Springen wir mal kurz zurück zu meinen ersten Tagen als Produktmanager: Damals hieß „an Daten kommen“ entweder, einen Entwickler mit Kaffee zu bestechen oder stundenlang Copy & Paste in Excel zu machen. (Ich träume heute noch von endlosen Strg+C, Strg+V-Marathons.) Heute leben wir in einer Welt, in der Daten allgegenwärtig sind – so sehr, dass der Markt für Web-Scraping-Software bis 2036 auf wachsen soll. Das Problem: Die meisten Daten sind hinter Bildschirmen versteckt – verteilt auf Webseiten, PDFs und Apps, die den Export alles andere als leicht machen.
Hier kommt KI-Screen Scraping ins Spiel – eine bewährte Methode, die durch KI komplett neu gedacht wurde. Egal ob du im Vertrieb, E-Commerce, Immobilienbereich arbeitest oder einfach Tabellen liebst: Wer versteht, wie modernes Screen Scraping funktioniert – und wie KI-Tools wie es für alle zugänglich machen – spart sich jede Menge Zeit und Nerven. Lass uns das mal genauer anschauen.
Was ist Screen Scraping? Datenextraktion einfach erklärt
Screen Scraping ist im Grunde die digitale Variante davon, was du auf dem Bildschirm siehst, automatisch zu erfassen – nur übernimmt das ein Roboter für dich. Es geht darum, Daten aus der visuellen Oberfläche einer Anwendung, Webseite oder sogar eines PDFs zu erfassen und in ein weiterverwendbares Format zu bringen ().
Stell dir vor: Wenn du schon mal eine Tabelle von einer Webseite in Excel kopiert hast, hast du Screen Scraping per Hand gemacht. Mit Automatisierung musst du aber nicht mehr deine Finger wund tippen – stattdessen liest eine Software den Bildschirminhalt aus, manchmal sogar mit Computer Vision oder OCR, wenn der Text nicht auswählbar ist.
Screen Scraping wird oft mit Web-Scraper und Data Scraping verwechselt. Hier die wichtigsten Unterschiede:
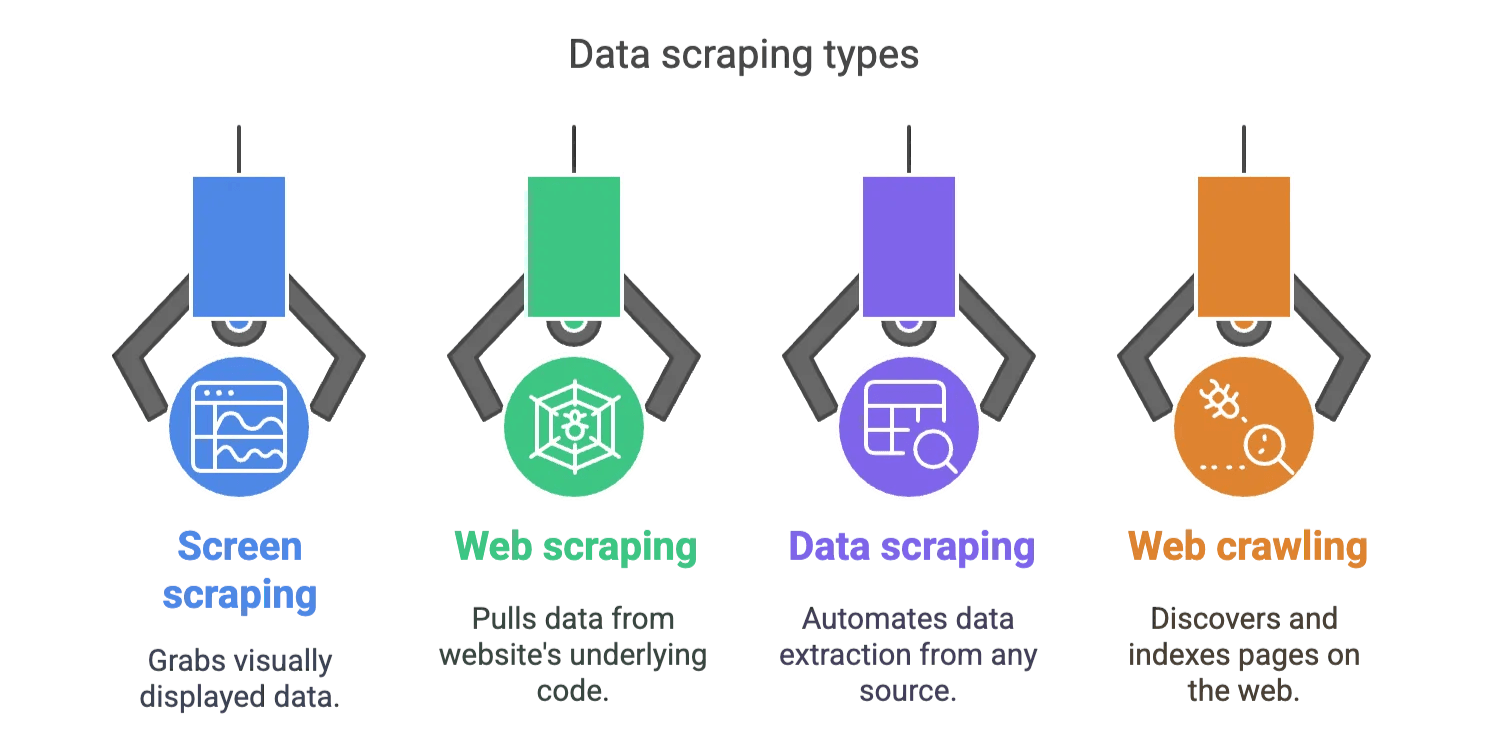
- Screen Scraping: Holt das, was sichtbar auf dem Bildschirm angezeigt wird.
- Web-Scraper: Zieht Daten aus dem Quellcode (HTML, JSON usw.) einer Webseite.
- Data Scraping: Überbegriff für die automatisierte Datenextraktion aus beliebigen Quellen (Web, Apps, Dateien usw.).
- Web Crawling: Durchsucht und indexiert Seiten, extrahiert aber nicht zwangsläufig Daten.
Wenn du also Infos aus einer alten Anwendung, einem geschützten PDF oder einer schwer zugänglichen Webseite brauchst, ist Screen Scraping dein Joker.
Screen Scraping vs. Web Scraper vs. Data Scraping: Die Unterschiede
Diese Begriffe werden oft durcheinandergeworfen, meinen aber nicht das Gleiche. Hier eine Übersichtstabelle zur Orientierung:
| Technik | Was sie macht | Wo sie funktioniert | Wie sie funktioniert | Typische Anwendungsfälle |
|---|---|---|---|---|
| Screen Scraping | Extrahiert Daten aus dem, was auf dem Bildschirm angezeigt wird | Apps, Altsysteme, PDFs, Webseiten | Liest Pixel, nutzt OCR oder UI-Automatisierung | Datenmigration, RPA, Altsysteme |
| Web-Scraper | Extrahiert Daten aus dem Webseiten-Code (HTML/DOM) | Webseiten | Parst HTML, nutzt HTTP-Requests, DOM-Navigation | Preisüberwachung, Lead-Generierung, Recherche |
| Data Scraping | Automatisiert die Extraktion aus beliebigen Datenquellen | Web, Dateien, Datenbanken, Logs usw. | Jegliche automatisierte Methode (Scraping, Parsing, Abfragen) | Datenintegration, Analysen |
| Web Crawling | Findet und indexiert Webseiten | Das Internet | Folgt Links, erstellt URL-Listen | Suchmaschinen, Sitemaps |
Warum die Verwirrung? Weil diese Methoden oft kombiniert werden: Ein Web Crawler findet alle Seiten, ein Web-Scraper extrahiert die Daten, und wenn diese nur sichtbar (nicht im Code) sind, kommt Screen Scraping ins Spiel.
Warum Screen Scraping für Unternehmen wichtig ist: Praxisbeispiele
Kommen wir zur Praxis: Warum interessieren sich Unternehmen für Screen Scraping, Web-Scraper und Data Scraping? Weil Daten Macht bedeuten – und die wenigsten Daten werden einem einfach so serviert.
Hier ein paar typische Anwendungsfälle:
| Team | Anwendungsfall | Vorteil | ROI-Beispiel |
|---|---|---|---|
| Vertrieb | Lead-Generierung aus Verzeichnissen | Mehr Leads, weniger Handarbeit | 5+ Stunden/Woche pro Mitarbeiter gespart (Thunderbit Nutzer) |
| E-Commerce | Wettbewerber-Preisüberwachung | Dynamische Preise, höhere Margen | 4% mehr Umsatz (John Lewis) |
| Immobilien | Aggregation von Immobilienanzeigen | Schnellere Marktanalyse | Mehr Abschlüsse, bessere Investitionen |
| Marketing | Bewertungen/Social Data scrapen | Sentiment-Analyse, Kampagnen-ROI | Besseres Targeting, schnellere Reaktion |
| Betrieb | Datenextraktion aus Lieferantenportalen | Automatisierte Berichte, weniger Fehler | Weniger manuelle Eingaben, weniger Fehler |
Und das ist nur der Anfang. Teams nutzen Scraping auch für Content-Migration, Compliance-Monitoring oder um interne Dashboards zu bauen, die jedem Data Scientist Konkurrenz machen.
Klassische Screen Scraping Tools: Funktionsweise und Grenzen
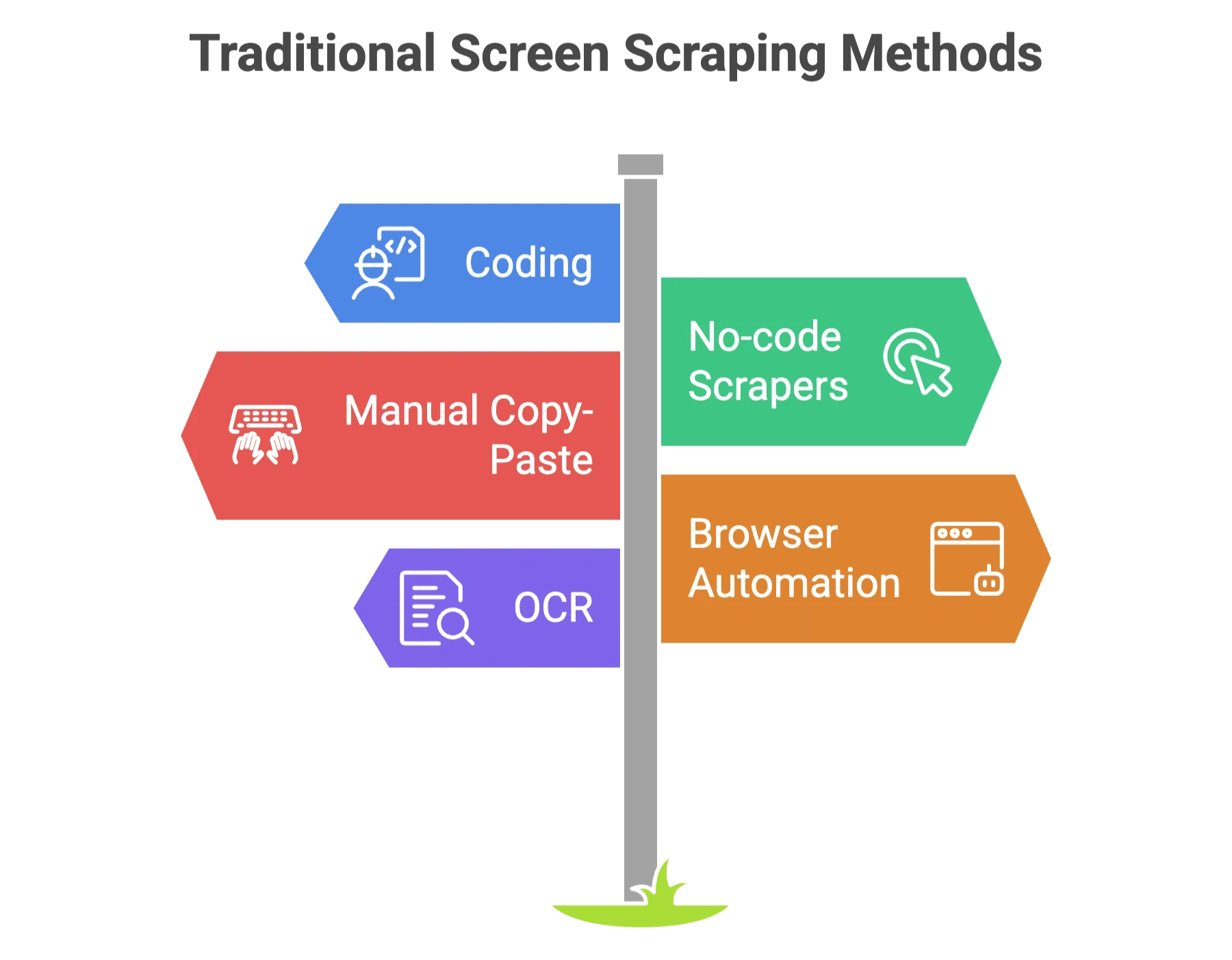
Vor dem KI-Zeitalter war Screen Scraping oft wie Möbel aufbauen ohne Anleitung. Es gab zwei Hauptwege:
- Programmieren: Eigene Skripte (z.B. in Python oder JavaScript) schreiben, um Daten zu holen und zu parsen. Super, wenn du gerne nachts debuggst.
- No-Code-Scraper: Tools, bei denen du per Klick auswählst, was extrahiert werden soll. Einfacher, aber oft fehleranfällig – und schon kleine Webseitenänderungen bringen alles durcheinander.
Weitere klassische Methoden:
- Manuelles Copy & Paste: Zeitfresser, fehleranfällig und nervig.
- Browser-Automatisierung (Selenium, Playwright): Simuliert einen Nutzer, braucht aber technisches Know-how.
- OCR: Wenn Daten in Bildern oder gescannten PDFs stecken.
Die größten Hürden:
- Aufbau ist technisch und dauert ewig.
- Wartung ist mühsam – schon kleine Änderungen auf der Webseite können alles lahmlegen.
- Kaum Datenaufbereitung – du bekommst Rohdaten, die du selbst weiterverarbeiten musst.
- Nicht-Techniker bleiben außen vor.
Wer schon mal mehr Zeit mit Reparieren als mit Datennutzung verbracht hat, weiß, wovon ich spreche.
KI-gestütztes Screen Scraping: So verändert KI das Spiel
Jetzt wird’s spannend: KI-gestützte Screen Scraper drehen den Spieß um. Statt sich mit Selektoren oder fehleranfälligem Code herumzuschlagen, übernimmt eine KI den Großteil der Arbeit.
Wie funktioniert das?
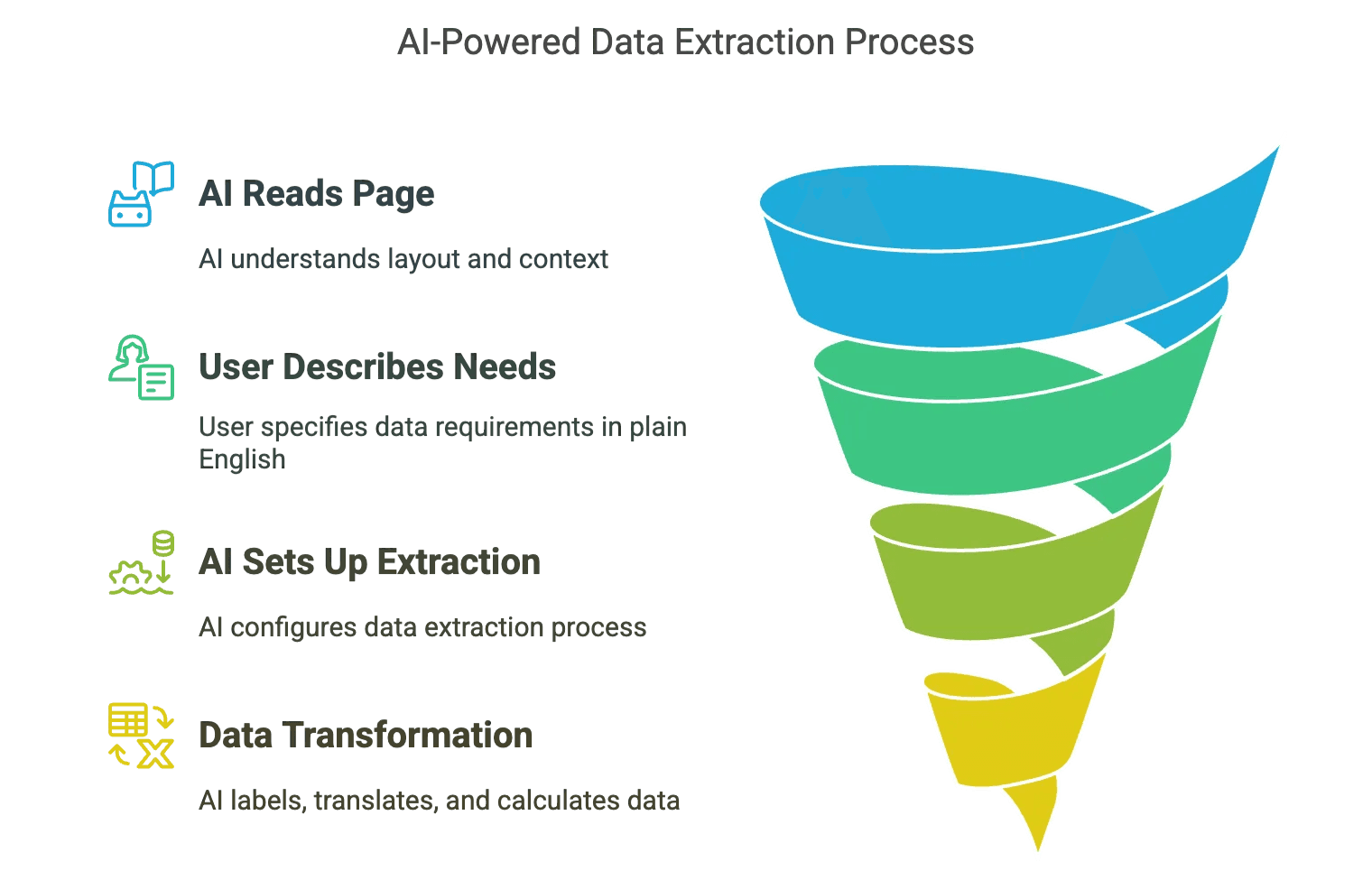
- Die KI „liest“ die Seite wie ein Mensch: Sie erkennt Layout, Kontext und relevante Inhalte – selbst wenn sich die Webseite ändert.
- Du beschreibst einfach, was du brauchst: Zum Beispiel „Alle Produktnamen, Preise und Bilder extrahieren“ – die KI richtet alles ein.
- Daten werden direkt aufbereitet: Beschriftungen, Übersetzungen, Berechnungen – die KI erledigt das während des Scrapings.
Das bedeutet:
- Kein mühsames Setup mehr.
- Keine ständige Wartung.
- Jeder kann es nutzen – nicht nur Entwickler.
Mit kannst du jede Webseite scrapen, egal wie sie aufgebaut ist, weil die KI sich automatisch anpasst. Du möchtest Daten direkt umwandeln oder beschriften? Thunderbit macht’s möglich – und das Ganze ist wirklich einfach zu bedienen.
Thunderbit: Der einfachste KI-Web-Scraper für alle
Kleiner Werbeblock – aber genau deshalb haben wir gebaut:
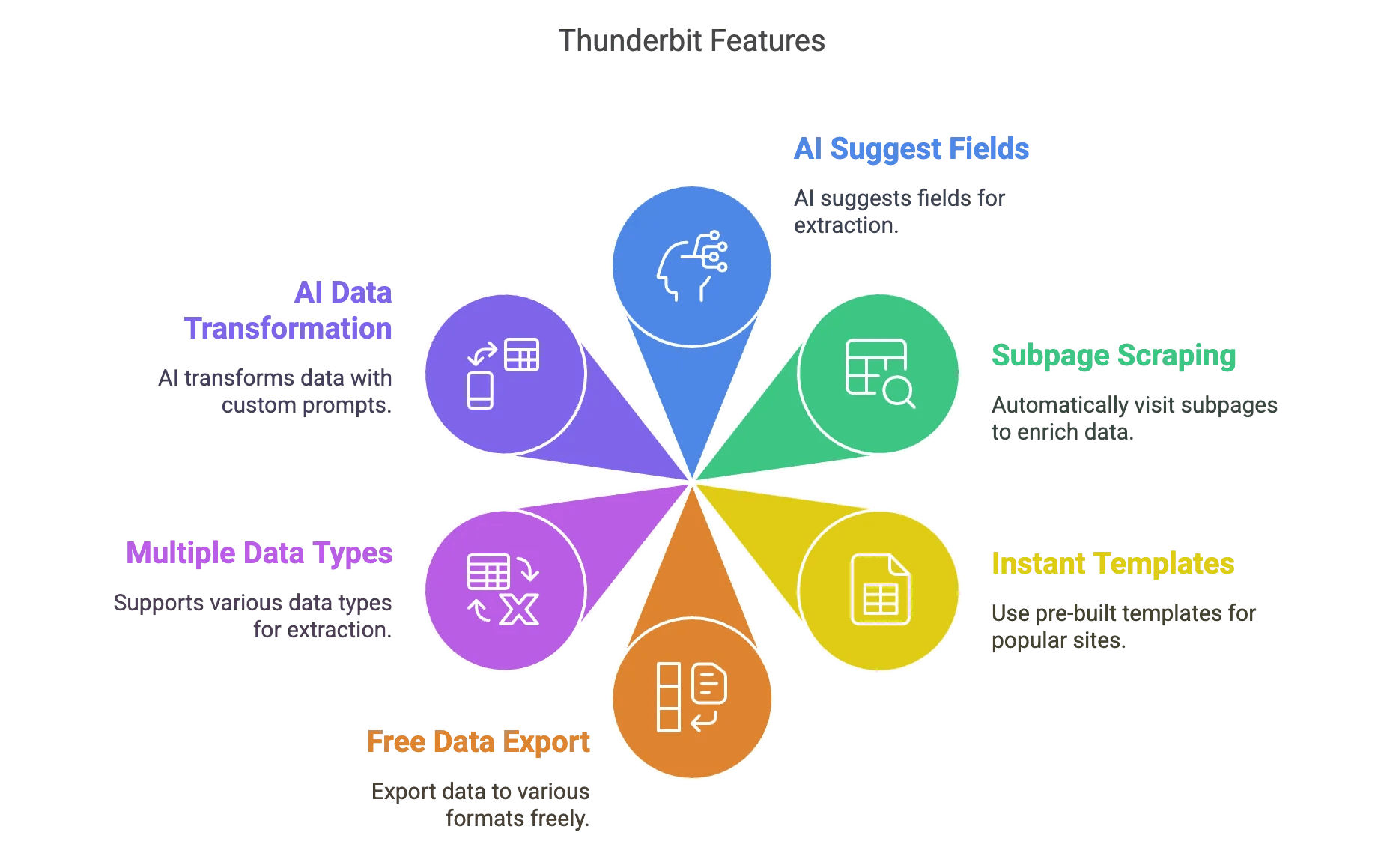
- KI-Feldvorschläge: Ein Klick, und Thunderbits KI analysiert die Seite und schlägt die besten Felder zur Extraktion vor. Kein Rätselraten mehr.
- Subpage-Scraping: Du brauchst mehr Details? Thunderbit besucht automatisch Unterseiten (z.B. einzelne Produkt- oder Profilseiten) und ergänzt deine Daten.
- Sofort-Vorlagen: Für bekannte Seiten (Amazon, Zillow, Instagram, Shopify usw.) gibt es fertige Templates für den 1-Klick-Export.
- Kostenloser Datenexport: Exportiere nach Excel, Google Sheets, Airtable, Notion, CSV oder JSON – ohne Zusatzkosten.
- Verschiedene Datentypen: Text, Zahlen, Daten, URLs, E-Mails, Telefonnummern, Bilder – alles möglich.
- KI-Datenaufbereitung: Mit eigenen Prompts kannst du Daten beim Scraping beschriften, formatieren oder sogar übersetzen lassen.
Und das alles steckt in einer , die wirklich Spaß macht (sofern Datenextraktion überhaupt Spaß machen kann).
So funktioniert KI-gestütztes Screen Scraping: Schritt für Schritt
So läuft ein typischer Workflow mit Thunderbit ab:
- Thunderbit Chrome-Erweiterung installieren.
- Einfach im herunterladen.
- Zur gewünschten Webseite oder PDF navigieren.
- Thunderbit unterstützt Webseiten, PDFs und sogar Bilder.
- „KI-Feldvorschläge“ anklicken.
- Die KI liest die Seite und schlägt passende Spalten vor (z.B. Name, Preis, E-Mail, Bild).
- Felder prüfen und anpassen.
- Spalten hinzufügen oder umbenennen, Datentypen festlegen oder eigene KI-Prompts für Beschriftung/Übersetzung ergänzen.
- „Scrapen“ klicken.
- Thunderbit extrahiert die Daten und zeigt sie in einer strukturierten Tabelle an.
- (Optional) Unterseiten scrapen.
- Für mehr Details kann Thunderbit Links folgen und weitere Infos holen.
- Daten exportieren.
- Als CSV, Excel oder direkt nach Google Sheets, Airtable oder Notion exportieren.
Tipps für beste Ergebnisse:
- Klare Feldnamen verwenden (z.B. „Produktname“, „Preis in EUR“).
- Prompts für spezielle Formatierungen oder Übersetzungen nutzen.
- Für jedes Feld den passenden Datentyp wählen.
Weitere Schritt-für-Schritt-Anleitungen findest du in unserem oder auf unserem .
Beispiel-Workflow: Leads von einer Webseite mit Thunderbit scrapen
Angenommen, du bist im Vertrieb und suchst Leads in einem Branchenverzeichnis. So würde ich vorgehen:
- Verzeichnis-Seite öffnen.
- Thunderbit-Erweiterung starten und „KI-Feldvorschläge“ anklicken.
- Thunderbit schlägt vor: Name, Firma, E-Mail, Telefonnummer, Webseite.
- Ich passe die Spalten an – z.B. „Standort“ oder „Branche“ ergänzen.
- „Scrapen“ klicken. Thunderbit sammelt alle sichtbaren Leads in einer Tabelle.
- Einige Leads verlinken auf Detailprofile. Ich klicke „Unterseiten scrapen“ und Thunderbit holt weitere Infos wie LinkedIn-URLs oder Kurzprofile.
- Die Liste exportiere ich nach Excel oder Google Sheets – fertig für die Ansprache.
Kein Code, kein Stress und keine Entwickler-Bestechung mehr nötig.
Mehr als nur Text: Fortgeschrittenes Data Scraping mit KI (Bilder, Labels, Übersetzungen & mehr)
Moderne KI-Scraper können viel mehr als nur Text erfassen. Mit Thunderbit kannst du:
- Bilder extrahieren: Perfekt für Produktkataloge oder Immobilienanzeigen.
- E-Mails und Telefonnummern erfassen: Thunderbit erkennt und formatiert diese Felder automatisch.
- Daten direkt übersetzen: Scrape zum Beispiel eine französische Webseite und erhalte die Daten auf Deutsch.
- Daten labeln oder kategorisieren: Mit KI-Prompts kannst du Einträge taggen, zusammenfassen oder gruppieren.
- Integration mit Notion, Airtable & Co.: Schick deine Daten direkt in deine Lieblingstools.
Gerade für Unternehmen ein riesiger Vorteil: CRM-Daten mit Bildern, mehrsprachigen Infos oder kategorisierten Leads anreichern – alles in einem Schritt.
Mehr zu fortgeschrittenen Workflows findest du unter und .
Rechtlich und sicher: Was Unternehmen beim Screen Scraping beachten sollten
Screen Scraping ist mächtig, aber du solltest dich an die Spielregeln halten. Meine Tipps:
- AGB der Webseite prüfen: Manche Seiten verbieten Scraping ausdrücklich. Im Zweifel um Erlaubnis fragen oder nach einer offiziellen API suchen.
- robots.txt respektieren: Nicht rechtlich bindend, aber höflich – und hilft, nicht blockiert zu werden.
- Keine geschützten Bereiche scrapen (außer eigene Daten): Hier drohen rechtliche Probleme.
- Mit personenbezogenen Daten vorsichtig umgehen: DSGVO, CCPA & Co. gelten auch beim Scraping von Namen, E-Mails usw.
- Server nicht überlasten: Mit Rate Limiting ein guter Web-Bürger bleiben.
Für mehr Infos siehe Ist LinkedIn Scraping legal? und .
Fazit: Die Zukunft von Screen Scraping mit KI
Screen Scraping hat sich enorm weiterentwickelt – von mühsamer Handarbeit zu KI-gestützter Automatisierung. Dank Tools wie Thunderbit kann heute jeder Daten aus fast jeder Quelle extrahieren, transformieren und nutzen – ohne großen Aufwand und ganz ohne Programmierkenntnisse.
Das Wichtigste auf einen Blick:
- Screen Scraping erschließt Daten, wo APIs nicht hinkommen.
- KI-Tools machen es für alle zugänglich – nicht nur für Entwickler.
- Unternehmen können Lead-Generierung, Preisüberwachung, Marktforschung und mehr mit wenigen Klicks automatisieren.
- Recht und Ethik sind entscheidend – immer Quelle und Gesetz respektieren.
Wenn du die manuelle Datensammlung endlich hinter dir lassen willst, probier aus. Deine Tastatur wird es dir danken.
Neugierig geworden? Im findest du tiefergehende Artikel zu , und vieles mehr. Oder installiere einfach die und erlebe selbst, wie einfach Screen Scraping heute ist.
Und falls du immer noch Daten per Hand kopierst ... glaub mir, es gibt einen besseren Weg.
Häufige Fragen
-
Funktioniert Screen Scraping auch bei mobilen Apps? Ja, Screen Scraping kann auch bei mobilen Apps eingesetzt werden, besonders bei älteren oder geschlossenen Systemen. Dafür sind meist UI-Automatisierung oder spezielle Mobile-Tools nötig, um Daten aus der App-Oberfläche zu extrahieren.
-
Kann Screen Scraping auch Bilder oder visuelle Inhalte extrahieren? Screen Scraping ist nicht auf Text beschränkt – es kann auch Bilder, Diagramme oder UI-Elemente erfassen, indem Bildschirmbereiche ausgelesen oder per Computer Vision erkannt und beschriftet werden.
-
Welche Tools brauche ich für den Einstieg ins Screen Scraping? Du kannst mit Skripting-Tools wie Python und Bibliotheken wie Selenium oder Playwright starten. Für Nicht-Programmierer gibt es visuelle Scraper oder KI-Tools, die per Klick bedient werden und kaum Einrichtung erfordern.
-
Welche Risiken gibt es beim Screen Scraping? Risiken sind rechtliche Probleme, IP-Blockaden oder ungenaue Daten. Änderungen am Layout können Scraper aus dem Tritt bringen, und das Scrapen personenbezogener Daten kann Datenschutzgesetze verletzen, wenn man nicht aufpasst.
Mehr erfahren