Hast du schon mal versucht, bei hunderten Wettbewerber-Websites den Überblick zu behalten – nur um festzustellen, dass du dafür entweder ein ganzes Team oder literweise Kaffee bräuchtest, um alle Daten per Hand zu kopieren? Damit bist du definitiv nicht allein. Im heutigen Business-Alltag sind Webdaten echtes Gold wert – egal ob im Vertrieb, Marketing, in der Forschung oder im operativen Bereich. Tatsächlich machen Web-Scraper mittlerweile über aus, und 81 % der US-Händler setzen automatisierte Scraper ein, um Preise zu überwachen (). Da sind also jede Menge Bots unterwegs, die die Arbeit übernehmen.
Aber wie funktionieren diese Bots eigentlich? Und warum setzen so viele Teams auf Node.js – das JavaScript-Framework, das hinter vielen modernen Webanwendungen steckt – um eigene node web crawler zu bauen? Als jemand, der seit Jahren im SaaS- und Automatisierungsbereich unterwegs ist (und als CEO von ), weiß ich aus Erfahrung: Mit den richtigen Tools wird das Sammeln von Webdaten vom nervigen Problem zum echten Wettbewerbsvorteil. Lass uns gemeinsam anschauen, was ein node web crawler wirklich ist, wie er funktioniert und wie auch Nicht-Programmierer davon profitieren können.
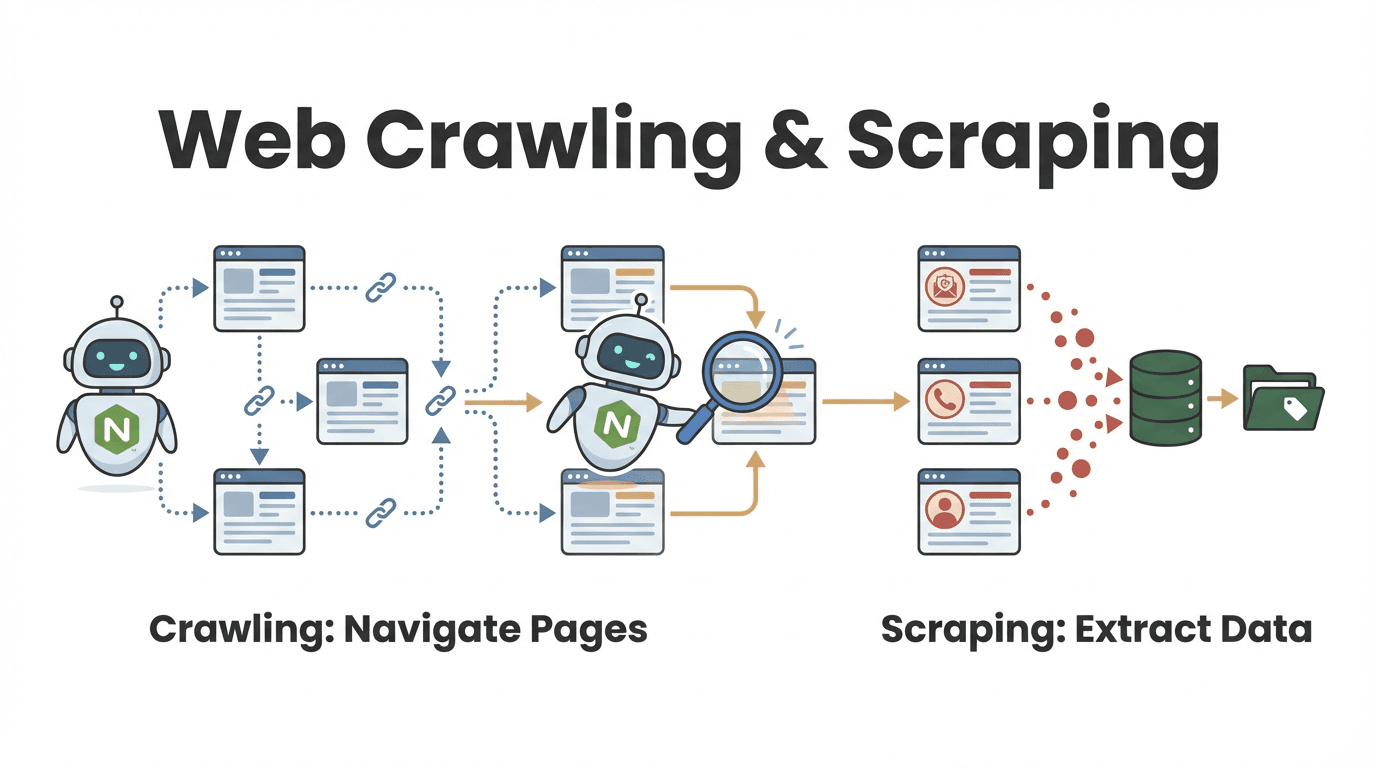
Node Web Crawler: Die Basics locker erklärt
Fangen wir ganz entspannt an. Ein node web crawler ist ein Programm, das mit Node.js gebaut wird und automatisch Webseiten besucht, Links abklappert und Infos einsammelt. Stell dir das wie einen digitalen Praktikanten vor, der nie müde wird: Du gibst ihm eine Start-URL, und er klickt sich durch die Seiten, sammelt die gewünschten Daten und macht so lange weiter, bis alles im Kasten ist, was du brauchst.
Doch was ist eigentlich der Unterschied zwischen Web Crawling und Web Scraping? Diese Frage höre ich oft, vor allem von Leuten aus dem Business:
- Web Crawling heißt, viele Seiten zu entdecken und zu durchforsten. Das ist, als würdest du in einer Bibliothek jedes Buch durchblättern, um die passenden zu finden.
- Web Scraping bedeutet, gezielt bestimmte Infos aus diesen Seiten zu ziehen – wie das Herausschreiben wichtiger Zitate aus jedem Buch.
In der Praxis machen die meisten node web crawler beides: Sie finden die relevanten Seiten und holen die gewünschten Daten raus (). Ein Vertriebsteam könnte zum Beispiel ein Firmenverzeichnis durchforsten, alle Profile finden und dann die Kontaktdaten extrahieren.
Wie läuft ein Node Web Crawler ab?
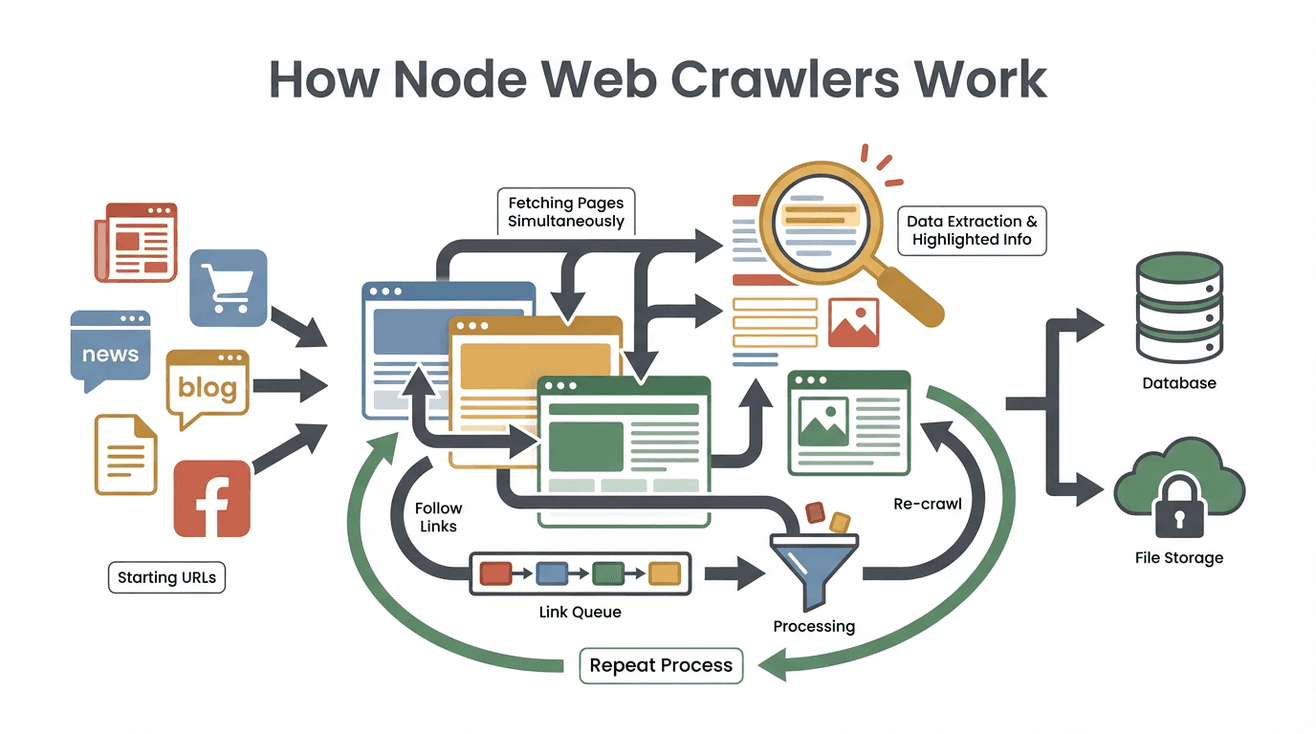 Schauen wir mal hinter die Kulissen. So arbeitet ein typischer node web crawler Schritt für Schritt:
Schauen wir mal hinter die Kulissen. So arbeitet ein typischer node web crawler Schritt für Schritt:
- Start mit Seed-URLs: Du gibst dem Crawler eine oder mehrere Startseiten (z. B. die Homepage oder eine Produktübersicht).
- Seiteninhalt holen: Der Crawler lädt den HTML-Code jeder Seite runter – ähnlich wie dein Browser, nur ohne Bilder und Design.
- Nützliche Daten rausziehen: Mit Tools wie Cheerio (quasi jQuery für Node) werden die gewünschten Infos gefiltert – Namen, Preise, E-Mails usw.
- Neue Links finden und einreihen: Der Crawler sucht auf jeder Seite nach weiteren Links (z. B. „Nächste Seite“ oder Produktdetails) und setzt sie auf eine To-Do-Liste (die sogenannte „Crawl Frontier“).
- Prozess wiederholen: Der Crawler besucht die neuen Links, extrahiert Daten und erweitert so nach und nach seinen Suchbereich, bis alles abgedeckt ist, was du vorgegeben hast.
- Ergebnisse speichern: Alle gesammelten Daten werden gespeichert – meist als CSV, JSON oder direkt in einer Datenbank.
- Fertig: Der Crawler stoppt, wenn keine neuen Links mehr da sind oder ein von dir gesetztes Limit erreicht ist.
Ein Beispiel aus dem Alltag: Du willst alle Stellenanzeigen einer Karriereseite sammeln. Du startest mit der Übersichtsseite, extrahierst alle Job-Links, besuchst jede einzelne Anzeige, holst dir die Details und folgst dem „Weiter“-Button, bis du die komplette Liste hast.
Das Coole daran: Dank der ereignisgesteuerten, nicht-blockierenden Architektur von Node.js kann der Crawler viele Seiten gleichzeitig abarbeiten, ohne auf langsame Websites warten zu müssen. Es ist, als hättest du ein ganzes Team von Praktikanten, die parallel arbeiten – nur ohne Pizza-Budget.
Warum ist Node.js für Web Crawler so beliebt?
Warum also Node.js? Warum nicht Python, Java oder was anderes? Das macht Node.js für Web Crawling besonders spannend:
- Ereignisgesteuerte, nicht-blockierende I/O: Node.js kann Dutzende oder sogar Hunderte Seitenanfragen gleichzeitig bearbeiten, ohne ins Stocken zu geraten. Während eine Seite lädt, arbeitet der Crawler schon an den nächsten ().
- Hohe Performance: Node läuft auf Googles V8-Engine (wie Chrome) und ist besonders schnell beim Verarbeiten großer Datenmengen.
- Riesiges Ökosystem: Es gibt für alles eine Node-Bibliothek: Cheerio für HTML-Parsing, Got für HTTP-Anfragen, Puppeteer für Headless-Browsing und Frameworks wie Crawlee für große Crawls ().
- JavaScript-Kompatibilität: Da die meisten Websites JavaScript nutzen, kann Node.js direkt mit ihnen interagieren. Auch der Umgang mit JSON-Daten ist super easy.
- Echtzeit-Fähigkeit: Du willst viele Seiten gleichzeitig auf Preisänderungen oder News überwachen? Mit Node ist das fast in Echtzeit möglich.
Kein Wunder, dass Node-basierte Tools wie Crawlee und Cheerio von genutzt werden.
Was kann ein Node Web Crawler alles?
Node web crawler sind echte Allrounder für Webdaten. Typische Features – und wie sie im Business-Alltag helfen:
| Funktion | Wie es im Node Crawler funktioniert | Business-Anwendungsbeispiel |
|---|---|---|
| Automatisierte Navigation | Folgt automatisch Links und durchblättert paginierte Seiten | Lead-Generierung: Alle Einträge eines Online-Verzeichnisses erfassen |
| Datenextraktion | Zieht gezielt Felder (Name, Preis, Kontakt) per Selektoren oder Muster | Preisüberwachung: Produktpreise von Wettbewerbern extrahieren |
| Gleichzeitige Verarbeitung | Lädt und verarbeitet viele Seiten parallel (dank asynchronem Node.js) | Echtzeit-Updates: Mehrere News-Seiten gleichzeitig überwachen |
| Strukturierte Datenausgabe | Speichert Ergebnisse als CSV, JSON oder direkt in einer Datenbank | Analytics: Daten in BI-Dashboards oder CRM-Systeme einspeisen |
| Anpassbare Logik & Filter | Eigene Regeln, Filter oder Datenbereinigung im Code möglich | Qualitätskontrolle: Veraltete Seiten überspringen, Datenformate anpassen |
Ein Marketing-Team könnte zum Beispiel mit einem node web crawler alle Blogartikel von Branchenseiten sammeln, Titel und URLs extrahieren und für die Content-Planung in Google Sheets exportieren.
Thunderbit: Die No-Code-Alternative zum Node Web Crawler
Jetzt wird’s richtig spannend – und vor allem für Nicht-Programmierer super easy. ist eine KI-gestützte Web-Scraper Chrome-Erweiterung, mit der du Webdaten extrahieren kannst – komplett ohne Code.
Wie läuft das ab? Du öffnest die Erweiterung, klickst auf „KI-Felder vorschlagen“ und Thunderbits KI liest die Seite, schlägt passende Datenfelder vor und packt alles in eine übersichtliche Tabelle. Du willst alle Produktnamen und Preise einer Seite erfassen? Sag Thunderbit einfach in Alltagssprache, was du brauchst – der Rest läuft automatisch. Auch Unterseiten und Paginierung? Ein Klick reicht.
Meine Lieblingsfunktionen bei Thunderbit:
- Bedienung in natürlicher Sprache: Einfach beschreiben, was du willst – die KI macht den Rest.
- KI-generierte Feldvorschläge: Thunderbit analysiert die Seite und schlägt die besten Spalten vor.
- No-Code-Unterseiten-Crawling: Detailseiten (z. B. einzelne Produkte oder Profile) automatisch erfassen und zusammenführen.
- Strukturierter Export: Daten direkt nach Excel, Google Sheets, Airtable oder Notion exportieren.
- Kostenloser Datenexport: Keine versteckten Gebühren für den Download deiner Ergebnisse.
- Automatisierung & Zeitplanung: Wiederkehrende Scrapes mit natürlicher Sprache planen („jeden Montag um 9 Uhr“).
- Kontakt-Extraktion: E-Mails, Telefonnummern und Bilder mit nur einem Klick extrahieren – komplett kostenlos.
Für Business-Anwender heißt das: Von „Ich brauche diese Daten“ zu „Hier ist meine Tabelle“ in wenigen Minuten statt Tagen. Und laut erstellen selbst Nicht-Techniker Lead-Listen, überwachen Preise und betreiben Recherche – ganz ohne Programmierkenntnisse.
Node Web Crawler vs. Thunderbit: Was passt zu deinem Unternehmen?
Welche Lösung ist die richtige für dich? Hier der direkte Vergleich:
| Kriterium | Node.js Web Crawler (eigener Code) | Thunderbit (No-Code KI-Scraper) |
|---|---|---|
| Einrichtungszeit | Stunden bis Tage (Programmierung, Debugging, Setup) | Minuten (installieren, klicken, scrapen) |
| Technisches Know-how | Programmierkenntnisse (Node.js, HTML, Selektoren) nötig | Kein Coding erforderlich; natürliche Sprache & Klicks |
| Anpassbarkeit | Extrem flexibel; jede Logik und jedes Workflow möglich | Begrenzung auf integrierte Features & KI-Fähigkeiten |
| Skalierbarkeit | Sehr hohe Skalierung möglich (mit Aufwand: Server, Proxies) | Cloud-Scraping für kleine bis mittlere Projekte |
| Wartung | Laufend (Code anpassen, Fehler beheben) | Minimal (Thunderbits KI passt sich Änderungen an) |
| Anti-Bot-Handling | Proxies, Delays, Headless-Browser selbst implementieren | Automatisch durch Thunderbit-Backend |
| Integration | Tiefe Integration möglich (APIs, Datenbanken, Workflows) | Export zu Sheets, Notion, Airtable, Excel, CSV |
| Kosten | Tools meist kostenlos, aber Entwickler- und Serverkosten | Kostenloser Einstieg, dann nutzungsbasiert oder Abo |
Wann solltest du Node.js nutzen?
- Du brauchst sehr individuelle Logik oder Integration.
- Du hast Entwickler im Team und willst volle Kontrolle.
- Du scrapest in großem Stil oder baust ein Produkt rund um Webdaten.
Wann ist Thunderbit die bessere Wahl?
- Du willst schnelle Ergebnisse mit minimalem Aufwand.
- Du bist kein Programmierer (und willst es auch nicht werden).
- Du musst regelmäßig verschiedene Websites für Business-Zwecke scrapen.
- Du legst Wert auf einfache Bedienung und KI-gestützte Anpassungsfähigkeit.
Viele Teams starten mit Thunderbit für schnelle Erfolge und steigen bei komplexeren Anforderungen auf eigene node web crawler um.
Typische Herausforderungen bei Node Web Crawlern
Node web crawler sind mächtig, aber nicht ohne Tücken. Die häufigsten Stolpersteine (und wie du sie umgehst):
- Anti-Scraping-Maßnahmen: Viele Websites setzen CAPTCHAs, IP-Sperren und Bot-Erkennung ein. Du musst Proxies rotieren, Header variieren und manchmal Headless-Browser wie Puppeteer nutzen ().
- Dynamische Inhalte: Viele Seiten laden Daten per JavaScript oder mit unendlichem Scrollen. Einfaches HTML-Parsing reicht dann nicht – du musst echtes Browsing simulieren oder APIs nutzen.
- Parsing und Datenbereinigung: Nicht alle Webseiten sind sauber strukturiert. Du musst mit inkonsistenten Formaten, fehlenden Daten und seltsamen Codierungen umgehen.
- Wartung: Websites ändern sich. Dein Code wird irgendwann nicht mehr laufen. Plane regelmäßige Updates und Fehlerbehandlung ein.
- Rechtliche und ethische Fragen: Beachte immer
robots.txt, Nutzungsbedingungen und Datenschutzgesetze. Keine sensiblen oder urheberrechtlich geschützten Daten scrapen.
Best Practices:
- Nutze Frameworks wie Crawlee, die viele Probleme direkt lösen.
- Baue Wiederholungen, Delays und Fehlerprotokolle ein.
- Überprüfe und aktualisiere deine Crawler regelmäßig.
- Scrape verantwortungsvoll – keine Überlastung von Websites oder Verstöße gegen Nutzungsbedingungen.
Node Web Crawler in der Cloud betreiben
Für größere, dauerhafte Webdaten-Projekte reicht der eigene Laptop nicht aus. Hier kommt die Cloud ins Spiel:
- Serverless Functions: Deploye deinen node web crawler als AWS Lambda oder Google Cloud Function. Plane automatische Ausführungen (z. B. täglich oder stündlich) und speichere Ergebnisse in Cloud-Speichern wie S3 oder BigQuery ().
- Containerisierte Crawler: Pack deinen Crawler in einen Docker-Container und betreibe ihn auf AWS Fargate, Google Cloud Run oder Kubernetes. So kannst du tausende Seiten parallel crawlen.
- Automatisierte Workflows: Nutze Cloud-Scheduler (wie AWS EventBridge), um Crawls zu starten, Ergebnisse zu speichern und Daten in Analytics- oder Machine-Learning-Modelle einzuspeisen.
Die Vorteile: Skalierbarkeit, Zuverlässigkeit und echte Automatisierung. Schon – und es werden immer mehr.
Wann Node Web Crawler, wann No-Code-Lösung?
Noch unsicher? Hier eine schnelle Entscheidungshilfe:
-
Brauchst du individuelle Anpassungen, spezielle Workflows oder Integration mit internen Systemen?
→ Node.js Web Crawler -
Bist du Business-Anwender und brauchst schnell Daten – ohne Programmierung?
→ Thunderbit (oder ein anderes No-Code-Tool) -
Ist es eine einmalige oder seltene Aufgabe?
→ Thunderbit -
Handelt es sich um ein kritisches, dauerhaftes Großprojekt?
→ Node.js (mit Cloud-Integration) -
Hast du Entwickler im Team und Zeit für Wartung?
→ Node.js -
Möchtest du, dass auch Nicht-Techniker im Team selbstständig Daten sammeln können?
→ Thunderbit
Mein Tipp: Starte mit einer No-Code-Lösung für schnelle Ergebnisse und Prototypen. Wenn der Bedarf wächst, kannst du immer noch auf einen eigenen node web crawler umsteigen. Viele Teams decken mit Thunderbit schon 90 % ihrer Anwendungsfälle ab – und sparen dabei jede Menge Zeit und Nerven.
Fazit: Webdaten als Wachstumsmotor für Unternehmen
 Webdaten zu extrahieren ist längst kein reines Technikthema mehr – es ist ein Muss für moderne Unternehmen. Egal, ob du einen eigenen node web crawler baust oder ein KI-Tool wie nutzt: Das Ziel ist immer, das Chaos des Webs in strukturierte, nutzbare Erkenntnisse zu verwandeln.
Webdaten zu extrahieren ist längst kein reines Technikthema mehr – es ist ein Muss für moderne Unternehmen. Egal, ob du einen eigenen node web crawler baust oder ein KI-Tool wie nutzt: Das Ziel ist immer, das Chaos des Webs in strukturierte, nutzbare Erkenntnisse zu verwandeln.
Node.js bietet maximale Flexibilität und Power, vor allem für komplexe oder groß angelegte Projekte. Für die meisten Business-Anwender ermöglichen No-Code- und KI-Tools aber, schnell und zuverlässig an die benötigten Daten zu kommen – ganz ohne Programmieraufwand.
Da inzwischen , werden die Teams, die Webdaten beherrschen, die Nase vorn haben. Egal ob Entwickler, Marketer oder einfach jemand, der keine Lust mehr auf Copy-Paste hat – es war nie einfacher, die Möglichkeiten von Web Crawling zu nutzen.
Neugierig geworden? kostenlos herunter und erlebe, wie einfach Webdaten-Extraktion sein kann. Und wenn du tiefer einsteigen willst, findest du im weitere Anleitungen, Tipps und Erfahrungsberichte aus der Welt der Webautomatisierung.
Häufige Fragen
1. Was ist der Unterschied zwischen einem Node Web Crawler und einem Web Scraper?
Ein node web crawler entdeckt und durchforstet automatisch Webseiten (wie eine Spinne im Netz), während ein Web-Scraper gezielt bestimmte Daten aus diesen Seiten extrahiert. Die meisten Node Crawler machen beides: Sie finden Seiten und holen die gewünschten Infos raus.
2. Warum ist Node.js so beliebt für Web Crawler?
Node.js ist ereignisgesteuert und nicht-blockierend, kann also viele Seitenanfragen gleichzeitig bearbeiten. Es ist schnell, hat ein riesiges Ökosystem an Bibliotheken und eignet sich besonders für Echtzeit- oder große Datenmengen.
3. Was sind die größten Herausforderungen bei Node Web Crawlern?
Typische Probleme sind Anti-Bot-Maßnahmen (CAPTCHAs, IP-Sperren), dynamische Inhalte (JavaScript-lastige Seiten), Datenbereinigung und laufende Wartung bei Website-Änderungen. Frameworks und Best Practices helfen, aber technisches Know-how ist nötig.
4. Wie unterscheidet sich Thunderbit von einem Node Web Crawler?
Thunderbit ist ein No-Code, KI-gestützter Web-Scraper. Statt zu programmieren, nutzt du eine Chrome-Erweiterung und natürliche Sprache, um Daten zu extrahieren. Ideal für Business-Anwender, die schnell Ergebnisse wollen – ohne Coding.
5. Wann sollte ich einen Node Web Crawler statt Thunderbit nutzen?
Node.js eignet sich für sehr individuelle, groß angelegte oder tief integrierte Projekte – vor allem, wenn Entwicklerressourcen vorhanden sind. Thunderbit ist ideal für schnelle, alltägliche Scraping-Aufgaben oder wenn auch Nicht-Techniker im Team Daten sammeln sollen.
Bereit, dein Webdaten-Game zu verbessern? Probier aus oder stöbere im weiter. Viel Erfolg beim Crawlen!
Mehr erfahren