

Web Scraping ist für moderne Unternehmen längst eine Art Geheimwaffe, egal ob im Vertrieb, in den Operations oder im Marketing. Wer flink und effizient Daten aus dem Netz zieht, verschafft sich für das nächste große Projekt einen klaren Vorsprung. In einer Zeit, in der datenbasierte Entscheidungen immer wichtiger werden, suchen Firmen nach Tools, die nicht nur schnell sind, sondern auch zuverlässig und skalierbar. Und genau hier kommt Rust ins Spiel: Diese moderne Programmiersprache gewinnt beim Web Scraping zunehmend Fans, besonders bei Teams, die auf Tempo und Sicherheit setzen.
Das ist mehr als bloß ein Hype: In der Stack Overflow Developer Survey wurde Rust schon mehrfach zur beliebtesten Programmiersprache gekürt und taucht immer häufiger in Backend- und Data-Engineering-Projekten auf. Aber was heißt „Web Scraping in Rust“ konkret für Unternehmen? Und wie schlägt sich Rust gegen No-Code-Lösungen wie Thunderbit, die gezielt für nicht-technische Teams gebaut wurden? Wir erklären es dir verständlich, ganz ohne Programmierlatein.
Was ist Web Scraping mit Rust? Die Basics locker erklärt
Im Kern heißt Web Scraping, dass du automatisiert Daten von Webseiten einsammelst. Stell dir einen digitalen Helfer vor, der hunderte oder tausende Webseiten ansteuert, gezielt Infos wie Preise, Kontaktdaten oder Bewertungen kopiert und am Ende alles sauber sortiert zurückbringt. Für Unternehmen, die aktuelle Daten für Lead-Generierung, Marktanalysen oder Preisbeobachtung brauchen, ist das ein enormer Zeitgewinn.
Rust ist eine Systemprogrammiersprache, die für ihre hohe Performance sowie ihre Speicher- und Ausfallsicherheit bekannt ist. Anders als ältere Sprachen, die oft für Fehler oder Performance-Probleme anfällig sind, fängt Rust viele Fehler schon vor dem Start ab. Fürs Web Scraping bedeutet das: Du baust extrem schnelle und stabile Tools, die selbst bei riesigen Datenmengen weder abstürzen noch in Speicherprobleme laufen – ein echter Vorteil bei großen Extraktionen.
Davon haben nicht nur Entwickler etwas: Schnellere und sicherere Scraper liefern Unternehmen aktuellere Daten, weniger Fehler und verlässlichere Analysen.
Warum Rust fürs Web Scraping? Die wichtigsten Pluspunkte für Unternehmen
Warum setzen immer mehr Teams auf Rust, obwohl Python und JavaScript seit Jahren die Platzhirsche beim Web Scraping sind? Die wichtigsten Gründe:
- Top-Performance: Rust wird direkt in Maschinencode übersetzt und ist damit spürbar schneller als interpretierte Sprachen wie Python oder JavaScript. Bei großen Datenmengen – etwa Millionen von Seiten – schlägt sich das direkt im Geschäftsergebnis nieder.
- Speichersicherheit: Rusts innovatives Speichermanagement (ohne Garbage Collector, dafür mit strikten Besitzregeln) verhindert viele typische Fehler und Abstürze. Deine Scraping-Prozesse laufen dadurch stabiler und zuverlässiger.
- Zuverlässigkeit: Der Rust-Compiler prüft streng auf Typfehler und Fehlerbehandlung, sodass viele Probleme schon vor dem Start auffallen. Das sorgt für stabile, vorhersehbare Abläufe.
- Nebenläufigkeit: Rust macht es einfach, Programme zu schreiben, die viele Aufgaben gleichzeitig erledigen (gleich mehr dazu) – ideal, wenn du viele Seiten parallel auslesen willst.
Im Vergleich zu Python oder JavaScript: Diese Sprachen lernt man zwar leichter, doch bei großen Projekten kommen sie oft an ihre Grenzen. Rusts technische Stärken erlauben es, mehr Daten schneller und mit weniger Problemen zu sammeln – ein klarer Wettbewerbsvorteil.
Asynchrone Power: Wie Rust effizientes Web Scraping im großen Stil möglich macht
Hier spielt Rust seine Stärken voll aus: Asynchrone Programmierung. Vereinfacht gesagt: Mit asynchronem Code ruft dein Scraper Daten von vielen Webseiten gleichzeitig ab, ohne auf jede einzelne Antwort warten zu müssen. Ein entscheidender Vorteil, wenn du große Datenmengen schnell brauchst.
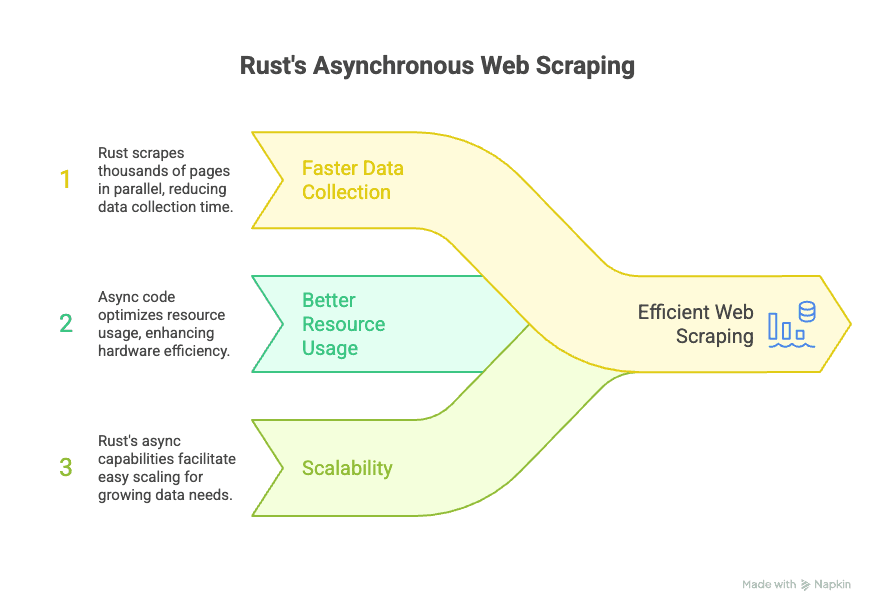
Rusts asynchrones Ökosystem stützt sich auf Bibliotheken wie Tokio und async-std, mit denen dein Scraper tausende Anfragen parallel verarbeitet, ohne den Hauptprozess zu blockieren. Für Unternehmen heißt das:
- Schnellere Datensammlung: Du liest tausende Seiten parallel aus und baust deine Datenbasis in Rekordzeit auf.
- Effizientere Ressourcennutzung: Asynchroner Code holt mehr aus der Hardware heraus – du erreichst mit weniger Aufwand mehr.
- Skalierbarkeit: Wächst dein Datenbedarf, skalierst du mit Rusts asynchronen Möglichkeiten mühelos mit, ohne alles neu schreiben zu müssen.
In der Praxis bedeutet das: Dein Team reagiert auf Marktveränderungen, beobachtet Wettbewerber oder generiert Leads in Echtzeit – ohne stunden- oder tagelange Wartezeiten.
Wie läuft Web Scraping mit Rust ab? Ein Überblick in fünf Schritten
Wie sieht ein typischer Web-Scraping-Prozess mit Rust aus? Ein verständlicher Ablauf – ohne Technikjargon:
- Vorbereitung: Festlegen, welche Daten von welchen Webseiten gesammelt werden sollen.
- Daten abrufen: Mit Bibliotheken wie Reqwest (für HTTP-Anfragen) werden die Webseiten heruntergeladen.
- Inhalte auslesen: Mit Scraper oder Select werden gezielt Infos (z. B. Produktnamen, Preise, E-Mails) aus dem HTML-Code extrahiert.
- Umgang mit Unterseiten/Paginierung: Logik programmieren, um durch mehrere Seiten zu navigieren oder Links zu Unterseiten zu folgen (gleich mehr dazu).
- Daten exportieren: Die gesammelten Daten landen in einem strukturierten Format wie CSV, Excel oder direkt in einer Datenbank – so kann dein Team sofort damit arbeiten.
Jede Bibliothek hat dabei ihre Rolle: Reqwest holt die Daten, Scraper/Select lesen sie aus, und für den Export stehen zahlreiche Rust-Tools oder externe Pakete bereit.
Komplexe Webseiten meistern: Rusts Stärken bei Paginierung und Unterseiten
Viele Scraping-Projekte sind anspruchsvoller als das Auslesen einer einzelnen Seite. Oft musst du:
- alle Produkte aus einem mehrseitigen Katalog erfassen
- Bewertungen sammeln, die über mehrere Unterseiten verteilt sind
- Kontaktdaten aus verschachtelten Verzeichnissen extrahieren
Für solche Aufgaben ist Rust bestens gerüstet. Dank des starken Typsystems und der robusten Fehlerbehandlung schreibst du Code, der:
- „Weiter“-Buttons oder Paginierungslinks automatisch erkennt und ihnen folgt
- Unterseiten (wie Produktdetails oder Autorenprofile) ansteuert und die Daten zusammenführt
- unerwartete Änderungen (z. B. fehlende Seiten oder defekte Links) sauber abfängt, ohne dass der Scraper abstürzt
Ein Rust-Scraper kann also auf einer Hauptseite starten, alle Paginierungslinks abarbeiten und für jedes Produkt die Detailseite besuchen – und dabei Preise, Beschreibungen und Bewertungen einsammeln. Das Ergebnis: ein vollständiger, aktueller Datensatz für deine Analysen.
Thunderbit vs. Rust-Code: No-Code-Vorteile für Unternehmen
Jetzt zum springenden Punkt: Nicht jeder hat die Zeit oder das Know-how, einen eigenen Rust-Scraper zu programmieren. Genau hier kommt Thunderbit ins Spiel.
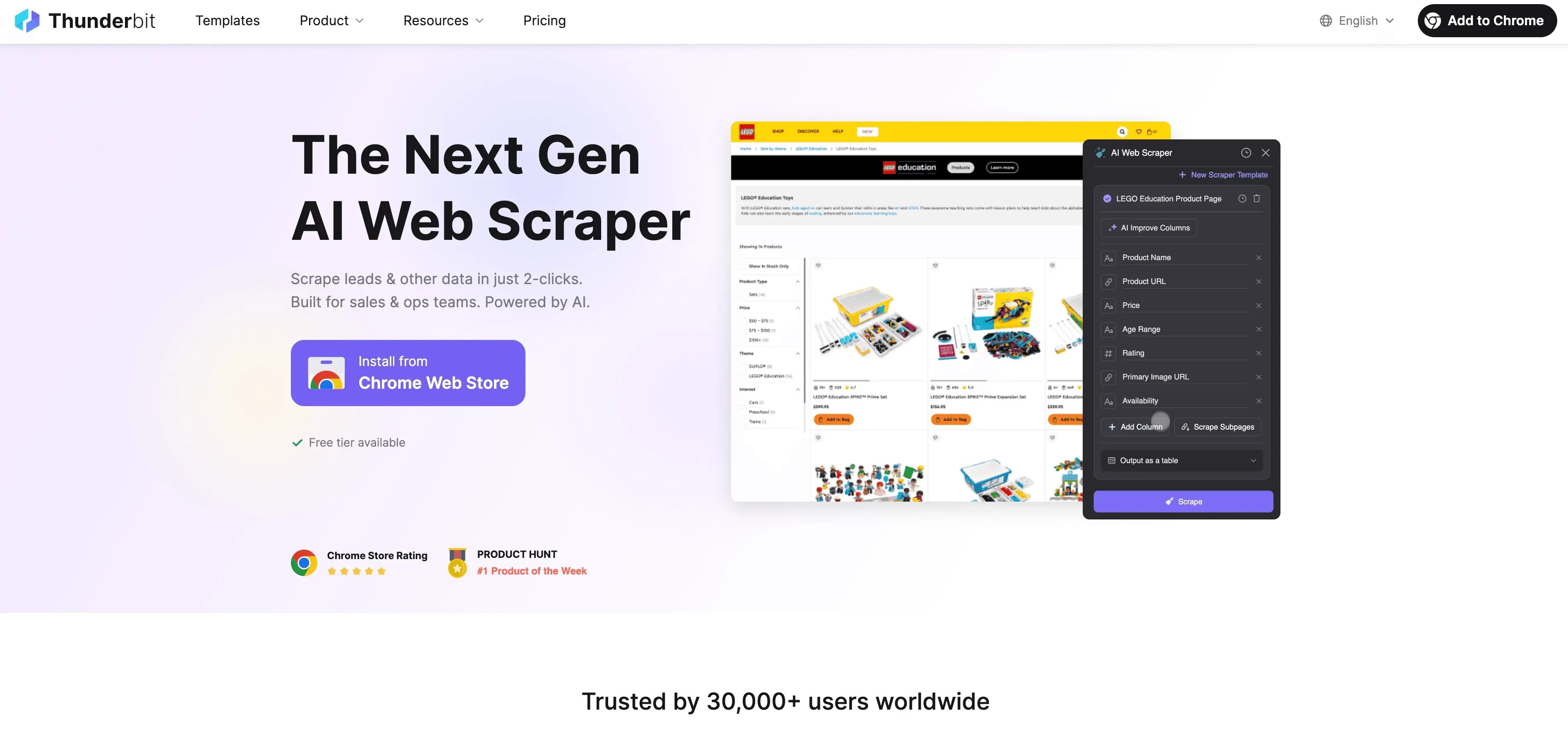
Thunderbit ist ein KI-gestützter, No-Code Web-Scraper für Business-Anwender. Statt zu programmieren, gehst du einfach so vor:
- Öffne die Thunderbit Chrome-Erweiterung
- Navigiere zur gewünschten Webseite
- Klicke auf „KI-Felder vorschlagen“ und lass Thunderbits KI die relevanten Datenfelder erkennen
- Starte den Scrape-Vorgang und exportiere die Ergebnisse direkt nach Excel, Google Sheets, Airtable oder Notion
Keine Vorlagen, kein Programmieren, keine Wartung. Thunderbit übernimmt sogar Paginierung und Unterseiten-Scraping automatisch – wie ein maßgeschneiderter Rust-Scraper, nur mit einer kinderleichten Oberfläche.
Thunderbit KI-Web-Scraper kostenlos testen
Wann ist Thunderbit die bessere Wahl? Die richtige Lösung für dein Team
Welcher Ansatz passt zu deinem Unternehmen? Hier ein schneller Überblick:
| Szenario | Thunderbit | Rust |
|---|---|---|
| Schnelle Lead-Generierung für den Vertrieb | ✅ Am einfachsten und schnellsten | Möglich, aber aufwendig |
| Preisüberwachung bei Wettbewerbern (E-Commerce) | ✅ No-Code, planbar | ✅ Für individuelle Integrationen |
| Komplexe, maßgeschneiderte Workflows | Möglich, aber eingeschränkt | ✅ Volle Kontrolle, hochgradig anpassbar |
| Große, integrierte Datenpipelines | Möglich (per API) | ✅ Optimal für tiefe Integration |
| Nicht-technische Nutzer (Vertrieb, Ops, Marketing) | ✅ Speziell dafür entwickelt | ❌ Programmierkenntnisse erforderlich |
| Schnelle Prototypen oder Einzelaufgaben | ✅ In 2 Klicks startklar | Möglich, aber langsamer im Setup |
Thunderbit ist ideal für Business-Teams, die schnell und unkompliziert Daten extrahieren wollen. Rust ist die richtige Wahl, wenn du maximale Kontrolle, individuelle Logik oder sehr große Datenmengen brauchst.
Praxisbeispiel: Web Scraping mit Rust im Einsatz
Ein Beispiel aus dem Alltag: Du bist Marktforscher und sollst alle Laptops auf einer großen E-Commerce-Plattform erfassen. Die Seite nutzt Paginierung (mehrere Produktseiten), und jedes Produkt hat eine Detailseite mit technischen Daten und Bewertungen.
Mit Rust würdest du:
- mit Reqwest die Hauptseite abrufen
- mit Scraper die Produktlinks aus dem HTML extrahieren
- die „Weiter“-Buttons erkennen und alle Seiten abarbeiten
- für jedes Produkt die Detailseite besuchen und Spezifikationen/Bewertungen auslesen
- Fehler (z. B. fehlende Seiten) abfangen und bei Bedarf wiederholen
- den finalen Datensatz als CSV oder direkt in dein Analyse-Tool exportieren
Der geschäftliche Mehrwert: Du erhältst einen vollständigen, aktuellen Marktüberblick – die Grundlage für bessere Preisgestaltung, Lagerplanung und Marketing.
Herausforderungen und Besonderheiten beim Web Scraping mit Rust
Auch mit Rust läuft nicht immer alles wie am Schnürchen. Typische Herausforderungen (und wie Rust hilft):
- Seitenänderungen: Ändert sich das Layout, kann der Scraper aussteigen. Rusts striktes Typsystem deckt viele Probleme früh auf, doch Anpassungen am Code bleiben nötig.
- Anti-Bot-Maßnahmen: Viele Seiten setzen CAPTCHAs oder Zugriffsbeschränkungen ein. Rusts Geschwindigkeit hilft, unauffällig zu bleiben, aber manchmal braucht es Pausen oder Proxys.
- Datenformatierung: Nicht alle Daten kommen sauber – Rusts starke Parsing-Tools erleichtern den Umgang mit unstrukturiertem HTML.
- Wartung: Individuelle Scraper wollen gepflegt werden. Für Unternehmen heißt das: enge Abstimmung mit den Technik-Teams oder für Routineaufgaben lieber No-Code-Tools wie Thunderbit nutzen.
Was ist Data Scraping und wie funktioniert es 2025? Get Started Free
Tipp: Egal ob Rust oder Thunderbit – achte beim Scraping immer auf die Nutzungsbedingungen und Datenschutzvorgaben der jeweiligen Webseite.
Fazit: Mit Web Scraping in Rust (und darüber hinaus) echten Mehrwert schaffen
Web Scraping ist für Unternehmen, die im datengetriebenen Wettbewerb vorne mitspielen wollen, heute unverzichtbar. Rust liefert unschlagbare Performance, Sicherheit und Zuverlässigkeit für maßgeschneiderte, groß angelegte Scraping-Lösungen, gerade dann, wenn Geschwindigkeit und Stabilität den Ausschlag geben. Für die meisten Business-Anwender liegt die technische Einstiegshürde allerdings hoch.
Hier punktet Thunderbit: Die Plattform öffnet Web Scraping für alle – mit einer KI-gestützten, No-Code-Oberfläche, die auch knifflige Aufgaben wie Paginierung und Unterseiten automatisch erledigt. Ob du im Vertrieb Leads sammelst, im E-Commerce Preise überwachst oder als Analyst Marktdaten brauchst: Mit Thunderbit kommst du schnell und unkompliziert an die gewünschten Daten.
Das Wichtigste auf einen Blick:
- Rust ist die Top-Wahl für individuelle, groß angelegte Web-Scraping-Projekte – ideal für Technik-Teams.
- Thunderbit macht Web Scraping auch für Nicht-Techniker nutzbar.
- Wähle das passende Tool: Rust für maximale Anpassung, Thunderbit für Tempo und Komfort.
Mit KI Daten von jeder Webseite extrahieren Get Started Free
Neugierig geworden, was Web Scraping für dein Unternehmen leisten kann? Lade Thunderbit herunter und erlebe, wie einfach Datensammlung sein kann. Oder erkunde die Möglichkeiten von Rust, wenn du eine maßgeschneiderte High-Performance-Lösung suchst.
KI-Web-Scraper ausprobieren Get Started Free
Häufige Fragen (FAQ)
1. Was ist Web Scraping mit Rust und wie unterscheidet es sich von anderen Sprachen?
Web Scraping mit Rust bedeutet, dass du die Programmiersprache Rust nutzt, um Daten automatisiert von Webseiten zu extrahieren. Rust überzeugt im Vergleich zu Python oder JavaScript durch Geschwindigkeit, Speichersicherheit und Zuverlässigkeit – ideal für große oder besonders wichtige Scraping-Projekte.
2. Ist Rust für nicht-technische Business-Anwender geeignet?
Rust ist leistungsstark, erfordert aber Programmierkenntnisse. Für Nicht-Techniker bieten Tools wie Thunderbit eine KI-gestützte, No-Code-Lösung, mit der jeder Daten extrahieren kann.
3. Wie geht Rust mit komplexen Aufgaben wie Paginierung oder Unterseiten um?
Dank des starken Typsystems und asynchroner Bibliotheken kann Rust Code effizient schreiben, der automatisch durch Paginierungen navigiert, Unterseiten folgt und Fehler abfängt – für vollständige und zuverlässige Datensätze.
4. Wann sollte ich Thunderbit statt eines eigenen Rust-Scrapers nutzen?
Thunderbit ist ideal, wenn du schnell und ohne Programmierung Daten extrahieren möchtest – perfekt für Vertrieb, Marketing und Operations. Rust empfiehlt sich für hochgradig individuelle, groß angelegte oder tief integrierte Scraping-Prozesse, die technisches Know-how erfordern.
5. Was sind die größten Herausforderungen beim Web Scraping mit Rust und wie kann man sie meistern?
Typische Herausforderungen sind Seitenänderungen, Anti-Bot-Maßnahmen und laufende Wartung. Rust hilft, Fehler früh zu erkennen, aber Anpassungen am Code bleiben nötig. Für Routineaufgaben sparen No-Code-Tools wie Thunderbit Zeit und Nerven.
Mehr erfahren:




