sogar Kundenbewertungen aus HKTVmall-Listings erfassen – ganz ohne komplizierte Einrichtung.
Mehr erfahren ->DialIndia Scraper
Mit dem Thunderbit DialIndia-Scraper können Sie Daten aus Geschäftsprofilen und Reiseverzeichnissen von DialIndia extrahieren – unterstützt durch KI-basierte Feldvorschläge. Sammeln Sie Firmennamen, Kontaktdaten, Standorte und Beschreibungen für Recherche, Marketing oder Lead-Generierung in wenigen Klicks.
Mehr erfahren ->Substack-Scraper
Hole dir Abonnentenzahlen, Artikeltitel und Beschreibungen von Substack-Publikationen in eine saubere Tabelle – ganz ohne Code, die KI übernimmt die Strukturierung.
Mehr erfahren ->
ReverseAustralia Scraper
Mit dem Thunderbit ReverseAustralia Scraper können Sie Daten von Beschwerde- und Kommentarseiten auf ReverseAustralia extrahieren. Dank KI-gestützter Feldvorschläge erfassen Sie schnell Telefonnummern, Beschreibungen von Beschwerden, Kommentartexte, Nutzernamen und vieles mehr – ideal für Analysen oder Recherchen. Perfekt für Marketer, Forschende und Unternehmen, die strukturierte Feedbackdaten benötigen.
Mehr erfahren ->On the Beach Web-Scraper
Mit dem Thunderbit On the Beach Scraper können Sie Urlaubs- und Hotelangebote, Preise, Bewertungen und vieles mehr von On the Beach in nur zwei Klicks extrahieren. Dank KI-gestützter Feldvorschläge sammeln und strukturieren Sie Reisedaten im Handumdrehen – ideal für Analyse, Vergleich oder Reiseplanung. Perfekt für Reiseprofis, Analysten und Urlaubsplaner.
Mehr erfahren ->
White Pages Scraper
Mit dem Thunderbit White Pages-Scraper können Sie ganz einfach Daten aus Telefon- und Firmenverzeichnissen der White Pages extrahieren. Dank KI-gestützter Felderkennung sammeln Sie Namen, Telefonnummern, Adressen und Webseiten-Links für Leadgenerierung, Marketing oder Recherche – und das in wenigen Klicks.
Mehr erfahren ->Bereit, deine Datenextraktion zu beschleunigen?
Schließe dich über 100.000 Profis an, die Thunderbit bereits nutzen, um ihre Web-Scraping-Workflows zu automatisieren.
Die kostenlose Testphase bietet unbegrenzte Credits für 8 Webseiten.