Thunderbits FlexJobs Scraper verwandelt FlexJobs-Seiten mithilfe von KI in saubere, strukturierte Datensätze. Du kannst Remote-Jobanzeigen und Karriere-Ratgeberartikel scrapen und anschließend per Subpage Scraping jede Zeile um vollständige Jobdetails oder den kompletten Artikelinhalt erweitern. Exportiere die Ergebnisse in wenigen Minuten nach Excel, Google Sheets, Airtable oder Notion – mit .
🤖 Was ist der FlexJobs Scraper
Der KI-gestützte FlexJobs Scraper ist ein , der Daten von ausliest und in einer Tabelle strukturiert, die du herunterladen oder mit deinen Tools synchronisieren kannst. Du öffnest einfach die gewünschte Seite (z. B. das Jobverzeichnis oder den Blog), klickst auf AI Suggest Columns und anschließend auf Scrape.
Er ist für echte Workflows gebaut – also für Fälle, in denen du mehr brauchst als das, was auf einer Ergebnisliste sichtbar ist. Mit Subpage Scraping kann Thunderbit jede einzelne Job- oder Artikelseite aufrufen und zusätzliche Felder (z. B. vollständige Beschreibung, Anforderungen, Kategorien, Autor u. v. m.) zurück in deinen Datensatz schreiben.
🧲 Was kannst du mit FlexJobs scrapen
FlexJobs wird häufig genutzt, um Remote Jobs, Hybrid-Stellen und flexible Arbeitsmodelle zu finden – plus Karriere-Ressourcen. Mit Thunderbit kannst du sowohl Joblisten als auch Content-Seiten scrapen, z. B. für Recherche, Lead-Generierung, Recruiting-Prozesse und Content-Analysen.
🧑💻 FlexJobs Remote-Jobanzeigen scrapen
Scrape das Jobverzeichnis unter , um eine strukturierte Datenbank mit Rollen, Unternehmen und Job-Metadaten aufzubauen. Anschließend kannst du jede Zeile anreichern, indem du die jeweilige Job-Subpage scrapest – inklusive vollständiger Beschreibung, Anforderungen und Bewerbungsdetails.
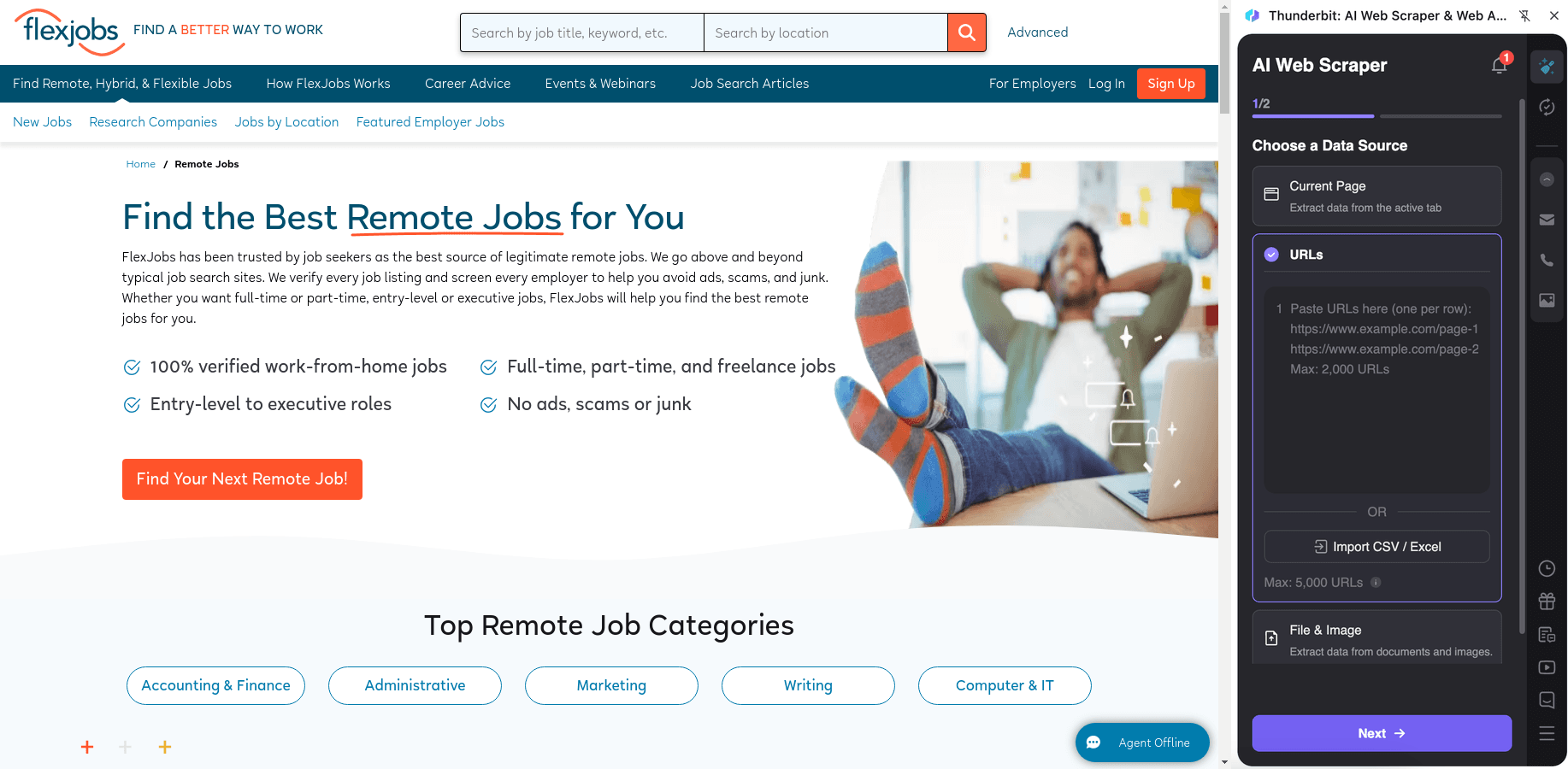
Schritte:
- Lade die herunter und registriere ein Konto.
- Öffne die Zielseite, z. B.: .
- Klicke auf AI Suggest Columns, um empfohlene Spaltennamen und Datentypen zu erzeugen.
- Klicke auf Scrape, starte den Scraper und exportiere anschließend nach Excel, Google Sheets, Airtable oder Notion.
Spaltennamen
| Spalte | Beschreibung |
|---|---|
| 🧾 Jobtitel | Der Titel der Stelle, wie er in der Ergebnisliste angezeigt wird. |
| 🏢 Unternehmen | Name des Arbeitgebers bzw. des einstellenden Unternehmens (falls verfügbar). |
| 📍 Standort / Remote-Typ | Standortangaben wie Remote, nur USA, Bundesstaat-Einschränkungen oder Stadt/Bundesstaat. |
| 🕒 Beschäftigungsart | Vollzeit, Teilzeit, Freelance, Vertrag, befristet usw. |
| 🧩 Kategorie / Karrierestufe | Jobkategorie und/oder Senioritätslevel, sofern angegeben. |
| 🗓️ Veröffentlichungsdatum | Datum der Veröffentlichung oder letzten Aktualisierung (falls sichtbar). |
| 🔗 Job-URL | Direkter Link zur Detailseite für Subpage Scraping. |
| 📝 Kurzbeschreibung | Vorschau-/Snippet-Text aus der Listenansicht. |
| 🧠 Skills / Keywords | Wichtige Skills oder Tags aus der Liste (falls vorhanden). |
| 📄 Vollständige Jobbeschreibung (Subpage) | Komplette Stellenbeschreibung von der Job-Detailseite. |
| ✅ Anforderungen (Subpage) | Anforderungen/Qualifikationen von der Job-Detailseite. |
| 📬 Bewerbung (Subpage) | Hinweise zur Bewerbung oder Bewerbungslink-Details, sofern verfügbar. |
📚 FlexJobs Karriere-Ratgeberartikel scrapen
Scrape den FlexJobs-Blog unter , um Artikel-Metadaten für Content-Recherche, SEO-Analysen oder eine interne Wissensdatenbank zu sammeln. Mit Subpage Scraping kannst du den vollständigen Artikeltext, Überschriften und Autorendetails erfassen.
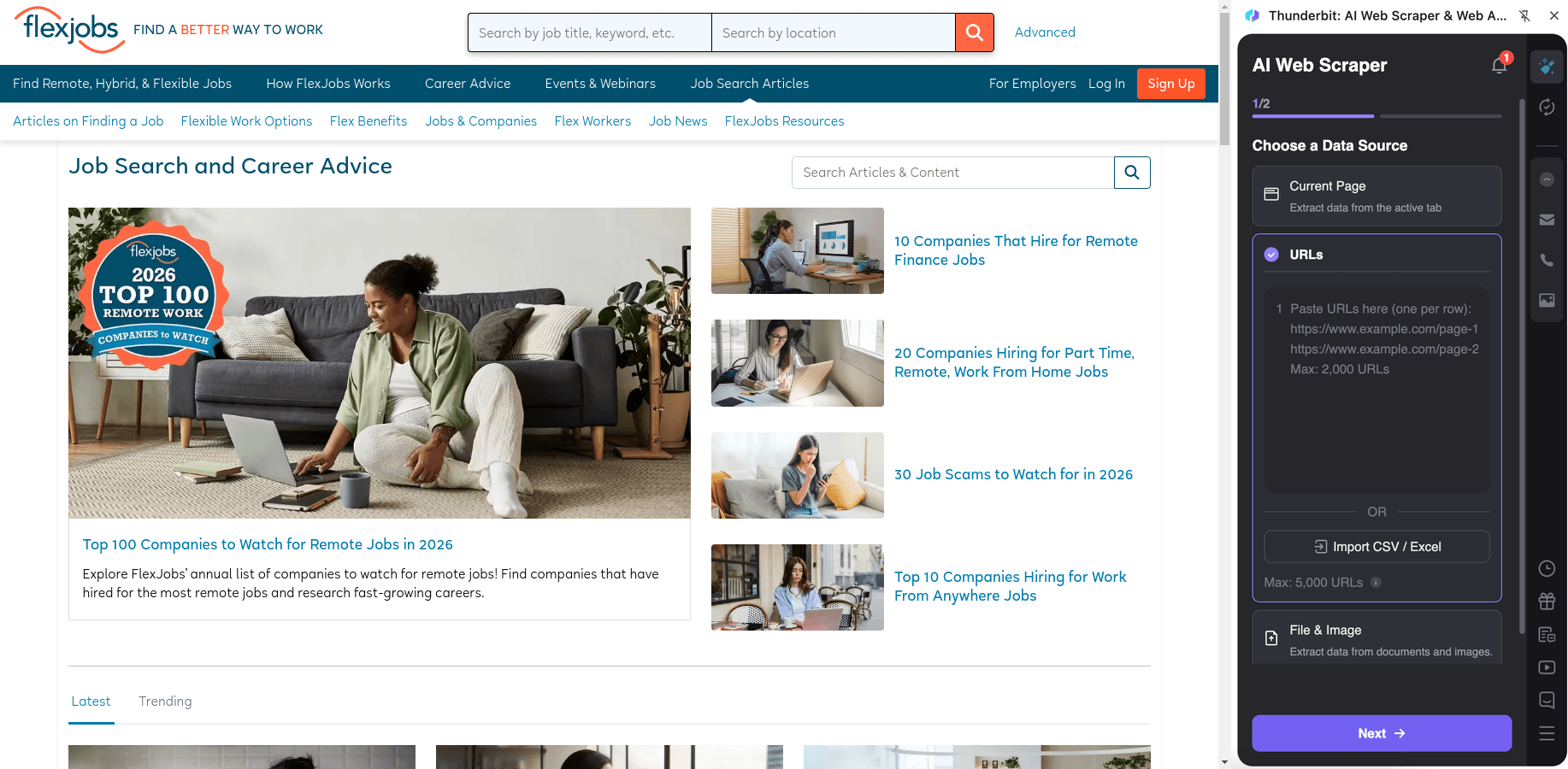
Schritte:
- Lade die herunter und registriere ein Konto.
- Öffne die Zielseite, z. B.: .
- Klicke auf AI Suggest Columns, um empfohlene Spaltennamen und Datentypen zu erzeugen.
- Klicke auf Scrape, extrahiere die Daten und exportiere anschließend nach Excel, Google Sheets, Airtable oder Notion.
Spaltennamen
| Spalte | Beschreibung |
|---|---|
| 📰 Artikeltitel | Überschrift des Blogbeitrags. |
| 🔗 Artikel-URL | Link zur Artikelseite für Subpage Scraping. |
| ✍️ Autor | Name des Autors, sofern angezeigt. |
| 🗓️ Veröffentlichungsdatum | Datum, an dem der Artikel veröffentlicht wurde. |
| 🏷️ Kategorie / Tag | Blogkategorie oder Tag (aus Liste oder Subpage, falls vorhanden). |
| 🧷 Auszug | Kurzer Vorschautext aus der Blog-Übersicht. |
| 🖼️ URL des Titelbilds | Hauptbild, das dem Artikel zugeordnet ist (falls verfügbar). |
| 🧾 Vollständiger Artikelinhalt (Subpage) | Volltext, der von der Artikelseite extrahiert wird. |
| 🔠 Überschriften (Subpage) | H2/H3-Überschriften für Gliederung und Analyse. |
| ⏱️ Lesezeit (optional) | Geschätzte Lesezeit, sofern die Seite sie bereitstellt. |
🎯 Warum ein FlexJobs Scraper Tool nutzen
Das Scrapen von FlexJobs kann verschiedene Teams und Prozesse unterstützen – überall dort, wo strukturierte Daten entscheidend sind.
- Recruiting & Talent Ops: Baue eine durchsuchbare Pipeline mit Remote-Rollen nach Kategorie, Standort-Einschränkungen und Jobtyp. So kannst du Trends über Zeit verfolgen und ein einheitliches Dataset im Team teilen.
- Sales & Partnerships: Finde Unternehmen, die Remote-Rollen ausschreiben, und reichere Lead-Listen nach Branche, Hiring-Tempo und Rollentypen an.
- Karrierecoaches & Creator: Sammle Signale aus dem Arbeitsmarkt und organisiere Ratgeberartikel in einer Content-Bibliothek für Newsletter, Kurse oder Coaching-Programme.
- Marketing- & SEO-Teams: Analysiere Themen, Veröffentlichungsrhythmus und Content-Struktur des FlexJobs-Blogs für deine eigene Redaktionsplanung.
- Ecommerce Ops & Analysten (ja, auch): Wenn du ein Jobboard, einen Staffing-Marktplatz oder ein HR-Produkt betreibst, kannst du gescrapte Jobdaten für Wettbewerbsanalysen und Taxonomie-Aufbau nutzen.
Thunderbit ist für Business-Anwender entwickelt, die schnell und zuverlässig arbeiten wollen – ohne fragile Scraping-Skripte zu pflegen. Wenn sich Layouts ändern, liest die KI die Seite neu und passt sich an.
🧩 So nutzt du die FlexJobs Chrome Extension
- Thunderbit Chrome Extension installieren: Hol sie dir aus dem und erstelle dein Konto.
- Zu einer FlexJobs-Seite navigieren: Öffne für Stellenanzeigen oder für Artikel.
- KI-Scraper aktivieren: Klicke auf AI Suggest Columns, um Felder zu generieren, und passe bei Bedarf Spaltennamen und Datentypen an (Text, Datum, URL, Bild usw.).
- Scrapen und mit Subpages anreichern: Klicke auf Scrape für die Listenansicht und nutze anschließend Scrape Subpages, um vollständige Jobdetails oder den kompletten Artikelinhalt in dieselbe Tabelle zu übernehmen.
Hilfreiche Ressourcen, wenn du neu beim Scraping bist:
- Weitere Guides im
💳 Preise für den FlexJobs Scraper
Thunderbit nutzt ein einfaches Credit-System:
- 1 Credit = 1 Ausgabezeile in deiner Ergebnistabelle (z. B. eine Jobanzeige-Zeile oder eine Blogartikel-Zeile).
- Datenexport ist kostenlos: Export nach Excel, Google Sheets, Airtable oder Notion oder Download als CSV/JSON.
Du kannst mit dem Free-Tarif starten und 6 Seiten pro Monat scrapen. Mit einer kostenlosen Testphase kannst du 10 Seiten gratis scrapen – ideal, um Pagination bei Joblisten und das Anreichern über Subpages zu testen, bevor du upgradest.
Bezahlte Pläne skalieren mit deinem Bedarf:
- Starter eignet sich für leichtes Scraping und einmalige Projekte.
- Pro-Tarife sind besser für laufende Recruiting-Prozesse, Jobmarkt-Monitoring und Content-Tracking.
- Der Jahresplan ist meist am günstigsten, da er im Vergleich zur monatlichen Zahlung einen Rabatt enthält.
Alle Optionen findest du unter .
❓ FAQ
-
Was ist der KI-gestützte FlexJobs Scraper?
Der KI-gestützte FlexJobs Scraper ist ein Thunderbit-Workflow, der FlexJobs-Jobanzeigen und Blogartikel in strukturierte Zeilen und Spalten überführt. Er nutzt KI, um das Seitenlayout zu verstehen – so scrapest du schnell und erhältst dennoch saubere Felder wie Titel, Unternehmen, Standort und URLs.
Zusätzlich kannst du Ergebnisse per Subpage Scraping anreichern, um vollständige Jobbeschreibungen oder den kompletten Artikelinhalt zu erfassen. -
Was ist Thunderbit?
ist eine KI-Web-Scraping-Chrome-Extension, mit der du Daten aus Websites, PDFs und Bildern in strukturierte Tabellen extrahieren kannst. Sie ist für Business-Workflows wie Lead-Generierung, Recruiting, Ecommerce Operations und Marktrecherche gebaut.
In der Regel klickst du auf AI Suggest Columns und dann auf Scrape – Thunderbit übernimmt bei Bedarf auch Pagination und Subpages. -
Brauche ich Programmierkenntnisse, um FlexJobs zu scrapen?
Nein. Thunderbit ist für nicht-technische Workflows konzipiert – du brauchst weder Python noch Selektoren oder Scraping-Infrastruktur.
Wenn du eine Seite öffnen und ein paar Buttons klicken kannst, kannst du dir ein Dataset erstellen. -
Kann Thunderbit Jobdetails von jeder einzelnen Jobseite scrapen?
Ja. Nach dem Scrapen der Listenansicht kannst du mit Subpage Scraping jede Job-URL besuchen und tiefere Felder wie vollständige Beschreibung, Anforderungen und Bewerbungshinweise extrahieren.
Das ist besonders hilfreich, wenn die Liste nur eine kurze Vorschau zeigt. -
Wie geht Thunderbit mit Pagination und Infinite Scroll bei FlexJobs um?
Thunderbit unterstützt sowohl klassische „Weiter“-Pagination als auch Infinite-Scroll-Muster. Du kannst mehrere Seiten in einem Lauf scrapen – praktisch, wenn du Hunderte Jobanzeigen sammeln willst.
Wenn du Cloud Scraping nutzt, kann Thunderbit Batches oft sehr schnell verarbeiten (häufig bis zu 50 Seiten auf einmal – abhängig vom Verhalten der Website). -
In welche Formate kann ich exportieren?
Du kannst gescrapte Daten nach Excel, Google Sheets, Airtable oder Notion exportieren oder als CSV bzw. JSON herunterladen.
Der Export ist kostenlos – dein Budget fließt also in das Scraping-Volumen statt in Dateizugriff. -
Was ist der Unterschied zwischen Cloud Scraping und Browser Scraping bei FlexJobs?
Browser Scraping läuft in deiner Chrome-Session – hilfreich, wenn eine Website Login oder personalisierten Zugriff erfordert. Cloud Scraping läuft auf Thunderbits Cloud-Infrastruktur und ist bei öffentlichen Seiten meist schneller.
Wenn du Seiten scrapest, die von deiner Account-Session abhängen, ist Browser Scraping oft die bessere Wahl. -
Wie viele Zeilen kann ich scrapen – und was bedeutet „500 max rows“?
Der Wert „max rows“ (z. B. 500) ist ein praxisnaher Richtwert für einen einzelnen Lauf – abhängig von Seitenstruktur und Konfiguration. Die tatsächliche Kapazität hängt von Pagination-Tiefe, Credits und davon ab, ob du über Subpages anreicherst.
Da 1 Credit = 1 Ausgabezeile ist, kannst du die Kosten grob über die Anzahl der Jobs oder Artikel kalkulieren, die du sammeln möchtest. -
Ist es in Ordnung, FlexJobs-Daten zu scrapen?
Du solltest immer die Nutzungsbedingungen von FlexJobs beachten, Privatsphäre respektieren und geltende Gesetze und Vorschriften einhalten. Thunderbit ist ein Tool zum Extrahieren und Strukturieren von Daten – für die korrekte Nutzung bist du selbst verantwortlich.
Wenn du unsicher bist, starte mit einem kleinen Testlauf und prüfe, ob dein Use Case zu deinen Compliance-Anforderungen passt.
📘 Mehr erfahren
- Extension holen:
- Produktdetails ansehen:
- Preise & Pläne:
- Scraping-Grundlagen lernen:
- In Tabellen exportieren:
- Smarter scrapen mit KI:
- Tutorials ansehen: